情感分析全解:文本预处理、加载词向量、搭建RNN
IMDB Sentiment Classification from scratch
Author: Beyond
Time: 2019.04.26
情感分析是上手NLP的最简单的任务之一,它就是一个简单的文本分类问题,判断一段文本的情感极性。最简单的就是二分类,判断是积极的还是消极的;更难一点的就是三分类,除了积极消极还有无情感倾向的;更加复杂的就比如情感打分,例如电影打1~5分,这就是五分类。但本质上都一样,无非类别太多更难以学习罢了。
IMDB是一个专业的电影评论网站,类似国内的豆瓣,IMDB的电影评论数据是大家经常使用来练手的情感分析数据集,也是各种比赛,如Kaggle,和各种学者做研究常用的数据集。
今天尝试用这个数据做一个情感二分类,作为一个NLP的练手。具体涉及到:
【想要了解更多NLP,可以去这个小众优质社区看看:建议收藏网址,一个自带阅读器的文献搜索库,并且还能动态讨论,发现的时候就很惊喜】学术范学术范是一个在线学术交流社区,收录论文、作者、研究机构等信息,是一个与小木虫、知乎类似的学术讨论论坛,也是一个与中国知网、万方数据库、readpaper类似的免费文献资源PDF阅读网站,帮助您轻松了解学科前沿,参与专业且活跃的学术讨论。https://www.xueshufan.com/
- 文本预处理;
- 预训练词向量的加载;
- 采用RNNs训练模型
数据集地址:Sentiment Analysis (stanford.edu)
且采用Keras作为框架在进行模型搭建。
1.数据集
①关于数据集
其实,keras自带了IMDB的已经进行很好的预处理的数据集,可以一行代码下载,不需要进行任何的处理就可以训练,而且效果比较好。但是,这样就太没意思了。在真实场景中,我们拿到的都是脏脏的数据,我们必须自己学会读取、清洗、筛选、分成训练集测试集。而且,从我自己的实践经验来看,数据预处理的本事才是真本事,模型都好搭,现在的各种框架已经让搭建模型越来越容易,但是数据预处理只能自己动手。所有往往实际任务中,数据预处理花费的时间、精力是最多的,而且直接影响后面的效果。
另外,我们要知道,对文本进行分析,首先要将文本数值化。因为计算机不认字的,只认数字。所以最后处理好的文本应该是数值化的形式。而keras自带的数据集全都数值化了,而它并不提供对应的查询字典让我们知道每个数字对应什么文字,这让我们只能训练模型,看效果,无法拓展到其他语料上,也无法深入分析。综上,我上面推荐的数据集,是原始数据集,都是真实文本,当然,为了方便处理,也已经被斯坦福的大佬分好类了。但是怎么数值化,需要我们自己动手。
下载后解压,会看到有两个文件夹,test和train,我们点进train中,会发现正样本和负样本已经分好类了,其中neg和pos分别是负样本和正样本,unsup是未标注的样本,可用后续需要采用。其他的都自己去看看吧。打开pos文件,都是一个个文本。
注意到,这些文本一般都不短...
数据集中,共有5w条文本,test集和train集各半,每个集合中,pos和neg也是各半。
当然,他们划分的train和test,你不一定真的要这样用。例如本文中,我为了方便,就吧train集合当做我所有的数据,在这2.5w条数据中再按照7:3划分train set和test set.
②导入数据集的代码
import os
datapath = r'datasets\aclImdb_v1\train'
pos_files = os.listdir(datapath+'/pos')
neg_files = os.listdir(datapath+'/neg')
print(len(pos_files))
print(len(neg_files))输出:
12500
12500所以我们总共有12500个正样本和12500个负样本。
import numpy as np
pos_all = []
neg_all = []
for pf,nf in zip(pos_files,neg_files):
with open(datapath+'/pos'+'/'+pf,encoding='utf-8') as f:
s = f.read()
pos_all.append(s)
with open(datapath+'/neg'+'/'+nf,encoding='utf-8') as f:
s = f.read()
neg_all.append(s)
print(len(pos_all))
print(len(neg_all))
X_orig = np.array(pos_all+neg_all)
Y_orig = np.array([1 for _ in range(12500)] + [0 for _ in range(12500)])
print("X_orig:",X_orig.shape)
print("Y_orig:",Y_orig.shape)上面代码的主要作用是把一个个样本放进正负样本对应的列表中,同时配上对应的label。代码很好理解。
输出:
12500
12500
X_orig: (25000,)
Y_orig: (25000,)2.文本数值化
①文本数值化的思路
前面提到过,NLP问题比CV问题更难的一部分原因,就是文本都是离散化的数据,不像图像数据都是连续的数值数据,所以我们要想办法把一系列文本转化成一系列数字。
这里的方法很多,我们这里采用的方法是,给词汇表中每一个词一个index,用index代替那个词。如一个语料库共有1w个词,那么就设置1w个index,每个词直接替换程index就行。
但是,很多问题中,词汇量巨大,但是可能大部分词都是低频词,对训练模型的贡献很小,反而会严重拖累模型的训练。所以,一般我们可以分析一下文本词汇的词频分布特征,选取词频占大头的一批词就行了。
例如,在本文的任务中,数据集共涉及到的词汇量有8~9w,这样训练起来会很慢。经过分析,发现大概2w个词就已经覆盖了绝大部分篇幅,所以我就选取词典大小为2w。然后,对文本数值化的时候,那些低频词就直接过滤掉了,只留下高频词。这样,模型训练起来效率就会大大提高。
词向量
如果你接触过词向量,那么一定会想到可以使用词向量吧文本转化成数值类型。不错,我们在本文中也会这么做。但是,如果直接吧文本转化成词向量,输入进模型的话,我们可能无法继续调优(fine-tune),词向量相当于是对文本的特征的一种表示,本身性质已经很好了。但是对于特定任务场景,我们一般都希望可以在训练好的词向量的基础上,继续用对应领域的数据对词向量进一步进行优化。所以,今天我们会探索,如果在加入词向量后,可以接着fine-tune。
②文本数值化,词向量导入的代码
keras自带的文本预处理的工具十分好用。
我们设置词典大小为20000,文本序列最大长度为200.
from keras.preprocessing.text import text_to_word_sequence,one_hot,Tokenizer
from keras.preprocessing.sequence import pad_sequences
import time
vocab_size = 20000
maxlen = 200
print("Start fitting the corpus......")
t = Tokenizer(vocab_size) # 要使得文本向量化时省略掉低频词,就要设置这个参数
tik = time.time()
t.fit_on_texts(X_orig) # 在所有的评论数据集上训练,得到统计信息
tok = time.time()
word_index = t.word_index # 不受vocab_size的影响
print('all_vocab_size',len(word_index))
print("Fitting time: ",(tok-tik),'s')
print("Start vectorizing the sentences.......")
v_X = t.texts_to_sequences(X_orig) # 受vocab_size的影响
print("Start padding......")
pad_X = pad_sequences(v_X,maxlen=maxlen,padding='post')
print("Finished!")上面的代码可以第一次读会比较难理解,这里稍微解释一下:
Tokenizer是一个类,可以接收一个vocab_size的参数,也就是词典大小。设置了词典大小后,在后面生成文本的向量的时候,会把那些低频词(词频在20000开外的)都筛掉。
定义了Tokenizer的一个实例t,然后调用方法t.fit_on_texts(X_orig)的作用,就是把我们所有的预料丢进去,让t去统计,它会帮你统计词频,给每个词分配index,形成字典等等。
想获取index和词的对照字典的话,就使用t.word_index方法。注意,获取字典的时候,不会筛掉那些低频词,是所有词的一个字典。
然后,想把一个句子、段落,转化成对应的index表示的向量怎么办呢?Tokenizer也提供了便捷的方法,不用你自己去慢慢查表,直接使用t.texts_to_sequences(X_orig)方法,就可以获取每句话的index组成的向量表示。注意,这里,就已经吧低频词给过滤掉了,比如一句话有100个词,其中有30个低频词,那么经过这个函数,得到的就是长度为70的一个向量。
得到每个句子的向量后,会发现大家长度各有不同,长的长短的短,这样在后面的RNNs训练时,就不方便批处理。所以,我们还需要对句子进行一个padding(填白,补全),把所有句子弄程统一长度,短的补上0,长的切掉。用的方法就是pad_sequences。
上面代码的输出是:
Start fitting the corpus......
all_vocab_size 88582
Fitting time: 9.10555362701416 s
Start vectorizing the sentences.......
Start padding......
Finished!可以看到,我们2.5w个文本,几百万词,丢进去统计,效率还是挺高的,不到10秒就统计好了。
刚刚说了,获取字典的时候,不会筛掉那些低频词,是所有词的一个字典。但后面我们需要只保留那些高频词的一个字典,所以需要进行这样一个操作,形成一个高频词字典:
import copy
x = list(t.word_counts.items())
s = sorted(x,key=lambda p:p[1],reverse=True)
small_word_index = copy.deepcopy(word_index) # 防止原来的字典也被改变了
print("Removing less freq words from word-index dict...")
for item in s[20000:]:
small_word_index.pop(item[0])
print("Finished!")
print(len(small_word_index))
print(len(word_index))输出:
Removing less freq words from word-index dict...
Finished!
20000
88582词向量的导入:
import gensim
model_file = '../big_things/w2v/GoogleNews-vectors-negative300.bin'
print("Loading word2vec model......")
wv_model = gensim.models.KeyedVectors.load_word2vec_format(model_file,binary=True)这里采用Google发布的使用GoogleNews进行训练的一个300维word2vec词向量。这个读者可以自行去网上下载。如果无法下载,可以到公众号留言申请。
现在,我们需要把这个词向量,跟我们本任务中的词汇的index对应起来,也就是构建一个embedding matrix这样就可以通过index找到对应的词向量了。方法也很简单:
先随机初始化一个embedding matrix,这里需要注意的是,我们的词汇量vocab_size虽然是20000,但是训练的时候还是会碰到不少词不在词汇表里,也在词向量也查不到,那这些词怎么处理呢?我们就需要单独给这些未知词(UNK)一个index,在keras的文本预处理中,会默认保留index=0给这些未知词。
embedding_matrix = np.random.uniform(size=(vocab_size+1,300)) # +1是要留一个给index=0
print("Transfering to the embedding matrix......")
# sorted_small_index = sorted(list(small_word_index.items()),key=lambda x:x[1])
for word,index in small_word_index.items():
try:
word_vector = wv_model[word]
embedding_matrix[index] = word_vector
except:
print("Word: [",word,"] not in wvmodel! Use random embedding instead.")
print("Finished!")
print("Embedding matrix shape:\n",embedding_matrix.shape)通过上面的操作,所有的index都对应上了词向量,那些不在word2vec中的词和index=0的词,词向量就是随机初始化的值。
3.划分训练集和测试集
划分训练集和测试集,当然使用经典的sklearn的train_test_split了。
废话少说,直接上代码:
from sklearn.model_selection import train_test_split
np.random.seed = 1
random_indexs = np.random.permutation(len(pad_X))
X = pad_X[random_indexs]
Y = Y_orig[random_indexs]
print(Y[:50])
X_train, X_test, y_train, y_test = train_test_split(X,Y,test_size=0.2)
print("X_train:",X_train.shape)
print("y_train:",y_train.shape)
print("X_test:",X_test.shape)
print("y_test:",y_test.shape)
print(list(y_train).count(1))
print(list(y_train).count(0))输出:
[0 0 1 0 0 1 0 0 0 1 0 1 0 0 0 1 1 1 0 1 1 0 1 0 1 1 0 0 0 0 0 0 0 0 1 0 1
1 0 1 0 1 1 0 1 0 0 1 1 0]
X_train: (20000, 200)
y_train: (20000,)
X_test: (5000, 200)
y_test: (5000,)
9982
10018训练样本2w,测试样本5k.
唯一值得注意的一点就是,由于前面我们加载数据集的时候,正样本和负样本都聚在一块,所以我们在这里要把他们随机打乱一下,用的就是numpy的random.permutation方法。这些都是惯用伎俩了。
恭喜!您已阅读本文80%的内容!
二、搭建模型跑起来
做完了数据的预处理,后面的东西,就都是小菜一碟了。那么多框架是干嘛的?就是为了让你用尽可能少的代码把那些无聊的事情给做了!Keras尤其如此。
1.模型的结构设计
处理NLP问题,最常用的模型的就是RNN系列,LSTM和GRU随便用。然后,一般还会在前面加一个embedding层。
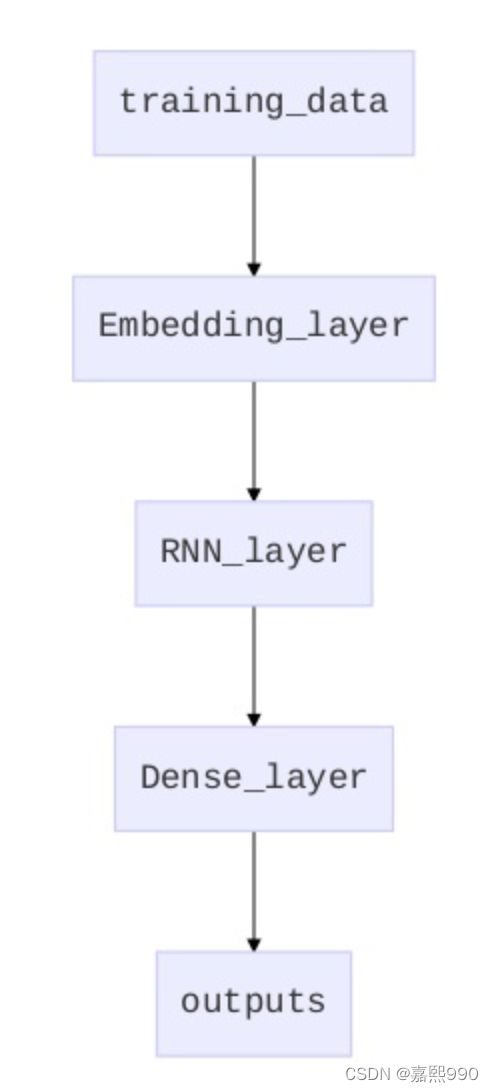
之前我一直以为embedding层就是把预训练好的词向量加进去,实际上不是。即使没有训练好的词向量,我们也可以使用embedding层。因为我们可以用我们的训练数据,来训练出词的embedding,只不过这个embedding不同于word2vec的那种表达词的含义的embedding,更多的是针对特定场景下的一个embedding。(不知道这样说有没有说清楚...)
所以,我们直接配置一个embedding层,不提供词向量都可以训练。如果提供了词向量,这样可以加速我们的训练,相当于我们已经有一个训练好的参数,提供给了模型,模型无非就需要接着改一改即可,而不是从一个随机的状态来慢慢训练。
2. 模型的搭建
Talk is cheap, the code below is also cheap:
import keras
from keras.models import Sequential,Model
from keras.layers import Input,Dense,GRU,LSTM,Activation,Dropout,Embedding
from keras.layers import Multiply,Concatenate,Dot
inputs = Input(shape=(maxlen,))
use_pretrained_wv = True
if use_pretrained_wv:
wv = Embedding(VOCAB_SIZE+1,wv_dim,input_length=MAXLEN,weights=[embedding_matrix]) (inputs)
else:
wv = Embedding(VOCAB_SIZE+1,wv_dim,input_length=MAXLEN)(inputs)
h = LSTM(128)(wv)
y = Dense(1,activation='sigmoid')(h)
m = Model(input=inputs,output=y)
m.summary()
m.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
m.fit(X_train,y_train,batch_size=32,epochs=3,validation_split=0.15)从上面的代码可以知道,想要把预训练的word2vec词向量加入到模型中,就是把词向量作为embedding层的参数(weights),具体我们需要先构建一个embedding matrix,这个我们在前面已经构建好了,然后传进embedding层即可。
运行!输出:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_7 (InputLayer) (None, 200) 0
_________________________________________________________________
embedding_7 (Embedding) (None, 200, 128) 2560128
_________________________________________________________________
lstm_7 (LSTM) (None, 128) 131584
_________________________________________________________________
dense_7 (Dense) (None, 1) 129
=================================================================
Total params: 2,691,841
Trainable params: 2,691,841
Non-trainable params: 0
_________________________________________________________________
Train on 17000 samples, validate on 3000 samples
Epoch 1/3
17000/17000 [==============================] - 178s 10ms/step - loss: 0.6711 - acc: 0.5692 - val_loss: 0.6701 - val_acc: 0.5697
Epoch 2/3
17000/17000 [==============================] - 168s 10ms/step - loss: 0.5964 - acc: 0.6479 - val_loss: 0.5072 - val_acc: 0.7940
Epoch 3/3
17000/17000 [==============================] - 169s 10ms/step - loss: 0.5104 - acc: 0.7171 - val_loss: 0.4976 - val_acc: 0.7943可以发现,参数的大部分,都是embedding层的参数。所以,读者可以尝试一下将词向量参数固定,可以发现训练速度会快得多。但是效果可能会略差一些。
建议读者对比一下:
①不使用word2vec作为embedding的参数
②使用word2vec作为embedding的参数并固定参数
③使用word2vec作为embedding的参数并继续fine-tune
相信会有一些有意思的发现。
但是你可能没时间(~~多半是懒!~~),所以这里我也告诉大家我的实验结果:
①效果最差,时间最长
②效果最好,时间较长
③效果中等,时间最快