【Pytorch神经网络理论篇】 33 基于图片内容处理的机器视觉:目标检测+图片分割+非极大值抑制+Mask R-CNN模型

基于图片内容的处理任务,主要包括目标检测、图片分割两大任务。
1 目标检测
目标检测任务的精度相对较高,主要是以检测框的方式,找出图片中目标物体所在的位置。目标检测任务的模型运算量相对较小,速度相对较快。
1.1 目标检测任务概述
目标检测任务要求模型能检测出图片中特定的目体,并获得这一目标物体的类别信息和位置信息。
在目标检测任务中,模型的输出是一个列表,列表的每一项用一个数组给出检测出的标物体的类别和位置(常用检测框的坐标表示)。
1.2 目标检测任务模型的分类
1.2.1 单阶段(1-stage)检测模型:
主要指直接从图片获得预测结果,也被称为Region-free法。相关的模型有YOLO、SSD、RetinaNet。
1.2.2 两阶段(2-stage)检测模型:
主要指先检测包含实物的区域,再对该区域内的实物进行分类识别,相关模型有R-CNN、Faster R-CNN,Mask R-CNN。
1.2.3 两种分类的对比
单阶段检测模型在分类方面表现出的精度高。
两阶段检测模型在检测框方面表现出的精度高。
2 图片分割:其模型大多数是两阶段
图片分割是指对图中的每个像素点进行分类,适用于对像素理解要求较高的场景。
2.1 图片分割的分类
2.1.1 语义分割
能将图片中具有不同语义的部分分开。
2.1.2 实例分割
能描述出目标物体的轮廓(比检测框更为精细)。
2.2 目标检测+语义分割=实例分割
目标检测:给你一张只有一条狗的图片,输入训练好的模型中(假设模型包含所有类型的狗),不管狗出现在图片中的哪个位置,它都能被检测为狗;给你一张有两条狗的图片,输入网络,会生成两个bbox,均被检测为狗,无法进行个体的区分。
语义分割:对所有像素进行分类,图片中只要出现狗,都会被分为一类,同样无法进行个体的区分。
实例分割:在所有不同类的狗的像素都被分类为狗的基础上,对不同类的狗进行目标定位,再给上狗1和狗2的标签,这就是实例分割。

3 非极大值抑制算法(Non-Max Suppression,NMS)
3.1 非极大值抑制算法的作用
在目标检测任务中,通常模型会从一张图片中检测出很多个结果,其中很有可能会出现重复物体(中心和大小略有不同)的情况。为了确保检测结果的唯一性,需要使用非极大值抑制算法对检测结果进行去重。
3.2 非极大值抑制算法的实现过程
1、从所有的检测框中找到置信度较大(置信度大于某个圆值)的检测框。
2、逐一计算其与剩余检测框的区域面积的重叠率(IOU)。
3、按照IOU阈值过滤。如果IOU大于一定阈值,则将该检测框剔除。
4、对剩余的检测框重复上述过程,直到处理完所有的检测框。
在整个过程中,用到的置信度阈值与lOU阈值需要提前给定。
3.3 IOU的概念(Intersection-over-Union)
IOU是交并比是目标检测中使用的一个概念是产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率,即它们的交集与并集的比值。最理想情况是完全重叠,即比值为1。在多目标跟踪中,用来判别跟踪框和目标检测框之间的相似度。

4 Mask R-CNN模型
MaskR-CND模型属于两阶段检测模型,即该模型会先检测包含实物的区域,再对该区域内的实物进行分类识别。
4.1 检测实物区域的步骤
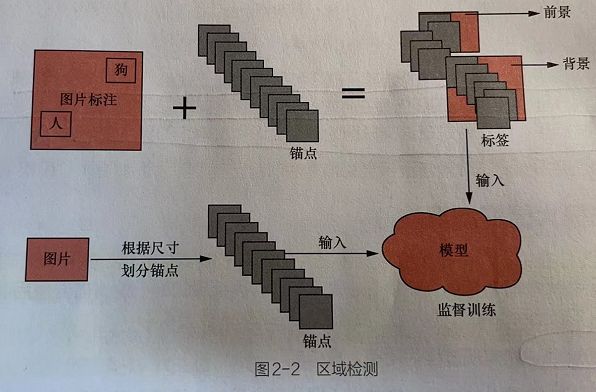
- 1、按照非极大值抑制算法将一张图片分成多个子框。这些子框被称作描点(Anchor),锚点是不同尺寸的检测框,彼此间存在部分重叠。
- 2、在图片中对具体实物进行标注其坐标(所属的位置区域)。
- 3、根据实物标注的坐标与锚点区域的IOU,计算出前景与背景。计算规则为IOU高的就是前景,IOU低的就是背景,其余的就忽略。
- 4、根据第3步结果中属于前景的锚点坐标和第2步结果中实物标注的坐标,算出二者的相对位移和长宽的缩放比例。
- 5、最终,检测区域的任务会被转化成一堆锚点的分类(前景和背景)和回归任务(偏移和缩放)。
4.1.2 区域检测图解
如图2-2所示,每张图片都会将其自身标注的信息转化为与锚点对应的标签,让模型已有的锚点进行训练或识别。
4.2 区域生成网络
在MaskR-CNN模型中,实现区域检测功能的网络被称作区域生成网络(Regon Proposal Network,RPN)。
4.3 感兴趣区域
在实际处理过程中,会从RPN的输出结果中选取前景概率较高的一定数量的锚点作为感兴趣区域(Region of Interest,ROI),送到第2阶段的网络中进行计算。
4.4 Mask R-CNN模型的完整步骤
4.4.1 Mask R-CNN模型的架构
4.4.2 Mask R-CNN模型的完整步骤
1、提取主特征,这部分的模型又被称作骨干网络。它用来从图片中提取出一些不同尺寸的重要特征,通常用于一些预训练好的模型(如VGG模型、Inception模型、ResNet模型等)。这些获得的特征数据被称作特征图。
2、特征融合;用特征金字塔网络(FeaturePyramid Network,FPN)整合骨干网络中不同尺寸的特征。最终的特征信息用于后面的RPN和最终的分类器(classifer)网络的计算。
3、提取ROI:主要通过RPN来实现。RPN的作用是,在众多锚点中计算出前景和背景的预测值,并计算基于锚点的偏移,然后对前景概率较大的ROI用非大值抑制算法实现去重,并从最终结果中取出指定个数的ROl用于后续网络的计算。
4、ROI池化:使用区域对齐的方式实现。将第2步的结果当作图片,按照ROl中的区域框位置从图中取出对应的内容,并将形状统一成指定大小,用于后面的计算。
5、最终检测:对第4步的结果依次进行分类、设置矩形坐标、实物像素分割处理,得到最终结果。