mysql学习之mysql集群
文章目录
-
-
- 单节点数据库服务问题
- mysql集群方案
-
- 主从架构
- 主从+Keepalived
- 高可用架构(扩展)
- 总结
- 复制方式的分类
-
- 基于语句的复制
- 基于行的复制
- 总结
- 数据同步原理
- 集群搭建
-
- 搭建主库
- 搭建备库
- 数据同步验证
-
单节点数据库服务问题
单个数据库服务器的缺点
-
数据库服务器存在单点问题;
-
数据库服务器资源无法满足增长的读写请求;
-
高峰时数据库连接数经常超过上限。
如何解决单点问题
-
增加额外的数据库服务器,组建数据库集群;
-
同一集群中的数据库服务器需要具有相同的数据;
-
集群中的任一服务器宕机后,其它服务器可以取代宕机服务器。
mysql集群方案
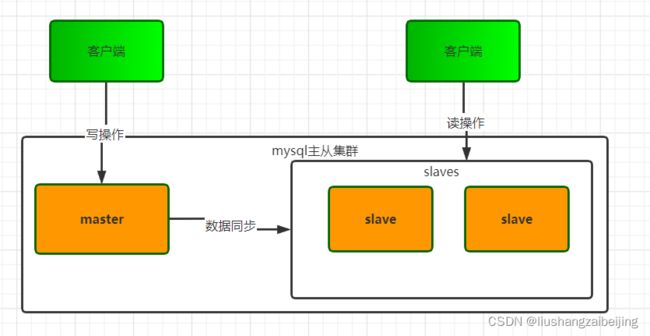
主从架构
mysql主从架构部署比较简单,常见架构根据主从节点个数不同分成 一主多从,多主一从,双主节点等。
一主多从的主从复制数据库集群架构师最基本也是最常用的一种架构部署,能够满足很多业务需求。本篇博文主要针对该架构进行实操。
优点:
- 数据存在多个镜像和数据冗余,可以防止单一主机的数据丢失,提高数据的安全性。
- 如果使用mysql proxy,在业务上可以实现读写分离。即可以把一些读操作在从服务器上执行,减小主服务器的负担。
- 在从服务器上做数据备份,这样不影响主服务器的正常运行。
- 从服务器可以使用不用的存储引擎,从库上的数据表建立不同的索引,适用不同的业务场景。
缺点
基于mysql主从数据同步方式(异步复制和Mysql5.7新增的半同步复制)会出现数据不一致的问题
主从+Keepalived
高可用架构(扩展)
上述主从架构,master宕机无法进行故障转移。再此基础上可能需要使用引入三方组件来保证服务的高可用。
比如:lVS负载、HaProxy、keepalive等组件。基于上述组件加持的高可用架构有如下解决方案
- LVS+Keepalived+MySQL(有脑裂问题?但似乎很多人推荐这个)
- DRBD+Heartbeat+MySQL(有一台机器空余?Heartbeat切换时间较长?有脑裂问题?)
- MySQL Proxy(不够成熟与稳定?使用了Lua?是不是用了他做分表则可以不用更改客户端逻辑?)
- **MySQL Cluster **(社区版不支持INNODB引擎?商用案例不足?)
- MySQL + MHA(Haproxy)(如果配上异步复制,似乎是不错的选择)
- MySQL + MMM(MMM即Multi-Master Replication Manager for MySQL) (mysql多主复制管理器,基于perl实现,关于mysql主主复制 配置的监控、故障转移和管理的一套可伸缩的脚本套件)
上述高可用架构先埋个坑,有时间再去学习。
总结
对于上述两大类集群架构都涉及到了集群中的多节点数据同步问题,涉及到同步问题需要了解mysql数据复制的类型和数据同步原理。
复制方式的分类
Mysql中支持两种复制方式:基于行的语句的复制(逻辑复制)和基于行的复制。
基于语句的复制
在Mysql5.0之前的版本中只支持基于语句的复制,主库会记录那些造成数据更改的SQL语句,当备库读取并重放这些事件时把主库上执行过的SQL再执行一遍。
优点
- 简单,理论上只需要记录和执行这些SQL语句即可。
- 另一个好处是记录在bin log 文件里的事件比较紧凑不会使用太多的带宽该方式占用存储空间少。
缺点
- 可能存在无法正确复制SQL的现象,同时SQL执行的开销可能会比较大。
- 更新必须是串行的,另外并不是所有的存储引擎都支持这种复制方式。
基于行的复制
Mysql 5.1开始支持基于行的复制,这种方式也是将实际数据记录到二进制日志当中,只不过在复制的过程中是一行一行来复制。
优点
他的优点就是可以正确的复制每一行,效率更高。如果是使用基于语句的复制模式,在备库更新一个不存在的记录时不会失败,但是基于行的复制模式下则会报错并停止复制。
总结
这两种方式没有哪一种是完美的,MySQL可以在这两种复制模式间动态的切换,默认情况下都是使用的基于语句的复制方式,但是如果发现语句无法被正确的复制,就切换到行的复制模式。
数据同步原理

如上图,从数据库备份主库数据分成三步。
**1. 主库开启bin-log日志: ** 主库需要设置开启记录二进制日志,提交数据更新的事务之前将更新的事件记录都二进制日志中,后才进行事务提交。
**2. 备库建立IO线程连接: ** 备库创建IO线程与主库创建连接,主库上启动一个binlog-dump线程。该线程会读取主库二进制事件,该线程不会对事件进行轮询。如果从库数据与主库已经保持一致后,该线程进入休眠状态,一旦主库有新事件会以信号量唤醒binlog-dump线程。备库IO线程会将事件写入到中继日志(relay-log)中。
**3. SQL线程重放数据:**SQL线程执行最后一步,从中继日志中获取事件并在备库中执行,从而实现数据库的更新。
上述复制模式下:获取主库二进制事件,重放备库事件两者是解耦异步进行的。互不影响。
,Master在写数据时(DML命令)会产生一个bin log(Binary Log),Slave开一个IO线程从指定偏移处去读取bin log,读回来后生成Relay Log,再开一个SQL线程"重放"数据来完成同步。
优点
- 读写分离,增加整体性能
- 部署简单,维护方便
缺点
- 无故障转移,Master挂了整个集群只能读取不能写入,需要引入其他的高可用机制
- 数据存在一致性问题,因为异步,所以Slave的数据一定不是最新的,需要等待一个时间窗后才能读取
- Slave过多时Slave对Master的负载以及网络带宽都会成为一个严重的问题
半同步复制
异步复制在主库崩溃,一部分数据没来得及同步到从库,从库切换为主库后,出现数据不一致情况。所以在MySQL 5.5版本中引入了半同步复制,半同步复制的关键改进就是当客户端在 主库上写入一个事务时,需要等待从库接收到主库的binlog,且主库接收到ACK确认之后,客户端才能收到事务成功提交的消息。
集群搭建
本篇文章使用docker搭建mysql主从集群,一主一从模式
#创建mysql主从集群 根目录
mkdir -p /home/mysql-ms
搭建主库
配置信息
my.cnf 配置信息 放入下图目录中的conf目录下
[mysqld]
## 必填参数 该mysql服务节点的唯一标识
server_id=2
## 必填参数 开启bin-log日志
log_bin = mysql-bin
## 选填参数 bin-log复制模式 混合模式复制
binlog_format = MIXED
## 选填参数 日志超过30天清除
expire_logs_days = 30
启动master服务
#创建主库文件
mkdir -p /home/mysql-ms/mysql-master/log
mkdir -p /home/mysql-ms/mysql-master/data
mkdir -p /home/mysql-ms/mysql-master/conf
## 指定mysql配置和数据存储地址 启动
docker run --name mysql-master -p 3310:3306 -v /home/mysql-ms/mysql-master/log:/var/log/mysql -v /home/mysql-ms/mysql-master/data:/var/lib/mysql -v /home/mysql-ms/mysql-master/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
创建复制账号
因为从库的IO线程需要建立与主库的TCP/IP连接用于将二进制日志复制到从库中继日志中。mysql要赋予一些特殊的权限给复制线程
#进入容器内部
docker exec -it 容器id /bin/sh
#登录mysql服务
mysql -uroot -p123456
#主库建立对应的复制用户(仅限于访问主库对应的ip)
grant replication slave, replication client on *.* to 'userName'@'主库ip' identified by 'password';
# 保存权限
flush privileges;
#查看mysql服务bin-log 开启状态
show master status;

搭建备库
配置信息
my.cnf 配置信息 放入下图目录中的conf目录下
[mysqld]
## 必填参数 该mysql服务节点的唯一标识
server_id=3
## 选填参数 开启二进制日志功能,以备Slave作为其它Slave的Master时使用
log_bin = mysql-bin
log_slave_updates = 1
## 选填参数 配置中继日志
relay_log = /home/mysql-ms/mysql-slave/log/relay-bin
## 设置为只读,该项如果不设置,表示slave可读可写
read_only=1
启动salve服务
#创建主库文件
mkdir -p /home/mysql-ms/mysql-slave/log
mkdir -p /home/mysql-ms/mysql-slave/data
mkdir -p /home/mysql-ms/mysql-slave/conf
## 指定mysql配置和数据存储地址 启动
docker run --name mysql-slave -p 3311:3306 -v /home/mysql-ms/mysql-slave/log:/var/log/mysql -v /home/mysql-ms/mysql-slave/data:/var/lib/mysql -v /home/mysql-ms/mysql-slave/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
从库与主库建立关系
##语法
change master to master_host='自己的IP地址', master_user='用于复制的用户名', master_password='密码', master_port=master节点端口, master_log_file='master节点对应的binlog文件', master_log_pos=master节点对应的binlog文件偏移量;
change master to master_host='127.0.0.1', master_user='reply', master_password='123456', master_port=3310, master_log_file='mysql-bin.000003', master_log_pos=931;
进入备库对应的mysql服务,使用show slaves status 查看备库状态

# 启动从节点
START SLAVE;

数据同步验证
在主库中创建demo数据库,创建user表,插入数据,均同步到了从库。
CREATE DATABASE `demo`
USE `demo`;
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(50) DEFAULT NULL COMMENT '姓名',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=latin1;
insert into `user`(`id`,`name`) values (1,'TOM');
