PaddleOCR数字仪表识别——2.数据合成及数据集制作
文章目录
- 1. 数据合成工具
-
- 1.1 text_renderer
-
- 1.1.1 尝试使用
-
- 1.1.1.1 配置过程
- 1.1.1.2 示例结果
- 1.1.1.3 研究提供的example
- 1.1.2 自己使用
-
- 1.1.2.1 简化文件结构
- 1.1.2.2 替换自己的内容
- 1.1.2.3 确定数据集格式
- 1.1.2.4 产数字图片
- 1.2 text_renderer工具总结
- 1.3 修改labels.json格式
-
- 1.3.1 制作测试集和训练集
- 1.3.2 制作字典
- 2. 数据收集
-
- 2.1 常见通用数据集
-
- 2.1.1 PaddleOCR整理的
- 2.1.2 深度实践OCR-基于深度学习的文字识别这个书整理的
- 2.2 专门的数字数据集
- 3. 数据标注工具
-
- 3.1 roLabelImg
- 4. 制作的数据集
1. 数据合成工具
PaddleOCR提供了许多数据合成工具:
https://github.com/PaddlePaddle/PaddleOCR/blob/develop/README_ch.md

也就是说这些数据合成工具其实也是百度从别的地方找的,做了个整合的目录,第一个应该是最推荐的。
1.1 text_renderer
只能用来产生 文字识别(不是文字检测 定位)的图片
(产出的是很小很精确的只有文字部分的图片,灰度图)
text_renderer是最常用的也是目前看起来效果比较好的:
https://github.com/Sanster/text_renderer,新的项目地址(它搬家啦,O(∩_∩)O)https://github.com/oh-my-ocr/text_renderer
相关参考文献:(2019年才有的项目,很新,目前使用的人比较少,我也算是先驱呀,哈哈哈)
- 知乎-CV学习笔记(十八):文本数据集生成(text_renderer)
- 知乎-CV学习笔记(十九):数据集拼接生成
- github二次开发的-有些示例
- 官方-Text Renderer文档
github上的介绍:
生成用于训练深度学习OCR模型(例如CRNN)的文本图像。 例
- 模块化设计。 您可以轻松地添加语料库,效果,布局。
- 支持生成与
PaddleOCR兼容的lmdb数据集,请参阅数据集(所以这是paddleOCR团队开发的工具?) - 支持在背景图上渲染有不同字体,字体大小以及字体颜色的语料,布局用来调节多个语料之间的布局
- 暂不支持产生垂直文字
- 暂不支持 语料采样器:用于进行字符平衡
1.1.1 尝试使用
先随便用一下,看一下大致效果,然后再决定要使用什么字体和什么样的背景图。在windows上使用
1.1.1.1 配置过程
git clone https://github.com/oh-my-ocr/text_renderer
cd text_renderer # 自己换个文件夹
python3 setup.py develop
pip3 install -r docker/requirements.txt
# windows下 是 docker\requirements.txt(因为发现如果是 / 的话,按tab键没有提示)
# 然后就会开始安装了
# 第一个要安装的就是 opencv-python==3.4.5.20 注意这个多一点,因为之后很有可能产生版本冲突。
python3 main.py \
--config example_data/example.py \
--dataset img \
--num_processes 2 \
--log_period 10
1.1.1.2 示例结果
我实际在我的windows环境中执行的是
> python3 main.py --config example_data\example.py --dataset img --num_processes 2
--log_period 10
然后大概显示以下内容
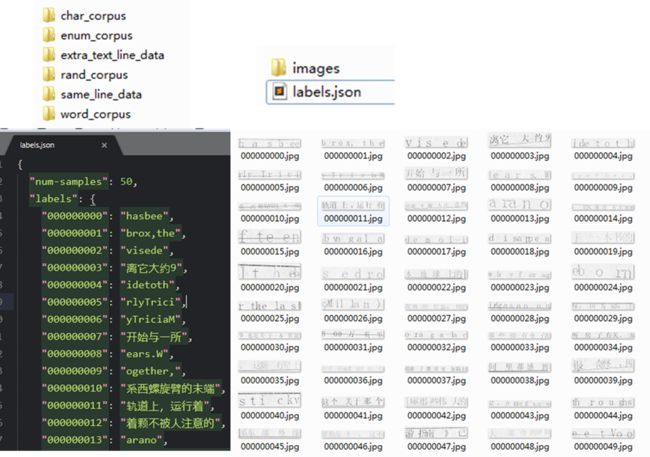
然后就可以在example_data/output里看到产生的图片了,大致给几个示例:
打开后可以看到,产生了好几个类型的图片语料,打开后会看到 图片及标记文件,看起来还不错。
1.1.1.3 研究提供的example
text_renderer提供的官方文档里没有一个很具体的例子,所以还是要稍微研究下的。
- 文件结构很明晰

- 调用参数说明,main.py脚本只有4个参数,分别是:
- config:python配置文件路径
- dataset: 数据集格式
img/imdb - num_processes: 使用的进程数量
- log_period: 日志打印时间 (0, 100)。(PS:上面的是10,意思是进度每完成10%打印一次)
1.1.2 自己使用
1.1.2.1 简化文件结构
配置过程其实有些复杂了,但是看调用过程,其实也就是几个.py文件,找个文件夹存一下,以后直接调用,用命令行调用不适合在代码里配置,想办法改成可以直接代码调用的,而不是在pycharm里配置参数/命令行运行。(毕竟要做成一个pipeline)
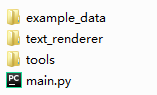
其实真的使用的时候只用到上面这四个内容,其中 main.py和example_data可以换成自己的代码以及相关内容,tools文件夹里放着lmdb2img.py用于转换文件标记类型。
所以真的有用的代码其实就只有 text_renderer这个文件夹(不需要调试的话,什么文档提示之类的,就只把这一个文件夹放到根目录就可以了)
1.1.2.2 替换自己的内容
很明显,给出的示例是针对场景文字识别这种通用场景的,我的主要需求是数字(电子仪表数字图片的生成),所以字体和背景图都要进行替换。
大致自己的需求(通用的工业数字仪表识别模型,你没见过的不代表人家没有这个需求):
- 字体类型要多一些
- 背景类型要更多:灰黑的还是比较多的类型
- 字体颜色可能也会多样:灰黑的,黄色的,紫色的,白色的
- 注意:
- 比较严重的一个问题是:有时候不显示字的时候,本身数字部分的内容就有数字底色。类似下面这个图,本身数字不显示的时候,仪表盘本身就有灰色底色的数字显示(这个要怎么分辨。。。),不过还好,这个目前只有这种颜色的底色,其他倒是没什么

- 另一个问题是:小数点的问题,不过我们的场景里 小数点的位置是卡死的,但是如果涉及到通用场景,这个小数点就比较尴尬(像上面这个图,这个小数点是每个数字后面都有,如何识别咧。)
- 比较严重的一个问题是:有时候不显示字的时候,本身数字部分的内容就有数字底色。类似下面这个图,本身数字不显示的时候,仪表盘本身就有灰色底色的数字显示(这个要怎么分辨。。。),不过还好,这个目前只有这种颜色的底色,其他倒是没什么
1.1.2.3 确定数据集格式
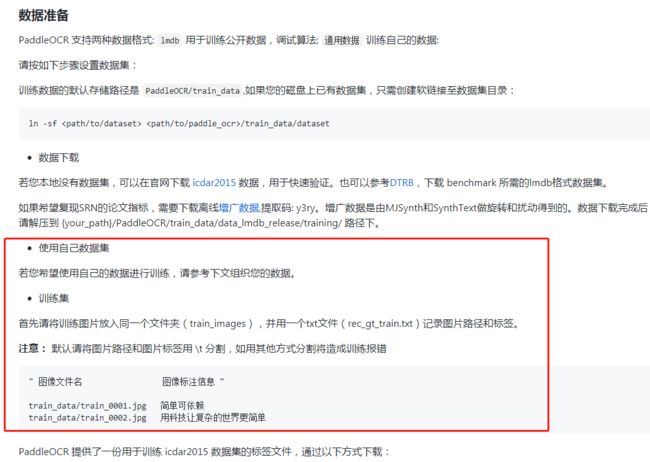
可以直接去根据icdar2015 Incidental Scene Text的链接注册个账号下载
其实文件也不是很大,下完之后根据官网提示:
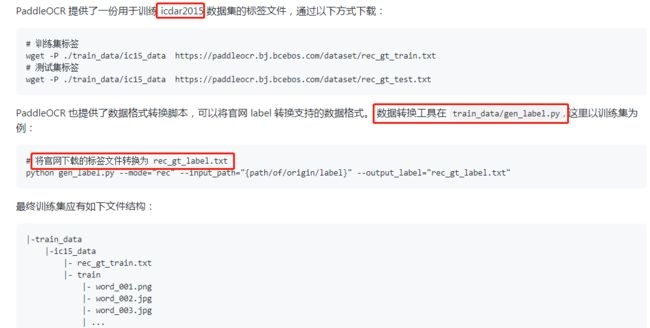
train_data/gen_label.py文件其实挺简单的,自己也可以照着写一个
这里给出原始的标签文件(第一个图)和转换后的标签文件的样子,大概看看什么样:

注意:后面的网址可以直接放到浏览器打开,就可以看到了
# 训练集标签
wget -P ./train_data/ic15_data https://paddleocr.bj.bcebos.com/dataset/rec_gt_train.txt
# 测试集标签
wget -P ./train_data/ic15_data https://paddleocr.bj.bcebos.com/dataset/rec_gt_test.txt
其实就是保证
重新跑一次示例demo,看一下lmdb格式产出来的标签文件是什么样的,再决定使用哪个去修改
python main.py --config example_data\example.py --dataset imdb --num_processes 2
--log_period 10
python main.py --config example_data\example.py --dataset img --num_processes 2
--log_period 10
直接报错了,而且产出的文件很奇怪,是 .mdb(Access数据库格式???)

放弃,这样看来只能使用 img格式来产了
1.1.2.4 产数字图片
这里涉及到四个参数中的dataset,因为是要使用PaddleOCR,所以要去看PaddleOCR用的是什么格式,虽然text_render也提供了一个tools->imdg2img的格式来完成这两者之间的转换,但是 毕竟还是一步到位比较好。
- config:python配置文件路径
- dataset: 数据集格式
img/imdb - num_processes: 使用的进程数量
- log_period: 日志打印时间 (0, 100)。
根据一个已经close的issue,关于产生图片txt标签 下的Q&A,
可知控制生成数据集标签文件的脚本是:text_renderer/text_renderer/dataset.py /这个文件,查看文件内容,感觉可以自己改改,生成要的那个 txt格式文件???
python main.py --config example_data\example.py --dataset img --num_processes 2 --log_period 10
产出的结果里每种类别都只有50张图,而且是每个文件夹中的图片独立编号,所以先试试一个类别产700张试试吧。
查看那个example.py文件,写得还是比较清晰的,关键修改的位置 对照着文档text_renderer-document看,其实很容易看懂
PerspectiveTransform 透视变换,也可以考虑加入其它的变换
这里注意:在 RenderCfg类中设置的text_color_cfg (TextColorCfg) –如果非空,则会覆盖CorpusCfg中设置的 text_color_cfg 。 可以看到,CorpusCfg其实是真正操控产生字体形式的类, EnumCorpusCfg继承自CorpusCfg,
但是感觉对颜色类的修改很单一啊,源码里关于颜色部分只有一点点,
露个口子是让我们自己写吗。。。。可以看到返回值是个元组,而且只有一个值。。。就是随机使用背景图的平均值,直接传递(r,g,b,alpha)四元组, 报错
根据github上issue,如果想实现反转颜色的功能,可以直接添加一个Effect并设置为RenderCfg. render_effects 注意,保存的图片一定是gray,所以加彩色也白搭。。。
But it's easy to do this by adding a Effect and set as RenderCfg. render_effects.
加了之后报错,算了。
背景还是尽量找亮色的吧,不然产出来的图 字的颜色和背景图有时候区分不开。
1.2 text_renderer工具总结
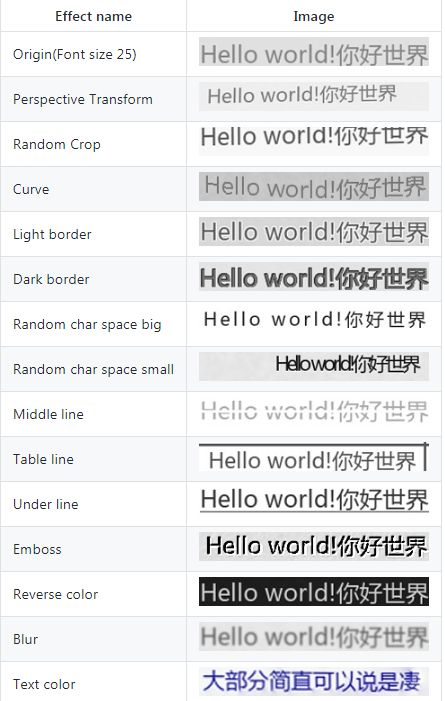
text-renderer早期的版本是支持很多种effect的,但是改版后,作者认为有些操作最好使用数据增强的方式来做,所以删除了很多effect,可以看到,早期版本是支持颜色修改的
现在的版本,effect就只有下面这几个。。
虽然issue中回答给了一个说法,但是不能用,哈哈哈。
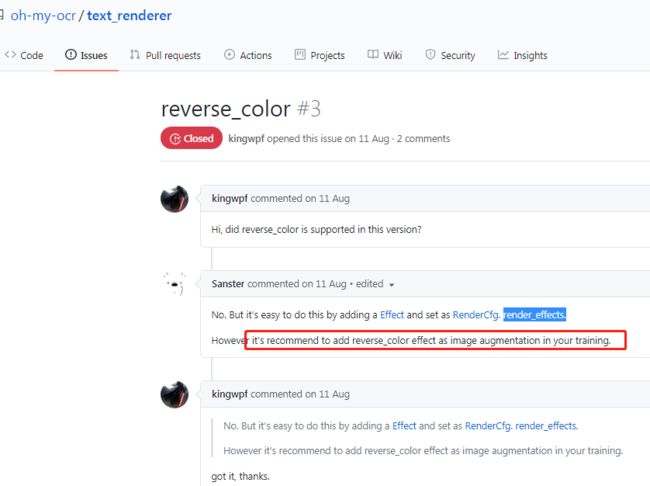
所以下次如果还要用的话,看自己的需求决定使用老版本还是新版本吧。
1.3 修改labels.json格式
1.3.1 制作测试集和训练集
由于PaddleOCR对使用的预训练数据集的标记格式有要求,所以这里要重新处理一下。
根据PaddleOCR文档中自定义数据集部分
暂时只使用直接使用text_renderer产生的800张图片来训练(可以考虑使用数据增强,反正标签不变。。。)
首先请将训练图片放入同一个文件夹(train_images),并用一个txt文件(rec_gt_train.txt)记录图片路径和标签。
注意: 默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。(PaddleOCR默认文件目录下有一个 train_data文件夹,正常刚下载下来,里面只含有一个叫 gen_label.py的脚本)
" 图像文件名 图像标注信息 "
train_data/train_0001.jpg 简单可依赖
train_data/train_0002.jpg 用科技让复杂的世界更简单
反正都是独立编号,完全可以使用text_renderer产两次,第一次800张训练集,第二次200张测试集,都分别进行label转换就好了,训练集和测试集中的数据路径

这里其实写路径的时候,和配置文件相关的,以官方提供的rec_icdar15_train.yml这个配置文件为例,里面有一项是:
reader_yml: ./configs/rec/rec_icdar15_reader.yml
在rec_icdar15_reader.yml文件里,可以看到以下内容(这里就给出了训练文件的路径,所以不管上面的数据集里路径怎么弄的,只要在这个文件里配置相容就可以了。不是死的)
TrainReader:
reader_function: ppocr.data.rec.dataset_traversal,SimpleReader
num_workers: 8
img_set_dir: ./train_data/ic15_data
label_file_path: ./train_data/ic15_data/rec_gt_train.txt
EvalReader:
reader_function: ppocr.data.rec.dataset_traversal,SimpleReader
img_set_dir: ./train_data/ic15_data
label_file_path: ./train_data/ic15_data/rec_gt_test.txt
TestReader:
reader_function: ppocr.data.rec.dataset_traversal,SimpleReader
从 配置文件说明: PaddleOCR/doc/doc_ch/config.md里面可以知道,一般XXXX_train.yml文件中会有以下选项:

XXXX_train.yml中有一项是另一个配置文件的路径。。。。(写在一个里面不好?单独分出来容易修改?好像也是)
所以仿照给出的路径,我最后的文件夹结构应该是:
|- train_data
|- train.txt
|- train
|- word_001.jpg
|- ..
|- test.txt
|- test
|- word_001.jpg
|- ..
不确定本机能不能训练的动,服务器上没有GPU。。。
1.3.2 制作字典
根据ppocr/utils/ic15_dict.txt 是一个包含36个字符的英文字典,,去查看相应的文件:PaddleOCR/ppocr/utils/ic15_dict.txt,大致内容:
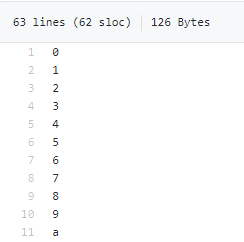
文件内容格式OK,关于文件存放位置
- 自定义字典
如需自定义dic文件,请在 configs/rec/rec_icdar15_train.yml 中添加 character_dict_path 字段, 指向您的字典路径。 并将 character_type 设置为 ch。 - 添加空格类别
如果希望支持识别"空格"类别, 请将yml文件中的 use_space_char 字段设置为 true。
注意:use_space_char 仅在 character_type=ch 时生效
其实在我的使用场景里,无关中英文,因为只使用数字。
2. 数据收集
由于直接造数字图片训练出来的模型在应用场景图片上的效果不是很好,所以还是需要收集一些真实场景的数字图片。
其实文本检测已经可以很准确的找到文本/数字的位置了,所以我只需要找一些有数字的图片,改进文本识别的效果。
2.1 常见通用数据集
2.1.1 PaddleOCR整理的
PaddleOCR收集了一些通用的数据集,通用中英文OCR数据集
- ICDAR2019-LSVT
- ICDAR2017-RCTW-17
- 中文街景文字识别
- 中文文档文字识别
- ICDAR2019-ArT
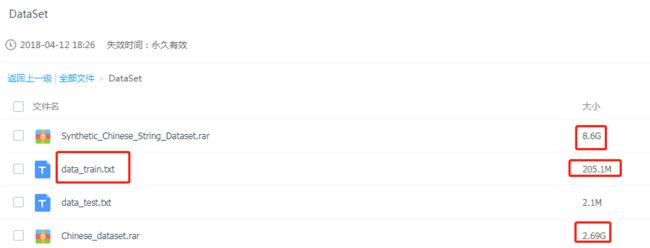
其中我觉得最接近我使用的应该是 中文文档文字识别,这个数据集其实来自另一个github上的ocr项目,https://github.com/YCG09/chinese_ocr,但是数据集太大了,共约364万张图片,图片分辨率统一为280x32(虽然每张图很小,但是抵不住量多啊)
数据集:https://pan.baidu.com/s/1QkI7kjah8SPHwOQ40rS1Pw (密码:lu7m)
2.1.2 深度实践OCR-基于深度学习的文字识别这个书整理的
https://github.com/ocrbook/ocrinaction/tree/master/chapter-5

2.2 专门的数字数据集
主要还是互联网搜索,大致的关键字是 seven segment digital datasets:
-
论文的数据集(以前听说过很多论文会公开自己的数据集,但是毕竟是少数,所以这个算是意外惊喜吧):
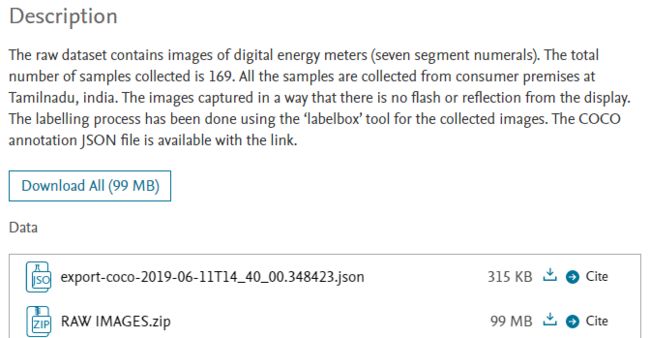
- 论文:Text detection and recognition in raw image dataset of seven segment digital energy meter display
- 数据集地址:Data for: Text detection and Recognition in Raw Image Dataset of Seven Segment Digital Energy Meter Display,感谢mendeley
-
github上的:https://github.com/SachaIZADI/Seven-Segment-OCR 不是我需要的(给的是多种类型的10个数字的图片)

-
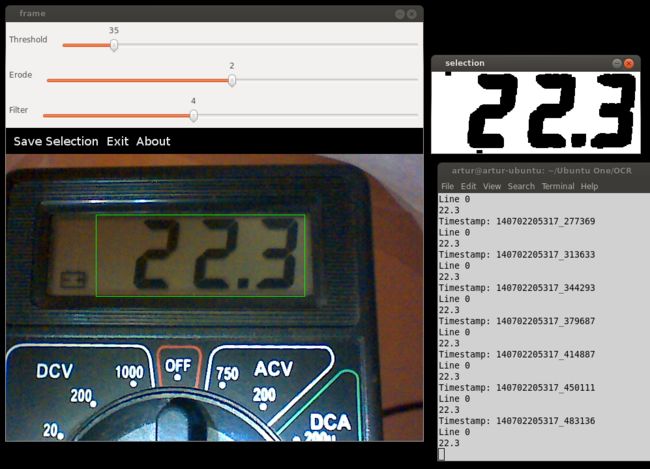
github上的:https://github.com/arturaugusto/display_ocr
-
XXXXX 啥都不是,竟然是c的代码,起个这样的名字,无语。。。LED Display Domain Data Set - UCI Machine Learning .

-
中文也搜了一波,没有发现更多了,就用找到的那个论文里的吧,做一下数据增强,也可以用,哈哈
3. 数据标注工具
3.1 roLabelImg
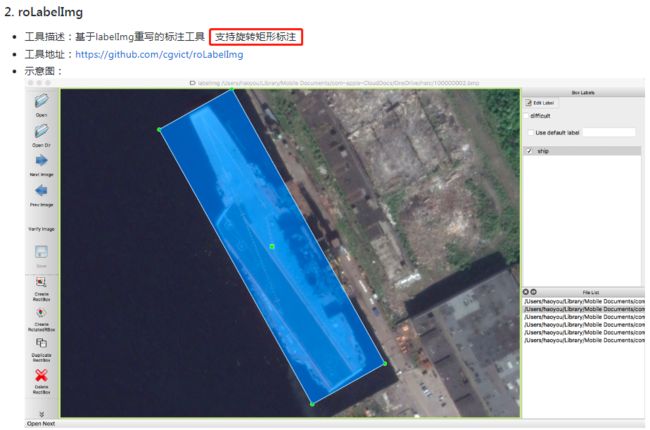
除了常见的labelme和labelimg,vott,以及后来配置服务端的CVAT,还有一个从PaddleOCR中数据标注工具上看到的
数据标注工具 这个文档里提到的: 支持旋转矩形标注 (这个感觉对标注ocr数字图像识别很有用啊)
4. 制作的数据集
百度网盘链接:
链接:https://pan.baidu.com/s/179X4c6JqAtR1VvQYON71sQ
提取码:r9b3
复制这段内容后打开百度网盘手机App,操作更方便哦
里面有两个小的数据集,都已经分为了测试和训练集,类似: