深度学习模型保存_解读计算机视觉的深度学习模型
作者 | Dipanjan(DJ)Sarkar
来源 | Medium
编辑 | 代码医生团队
介绍
人工智能(AI)不再仅限于研究论文和学术界。业内不同领域的企业和组织正在构建由AI支持的大规模应用程序。这里要考虑的问题是,“我们是否相信AI模型做出的决策?”和“机器学习或深度学习模型如何做出决策?”。解释机器学习或深度学习模型一直是整个数据科学生命周期中经常被忽视的任务,因为数据科学家或机器学习工程师会更多地参与实际推动生产或建立和运行模型。

但是除非正在构建一个有趣的机器学习模型,否则准确性并不是唯一重要的!业务利益相关者和消费者经常会问到用于解决现实问题的任何机器学习模型的公平性,问责制和透明度等难题!

在本文中,将研究用于解释计算机视觉中使用的深度学习模型的概念,技术和工具,更具体地说 - 卷积神经网络(CNN)。将采用实践方法,使用Keras和TensorFlow 2.0实现深度学习模型,并利用开源工具来解释这些模型所做出的决策!简而言之本文的目的是找出 - 深度学习模型真正看到了什么?
卷积神经网络
用于计算机视觉问题的最流行的深度学习模型是卷积神经网络(CNN)!
资料来源:Becomehuman.aiCNN通常由多个卷积和池化层组成,这有助于深度学习模型从图像等可视数据中自动提取相关特征。由于这种多层架构,CNN学习了强大的特征层次结构,即空间,旋转和平移不变。
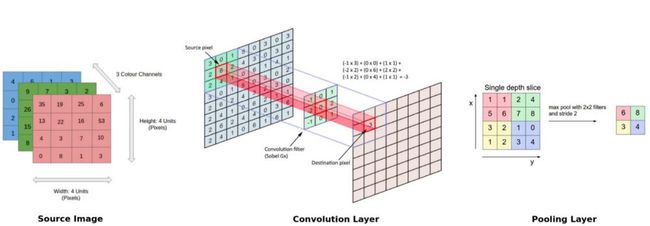
CNN模型中的关键操作如上图所示。任何图像都可以表示为像素值的张量。卷积层有助于从该图像中提取特征(形成特征图)。网络中的较浅层(更接近输入数据)学习非常通用的特征,如边缘,角落等。网络中更深的层(更靠近输出层)学习与输入图像有关的非常具体的特征。下图有助于总结任何CNN模型的关键方面。

由于只关心CNN模型如何感知图像,因此不会从头开始训练任何CNN模型。相反将在示例中利用迁移学习的功能和预先训练的CNN模型。

像VGG-16这样的预训练模型已经在具有大量不同图像类别的大型数据集(ImageNet)上进行了预训练。考虑到这一事实,该模型应该已经学习了强大的功能层次结构。因此该模型已经学习了属于1,000个不同类别的超过一百万个图像的特征的良好表示,可以作为适合于计算机视觉问题的新图像的良好特征提取器。
解读CNN模型 - 深度学习模型真正看到了什么?
这是有趣的部分,真的可以通过一个看似黑盒子的CNN模型来解除呈现的不透明度,并尝试理解幕后真正发生的事情以及模型在看到图像时真正看到了什么?有许多技术和工具可用于解释基于视觉的深度学习模型所做出的决策。本文中介绍的一些主要技术如下所示。

看看这些技术中的每一种,并解释一些使用Keras和TensorFlow构建的基于CNN的深度学习模型。
SHAP Gradient Explainer
这种技术试图结合来自Integrated Gradients,SHapley Additive exPlanations(SHAP)和SmoothGrad的众多想法。该技术试图使用预期梯度(集成梯度的扩展)来解释模型决策。这是一种功能归因方法,专为基于Shapley值扩展到无限玩家游戏的可微模型而设计。将在此处使用此框架来实现此技术。
https://github.com/slundberg/shap
集成梯度值与SHAP值略有不同,需要单个参考值进行集成。然而在SHAP Gradient Explainer中,预期梯度将积分重新表示为期望,并将该期望与来自背景数据集的采样参考值相结合。因此该技术使用整个数据集作为背景分布而不是单个参考值。尝试在一些示例图像上实现这一点。首先加载一些基本依赖项和模型可视化函数实用程序。
import kerasfrom keras.applications.vgg16 import VGG16from keras.applications.vgg16 import preprocess_input, decode_predictionsfrom matplotlib.colors import LinearSegmentedColormapimport numpy as npimport shapimport keras.backend as Kimport json shap.initjs() # utility function to visualize SHAP values in larger image formats# this modifies the `shap.image_plot(...)` functiondef visualize_model_decisions(shap_values, x, labels=None, figsize=(20, 30)): colors = [] for l in np.linspace(1, 0, 100): colors.append((30./255, 136./255, 229./255,l)) for l in np.linspace(0, 1, 100): colors.append((255./255, 13./255, 87./255,l)) red_transparent_blue = LinearSegmentedColormap.from_list("red_transparent_blue", colors) multi_output = True if type(shap_values) != list: multi_output = False shap_values = [shap_values] # make sure labels if labels is not None: assert labels.shape[0] == shap_values[0].shape[0], "Labels must have same row count as shap_values arrays!" if multi_output: assert labels.shape[1] == len(shap_values), "Labels must have a column for each output in shap_values!" else: assert len(labels.shape) == 1, "Labels must be a vector for single output shap_values." # plot our explanations fig_size = figsize fig, axes = plt.subplots(nrows=x.shape[0], ncols=len(shap_values) + 1, figsize=fig_size) if len(axes.shape) == 1: axes = axes.reshape(1,axes.size) for row in range(x.shape[0]): x_curr = x[row].copy() # make sure if len(x_curr.shape) == 3 and x_curr.shape[2] == 1: x_curr = x_curr.reshape(x_curr.shape[:2]) if x_curr.max() > 1: x_curr /= 255. axes[row,0].imshow(x_curr) axes[row,0].axis('off') # get a grayscale version of the image if len(x_curr.shape) == 3 and x_curr.shape[2] == 3: x_curr_gray = (0.2989 * x_curr[:,:,0] + 0.5870 * x_curr[:,:,1] + 0.1140 * x_curr[:,:,2]) # rgb to gray else: x_curr_gray = x_curr if len(shap_values[0][row].shape) == 2: abs_vals = np.stack([np.abs(shap_values[i]) for i in range(len(shap_values))], 0).flatten() else: abs_vals = np.stack([np.abs(shap_values[i].sum(-1)) for i in range(len(shap_values))], 0).flatten() max_val = np.nanpercentile(abs_vals, 99.9) for i in range(len(shap_values)): if labels is not None: axes[row,i+1].set_title(labels[row,i]) sv = shap_values[i][row] if len(shap_values[i][row].shape) == 2 else shap_values[i][row].sum(-1) axes[row,i+1].imshow(x_curr_gray, cmap=plt.get_cmap('gray'), alpha=0.15, extent=(-1, sv.shape[0], sv.shape[1], -1)) im = axes[row,i+1].imshow(sv, cmap=red_transparent_blue, vmin=-max_val, vmax=max_val) axes[row,i+1].axis('off') cb = fig.colorbar(im, ax=np.ravel(axes).tolist(), label="SHAP value", orientation="horizontal", aspect=fig_size[0]/0.2) cb.outline.set_visible(False)下一步是加载预先训练好的VGG-16模型,该模型先前已在Imagenet数据集上进行过训练。可以使用以下代码轻松完成。
model = VGG16(weights='imagenet', include_top=True)model.summary() # output_________________________________________________________________Layer (type) Output Shape Param # =================================================================input_3 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________......_________________________________________________________________fc2 (Dense) (None, 4096) 16781312 _________________________________________________________________predictions (Dense) (None, 1000) 4097000 =================================================================Total params: 138,357,544Trainable params: 138,357,544Non-trainable params: 0_________________________________________________________________加载CNN模型后,现在将加载一个可用作背景分布的小图像数据集,将使用四个样本图像进行模型解释。
# load sample imagesX, y = shap.datasets.imagenet50() # load sample cat image for testIMAGE_PATH = './cat2.jpg'img = keras.preprocessing.image.load_img(IMAGE_PATH, target_size=(224, 224))img = keras.preprocessing.image.img_to_array(img) # select 3 other sample images for testimport matplotlib.pyplot as plt%matplotlib inline to_predict = np.array([X[28], X[35], X[46], img])fig, ax = plt.subplots(1, 4, figsize=(18, 10))ax[0].imshow(to_predict[0]/255.)ax[1].imshow(to_predict[1]/255.)ax[2].imshow(to_predict[2]/255.)ax[3].imshow(to_predict[3]/255.)
有四种不同类型的图像,包括一只猫的照片!首先看一下模型对这些图像的预测。
# get imagenet id to label name mappingsurl = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"fname = shap.datasets.cache(url)with open(fname) as f: class_names = json.load(f) # make model predictionspredictions = model.predict(preprocess_input(to_predict.copy())) # get prediction labelspredicted_labels = [class_names.get(str(pred)) for pred in np.argmax(predictions, axis=1)]print(predicted_labels)[['n02999410','chain'],
['n01622779','great_grey_owl'],
['n03180011','desktop_computer'],
['n02124075','Egyptian_cat']]
首先尝试可视化模型在神经网络的第7层(通常是模型中较浅层之一)中看到的内容。
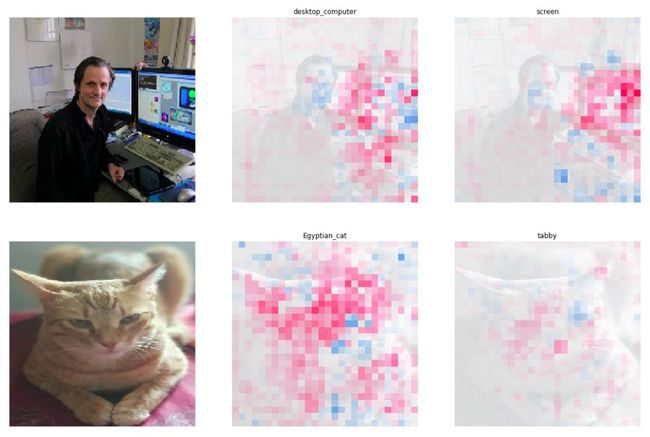
# utility function to pass inputs to specific model layersdef map2layer(x, layer): feed_dict = dict(zip([model.layers[0].input], [preprocess_input(x.copy())])) return K.get_session().run(model.layers[layer].input, feed_dict) # focus on the 7th layer of CNN modelprint(model.layers[7].input)Out [46]: # make model predictionse = shap.GradientExplainer((model.layers[7].input, model.layers[-1].output), map2layer(preprocess_input(X.copy()), 7))shap_values, indexes = e.shap_values(map2layer(to_predict, 7), ranked_outputs=2)index_names = np.vectorize(lambda x: class_names[str(x)][1])(indexes)print(index_names)Out [47]: array([['chain', 'chain_mail'], ['great_grey_owl', 'prairie_chicken'], ['desktop_computer', 'screen'], ['Egyptian_cat', 'tabby']], dtype=') # visualize model decisionsvisualize_model_decisions(shap_values=shap_values, x=to_predict, labels=index_names, figsize=(20, 40)) 
这提供了一个很好的视角,可以看到模型对每个图像做出的前两个预测,以及为什么要做出这样的决定。来看看VGG-16模型中的一个更深层,并可视化第14层的决策。
# focus on 14th layer of the CNN modelprint(model.layers[14].input)Out [49]: # make model predictionse = shap.GradientExplainer((model.layers[14].input, model.layers[-1].output), map2layer(preprocess_input(X.copy()), 14))shap_values, indexes = e.shap_values(map2layer(to_predict, 14), ranked_outputs=2)index_names = np.vectorize(lambda x: class_names[str(x)][1])(indexes) # visualize model decisionsvisualize_model_decisions(shap_values=shap_values, x=to_predict, labels=index_names, figsize=(20, 40)) 
现在可以看到模型变得更强大和更自信的预测判决基础上,十八值的强度,模型预测一个方面screen对一个desktop_computer地方,它还要在键盘上。预测猫是tabby因为鼻子,胡须,面部图案等特定功能!
解释使用TensorFlow 2.0构建的CNN模型
对于其余四种技术,将使用TensorFlow 2.0预先训练的模型,并使用流行的开源框架tf-explain。这里的想法是研究CNN的不同模型解释技术。
https://github.com/sicara/tf-explain

加载预先训练的CNN模型
加载一个最复杂的预训练CNN模型,Xception模型声称比Inception V3模型略胜一筹。从加载必要的依赖项和预先训练的模型开始。
# load dependenciesimport numpy as npimport tensorflow as tfimport matplotlib.pyplot as pltfrom tf_explain.core.activations import ExtractActivationsfrom tensorflow.keras.applications.xception import decode_predictions %matplotlib inline # load Xception pre-trained CNN modelmodel = tf.keras.applications.xception.Xception(weights='imagenet', include_top=True)model.summary() # OutputModel: "xception"__________________________________________________________________________________________________Layer (type) Output Shape Param # Connected to ==================================================================================================input_1 (InputLayer) [(None, 299, 299, 3) 0 __________________________________________________________________________________________________block1_conv1 (Conv2D) (None, 149, 149, 32) 864 input_1[0][0] __________________________________________________________________________________________________block1_conv1_bn (BatchNormaliza (None, 149, 149, 32) 128 block1_conv1[0][0] __________________________________________________________________________________________________......__________________________________________________________________________________________________block14_sepconv2_act (Activatio (None, 10, 10, 2048) 0 block14_sepconv2_bn[0][0] __________________________________________________________________________________________________avg_pool (GlobalAveragePooling2 (None, 2048) 0 block14_sepconv2_act[0][0] __________________________________________________________________________________________________predictions (Dense) (None, 1000) 2049000 avg_pool[0][0] ==================================================================================================Total params: 22,910,480Trainable params: 22,855,952Non-trainable params: 54,528可以从上面的模型体系结构快照中看到,该模型总共有14个块,每个块中有多个层。绝对是CNN更深的模型之一!
样本图像的模型预测
将重用猫的样本图像,并使用Xception模型进行前5个预测。在进行预测之前先加载图像。
# load and pre-process cat imageIMAGE_PATH = './cat2.jpg'img = tf.keras.preprocessing.image.load_img(IMAGE_PATH, target_size=(299, 299))img = tf.keras.preprocessing.image.img_to_array(img) # view the imageplt.imshow(img/255.)
现在使用Xception模型对此图像进行前5个预测。将在推断之前预处理图像。
# load imagenet id to class label mappingsimport requests response = requests.get('https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json')imgnet_map = response.json()imgnet_map = {v[1]: k for k, v in imgnet_map.items()} # make model predictionsimg = tf.keras.applications.xception.preprocess_input(img)predictions = model.predict(np.array([img]))decode_predictions(predictions, top=5)[[('n02124075', 'Egyptian_cat', 0.80723596),
('n02123159', 'tiger_cat', 0.09508163),
('n02123045', 'tabby', 0.042587988),
('n02127052', 'lynx', 0.00547999),
('n02971356', 'carton', 0.0014547487)]]
有趣的预测,至少前三名肯定是相关的!
激活层可视化
此技术通常用于可视化给定输入如何来自特定激活层。关键的想法是探索在模型中激活哪些特征图并将其可视化。通常这是通过查看每个特定层来完成的。以下代码展示了CNN模型的块2中的一个层的激活层可视化。
explainer = ExtractActivations()grid = explainer.explain((np.array([img]), None), model, ['block2_sepconv2_act'])fig, ax = plt.subplots(figsize=(18, 18))ax.imshow(grid, cmap='binary_r')
这种方式了解哪些特征图被激活以及它们通常关注的图像部分。
遮挡敏感度
使用遮挡灵敏度进行解释的想法非常直观。基本上试图通过迭代地遮挡(隐藏)部分来可视化图像的各部分如何影响神经网络模型的置信度。这是通过用灰色方块系统地遮挡输入图像的不同部分并监视分类器的输出来完成的。
# get label imagenet IDimgnet_map['Egyptian_cat'] from tf_explain.core.occlusion_sensitivity import OcclusionSensitivity explainer = OcclusionSensitivity()img_inp = tf.keras.preprocessing.image.load_img(IMAGE_PATH, target_size=(299, 299))img_inp = tf.keras.preprocessing.image.img_to_array(img_inp)grid = explainer.explain(([img_inp], None), model, 285, 7)fig, ax = plt.subplots(figsize=(8, 8))plt.imshow(grid)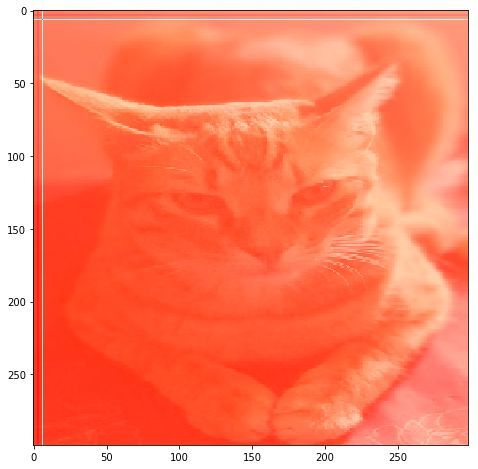
理想情况下,图像的特定色块应以红色\黄色突出显示,如热图,但对于猫图像,它会突出显示红色色调的整体图像,原因可能是因为猫的缩放图像。然而,图像的左侧具有更高的强度,更多地关注猫的形状,而不是图像的纹理。
GradCAM
这可能是解释CNN模型最流行和最有效的方法之一。使用GradCAM,尝试通过查看类激活图(CAM)来可视化图像的各部分如何影响神经网络的输出。类激活图是一种简单的技术,用于获取CNN使用的辨别图像区域来识别图像中的特定类。换句话说,类激活图(CAM)可以看到图像中的哪些区域与此类相关。
grad-CAM的输出将是有助于目标函数最大化的像素。例如,如果对最大化类别编号285的内容感兴趣,则将所有其他类别归零。
相对于卷积层输出计算目标函数的梯度。这可以通过反向传播有效地完成
给定图像和感兴趣的类别(例如,“老虎猫”或任何其他类型的可微分输出)作为输入,通过模型的CNN部分向前传播图像,然后通过任务特定的计算获得原始分数对于该类别。除了所需的类(虎猫)之外,所有类的梯度都设置为零,设置为1.然后将该信号反向传播到感兴趣的整流卷积特征图,将它们组合起来计算粗Grad-CAM定位( blue heatmap)表示模型必须在哪里做出特定决定。
看一下CNN模型中特定块的GradCAM可视化。首先从块1(较浅层)可视化其中一个层。
from tf_explain.core.grad_cam import GradCAM explainer = GradCAM() # get imagenet IDs for cat breedsimgnet_map['tabby'], imgnet_map['Egyptian_cat']Out [24]: ('281', '285') # visualize GradCAM outputs in Block 1grid1 = explainer.explain(([img], None), model, 'block1_conv2', 281)grid2 = explainer.explain(([img], None), model, 'block1_conv2', 285) fig = plt.figure(figsize = (18, 8))ax1 = fig.add_subplot(1, 3, 1)ax1.imshow(img_inp / 255.)ax1.imshow(grid1, alpha=0.6)ax2 = fig.add_subplot(1, 3, 2)ax2.imshow(img_inp / 255.)ax2.imshow(grid2, alpha=0.6)ax3 = fig.add_subplot(1, 3, 3)ax3.imshow(img_inp / 255.)
就像预期的那样,这是浅层之一,看到更高级别的特征,如边缘和角落在网络中被激活。现在在块6中可视化来自网络中较深层之一的GradCAM输出。
# visualize GradCAM output from Block 6grid1 = explainer.explain(([img], None), model, 'block6_sepconv1', 281)grid2 = explainer.explain(([img], None), model, 'block6_sepconv1', 285) fig = plt.figure(figsize = (18, 8))ax1 = fig.add_subplot(1, 3, 1)ax1.imshow(img_inp / 255.)ax1.imshow(grid1, alpha=0.6)ax2 = fig.add_subplot(1, 3, 2)ax2.imshow(img_inp / 255.)ax2.imshow(grid2, alpha=0.6)ax3 = fig.add_subplot(1, 3, 3)ax3.imshow(img_inp / 255.)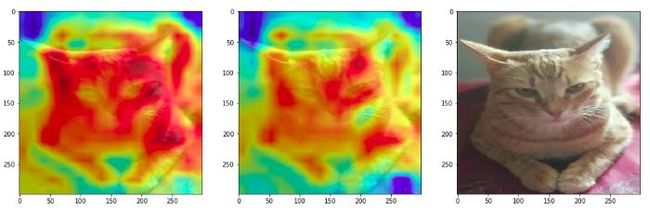
事情肯定开始变得更有趣,可以清楚地看到,当模型预测猫时tabby,它关注的是纹理以及猫的整体形状和结构,而不是它预测猫作为一个Egyptian_cat。最后来看看Block 14中模型中最深的一层。
# visualize GradCAM output from Block 14grid1 = explainer.explain(([img], None), model, 'block14_sepconv1', 281)grid2 = explainer.explain(([img], None), model, 'block14_sepconv1', 285) fig = plt.figure(figsize = (18, 8))ax1 = fig.add_subplot(1, 3, 1)ax1.imshow(img_inp / 255.)ax1.imshow(grid1, alpha=0.6)ax2 = fig.add_subplot(1, 3, 2)ax2.imshow(img_inp / 255.)ax2.imshow(grid2, alpha=0.6)ax3 = fig.add_subplot(1, 3, 3)ax3.imshow(img_inp / 255.)
非常有趣的是,对于tabby猫标签预测,该模型还在观察猫周围的区域,该区域主要关注猫的整体形状\结构以及猫的面部结构的某些方面!
SmoothGrad
这种技术有助于在决策输入上可视化稳定的梯度。关键目标是识别强烈影响最终决策的像素。该策略的起点是类别得分函数相对于输入图像的梯度。该梯度可以解释为灵敏度图,并且有几种技术可以阐述这个基本思想。
SmoothGrad是一种简单的方法,可以帮助在视觉上锐化基于梯度的灵敏度图。核心思想是拍摄感兴趣的图像,通过向图像添加噪声来对相似图像进行采样,然后获取每个采样图像的最终灵敏度图的平均值。
from tf_explain.core.smoothgrad import SmoothGrad explainer = SmoothGrad() grid1 = explainer.explain(([img], None), model, 281, 80, .2)grid2 = explainer.explain(([img], None), model, 285, 80, .2) fig = plt.figure(figsize = (18, 8))ax1 = fig.add_subplot(1, 3, 1)ax1.imshow(img_inp / 255.)ax1.imshow(grid1, alpha=0.9, cmap='binary_r')ax2 = fig.add_subplot(1, 3, 2)ax2.imshow(img_inp / 255.)ax2.imshow(grid2, alpha=0.9, cmap='binary_r')ax3 = fig.add_subplot(1, 3, 3)ax3.imshow(img_inp / 255.)
对于tabby猫来说,焦点肯定是在脸上的关键点,包括斑点和条纹,这是非常有区别的特征。
结论
这应该很好地了解如何利用预先训练的复杂CNN模型来预测新图像,甚至尝试可视化神经网络模型真正看到的内容!这里的技术列表并不详尽,但绝对涵盖了一些最流行和广泛使用的解释CNN模型的方法。建议您使用自己的数据和模型进行尝试!
本文中使用的所有代码都可以在GitHub中作为Jupyter笔记本在此存储库中获得。
https://github.com/dipanjanS/data_science_for_all/tree/master/gde_cnn_interpretation_xai
推荐阅读
在Python中逐步检测Canny边缘 - 计算机视觉