YOLOV5训练自己的数据集(踩坑经验之谈)
导言
很惭愧,来csdn已经三年多了,却一直都在“白嫖”各位大神的经验与总结。这几天也一直在csdn里学习YOLOv3与YOLOv5训练数据集的具体步骤,几经波折终于实现了很好的效果。因此,决定利用闲暇时间,为大家写一篇YOLOv5训练数据集的小白手册,还望大家喜欢!有不同看法或意见欢迎在评论区指出!
1.YOLOv5的简介
(本段为个人理解,有错误问题欢迎指正!)
严格来讲,YOLOv5并不算是YOLO系列的第五代,因为并非原作者创作且暂时没有得到原作者的许可。但是,它的性能比上一代高很多,无论是效率还是精准度,都有很大的提升,因此被称为YOLOv5。
技术层面的知识本人就不叙述了,毕竟属于一个小白,掌握的还不完全,大家可以去官网多多了解!
2.前期的准备
YOLOv5的代码链接:
GitHub官方下载(推荐):https://github.com/ultralytics/yolov5
环境:
- Python版本:官方文档给出的是Python3.8以上,但博主亲测3.7版本也可以完美运行;
- Torch与CUDA:1.7.1+cu110(我在这里踩过坑,测试v3的时候使用了CUDA10.1版本,结果报错,后来升级为CUDA11了,就没出现任何问题了,这个还是看大家自己设备的需求吧(_))具体安装版本可查看官网:https://pytorch.org/;
- 其他包:直接查看代码内置的requirements.txt文件的需求即可,缺什么装什么。
3.数据集的制作
制作数据集是一个繁琐且枯燥的过程,这里需要使用LabelImg工具,具体步骤就不展开了,但是大家标注具体类别的时候一定要细心,因为这会决定你的预测结果。
我用到的是识别鱼群中一类鱼的数据集,大概两百张。
4.配置文件
4.1 创建文件
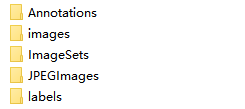
在data下创建如下几个文件夹(注意: images内为数据集原始图片,Annotations内为标注的xml文件)
并将images内文件复制到JPEGIamges中
根目录下创建 1make_txt.py 文件,代码如下:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
根目录下继续创建 1voc_label.py 文件,代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ['fish']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
在这里要注意: 我这里的 classes = [‘fish’] 仅代表我的数据集需要标注的类别是fish类,单引号的内容需要根据你的数据集确定,有几类就写几类。
修改之后,依次执行上面两个py文件,执行成功是这样的:
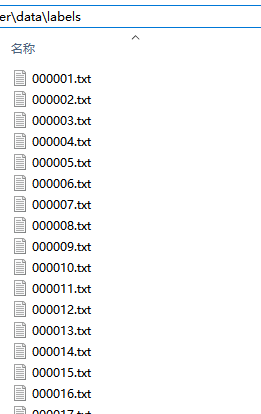
(1) labels下生成txt文件(显示数据集的具体标注数据)
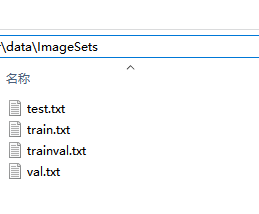
(2) ImageSets下生成四个txt文件
(3) data下生成三个txt文件(带有图片的路径)

4.2 修改yaml文件
这里的yaml和以往的cfg文件是差不多的,但需要配置一份属于自己数据集的yaml文件。
复制data目录下的coco.yaml,我这里命名为fish.yaml
主要修改三个地方:

a. 修改train,val,test的路径为自己刚刚生成的路径
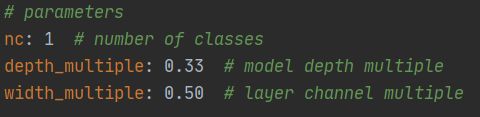
b. nc 里的数字代表数据集的类别,我这里只有鱼一类,所以修改为1
c. names 里为自己数据集标注的类名称,我这里是’fish’
4.3 修改models模型文件
models下有四个模型,smlx需要训练的时间依次增加,按照需求选择一个文件进行修改即可

这里修改了yolov5s.yaml,只需要将nc的类别修改为自己需要的即可
5.训练train.py
这里需要对train.py文件内的参数进行修改,按照我们的需求需改即可
官方下载pt权重文件的速度太太太太太太慢了,所以分享给大家
链接:https://pan.baidu.com/s/1vlTmjNofB5kD3BOaSy4SnA
提取码:gr8v
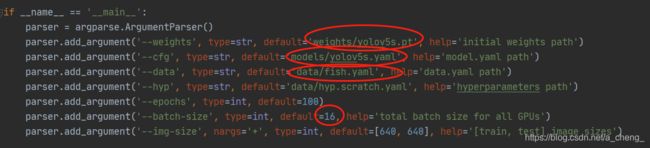
weights,cfg,data按照自己所需文件的路径修改即可
epochs迭代次数自己决定,我这里仅用100次进行测试
batch-size过高可能会影响电脑运行速度,还是要根据自己电脑硬件条件决定增加还是减少
修改完成,运行即可!
此处附上命令行代码,按照个人需求修改即可!
python train.py --data fish.yaml --cfg yolov5s.yaml --weights weights/yolov5s.pt --epochs 10 --batch-size 32
我遇到的错误:
![]() train.py内加上这一行代码即可修改错误
train.py内加上这一行代码即可修改错误
os.environ[“KMP_DUPLICATE_LIB_OK”]=“TRUE”
接着提示我CUDA内存溢出,这就是内存占用过高电脑带不动了,因此需要修改batch-size,改小一点再试试

继续运行,成功!

6. 测试detect.py
6.1 图片/视频检测
可以去detect.py下修改参数,也可以直接运行这一行代码
python detect.py --weights runs/train/exp3/weights/best.pt --source data/Samples/ --device 0 --save-txt
source data/Samples/ 代表的是需要预测的图片路径,根据自己情况修改即可(视频检测也是一样的方法,添加视频路径即可)
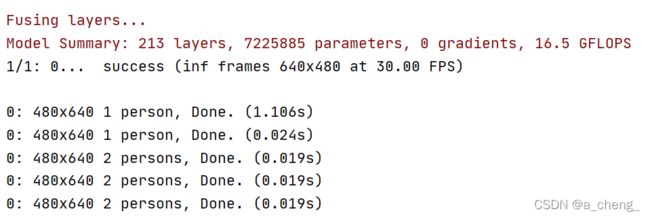
运行结果:(结果图片会在run/detect下的exp文件夹中生成)

效果巨好啊!!!(除了一条隐身)而且这只是迭代100次的结果,和我的原始标注的图片几乎没什么区别了
吹爆YOLOv5!!!
6.2 开启摄像头实时检测
如果想开启摄像头进行实时目标检测,只需要将上述部分图片的路径改为“0”即可调用摄像头,不过有时候可能会遇到这种错误:

后来我查了资料,发现可以在general.py中找到def is_docker代码段,将注释修改如下即可正常显示界面了~
def is_docker():
# Is environment a Docker container?
# return Path('/workspace').exists() # or Path('/.dockerenv').exists()
return Path('/.dockerenv').exists()
结语
这是我的第一篇CSDN博客,用了两个小时才写完,第一次接触有些生疏,可能文章有些细节也没有交代清楚,以后继续努力!如果能够帮助到大家,是我的荣幸!如果大家看过还是有些迷茫,可以评论提问,只要我看到就会回复的!
恰巧这篇文章对你有帮助的话,别忘了给我点个赞哟(^U^)ノ~YO
本文链接:https://blog.csdn.net/a_cheng_/article/details/111401500
转载请注明出处