在飞桨平台做图像分类-2 完成模型组网并训练|CSDN创作打卡
在飞桨平台做图像分类
文章目录
- 在飞桨平台做图像分类
- 前言
- 导入数据集
- Sequential组网
-
- 训练模型
- 模型评估及预测
- 后记
前言
计划是在寒假时用在飞桨平台上做动物,水果的分类。
前面已经完成了数据集的建立:在飞桨平台做图像分类-1 制作基于飞桨的数据集
这里使用飞桨的高层API来快速完成模型组网并训练
我用的是飞桨的BIM CodeLab,环境信息是这样的

导入数据集
前面已经完成了数据集的建立:在飞桨平台做图像分类-1 制作基于飞桨的数据集
我把myImageReader.py放在work文件夹里
导入myImageReader
from work import myImageReader
用这个可以返回定义的数据集
'''
图片文件路径;
训练集占总数的比例;
读取的种类;
'''
train_dataset = myImageReader.myreader(r'animal_fruit',0.7,9,'train')
然后用 paddle.io.DataLoader方法来加载数据集,这个方法返回一个迭代器,迭代器会根据给定的顺序来迭代给定的datast。文档paddle.io.DataLoader
文档里说return_list 这个参数在动态图模式下,必须设置为True,默认是False。现在飞桨2.0以上的版本默认都是动态图模式(关于飞桨的动态图、静态图模式可以先搜索了解一下)。但是飞桨2.2的源码中这个参数默认已经是True了,也就是对于这个参数动态图模式下不用设置。
还有places这个参数在2.2的源码里也说了这个位置可以是None,是None的话,就是使用默认位置(CPUPlace或CUDAPlace(0))。
'''
设置了batch的大小以及是否打乱
'''
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
用这些在飞桨的BIM CodeLab上实现数据集的导入:
- 先导入需要的模块:
from work import myImageReader
import paddle
import matplotlib.pyplot as plt
import numpy as np
可能有这个警告,无伤大雅

看着不顺眼的话可以在上面加这两行来忽略警告:
import warnings
warnings.filterwarnings('ignore')
然后就是用上面的方法把数据集导入了
# 导入训练集
train_dataset = myImageReader.myreader(r'animal_fruit',0.7,9,'train')
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 导入测试集
test_dataset = myImageReader.myreader(r'animal_fruit',0.7,9,'test')
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, shuffle=True)
# 验证一下读取是否成功
print(train_dataset[1][0])
l = np.array(train_dataset[0][0])
plt.figure(figsize=(2,2))
plt.imshow(l, cmap=plt.cm.binary)

至此就完成了数据集的建立和读取。
Sequential组网
飞桨框架支持两种组网方式,一种是Sequential组网,另一种是SubClass组网。Sequential 可以快速的完成组网。但是当我们想组建一些比较复杂的网络结构可能就需要SubClass组网了。我使用的是Sequential 来快速搭建一个简单的网络。
Sequential文档
这个网络由卷积层,池化层,激活函数层和线性变换层构成。
注意飞桨的paddle.nn.Conv2D以及paddle.nn.MaxPool2D的默认输入格式都是‘NCWH’,N是批尺寸,C是通道数,H是特征高度,W是特征宽度。而我的数据集读取的格式是‘NHWC’,所以要设置一下。
mnist = paddle.nn.Sequential(
paddle.nn.Conv2D(3,16,(3,3),data_format='NHWC'),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(2, 2,data_format='NHWC'),
paddle.nn.Conv2D(16,32,(3,3),data_format='NHWC'),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(2, 2,data_format='NHWC'),
paddle.nn.Conv2D(32,64,(3,3),data_format='NHWC'),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(2, 2,data_format='NHWC'),
paddle.nn.Flatten(),
paddle.nn.Linear(2304, 128),
paddle.nn.Linear(128, 10),
)
paddle.summary(mnist, (-1, 64, 64,3))
model = paddle.Model(mnist) # 将网络结构用 Model类封装成为模型
使用paddle.summary()方法可以看到网络结构,只要指定输入网络模型以及输入的形状就可以。非常好用,在搭建网络的时候可以写一点就看一下网络结构,方便理清脉络。

训练模型
先设置一下optimizer优化器,loss损失函数,metrics设置精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
然后使用高层API train_batch() 完成单个批次数据的训练操作。
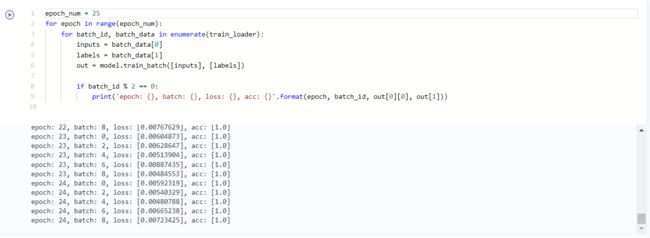
epoch_num = 25 # 设置训练轮次
for epoch in range(epoch_num):
for batch_id, batch_data in enumerate(train_loader):
inputs = batch_data[0]
labels = batch_data[1]
out = model.train_batch([inputs], [labels])
if batch_id % 2 == 0:
print('epoch: {}, batch: {}, loss: {}, acc: {}'.format(epoch, batch_id, out[0][0], out[1]))
eval_result = model.evaluate(test_dataset, verbose=1)
print('测试',eval_result['loss'][0])
print('测试acc',eval_result['acc'])
模型评估及预测
- 模型评估
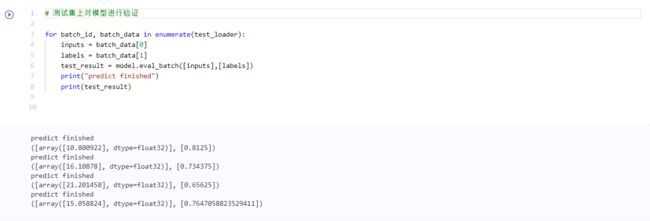
# 用 model.eval_batch 在测试集一个批次的数据上进行验证
for batch_id, batch_data in enumerate(test_loader):
inputs = batch_data[0]
labels = batch_data[1]
test_result = model.eval_batch([inputs],[labels])
print("predict finished")
print(test_result)
- 模型预测
for batch_id, batch_data in enumerate(test_loader):
inputs = batch_data[0]
labels = batch_data[1]
out = model.predict_batch([inputs])
for i, label in enumerate(labels):
print('实际:',label)
out1 = np.argmax(out[0][i])
print('预测',out1)

后记
我用的环境是CPU版本,会有概率出现内存溢出,后面再看看是什么地方的问题。
测试集的正确率大概在73%,预测集也就是用的测试集。
后面再优化。