数据科学 机器学习系列1 机器学习历史
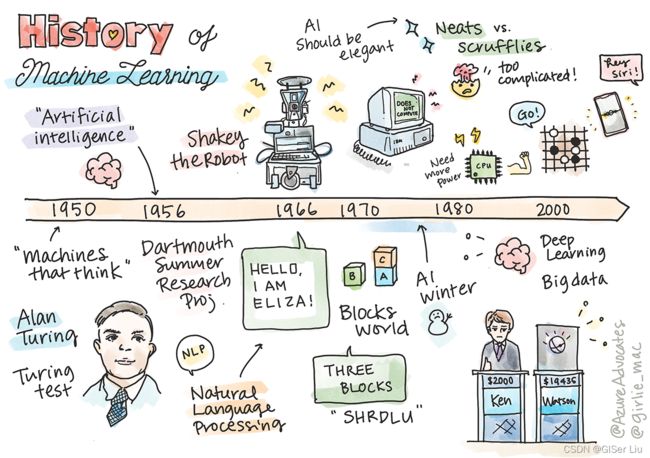
图1.人工智能发展史
目录
一、课程内容
二、理论发现
三、AI发展历史
(1)1950年:思考的机器
(2)1956年:达特茅斯夏季研究项目
(3)1956-1974: “黄金岁月”
(4)1974-1980:“人工智能寒冬”
(5)1980s :专家系统(Expert system)
(6)1987-1993: “人工智能硬件寒冬”
(7)1993 - 2011:“人工智能第二次浪潮”
(8)2016-2022 :“人工智能当下的挑战”
四、结论展望
一、课程内容
机器学习的发展分为知识推理期、知识工程期、浅层学习(Shallow Learning)和深度学习(Deep Learning)几个阶段。
在本课中,我们将介绍机器学习和人工智能历史上的主要里程碑。
人工智能(AI)作为计算机领域与机器学习的历史交叉点,随着支撑机器学习的算法和算力的增长,AI的发展也得到进步。值得关注的是,虽然这些研究从1950年代已经开始出现,但重要的算法:统计,数学,计算等相关技术理论的发现远早于这个时代。事实上,人们已经思考这些问题数百年 。本文将讨论“思考机器”概念的历史知识基础。
二、理论发现
如下是一些重要的理论发现:
1763 贝叶斯定理及其前身。这个定理及其应用是推理的基础,描述了基于先验知识的事件发生的概率。
1805 法国数学家Adrien-Marie Legendre的最小二乘理论。我将在回归单元中学习此理论,回归有助于数据拟合。
1913 马尔可夫链,以俄罗斯数学家安德烈·马尔可夫的名字命名,用于描述基于先前状态的一系列可能事件。
1957 Perceptron是由美国心理学家Frank Rosenblatt发明的一种线性分类器,是深度学习进步的基础。
1967 最近邻是一种最初设计用于映射路线的算法。在在机器学习中,它被用于检测模式。
1970 反向传播用于训练前馈神经网络。
1982 Recurrent Neural Networks(RNN)是从创建时间图的前馈神经网络派生出来的人工神经网络...
三、AI发展历史
(1)1950年:思考的机器
艾伦·图灵(Alan Turing)是一位真正了不起的人,他在2019年被公众评选为20世纪最伟大的科学家之一,他为“会思考的机器”的概念奠定了基础。并努力解决反对者和他自己对这个概念的经验证据的辩证需求,其部分原因是因为他创造了图灵测试。
(2)1956年:达特茅斯夏季研究项目
“达特茅斯夏季人工智能研究项目”是人工智能领域的开创性事件,“人工智能”术语便源自于此。
原则上看,学习的每个方面或任何其他智能特征都可以被精确地描述,以至于机器可以被制造出来模拟它。
首席研究员、数学教授约翰·麦卡锡(John McCarthy)希望在这样一种猜想的基础上进行,即学习的每个方面或任何其他智力特征原则上都可以被精确地描述,以至于机器可以被制造出来模拟它。与会者包括该领域的另一位杰出人物马文·明斯基(Marvin Minsky)。
图2 马文.明斯基

图3 约翰.麦卡锡

该研讨会发起并鼓励了几次讨论,包括“符号方法的兴起,专注于有限领域的系统(早期专家系统),演绎系统与归纳系统。
(3)1956-1974: “黄金岁月”
从20世纪50年代到70年代中期,人们乐观地希望人工智能能够解决许多问题。1967年,马文·明斯基自信地说:“在一代人的时间里......创造'人工智能'的问题将得到实质性解决。
自然语言处理研究蓬勃发展,搜索得到改进并变得更加强大,并创建了“micro-worlds”的概念,其中使用简单的语言指令完成简单的任务。该研究得到了政府机构的大力资助,在算力和算法方面取得了进展,并建立了智能机器的原型。其中一些机器包括:
① Shakey the Robot
Shakey the Robot是第一个能够推理自己行为的通用移动机器人。由于其性质,该项目结合了机器人技术,计算机视觉和自然语言处理方面的研究。正因为如此,这是第一个融合逻辑推理和物理动作的项目。
图4.Shakey the Robot
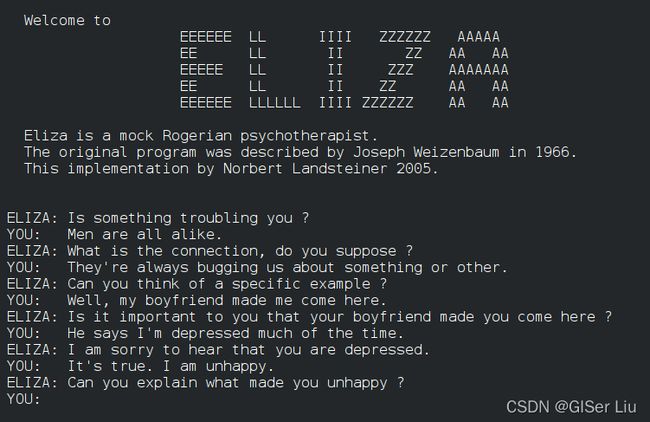
②伊丽莎Eliza,
伊丽莎Eliza,一个早期的聊天机器人,可以与人交谈,并充当一个原始的“治疗师”。在NLP课程中我将会讲述Eliza的更多信息。
图5.某个版本的Eliza聊天记录
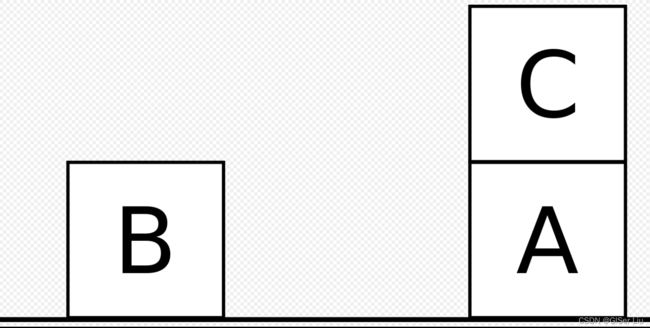
③积木世界(Blocks world)
Blocks world是人工智能的一个规划领域。该算法类似于坐在桌子上的一组各种形状和颜色的木块。目标是构建一个或多个垂直的块堆栈。一次只能移动一个方块:它可以放在桌子上或放在另一个方块上。因此,在给定时间位于另一个块下的任何块都无法移动。此外,某些类型的块不能在其上堆叠其他块。
图6.积木世界案例(苏尔曼异常问题)
油管视频链接:https://www.youtube.com/watch?v=QAJz4YKUwqw
相关博客链接:UVa 101 - The Blocks Problem(积木问题,指令操作)_kisskiller啊的技术博客_51CTO博客
这个玩具世界由于其简单性很容易适应经典的符号人工智能方法,其中世界被建模为一组抽象的符号,这些符号可以被推理。
(4)1974-1980:“人工智能寒冬”
20 世纪 70 年代开始,人工智能进入知识工程期,费根鲍姆(E.A. Feigenbaum)作为知识工程之父在 1994 年获得了图灵奖。由于人工无法将所有知识都总结出来教给计算机系统,所以这一阶段的人工智能面临知识获取的瓶颈。
到20世纪70年代中期,制造“智能机器”的复杂性很显然被低估,而且考虑到可用的计算能力,它的承诺被过分夸大最后,导致资金枯竭,对该领域的研究信心逐渐放缓。“人工智能寒冬”来临。
导致寒冬的一些原因包括:
0 算力限制 硬件计算能力有限。
1 组合爆炸 需要训练的参数数量呈指数级增长,因为对计算机的要求越来越高,却没有算力与算法的并行发展。
2 缺乏数据 硬件太少,缺乏训练数据,阻碍了测试、开发和优化算法的过程。
3 提出的问题是否正确? 被问到的问题开始受到质疑。研究人员开始对他们的方法提出批评:图灵测试通过“中文房间理论”等想法而受到质疑,(该理论假设,“对数字计算机进行编程可能会使它看起来理解语言,但无法产生真正的理解。)
4 道德伦理 将“心理治疗师”ELIZA等人工智能引入社会的伦理受到挑战。
与此同时,各种人工智能思想流派开始形成。在 "scruffy" 与"neats" 流派分为两个阵营。
“Neats”使用基于逻辑、数学优化或神经网络等形式范式的算法。其研究人员和分析人士表示,希望可以扩展和改进单一的形式范式,以实现通用智能和超级智能。
“Scruffies”使用任意数量的不同算法和方法来实现智能行为。“scruffy”的程序可能需要大量的手工编码或知识工程。Scruffies认为,通用智能只能通过解决大量本质上不相关的问题来实现,并且没有灵丹妙药可以让程序自主开发通用智能。而ELIZA和SHRDLU则是典型的neat AI系统。
“scruffy”的方法类似于物理学,因为它使用简单的数学模型作为其基础。这种“neat”的方法更像是生物学,其中大部分工作涉及研究和分类各种现象。在20世纪80年代,随着使机器学习系统可重复的需求出现,scruffy系统逐渐走在前列,因为它的结果更容易解释。
在这里我们也可以看出前者类似于我们在上一篇文章中提出的规则机器,后者则是如支持向量机,神经网络等实际行业常用的机器学习算法,后者相比前者可重复性高,易于解释与开发。
(5)1980s :专家系统(Expert system)
随着该领域的发展,它对企业的好处变得更加明显,在20世纪80年代,“专家系统”的激增也随之而来。“专家系统是人工智能(AI)软件的首批真正成功形式之一。
这种类型的系统实际上是混合的,部分由定义业务需求的规则引擎和利用规则系统推断新事实的推理引擎组成。专家系统分为两个子系统:推理引擎和知识库。知识库表示事实和规则。推理引擎将规则应用于已知事实以推断新事实。推理引擎还可以包括解释和调试功能。
这个时代也越来越关注神经网络。实际上,在 20 世纪 50 年代,就已经有机器学习的相关研究,代表性工作主要是罗森布拉特(F. Rosenblatt)基于神经感知科学提出的计算机神经网络,即感知器,在随后的十年中浅层学习的神经网络曾经风靡一时,特别是马文·明斯基提出了著名的 XOR 问题和感知器线性不可分的问题。由于计算机的运算能力有限,多层网络训练困难,通常都是只有一层隐含层的浅层模型,虽然各种各样的浅层机器学习模型相继被提出,对理论分析和应用方面都产生了较大的影响,但是理论分析的难度和训练方法需要很多经验和技巧,随着最近邻等算法的相继提出,浅层模型在模型理解、准确率、模型训练等方面被超越,机器学习的发展几乎处于停滞状态。
(6)1987-1993: “人工智能硬件寒冬”
专项专家系统硬件的激增产生了过于专业化的不幸后果。个人计算机在兴起后也加入到这些大型、专业化、集中式系统竞争。计算机的大众化已经开始,这最终为大数据的现代的爆发铺平了道路。
(7)1993 - 2011:“人工智能第二次浪潮”
这个时代见证了机器学习和AI发展的新浪潮,之前由于缺乏数据和算力而导致的一些问题随着计算机技术的发展被一一解决。数据量开始迅速增加。特别是随着2007年智能手机的出现。算力呈指数级增长,算法紧跟着迭代。终于,过去零散研究的AI领域开始成长为一门真正的学科,这个领域开始变得成熟。
2006 年,希尔顿(Hinton)发表了深度信念网络论文,Bengio等人发表了“Greedy Layer-Wise Training of Deep Networks”论文,杨立昆(LeCun)团队发表了“Efficient Learning of Sparse Representations with an Energy-Based Model”论文,这些事件标志着人工智能正式进入了深层网络的实践阶段,同时,云计算和 GPU 并行计算为深度学习的发展提供了基础保障,特别是最近几年,机器学习在各个领域都取得了突飞猛进的发展。
(8)2016-2022 :“人工智能当下的挑战”
今天,机器学习和人工智能几乎遍布我们生活的方方面面。这个时代需要仔细理解这些算法对人类生活的风险和潜在影响。正如微软的布拉德·史密斯(Brad Smith)所说,“信息技术提出的问题涉及隐私和言论自由等基本人权保护的核心。这些问题加剧了创造这些产品的科技公司的责任。我们认为,他们还呼吁深思熟虑的政府监管,并围绕可接受的用途制定规范“。新的机器学习算法面临的主要问题更加复杂,机器学习的应用领域从广度向深度发展,这对模型训练和应用都提出了更高的要求。随着人工智能的发展,冯·诺依曼式的有限状态机的理论基础越来越难以应对目前神经网络中层数的要求,这些都对机器学习提出了挑战。
四、结论展望
未来还有待观察,但最重要的是要了解这些计算机系统以及它们运行的软件和算法。在此基础上我们才可以将我们的想法实现,我希望本课程将帮助您更好地理解人工智能。
学习链接
