机器学习——sklearn学习
1介绍
主要是一些API的使用,详细可以看机器学习这篇内容,都是我整理的,算是相互对应吧
可以先尝试一下鸢尾花的案例
当然需要先下载库
按照使用的先后顺序
2加载数据集
sklearn内置的一些数据集
3划分测试集训练集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =sklearn.model_selection.train_test_split( train_data, train_target, test_size=0.4, random_state=0, stratify=y_train)
train_x, test_x, train_y, test_y = train_test_split(x, y, train_size=0.7, random_state=0)
train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
stratify是为了保持split前类的分布。比如有100个数据,80个属于A类,20个属于B类。如果train_test_split(... test_size=0.25, stratify = y_all), 那么split之后数据如下:
training: 75个数据,其中60个属于A类,15个属于B类。
testing: 25个数据,其中20个属于A类,5个属于B类。
用了stratify参数,training集和testing集的类的比例是 A:B= 4:1,等同于split前的比例(80:20)。通常在这种类分布不平衡的情况下会用到stratify。
将stratify=X就是按照X中的比例分配
将stratify=y就是按照y中的比例分配
整体总结起来各个参数的设置及其类型如下:
4特征提取
模块 sklearn.feature_extraction 可用于提取符合机器学习算法支持的特征,比如文本和图片。
4.1通用
vectorizer.fit()
vectorizer.transform()
vectorizer.fit_transform(measurements).toarray()
>>>array([[ 1., 0., 0., 33.],
[ 0., 1., 0., 12.],
[ 0., 0., 1., 18.]])
count_vectorizer.fit_transform()得到的是个稀疏矩阵。如果要得到正常的二维数据稠密表达的矩阵,需要使用x_ctv.toarray()。
注意,稀疏矩阵是不可以进行切片操作,比如x_ctv[1][2]。
注意:使用tfidf_vectorizer.fit_transformer()输入为一个numpy.array,形状是(n_samples, n_features)。
因为2个方法的输入设定不同,对于CountVectorizer和TfidfVectorizer只要是iterable(可迭代)的就可以了。
根据设定,TfidfTransformer是将CountVectorizer的输出作为输入的。
vectorizer.get_feature_names()
返回一个list,所有特征的名字
4.2从字典类型加载特征
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
4.3文本特征提取
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
count_vectorizer= CountVectorizer()
4.3.1CountVectorizer
CountVectorizer是通过统计词汇出现的次数,并用词汇出现的次数的稀疏矩阵来表示文本的特征。它会统计所有出现的词汇,每个词汇出现了多少次,最后得到的稀疏矩阵的列就是词汇的数量(每个词汇就是一个特征/维度)
这里的CountVectorizer使用的是默认的参数,主要是:
(1)ngram_range=(min_num_words,max_num_words)。其中,x,y 为数字,即n元语法。(词的粒度)
(2)stop_words = stop_words。其中,stop_words是从停用词文件中读取的list,每行一个停用词。
(3)max_features = n。其中,n为词汇表的数量。表示根据词频大小降序排列后的TOP n词汇数。(选取的特征值的数量)
4.3.2TfidfVectorizer
和CountVectorizer很像,TfidfVectorizer提取的特征是:在一个文本中各个有效词汇对应的TFIDF值是多少,同时,每个文本特征向量会自动进行normalization(归一化)操作。
tfidf_vectorizer = TfidfVectorizer(analyzer='word', ngram_range=(1,4), max_features=10000)
主要参数和CounterVectorizer类似
5模型训练——分类器classfier
5.1分类器通用
fit(X_train, y_train)训练模型
predict(X_test)预测
print('\n>>>算法正在进行训练,请稍候...')
clf.fit(X, y) # X是特征训练集,y是目标训练集(X应该是二维的,y是一维的)
print(clf)
print('\n>>>算法正在进行预测,请稍候...')
y_pred_model = clf.predict(X_test) # X_test是特征测试集,根据测试集的特征预测测试集的目标预测值
print(y_pred_model)
效果如下

也可以像下面这样
 注意特征值的处理
注意特征值的处理
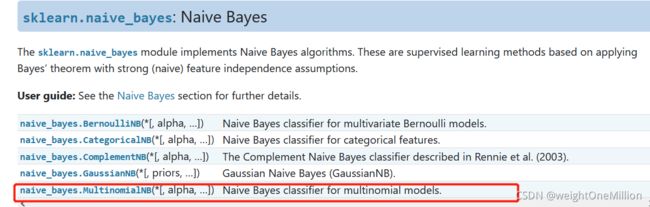
5.2朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB, BernoulliNB, ...
mnb = MultinomialNB(alpha = 1) # alpha拉普拉斯平滑系数
mnb.fit(X_train, y_train)
mnb.predict(X_test)
5.3SVM
SVC, NuSVC 和 LinearSVC 能在数据集中实现多元分类.
5.3.1SVC
from sklearn import svm
svc = svm.SVC()
class sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3,coef0=0.0,random_state=None)
- C: 惩罚系数,⽤来控制损失函数的惩罚系数,类似于线性回归中的正则化系数。
- C越⼤,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增⼤,趋向于对训练集全分对的情 况,这样会出现训练集测试时准确率很⾼,但泛化能⼒弱,容易导致过拟合。
- C值⼩,对误分类的惩罚减⼩,容错能⼒增强,泛化能⼒较强,但也可能⽋拟合。
- kernel: 算法中采⽤的核函数类型,核函数是⽤来将⾮线性问题转化为线性问题的⼀种⽅法。
- 参数选择有RBF, Linear, Poly, Sigmoid或者⾃定义⼀个核函数。
- 默认的是"RBF",即径向基核,也就是⾼斯核函数; ⽽Linear指的是线性核函数, Poly指的是多项式核, Sigmoid指的是双曲正切函数tanh核;。
- degree: 当指定kernel为’poly’时,表示选择的多项式的最⾼次数,默认为三次多项式;
- 若指定kernel不是’poly’,则忽略,即该参数只对’poly’有⽤。
- 多项式核函数是将低维的输⼊空间映射到⾼维的特征空间。
- coef0: 核函数常数值(y=kx+b中的b值), 只有‘poly’和‘sigmoid’核函数有,默认值是0。
5.3.2NuSVC
class sklearn.svm.NuSVC(nu=0.5)
- nu: 训练误差部分的上限和⽀持向量部分的下限,取值在(0,1)之间,默认是0.5
5.3.3 LinearSVC
class sklearn.svm.LinearSVC(penalty='l2', loss='squared_hinge', dual=True, C=1.0)
- penalty:正则化参数, L1和L2两种参数可选,仅LinearSVC有。
- loss:损失函数, 有hinge和squared_hinge两种可选,前者⼜称L1损失,后者称为L2损失,默认是squared_hinge, 其中hinge是SVM的标准损失,squared_hinge是hinge的平⽅
- dual:是否转化为对偶问题求解,默认是True。
- C:惩罚系数, ⽤来控制损失函数的惩罚系数,类似于线性回归中的正则化系数。
5.4随机梯度下降
随机梯度下降(SGD)是一种简单但非常有效的方法,多用用于支持向量机、逻辑回归等凸损失函数下的线性分类器的学习。并且SGD已成功应用于文本分类和自然语言处理中经常遇到的大规模和稀疏机器学习问题。
SGD既可以用于分类计算,也可以用于回归计算。
1)分类
a)核心函数
sklearn.linear_model.SGDClassifier
b)主要参数(详细参数)
loss :指定损失函数。可选值:‘hinge’(默认), ‘log’, ‘modified_huber’, ‘squared_hinge’, ‘perceptron’,
"hinge":线性SVM
"log":逻辑回归
"modified_huber":平滑损失,基于异常值容忍和概率估计
"squared_hinge": 带有二次惩罚的线性SVM
"perceptron":带有线性损失的感知器
alpha:惩罚系数
2)回归
SGDRegressor非常适合回归问题具有大量训练样本(> 10000),对于其他的问题,建议使用的Ridge, Lasso或ElasticNet。
a)核心函数
sklearn.linear_model.SGDRegressor
b)主要参数(详细参数)
loss:指定损失函数。可选值‘squared_loss’(默认), ‘huber’, ‘epsilon_insensitive’, ‘squared_epsilon_insensitive’
说明:此参数的翻译不是特别准确,请参考官方文档。
"squared_loss":采用普通最小二乘法
"huber": 使用改进的普通最小二乘法,修正异常值
"epsilon_insensitive": 忽略小于epsilon的错误
"squared_epsilon_insensitive":
alpha:惩罚系数
6模型评估
7标签二值化
>>> import numpy as np
>>> from sklearn.preprocessing import LabelBinarizer
>>> y = np.array(['apple', 'pear', 'apple', 'orange'])
>>> y_dense = LabelBinarizer().fit_transform(y)
>>> print(y_dense)
[[1 0 0] # apple
[0 0 1] # pear
[1 0 0] # apple
[0 1 0]] # orange
>>> from scipy import sparse
>>> y_sparse = sparse.csr_matrix(y_dense)
>>> print(y_sparse)
(0, 0) 1 # (位置,类别)第0个位置上是类别0(类别0即apple)
(1, 2) 1 # 同理,
(2, 0) 1
(3, 1) 1
多标签二值化MultiLabelBinarizer
# 多标签分类格式。将多分类转换为二分类的格式,类似于one-hot编码
from sklearn.preprocessing import MultiLabelBinarizer
y = [[2, 3, 4], [2], [0, 1, 3], [0, 1, 2, 3, 4], [0, 1, 2]]
y_new = MultiLabelBinarizer().fit_transform(y)
print('新的输出格式:\n',y_new)
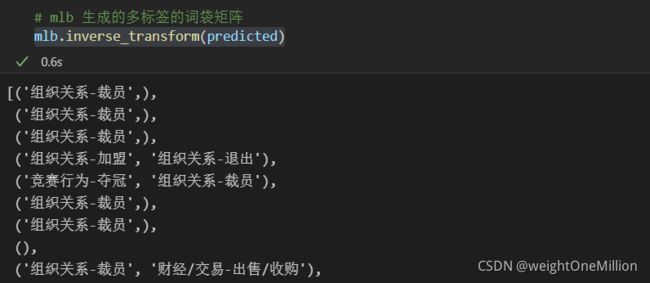
根据预测结果,转化成标签
mlb.inverse_transform(predicted)
效果如下:
8多类别分类策略sklearn.multiclass: Multiclass classification
多类别是指多个类别,可以是1对1,也可以是1对多
注意:sklearn的所有分类器都是开箱即用的多类分类。除非您想尝试不同的多类策略,否则不需要使用sklearn.multiclass模块。
from sklearn import multiclass
multiclass.OneVsRestClassifier(estimator, *) # One-vs-the-rest (OvR) multiclass strategy.该策略包括为每个类安装一个分类器。对于每个分类器,该类与所有其他类相匹配。
multiclass.OneVsOneClassifier(estimator, *) # One-vs-one multiclass strategy. 将会为每一对类别构造出一个分类器
multiclass.OutputCodeClassifier(estimator, *) # (Error-Correcting) Output-Code multiclass strategy.
本模块中提供的估计器是元估计器:它们需要在其构造函数中提供一个基估计器。例如,
- 可以使用这些估计器将二元分类器或回归器转换为多类分类器。
- 也可以将这些估计器与多类估计器一起使用,以期提高它们的准确性或运行时性能。
scikit学习中的所有分类器都实现了多类分类;如果您想尝试自定义多类策略,只需使用此模块。
one vs the rest元分类器还实现了predict_proba方法,只要这种方法是由基础分类器实现的。此方法返回单标签和多标签情况下的类成员概率。注意,在多标签情况下,概率是给定样本落在给定类中的边际概率。因此,在多标签情况下,给定样本的所有可能标签上的这些概率之和不会像在单标签情况下那样总和为一。
8.2多标签分类MultiLable Classification
多标签分类(与多输出分类密切相关)是一项分类任务,使用n_类可能类中的m个标签标记每个样本,其中m可以是0到n_类(包括)。这可以被认为是预测一个样本的属性,而不是相互排斥的。形式上,对于每个示例,为每个类分配一个二进制输出。正类用1表示,负类用0或-1表示。因此,它相当于运行n_类二进制分类任务,例如使用MultiOutputClassifier。这种方法独立地处理每个标签,而多标签分类器可以同时处理多个类,考虑它们之间的相关行为。
例如,预测与文本文档或视频相关的主题。文件或视频可能是关于“宗教”、“政治”、“金融”或“教育”中的一个,几个主题课或所有主题课。
8.2.1多输出分类器MultiOutputClassifier
可以将多标签分类支持添加到具有MultiOutputClassifier的任何分类器。该策略包括为每个目标装配一个分类器。这允许多个目标变量分类。本课程的目的是扩展估计器,使其能够估计一系列目标函数(f1、f2、f3…、fn),这些目标函数在单个X预测矩阵上进行训练,以预测一系列响应(y1、y2、y3…、yn)。
以下是多标签分类的示例:
from sklearn.datasets import make_classification
from sklearn.multioutput import MultiOutputClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.utils import shuffle
import numpy as np
X, y1 = make_classification(n_samples=10, n_features=100, n_informative=30, n_classes=3, random_state=1)
y2 = shuffle(y1, random_state=1)
y3 = shuffle(y1, random_state=2)
Y = np.vstack((y1, y2, y3)).T
n_samples, n_features = X.shape # 10,100
n_outputs = Y.shape[1] # 3
n_classes = 3
forest = RandomForestClassifier(random_state=1)
multi_target_forest = MultiOutputClassifier(forest, n_jobs=-1)
multi_target_forest.fit(X, Y).predict(X)
》》》
array([[2, 2, 0],
[1, 2, 1],
[2, 1, 0],
[0, 0, 2],
[0, 2, 1],
[0, 0, 2],
[1, 1, 0],
[1, 1, 1],
[0, 0, 2],
[2, 0, 0]])
9多输出sklearn.multioutput: Multioutput regression and classification
multioutput.ClassifierChain(base_estimator, *) # A multi-label model that arranges binary classifiers into a chain.
multioutput.MultiOutputRegressor(estimator, *) # Multi target regression.
multioutput.MultiOutputClassifier(estimator, *) # Multi target classification. 可以看上面的8.2.1
multioutput.RegressorChain(base_estimator, *) # A multi-label model that arranges regressions into a chain.
参考链接:主要基于scikit-learn (sklearn) 官方文档中文版:https://sklearn.apachecn.org/#/ (还有百度翻译)
7种文本特征提取方法:http://blog.sina.com.cn/s/blog_b8effd230102zu8f.html
sklearn的train_test_split()各函数参数含义解释(非常全):https://www.cnblogs.com/Yanjy-OnlyOne/p/11288098.html
python机器学习库sklearn——多类、多标签、多输出:http://www.jintiankansha.me/t/bytTYiqrRy
机器学习:随机梯度下降法:https://blog.csdn.net/qq_38150441/article/details/80533891