Pytorch学习笔记(4)——从0实现CNN情感分析
感觉之前RNN的代码写的太丑陋了,所以该文章主要参考了Dive-into-DL-PyTorch和中文文本分类 pytorch实现的代码。
目录
- 1 项目框架
- 2 预处理
-
- 2.1 将所有词映射为词向量
- 2.2 将句子中的词语映射为id
- 3 CNN模型
- 4 参考
1 项目框架
整个项目的框架抽象来看是如下的:

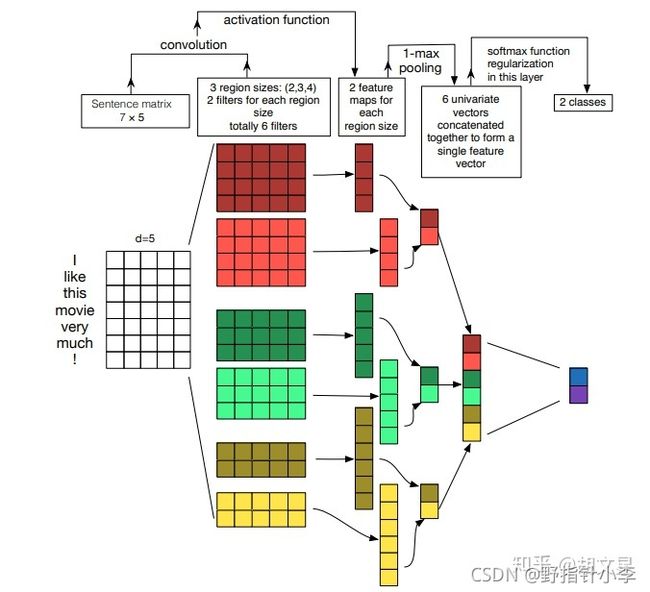
简而言之就是输入的是整一句话,宽度为词向量维度(这里是300维),高度为句子最大长度。经过嵌入层嵌入后,通过卷积与最大池化层,最后进入全连接层,在softmax后得到情感分类的输出。
其详细的框架图为:中文文本分类 pytorch实现
2 预处理
预处理的大部分内容包括数据集与我上篇博客相同:Pytorch学习笔记(3)——从0实现RNN情感分析。只是说将词嵌入这一部分取消了,而是放在的神经网络中进行。更改的部分为:
2.1 将所有词映射为词向量
比起之前将每句话给编码为向量,这里只是将词语与其词向量对应起来。首先,在w2v词向量中已经有了UNK的词向量,所以遇到未登录词,我们可以直接用UNK来表达。但是遇到句子长度不足max_seq_length的时候,我们需要为其填充词向量。我们先定义pad这个变量,其值为
pad = ''
接着在构建id与词的映射关系时,将词库的最后一维定义为pad。
def get_idx_word_mapping(cleaned_X):
"""
获得id与词语之间的映射关系
:param cleaned_X: list
[[word11, word12, ...], [word21, word22, ...], ...]
清洗后的文本数据
:return idx2char: dict
{1: 'word1', 2: 'word2', ...}
id与词的映射
:return char2idx: dict
{'word1': 1, 'word2': 2, ...}
词与id的映射
:return word_set: set
数据中的所有词
"""
idx2char = {}
char2idx = {}
word_list = []
# 获得全部词语
for sentence in cleaned_X:
for word in sentence:
word_list.append(word)
word_set = set(word_list) # 去重
# for i, word in enumerate(word_set, start=1):
for i, word in enumerate(word_set):
idx2char[i] = word
char2idx[word] = i
idx2char[len(word_set)] = pad
char2idx[pad] = len(word_set)
return idx2char, char2idx, word_set
于是idx2char与char2idx变为了:
idx2char: {..., last_idx: '' }
char2idx: {..., '' : last_idx}
接着根据id与词的映射关系,构建词与词向量之间的映射关系:
def find_word_embedding(w2v, idx2char):
"""
找到词对应的w2v
:param w2v: Object
词向量
:param idx2char: dict
id与词的映射
:return embed: tensor
id与词向量的映射
"""
embed = torch.zeros((len(idx2char), 300))
count = 0
for id_ in idx2char.keys():
if id_ == len(idx2char) - 1:
embed[id_] = torch.zeros(300)
else:
try:
embed[id_] = torch.FloatTensor(w2v[idx2char[id_]])
except KeyError:
embed[id_] = torch.FloatTensor(w2v['UNK'])
count += 1
print('OOV: ', count)
return embed
这里要先判断该词语是否是UNK的词向量,否则就是原词语的词向量。
2.2 将句子中的词语映射为id
最后,对语料库中的所有句子进行处理,处理的内容包括:
- 如果词语数不足
max_seq_length,则补充max_seq_length; - 如果词语数超出
max_seq_length,则在max_seq_length处截断句子; - 将句子中的词语转换为
id。
def sentence2ids(cleaned_X, char2idx):
"""
对句子进行处理
1. 将句子给统一切割或补充到max_seq_length
2. 将词语替换为id
:param cleaned_X: list
句子中的词语
:param char2idx: dict
词语与id的映射
:return: tensor
句子中每个词语与id之间的映射
"""
sentences_ids = []
for sentence in cleaned_X:
word_count = 0
sentence_ids = []
for word in sentence:
sentence_ids.append(char2idx[word])
word_count += 1
# 如果词语数超过了max_seq_length, 则切割
if word_count >= max_seq_length:
break
# 如果词语数不足max_seq_length, 则填补3 CNN模型
整个CNN的框架结构可以看博客:中文文本分类 pytorch实现,我也只是照着他的框架结构给实现出来。整体而言,就是先将2.1中生成的embed输入到Embedding层中做映射关系,当输入2.2中的sentences_ids时,根据句子中的id就能查找到对应的词向量。简而言之就是一个lookup function。接着有三个卷积层,其宽为300维,即词向量维度,高分别为[2, 3, 4],也就是说卷积后的输出的高分别为30-2+1, 30-3+1, 30-4+1,即max_seq_length - filter_size + 1。卷积层的输入只有一个通道,输出有128个通道。其输出通过ReLU做激活函数后,经过全局最大池化层,将每个通道池化后的结果拼接在一起,通过Dropout后,放入全连接层,即可获得最后结果。
class CNN(nn.Module):
def __init__(self, embed, num_filters, num_outputs, is_freeze=True):
super().__init__()
self.filter_sizes = (2, 3, 4)
self.embeddings = nn.Embedding.from_pretrained(embed, freeze=is_freeze)
self.convs = nn.ModuleList(
[nn.Conv2d(1, num_filters, (k, 300)) for k in self.filter_sizes]
)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.linear = nn.Linear(num_filters * len(self.filter_sizes), num_outputs)
self.softmax = nn.Softmax()
def global_max_pool1d(self, x):
"""
全局最大池化层, 对高做池化
:param x: tensor
shape: (batch_size, output, height)
:return: tensor
shape: (batch_size, output, 1)
"""
return F.max_pool1d(x, kernel_size=x.shape[2])
def forward(self, inputs):
"""
前向传播
:param inputs: tensor
shape: (batch_size, seq_len)
:return out: tensor
shape: (batch_size, num_outputs)
"""
# height_1: seq_len, width_1: w2v_dim
embed = self.embeddings(inputs) # shape: (batch_size, height_1, width_1)
# 添加一维通道维, shape: (batch_size, in_channel, height_1, width_1)
embed = embed.unsqueeze(1)
pool_outs = []
for conv in self.convs:
# height_2: height_1 - filter_size + 1, width_2 = 1
# shape: (batch_size, output, height_2, width_2)
conv_out = conv(embed)
conv_relu_out = self.relu(conv_out).squeeze(3) # 清理掉width, 因为是1
# shape: (batch_size, out, 1)
pool_out = self.global_max_pool1d(conv_relu_out).squeeze(2) # 清理掉height, 因为是1
pool_outs.append(pool_out)
# shape: (batch_size, out * len(filter_sizes))
pool_outs = torch.cat(pool_outs, 1)
pool_dropout_out = self.dropout(pool_outs)
out = self.linear(pool_dropout_out)
return self.softmax(out)
训练与测试代码为:
def evaluate(model, data_iter):
"""
准确率
:param model: Object
模型
:param data_iter: DataLoader
验证集或测试集
"""
model.eval()
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad():
for texts, labels in data_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
loss_total += loss
labels = labels.data.cpu().numpy()
predic = torch.max(outputs.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
acc = metrics.accuracy_score(labels_all, predict_all)
print('test total loss %f, test accuracy %f' % (loss_total / len(data_iter), acc))
def train(X, y, embed, lr, num_epochs):
"""
训练数据
:param X: tensor
shape: (num_sentences, max_seq_length)
输入数据
:param y: list
shape: (num_sentences)
输入标签
:param embed: tensor
shape: (vocab_size, 300)
词嵌入
:param lr: float
学习率
:param num_epochs: int
epochs
"""
batch_size = 8
y = torch.LongTensor(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
train_dataset = Data.TensorDataset(X_train, y_train)
test_dataset = Data.TensorDataset(X_test, y_test)
train_iter = Data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_iter = Data.DataLoader(test_dataset, batch_size=batch_size)
model = CNN(embed, 128, 2)
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
total_iter = 0 # 记录训练了多少轮
for epoch in range(num_epochs):
model.train()
for X, y in train_iter:
y_hat = model(X)
optimizer.zero_grad()
l = loss(y_hat, y)
l.backward()
optimizer.step()
if (total_iter + 1) % 100 == 0:
pred = torch.max(y_hat.data, 1)[1] # 哪个位置是预测值
train_acc = metrics.accuracy_score(y, pred)
print('iter %d, train_loss %f, train accuracy %f' % (total_iter + 1, l.item(), train_acc))
total_iter += 1
evaluate(model, test_iter)
结果为:
iter 10, train_loss 0.622447, train accuracy 0.625000
iter 20, train_loss 0.413261, train accuracy 0.875000
iter 30, train_loss 0.347180, train accuracy 1.000000
iter 40, train_loss 0.314206, train accuracy 1.000000
iter 50, train_loss 0.318095, train accuracy 1.000000
...
iter 1180, train_loss 0.313262, train accuracy 1.000000
iter 1190, train_loss 0.313262, train accuracy 1.000000
iter 1200, train_loss 0.313262, train accuracy 1.000000
test total loss 0.604928, test accuracy 0.727273
由于我这里没有加early stop,也没有加验证集,所以可能会有点过拟合的情况出现。
4 参考
[1] 胡文星. 中文文本分类 pytorch实现[EB/OL]. (2019-08-01)[2021-10-26]. https://zhuanlan.zhihu.com/p/73176084
[2] Aston Zhang, Zachary C. Lipton, Mu Li, Alexander J. Smola. Dive into Deep Learning[M]. http://www.d2l.ai, 2020.