深度学习系列笔记05卷积神经网络CNN
文章目录
- 1 从全连接层到卷积
-
- 1.1 不变性和局部性
- 1.2 限制多层感知机
- 1.3 通道
- 2 图像卷积
-
- 2.1. 互相关运算
-
- img.shape[i]函数记录:
- 2.2 卷积层
-
- rand&randn函数记录
- torch.normal&torch.linspace函数记录
- 2.3. 图像中目标的边缘检测
- 2.4. 学习卷积核
-
- Conv2d函数记录
- 2.5 特征映射和感受野
- 3 填充和步幅
-
- 3.1 填充 padding
- 3.2. 步幅 stride
- 4. 多输入多输出通道
-
- 4.1. 多输入通道
-
- zip函数记录
- 4.2. 多输出通道
-
- stack函数记录
- 4.3 1×1 卷积层
- 5 池化层pooling
-
- 5.1. 最大汇聚层和平均汇聚层
- 5.2. 填充padding和步幅stride
- 5.3. 多个通道
- cat函数记录
- 6. 卷积神经网络(LeNet)
-
- 6.1. LeNet
- 6.2. 模型训练
-
- net.eval()函数记录:

1 从全连接层到卷积

当使用MLP处理数据时,我们发现尽然有36亿个特征,显然输出参数太多,不合理。
以图识别为例,我们的分类器应该有两个原则,平移不变性和局部性原则 。下面我们将从这两个原则出发,从全连接层得到卷积。
1.1 不变性和局部性
我们可以使用一个“检测器”扫描图像。 该检测器将图像分割成多个区域,并为每个区域包含目标的可能性打分。 卷积神经网络正是将空间不变性(spatial invariance)的这一概念系统化,从而基于这个模型使用较少的参数来学习有用的表示。
神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。 最终,在后续神经网络,整个图像级别上可以集成这些局部特征用于预测。
1.2 限制多层感知机

之前的全连接层:输入输出是一维张量,发生长度上的转化。权重是上一层的神经元个数(行)和下一层的神经元个数(列)的2维矩阵。


V 被称为 卷积核 (convolution kernel) 或者 滤波器 (filter),它仅仅是可学习的一个层的权重。

1.3 通道
然而这种方法有一个问题:我们忽略了图像一般包含三个通道/三种原色(红色、绿色和蓝色)。 实际上,图像不是二维张量,而是一个由高度、宽度和颜色组成的三维张量,比如包含 1024×1024×3 个像素。
这些通道有时也被称为 特征映射 (feature maps),因为每个通道都向后续层提供一组空间化的学习特征。 直观上你可以想象在靠近输入的底层,一些通道专门识别边,而其他通道专门识别纹理。
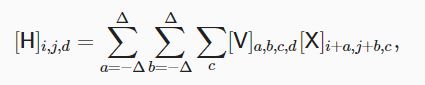
2 图像卷积
2.1. 互相关运算
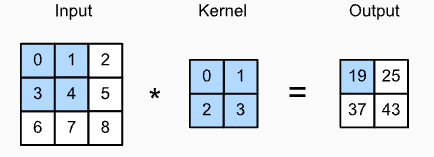
首先,我们暂时忽略通道(第三维)这一情况,看看如何处理二维图像数据和隐藏表示。

输入是高度为 3 、宽度为 3 的二维张量(即形状为 3×3 )。卷积核的高度和宽度都是 2 ,而卷积核窗口(或卷积窗口)的形状由内核的高度和宽度决定(即 2×2 )。
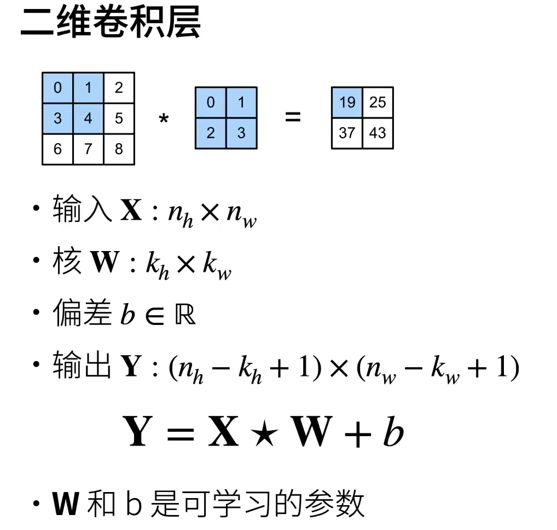
互相关代码:
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X, K):
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1)) # 计算输出Y的维度
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i+h, j:j+w] * K).sum() # 核心计算
return Y
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
print(corr2d(X, K))
先由结论得到输出矩阵的维数,然后将输出矩阵的高度和宽度作为限制条件,来进行核心运算。
img.shape[i]函数记录:
对于图像来说:
img.shape[0]:图像的垂直尺寸(高度)
img.shape[1]:图像的水平尺寸(宽度)
img.shape[2]:图像的通道数
而对于矩阵来说:
shape[0]:表示矩阵的行数
shape[1]:表示矩阵的列数
2.2 卷积层
卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出。 所以,卷积层中的两个被训练的参数是卷积核权重和标量偏置。
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
rand&randn函数记录
torch.rand(*sizes, out=None) → Tensor
返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数。张量的形状由参数sizes定义。
torch.rand(2, 3)
torch.randn(*sizes, out=None) → Tensor
返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义。
torch.randn(2, 3)
torch.normal&torch.linspace函数记录
离散正态分布
torch.normal(means, std, out=None) → → Tensor
线性间距向量
torch.linspace(start, end, steps=100, out=None) → Tensor
返回一个1维张量,包含在区间start和end上均匀间隔的step个点。输出张量的长度由steps决定。
2.3. 图像中目标的边缘检测
如下是卷积层的一个简单应用:通过找到像素变化的位置,来检测图像中不同颜色的边缘。
首先,我们构造一个 6×8 像素的黑白图像。中间四列为黑色( 0 ),其余像素为白色( 1 )。
接下来,我们构造一个高度为 1 、宽度为 2 的卷积核 K 。当进行互相关运算时,如果水平相邻的两元素相同,则输出为零,否则输出为非零。
X = torch.ones((6, 8))
X[:, 2:6] = 0
print(X)
K = torch.tensor([[1.0, -1.0]])
Y = corr2d(X, K)
print(Y)
2.4. 学习卷积核
我们是否可以学习由X生成Y的卷积核呢?
现在让我们看看是否可以通过仅查看“输入-输出”对来学习由 X 生成 Y 的卷积核。 我们先构造一个卷积层,并将其卷积核初始化为随机张量。接下来,在每次迭代中,我们比较 Y 与卷积层输出的平方误差,然后计算梯度来更新卷积核。为了简单起见,我们在此使用内置的二维卷积层,并忽略偏置。
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1, 1, kernel_size=(1, 2), bias=False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
conv2d.weight.data[:] -= 3e-2 * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'batch{i + 1}, loss{l.sum():.3f}')
conv2d.weight.data.reshape((1, 2))
print(conv2d.weight.data)
######################
batch2, loss8.572
batch4, loss1.830
batch6, loss0.468
batch8, loss0.144
batch10, loss0.051
tensor([[[[ 0.9642, -1.0084]]]])
我们学习到的卷积核权重非常接近我们之前定义的卷积核 K 。
Conv2d函数记录
Conv2d函数详解(Pytorch)
2.5 特征映射和感受野
上图中输出的卷积层有时被称为 特征映射 (Feature Map),因为它可以被视为一个输入映射到下一层的空间维度的转换器。 在CNN中,对于某一层的任意元素 x ,其 感受野 (Receptive Field)是指在前向传播期间可能影响 x 计算的所有元素(来自所有先前层)。
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域。
3 填充和步幅
3.1 填充 padding
在应用多层卷积时,我们常常丢失边缘像素。 由于我们通常使用小卷积核,因此对于任何单个卷积,我们可能只会丢失几个像素。 但随着应用许多连续卷积层,累积丢失的像素数就多了。 解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素(通常填充元素是 0 )。


卷积神经网络中卷积核的高度和宽度通常为奇数,例如 1、3、5 或 7。 选择奇数的好处是,保持空间维度的同时,我们可以在顶部和底部填充相同数量的行,在左侧和右侧填充相同数量的列。
import torch
from torch import nn
# 为了方便起见,我们定义了一个计算卷积层的函数。
# 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数
def comp_conv2d(conv2d, X):
# 这里的(1,1)表示批量大小和通道数都是1
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
# 省略前两个维度:批量大小和通道
return Y.reshape(Y.shape[2:])
# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
print(comp_conv2d(conv2d, X).shape)
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
print(comp_conv2d(conv2d, X).shape)
3.2. 步幅 stride
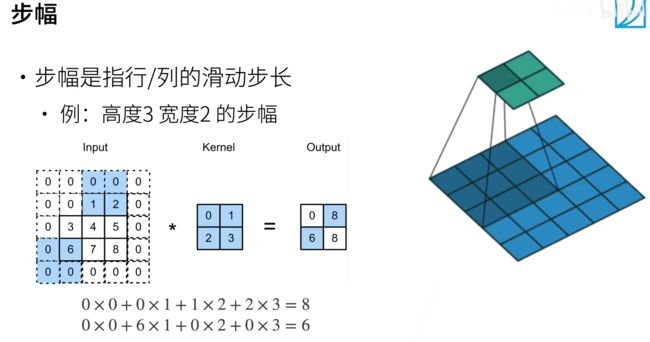

注意是向下取整。
# 下面,我们将高度和宽度的步幅设置为2,
# 从而将输入的高度和宽度减半。
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
print(comp_conv2d(conv2d, X).shape)
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
print(comp_conv2d(conv2d, X).shape)
可以先依据公式推算输出维度是多少。

4. 多输入多输出通道
当我们添加通道时,我们的输入和隐藏的表示都变成了三维张量。例如,每个RGB输入图像具有 3×h×w 的形状 。我们将这个大小为 3 的轴称为 通道(channel) 维度。
4.1. 多输入通道
当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数目的卷积核,以便与输入数据进行互相关运算。

import torch
from d2l import torch as d2l
def corr2d_multi_in(X, K):
print(list(zip(X, K)))
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
print(corr2d_multi_in(X, K))
###################
[(tensor([[0., 1., 2.],
[3., 4., 5.],
[6., 7., 8.]]), tensor([[0., 1.],
[2., 3.]])), (tensor([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]]), tensor([[1., 2.],
[3., 4.]]))]
zip函数记录
Python 函数 | zip 函数详解
当 zip() 函数有两个参数时,分别从两个参数中依次各取出一个元素组成元组,再将依次组成的元组组合成一个新的迭代器。

4.2. 多输出通道
随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作是对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。因此,多输出通道并不仅是学习多个单通道的检测器。

# K.shape == [2, 2, 2]
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
K = torch.stack((K, K + 1, K + 2), 0) # 每个元素+1, +2
# 0是选择维度
print(K.shape)
################
torch.Size([3, 2, 2, 2])
通过将核张量 K 与 K+1 ( K 中每个元素加 1 )和 K+2 连接起来,构造了一个具有 3 个输出通道的卷积核。
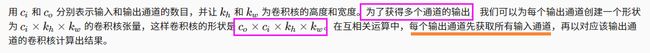
def corr2d_multi_in_out(X, K):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
K = torch.stack((K, K + 1, K + 2), 0)
print(corr2d_multi_in_out(X, K))

stack函数记录
torch.stack()的官方解释,详解以及例子
官方解释:沿着一个新维度对输入张量序列进行连接。 序列中所有的张量都应该为相同形状。
浅显说法:把多个2维的张量凑成一个3维的张量;多个3维的凑成一个4维的张量…以此类推,也就是在增加新的维度进行堆叠。
4.3 1×1 卷积层
1×1 卷积,即 k_h=k_w=1 ,看起来似乎没有多大意义。 毕竟,卷积的本质是有效提取相邻像素间的相关特征,而 1×1 卷积显然没有此作用。
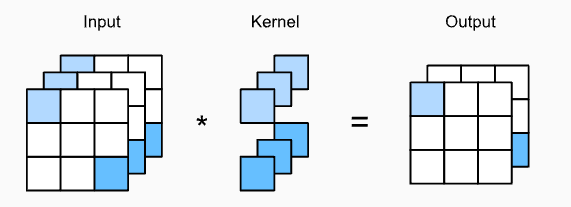
上图展示了使用 1×1 卷积核与 3 个输入通道和 2 个输出通道的互相关计算。 这里输入和输出具有相同的高度和宽度,输出中的每个元素都是从输入图像中同一位置的元素的线性组合。
卷积核有几组,就有几个输出通道。
我们可以将 1×1 卷积层看作是在每个像素位置应用的全连接层,以 c_i 个输入值转换为 c_o 个输出值。
把输入当作全连接层的输入,任取一组的核函数作为权重,进行相乘求和,得到输出。(和全连接层一模一样)。
同时, 1×1 卷积层需要的权重维度为 c_o×c_i ,再额外加上一个偏置。
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape # 通道,行,列
c_o = K.shape[0] # 通道
X = X.reshape((c_i, h * w)) # 展成3个条形数组
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
X = torch.normal(0, 1, (3, 3, 3)) # torch.Size([3, 3, 3])
K = torch.normal(0, 1, (2, 3, 1, 1)) # torch.Size([2, 3, 1, 1])
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
print(Y1) # torch.Size([2, 3, 3])
print(Y2) # torch.Size([2, 3, 3])
print(Y1 == Y2)
assert float(torch.abs(Y1 - Y2).sum()) < 1e-6
5 池化层pooling
池化(pooling)层,它具有双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。

5.1. 最大汇聚层和平均汇聚层
与卷积层类似,汇聚层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为 池化窗口)遍历的每个位置计算一个输出。
然而,不同于卷积层中的输入与卷积核之间的互相关计算,汇聚层不包含参数。 相反,池运算符是确定性的,我们通常计算池化窗口中所有元素的最大值或平均值。这些操作分别称为 最大汇聚层 (maximum pooling)和 平均汇聚层 (average pooling)。

池化窗口形状为 p×q 的汇聚层,称为 p×q 汇聚层。池化操作称为 p×q 池化。



import torch
from torch import nn
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
print(pool2d(X, (2, 2)))
print(pool2d(X, (2, 2), 'avg'))
####################
tensor([[4., 5.],
[7., 8.]])
tensor([[2., 3.],
[5., 6.]])
5.2. 填充padding和步幅stride
与卷积层一样,汇聚层也可以改变输出形状。和以前一样,我们可以通过填充和步幅以获得所需的输出形状。
import torch
from torch import nn
from d2l import torch as d2l
# 样本数和通道数都是 1
X = torch.arange(16, dtype=d2l.float32).reshape((1, 1, 4, 4))
# 默认情况下,深度学习框架中的步幅与池化窗口的大小相同
pool2d = nn.MaxPool2d(3) # (3,3)
print(pool2d(X)) # tensor([[[[10.]]]])
print(pool2d(X).shape) # torch.Size([1, 1, 1, 1])
# 填充和步幅可以手动设定。
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
print(pool2d(X))
# 设定一个任意大小的矩形池化窗口,并分别设定填充和步幅的高度和宽度。
pool2d = nn.MaxPool2d((2, 3), padding=(1, 1), stride=(2, 3))
print(pool2d(X))
默认情况下,深度学习框架中的步幅与池化窗口的大小相同。
5.3. 多个通道
X = torch.cat((X, X + 1), 1) #在X的第一维上进行连接(从零开始计数)
print(X)
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
print(pool2d(X))
###############
X.shape:torch.Size([1, 1, 4, 4]), X.shape.cat:torch.Size([1, 2, 4, 4])
cat函数记录
PyTorch的torch.cat
torch.cat是将两个张量(tensor)拼接在一起,cat是concatenate的意思,即拼接,联系在一起。
6. 卷积神经网络(LeNet)
通过之前几节,我们学习了构建一个完整卷积神经网络的所需组件。 回想一下,之前我们将 softmax 回归模型和多层感知机模型应用于 Fashion-MNIST 数据集中的服装图片上。 为了能够应用 softmax 回归和多层感知机,我们首先将每个大小为 28×28 的图像展平为一个 784 固定长度的一维向量,然后用全连接层对其进行处理。 而现在,我们已经掌握了卷积层的处理方法,我们可以在图像中保留空间结构。 同时,用卷积层代替全连接层的另一个好处是:更简洁的模型所需的参数更少。
6.1. LeNet
总体来看,LeNet(LeNet-5)由两个部分组成:
卷积编码器: 由两个卷积层组成 ;
全连接层密集块:由三个全连接层组成。

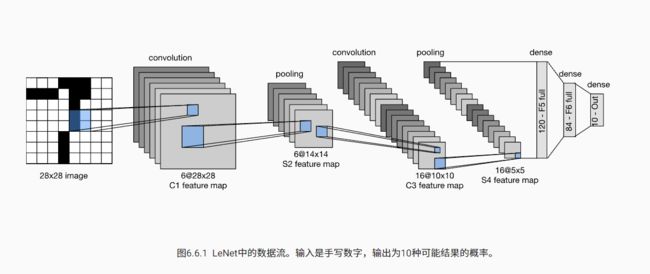
每个卷积块中的基本单元是一个卷积层、一个 sigmoid 激活函数和平均汇聚层。
每个卷积层使用 5×5 卷积核和一个 sigmoid 激活函数。这些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有 6 个输出通道,而第二个卷积层有 16 个输出通道。
每个 2×2 池操作通过空间下采样将维数减少 4 倍。卷积的输出形状由批量大小、通道数、高度、宽度决定。
为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本。
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
class Reshape(torch.nn.Module):
def forward(self, x):
return x.view(-1, 1, 28, 28) # 相当于numpy中resize的功能
net = torch.nn.Sequential(
Reshape(),
# 第1层
nn.Conv2d(1, 6, kernel_size=5,padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
# 第2层
nn.Conv2d(6, 16, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
# 展开成行向量
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10)
)
对原始模型做了一点小改动,去掉了最后一层的高斯激活。
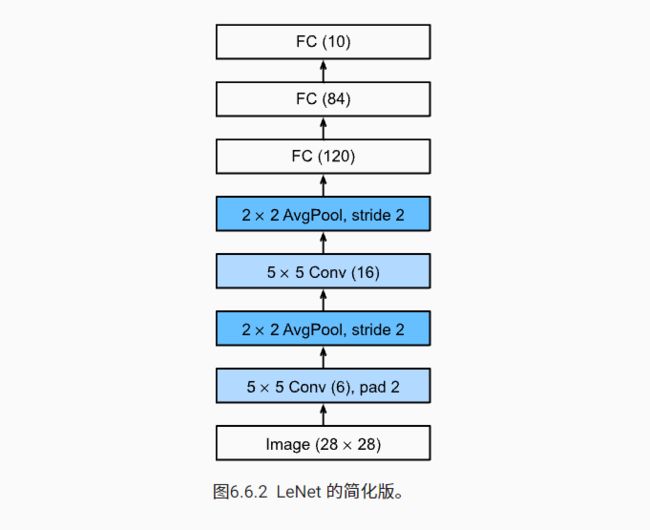
打印来检测每层的输出。
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape :\t', X.shape)
######################
Reshape output shape: torch.Size([1, 1, 28, 28])
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
6.2. 模型训练
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy_gpu(net, data_iter, device=None):
if isinstance(net, torch.nn.Module): # 判断类型是否相同,返回布尔值
net.eval()
if not device:
device = next(iter(net.parameters())).device
metric = d2l.Accumulator(2)
for X, y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0]/metric[1]
net.eval()函数记录:
神经网络模块存在两种模式,train模式(net.train())和eval模式(net.eval())。一般的神经网络中,这两种模式是一样的,只有当模型中存在dropout和batchnorm的时候才有区别。
为了使用 GPU,我们还需要一点小改动。在进行正向和反向传播之前,我们需要将每一小批量数据移动到我们指定的设备(例如 GPU)上。
def train(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)。"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,范例数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
lr, num_epochs = 0.9, 10
train(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
