论文笔记:Learning with Noisy Labels for Sentence-level Sentiment Classification
emnlp 2019
0 摘要
深度神经网络 (DNN) 可以很好地拟合(甚至过度拟合)训练数据。 如果 DNN 模型使用带有噪声标签的数据进行训练,并在带有干净标签的数据上进行测试,则该模型可能表现不佳。 本文研究了使用噪声标签进行句子级情感分类的学习问题。 我们提出了一种新的 DNN 模型,称为 NETAB(作为带有 AB 网络的卷积神经网络的简写)来处理训练期间的噪声标签。 NETAB 由两个卷积神经网络组成,一个具有噪声转换层,用于处理输入噪声标签,另一个用于预测“干净”标签。 我们使用它们各自的损失函数以相互增强的方式训练这两个网络。 实验结果证明了所提出模型的有效性。
1 introduction
众所周知,情感标签是主观的。 注释者经常有很多分歧。 对于没有受过良好训练的群众工作者来说尤其如此。 这就是为什么人们总是觉得带注释的数据集中有很多错误。 在本文中,我们研究了即使使用带有噪声标签的训练数据,是否也可以构建准确的情感分类器。 情感分类旨在根据文本中表达的情感的极性对一段文本进行分类,例如正面或负面 在这项工作中,我们专注于带有标签错误的句子级情感分类(SSC)。
正如我们将在实验部分看到的那样,训练数据中的噪声标签可能具有很大的破坏性,尤其是对于 DNN,因为它们很容易拟合训练数据并记住它们的标签,即使训练数据被噪声标签破坏。 收集带有干净标签注释的数据集既昂贵又耗时,因为基于 DNN 的模型通常需要大量训练示例。 研究人员和从业者通常不得不求助于众包。 然而,如上所述,众包注释可能非常嘈杂。
问题定义: 给定有噪声的标记训练句子 S = {(x1, y1), ..., (xn, yn)},其中
是第 i 个句子,yi ∈ {1, ..., c} 是这个句子的情感标签,带噪声的标签句子用于训练 SSC 任务的 DNN 模型。 然后使用经过训练的模型将具有干净标签的句子分类为 c 个情感标签之一。
在本文中,我们提出了一种带有 AB 网络 (NETAB) 的卷积神经网络来处理训练期间的噪声标签,如图 1 所示。我们将在后续章节中介绍详细信息。
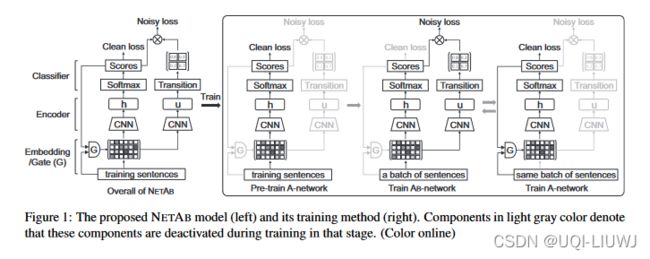
基本上,NETAB 由两个卷积神经网络 (CNN) 组成(见图 1),一个用于学习情绪分数以预测“干净”1标签,另一个用于学习噪声转换矩阵以处理输入噪声标签。我们将这两个 CNN 分别称为 A-network 和 AB-network。
这里的基础是
(1)DNNs 首先记忆简单的实例,然后随着训练时期的增加逐渐适应困难的实例
(2) 理论上,噪声标签通过噪声转换矩阵从干净/真实标签中转换得到。
我们提出了一个带有转换层的 CNN 模型来估计输入噪声标签的噪声转换矩阵,同时利用另一个 CNN 来预测训练(和测试)句子的“干净”标签。
在训练中,我们在早期阶段预训练 A 网络,然后以交替的方式训练 AB 网络和 A 网络,它们具有各自的损失函数。
2 related work
略
3 proposed model
我们的模型建立在 CNN 之上。 关键思想是交替训练两个 CNN,一个用于处理输入噪声标签,另一个用于预测“干净”标签。 所提出模型的整体架构如图 1 所示。在进一步讨论之前,我们首先在下面介绍一个命题、一个属性和一个假设。
命题 1: 噪声标签通过未知噪声转移矩阵从干净标签转换得到。
这个命题表明,如果我们知道噪声转移矩阵,我们可以用它来恢复干净的标签。 换句话说,我们可以将噪声转移矩阵放在干净的标签上来处理噪声标签。 鉴于这些,我们提出以下问题:如何估计这样一个未知的噪声转移矩阵? 下面我们根据 DNN 的以下特性给出这个问题的解决方案。
属性 1 DNN 倾向于优先记忆简单实例,然后逐渐记忆困难实例。
我们的设置是简单的实例是干净标签的句子,而复杂困难的实例是带有嘈杂标签的句子。 我们也有以下假设。
假设 1 训练数据的噪声率小于 50%。
这个假设通常在实践中得到满足,因为没有它,在训练期间很难处理输入噪声标签。
基于以上的先验知识,我们需要预测噪声转移矩阵
(在这个问题中,c=2,即正向or负向),并且训练两个分类器
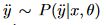
。其中x是输入序列,
是噪声标签,
是干净标签。(这两个都是模型的预测结果,并不是输入标签)。
分别是两个分类器的参数
我们定义将句子x标记为类别y的概率为:
其中
是噪声转化矩阵Q中的第ji项。
我们现在展示我们的模型 NETAB 并介绍 NETAB 如何执行前面说的公式 (1)。 如图 1 所示,NETAB 由两个 CNN 组成。 我们使用一个 CNN 计算干净标签概率
,并使用另一个 CNN 计算噪声标签概率
。
同时, 计算噪声标签概率
更准确地说,在图 1 中,具有clean loss的 CNN 执行
AB-network 共享 A-network 的所有参数,除了来自 Gate unit 和 clean loss 的参数。
此外,ABnetwork 有一个转换层来估计噪声转换矩阵 Q。
这样,A 网络预测“干净”标签,AB 网络处理输入噪声标签。
我们使用带有预测标签
其中 I 是指标函数(如果 y == i,I = 1;否则,I = 0),
是每batch训练 AB 网络的句子数。
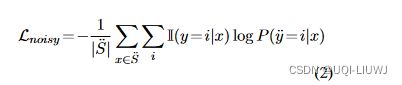
类似地,我们使用带有预测标签
其中
每batch训练 A 网络的句子数。
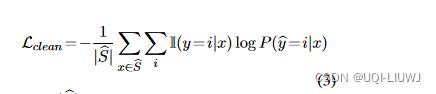
接下来我们介绍我们的模型如何学习参数
。 通过查找预先训练的词嵌入数据库(例如,GloVe.840B),为每个句子 x 生成一个嵌入矩阵 v。
然后为 A网络(和 AB-网络)中的每个嵌入矩阵 v 生成一个编码向量 h = CN N (v)(和 u = CN N (v))。
sofmax 分类器在学习到的编码向量 h 上为我们提供
由于噪声转换矩阵 Q 表示从干净标签到噪声标签的转换值,我们如下计算Q矩阵:
其中W是可训练矩阵,b和f是可训练向量,他们都在AB网络中训练
然后
求得
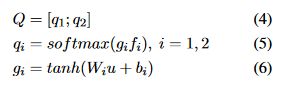
在训练中,NETAB 是端到端训练的。 基于命题 1 和属性 1,我们在早期阶段(例如,前5个epoch)预训练 A 网络。 然后我们以交替的方式训练 AB-network 和 A-network。
这两个网络使用它们各自的交叉熵损失进行训练。
给定一批句子,我们首先训练 AB-network。 然后我们使用从 A-network 预测的分数从这批中选择一些可能“干净”的句子,并在所选句子上训练 A-network。
具体来说,我们使用预测分数通过
计算情感标签。 然后我们选择结果情感标签等于输入标签的句子。 选择过程由图 1 中的 Gate 单元标记。
在测试句子时,我们使用 A-network 产生最终的分类结果。
【也就是说,我先通过AB-network获得带有noise的情感分类,看哪些带噪声的情感分类结果和原来的input label一样,然后拿这些句子train A-network】
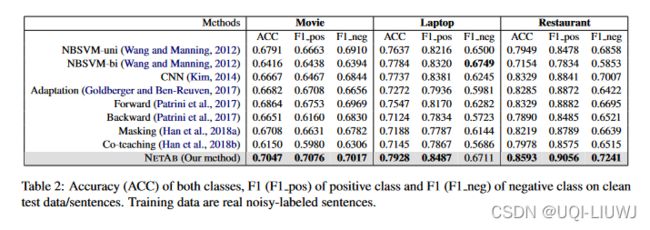
4 实验
在本节中,我们评估所提出的 NETAB 模型的性能。 我们进行两种类型的实验。
(1) 我们破坏干净标记的数据集以生成带有噪声标记的数据集,以显示噪声对情感分类准确性的影响。
(2) 我们收集了一些真实的噪声数据,并用它们来训练模型来评估 NETAB 的性能。
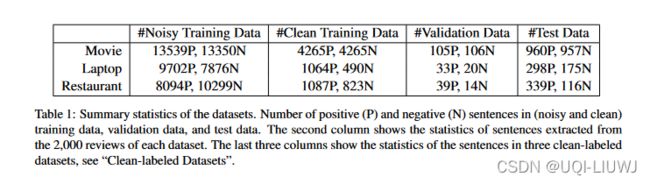
干净标记的数据集。
我们使用三个干净的标记数据集。 第一个是来自 电影句子极性数据集。 另外两个数据集是从 笔记本电脑和餐厅数据集,前者由笔记本电脑评论句子组成,后者由餐厅评论句子组成。
原始数据集(笔记本电脑和餐厅)在每个句子中都用方面极性进行了注释。 我们使用所有只有一种极性(正面或负面)的句子。 也就是说,我们只使用在一整个句子中具有相同情感标签的句子。
对于每个干净标记的数据集,句子被随机划分为训练集和测试集,分别占 80% 和 20%。我们还随机选择 10% 的测试数据进行验证,以在训练期间检查模型。
嘈杂标记的训练数据集。
对于上述三个领域(电影、笔记本电脑和餐厅),我们从同一评论来源为每个领域收集了 2,000 条评论。 我们从每条评论中提取句子,并将评论的标签分配给它的句子。 与之前的工作一样,我们将 4 或 5 颗星视为正面,将 1 或 2 颗星视为负面。 数据是嘈杂的,因为正面(负面)评论可以包含负面(正面)句子,也有中性句子。 这为我们提供了三个带有噪声标记的训练数据集。 我们仍然使用与干净标记数据集相同的测试集。
实验 1:这里我们使用干净标记的数据。 我们通过基于噪声率参数切换一些随机实例的标签来破坏干净的训练数据。 然后我们使用有噪声的数据来训练 NETAB 和 CNN。
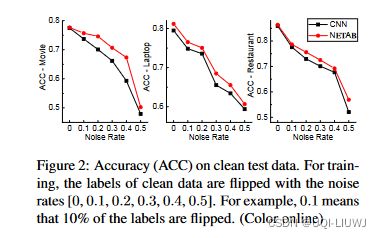
噪声率为[0, 0.1, 0.2, 0.3, 0.4, 0.5]的测试精度曲线如图2所示。
从图中我们可以看到,当噪声率从 0 增加到 0.5 时,测试精度从 0.8 左右下降到 0.5,但我们的 NETAB 优于 CNN。 结果清楚地表明,随着噪声率的增加,CNN 的性能下降了很多。
实验 2:这里我们使用真实的有噪声标记的训练数据来训练我们的模型和基线,然后在表 1 中的测试数据上进行测试。我们的目标是双重的。 首先,我们想使用真实的噪声数据评估 NETAB。 其次,我们想看看是否可以使用带有评论级别标签的句子来构建有效的 SSC 模型。