linux下用shell做成绩统计,Linux探索之旅 | 第五部分第八课:用Shell做统计练习
内容简介
前言
成果展示
解题步骤和答案
可能的优化
第五部分第九课预告
1. 前言
这个练习用一个 Shell 脚本来生成一个 HTML 文件,这个 HTML 文件是一个展示图片缩略图的网页,点击每个缩略图还会链接到原始图片。
这一课我们继续做一个进阶的 Shell 脚本练习。这个练习要实现的是对一个英语字典做统计。
通过这个练习,你将巩固 Shell 和 Linux 的知识点。
为了完成它,我们需要用到一个文本文件:words.txt。这是一个包含 354935 个英文单词的字典,请从我的 Github 上下载 (下面也会给出百度云盘下载链接):
你可以选择 git clone 到你本地目录,或者下载 zip 压缩包。然后提取里面的 words.txt 文件即可。
对于不用 Github 的朋友,我也把字典文件上传到百度云盘了,请 点我下载 。
当然了,如果你自己能在网上找到其他完整的英文字典的文本文档也可以,不一定要用我这个。
2. 成果展示
我们要用到的字典文本文档里的内容类似如下:
字典开头
字典结尾
我们要写一个 Shell 脚本,来显示这个庞大的字典中 26 个英文字母(从 a 到 z )出现的次数,而且以次数最多到最少的顺序排列。
成果是像下面这样的:
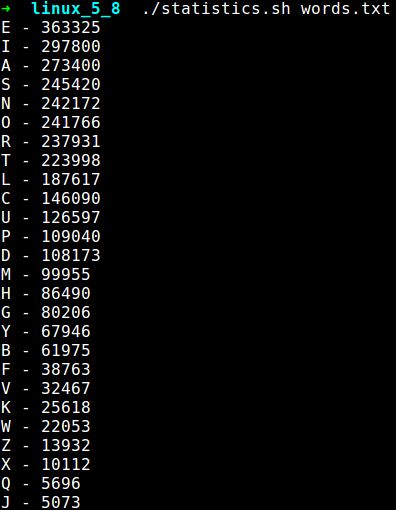
可以看到,字母 e 出现的次数最多,是 363325 次; 字母 j 出现的次数最少,是 5073 次。
下面给出我的解题步骤和答案,希望大家最好先不看答案,尝试着自己解决问题,然后再来看答案。
你的解法也许比我还要好。相信你可以的,加油!
3. 解题步骤和答案
首先,我们创建一个文件夹,然后把 words.txt 这个字典文件放进去。
然后,我们在文件夹中创建一个文件,就是我们的脚本,叫 statistics.sh 好了,因为 statistics 是英语「统计」的意思。
vim statistics.sh
你也许还会在使用一些命令时忘了如何用,那你可以查一下命令的使用手册 ( Linux探索之旅 | 第二部分第八课:RTFM 阅读那该死的手册 )。
根据上面的成果那张截图,我们可以看到要实现的是 :
「在终端打印出结果,按照字母出现的次数来排列,由最多到最少。在次数左边,依次是 该次数对应的字母、空格、短横杠、空格。而且每个字母是大写的(在字典文件中字母都是小写,因此需要小写到大写的转换)」。
因此,我们首先需要统计每个字母出现的次数。
怎么做呢?我们想到了 grep 命令,它可以帮助我们在文件中查找所需的字母。
我们首先用命令行来测试,之后再着手编写我们的 statistics.sh 这个文件。
首先,在命令行中输入以下命令:
grep -io a words.txt
回车运行后可以看到输出了许多行,每一行包含一个 a。
因为 grep 就是用于在文件中查找关键字,并且显示关键字所在的行。
这里我们用了 -i 和 -o 两个参数。-i 参数我们之前学过,是 ignore-case 的简写,表示「忽略大小写」。
而-o 这个参数我们之前没学过,不过可以用 man grep 来看看:
man grep
![]()
可以看到 -o 参数中的 o 是英语 only-matching 的简写,表示「只匹配」。其描述 「 Print only the matched (non-empty) parts of a matching line, with each such part on a separate output line. 」可以翻译为 「只显示匹配行中不为空的那个匹配的部分,每个这样的部分被单独显示在一行上」。
如果不加 -o 参数而直接用
grep -i a words.txt
那么输出是这样的:
理解了吗?不加 -o 参数,那么 grep 就会输出每一个包含 a 的行。而每一行 (字典文件中一行有一个单词)也许包含不止一个 a。因此为了统计所有的 a,我们须要加上 -o 参数。
既然我们已经用 grep -io a words.txt 命令来输出了所有字母 a 的 出现(逐行显示),那么我们可以用 wc -l 命令来统计行数,即可知道 a 的出现次数了。
接下来我们就用管道来把 grep 命令的结果赋给 wc 命令:
grep -io a words.txt | wc -l
![]()
可以看到输出是 273400,表示 words.txt 文件中字母 a 出现了 273400 次。
我们也可以不加 -o 参数来测试一下:
grep -i a words.txt | wc -l
![]()
可以看到输出是 206518,比 273400 少了很多,因为不加 -o 参数只统计了 a 出现的那些行(相当于统计了包含 a 的单词数目),而不是统计 a 的真正出现次数。
我们现在已经知道如何统计字母 a 的次数了,那么举一反三,统计其他 25 个字母也不在话下。我们可以用一个循环语句来实现:
for char in {a..z}; do
grep -io "$char" words.txt | wc -l
done
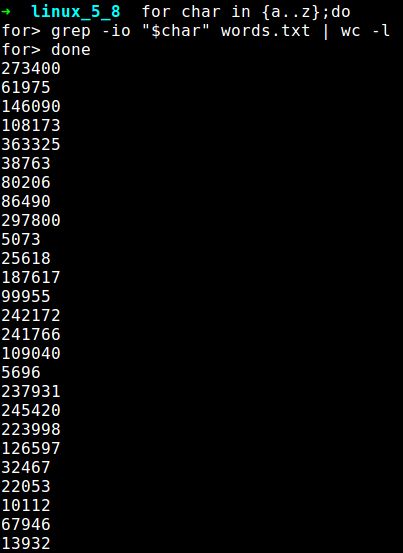
可以看到我们在终端输入 for 循环语句后,依次打印出了 a, b, c, 一直到 z 这 26 个字母在 words.txt 文件中出现的次数。
虽然现在我们只是开了个头,但是已经可以来写我们的 Shell 脚本了。
我们首先写一些基础的部分:
#!/bin/bash
# Verification of parameter
# 确认参数
if [ -z $1 ]
then
echo "Please enter the file of dictionary !"
exit
fi
# Verification of file existence
# 确认文件存在
if [ ! -e $1 ]
then
echo "Please make sure that the file of dictionary exists !"
exit
fi
上面两段代码分别用于确认参数和确认文件存在,如果不满足 if 条件,那么用 echo 显示提示信息,然后用 exit 命令退出 Shell。
然后,我们来定义一个函数,就叫 statistics 好了,我们继续在 statistics.sh 这个文件中加入以下代码:
```