pandas快速上手
1.简单介绍
pandas库是基于NumPy构建的,它含有使数据分析工作变得更快更简单的高级数据结构和操作工具,让以NumPy为中心的应用变得更加简单。下面简单介绍pandas的一些功能。
2.两种主要数据结构Series和DataFrame的创建
2.1 Series的创建
代码示例:
import numpy as np
import pandas as pd
s1=pd.Series(range(3))
s2=pd.Series({'a':1.,'b':2.,'c':3.})
s3=pd.Series(range(1,7), index=pd.date_range('20180101', periods=6))
print('s1')
print(s1)
print('s2')
print(s2)
print('s3')
print(s3)运行结果:

2.2 DataFrame的创建
代码示例:
df=pd.DataFrame(np.tile(np.arange(1,9),8).reshape(8,8),
index=list('CDABefGH'),columns=list('42760513'))
df.index.name='group'
df.columns.name='col'
print('df')
print(df)运行结果:

3.把数据保存到CSV文件
代码示例:
df.to_csv('D:\Jupyter\data_df.csv')运行结果:

4.从CSV文件读取数据
代码示例:
df1=pd.read_csv('D:\Jupyter\data_df.csv',index_col=['group'])
df1.columns.name='col'
print('df1')
print(df1)运行结果:

5.转置
代码示例:
df1t=df1.T
print('df1t')
print(df1t)运行结果:

6.添加和删除一列
代码示例:
df2=df1.copy()
df2['group1']=list('cdabefgh')
df2.drop('0',axis=1,inplace=True)
#上面这行代码可以用del df2['0']代替,但只能用于删除列
print('df2')
print(df2)运行结果:

7.索引排序及重命名
代码示例:
df3=df2.reindex(index=list('ABCDefGH'))
df3.sort_index(axis=1,inplace=True)
df3.rename(index={'e':'E','f':'F'},inplace=True)
print('df3')
print(df3)运行结果:

8.重新设置索引
代码示例:
df4=df3.reset_index().set_index('group1')
print('df4')
print(df4)运行结果:

9.选择
loc用于选择轴标签的闭合区间,iloc根据索引的默认整数位置进行选择。
代码示例:
df5=df4.loc['a':'c','1':'4']
df6=df4.iloc[3:8,[0,1,2,3,7]]
print('df5')
print(df5)
print('df6')
print(df6)运行结果:

10.简单合并
代码示例:
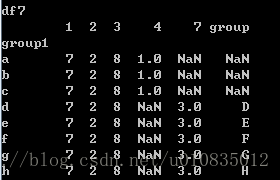
df7=pd.concat([df5,df6],sort=True)
print('df7')
print(df7)运行结果:
11.值替换
代码示例:
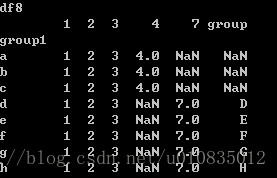
df8=df7.replace({7:1,8:3,1:4,3:7})
print('df8')
print(df8)运行结果:
12.缺失数据处理
代码示例:
df9=df8.copy()
df9[:1]=df9[:1].fillna(0)
#用0代替第1行的NaN
df9.fillna(method='bfill',limit=1,inplace=True)
#用下一行的值代替NaN,只改变一行
df9.dropna(thresh=5,inplace=True)
#删除b行,因为b行只有4个非NaN值
df9.fillna(df9.sum(),inplace=True)
#剩下的NaN用该列其它行数字之和代替
print('df9')
print(df9)运行结果:

13.简单聚合
示例代码:
grouped=df9.groupby(['4','group1'])
df10=grouped.mean()
print('df10')
print(df10)运行结果:

14.轴向旋转,stack与unstack
stack可以把宽数据变成长数据,unstack则把长数据变成宽数据。
代码示例:
df11=df10.unstack('4').fillna(0)
df12=df11.stack()
print('df11')
print(df11)
print('df11.stack()')
print(df12)运行结果:


15.层次化索引重排顺序,swaplevel与sortlevel
代码示例:
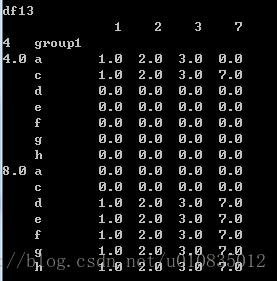
df13=df12.swaplevel(0,1).sort_index(level=0)
print('df13')
print(df13)运行结果:
16.根据级别汇总统计
代码示例:
df14=df13.sum(level='4')
print('df14')
print(df14)运行结果:

全部代码示例:
import numpy as np
import pandas as pd
'''Series的创建'''
s1=pd.Series(range(3))
s2=pd.Series({'a':1.,'b':2.,'c':3.})
s3=pd.Series(range(1,7), index=pd.date_range('20180101', periods=6))
print('s1')
print(s1)
print('s2')
print(s2)
print('s3')
print(s3)
'''DataFrame的创建'''
df=pd.DataFrame(np.tile(np.arange(1,9),8).reshape(8,8),
index=list('CDABefGH'),columns=list('42760513'))
df.index.name='group'
df.columns.name='col'
print('df')
print(df)
'''把数据保存到CSV文件'''
df.to_csv('D:\Jupyter\data_df.csv')
'''从CSV文件读取数据'''
df1=pd.read_csv('D:\Jupyter\data_df.csv',index_col=['group'])
df1.columns.name='col'
print('df1')
print(df1)
'''转置'''
df1t=df1.T
print('df1t')
print(df1t)
'''添加和删除一列'''
df2=df1.copy()
df2['group1']=list('cdabefgh')
df2.drop('0',axis=1,inplace=True)
#上面这行代码可以用del df1['0']代替,但del只能用于删除列
print('df2')
print(df2)
'''索引排序及重命名'''
df3=df2.reindex(index=list('ABCDefGH'))
df3.sort_index(axis=1,inplace=True)
df3.rename(index={'e':'E','f':'F'},inplace=True)
print('df3')
print(df3)
'''重新设置索引,set_index和reset_index'''
df4=df3.reset_index().set_index('group1')
print('df4')
print(df4)
'''选择,loc和iloc'''
df5=df4.loc['a':'c','1':'4']
df6=df4.iloc[3:8,[0,1,2,3,7]]
print('df5')
print(df5)
print('df6')
print(df6)
'''简单合并,concat'''
df7=pd.concat([df5,df6],sort=True)
print('df7')
print(df7)
'''值替换,replace'''
df8=df7.replace({7:1,8:3,1:4,3:7})
print('df8')
print(df8)
'''缺失数据处理,fillna和dropna'''
df9=df8.copy()
df9[:1]=df9[:1].fillna(0)
#用0代替第1行的NaN
df9.fillna(method='bfill',limit=1,inplace=True)
#用下一行的值代替NaN,只改变一行
df9.dropna(thresh=5,inplace=True)
#删除b行,因为b行只有4个非NaN值
df9.fillna(df9.sum(),inplace=True)
#剩下的NaN用该列其它行数字之和代替
print('df9')
print(df9)
'''简单聚合,groupby'''
grouped=df9.groupby(['4','group1'])
df10=grouped.mean()
print('df10')
print(df10)
'''轴向旋转,stack与unstack'''
df11=df10.unstack('4').fillna(0)
df12=df11.stack()
print('df11')
print(df11)
print('df11.stack()')
print(df12)
'''层次化索引重排顺序,swaplevel与sortlevel'''
df13=df12.swaplevel(0,1).sort_index(level=0)
print('df13')
print(df13)
'''根据级别汇总统计'''
df14=df13.sum(level='4')
print('df14')
print(df14)