【论文学习】《A Survey on Neural Speech Synthesis》
《A Survey on Neural Speech Synthesis》论文学习
文章目录
- 《A Survey on Neural Speech Synthesis》论文学习
-
- 摘要
- 1 介绍
-
- 1.1 TTS 技术的历史
- 1.2 调查的组成
- 2 TTS 中的关键组件
-
- 2.1 主要分类
- 2.2 文本分析
- 2.3 声学模型
-
- 2.3.1 SPSS 中的声学模型
- 2.3.2 端到端 TTS 中的声学模型
- 2.4 声码器
- 2.5 面向完全端到端 TTS
- 2.6 其他分类
- 3 TTS 中的高级主题
-
- 3.1 背景与分类
- 3.2 快速 TTS
- 3.3 低资源 TTS
- 3.4 鲁棒 TTS
-
- 3.4.1 增强注意力
- 3.4.2 用持续时间预测取代注意力
- 3.4.3 增强 AR 生成
- 3.4.4 用 NAR 代取代 AR 生成
- 3.5 富有表现力的 TTS
-
- 3.5.1 变异信息的分类
- 3.5.2 建模变异信息
- 3.5.3 解缠、控制和转移
- 3.6 自适应 TTS
-
- 3.6.1 一般适应
- 3.6.2 高效适应
- 4 资源
- 5 未来方向
摘要
文本到语音( Text to speech , TTS ),又叫语音合成,其目的是从给定文本合成可理解和自然语音,是语音、语言和机器学习领域的一个热点研究课题,在业界有着广泛的应用。
近年来,随着深度学习和人工智能的发展,基于神经网络的 TTS 大大提高了合成语音的质量。
在本文中,我们对神经 TTS 进行了一个全面的调查,旨在提供一个良好的研究现状和未来的趋势。
我们重点讨论了神经网络 TTS 的关键组成部分,包括文本分析、声学模型和声码器,以及一些高级主题,包括快速 TTS 、低资源 TTS 、鲁棒 TTS 、表达性 TTS 和自适应 TTS 等。
我们进一步总结了与 TTS 相关的资源(如数据集、开源实现),并讨论了未来的研究方向。
这项调查可以服务于从事 TTS 研究的学术研究者和行业从业者。
1 介绍
文本到语音( Text to speech , TTS ),又称语音合成( speech synthesis ),旨在从文本中合成出可理解、自然的语音(《Text-to-speech synthesis》),在人类交际中有着广泛的应用(《Understanding Human Communication》),一直是人工智能、自然语言和语音处理领域的研究课题(《Artificial intelligence: a modern approach》,《Foundations of statistical natural language processing》,《Speech & language processing》)。
开发一个 TTS 系统需要关于语言和人类语音产生的知识,涉及多个学科,包括语言学(《Course in general linguistics》)、声学(《Fundamentals of acoustics》)、数字信号处理(《Digital signal processing》)和机器学习(《Pattern recognition and machine learning》,《Machine learning: Trends, perspectives, and prospects》)。
随着深度学习的发展(《Deep learning》),基于神经网络的 TTS 蓬勃发展,针对神经 TTS 不同方面的大量研究工作应运而生(《Statistical parametric speech synthesis using deep neural networks》,《Wavenet: A generative model for raw audio》,《Tacotron: Towards end-to-end speech synthesis》,《Natural tts synthesis by conditioning wavenet on mel spectrogram predictions》,《Efficient neural audio synthesis》,《Deep voice 3: 2000-speaker neural text-to-speech》,《Neural speech synthesis with transformer network》,《Fastspeech: Fast, robust and controllable text to speech》)。
因此,近年来合成语音的质量有了很大的提高。
了解目前的研究现状,找出尚未解决的研究问题,对于从事 TTS 工作的人是非常有帮助的。
虽然有多个调查论文统计参数语音合成(《Statistical parametric speech synthesis》,《Speech synthesis based on hidden markov models》,《Acoustic modeling in statistical parametric speech synthesis-from hmm to lstm-rnn》)和神经 TTS (《Speech synthesis techniques. a survey》,《A survey on text to speech translation of multi language》,《Survey on various methods of text to speech synthesis》,《A review of deep learning based speech synthesis》,《Towards robust neural vocoding for speech generation: A survey》,《A survey on speech synthesis techniques in indian languages》,《Review of end-to-end speech synthesis technology based on deep learning》),全面调查神经 TTS 的基础知识和最新发展仍然是必要的因为这一领域的主题是多样的和迅速发展。
本文对神经系统 TTS 进行了深入而全面的研究。
在接下来的章节中,我们首先简要回顾了 TTS 技术的发展历史,然后介绍了神经 TTS 的一些基本知识,最后概述了本研究的概况。
1.1 TTS 技术的历史
早在 12 世纪,人们就尝试建造机器来合成人类语音。
18 世纪下半叶,匈牙利科学家沃尔夫冈·冯·肯佩伦( Wolfgang von Kempelen )用一系列的风箱、弹簧、风笛和共振箱制造出一些简单的单词和短句(《The speaking machine of wolfgang von kempelen》),制造出了一个会说话的机器。
第一个建立在计算机上的语音合成系统出现在 20 世纪下半叶。
早期基于计算机的语音合成方法包括发音合成(《A model of articulatory dynamics and control》,《Prospects for articulatory synthesis: A position paper》)、共振峰合成(《Automatic generation of control signals for a parallel formant speech synthesizer》,《Mitalk-79: The 1979 mit text-to-speech system》,《Software for a cascade/parallel formant synthesizer》,《Review of text-to-speech conversion for english》)和串联合成(《Rule synthesis of speech from dyadic units》,《Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones》,《Atr µ-talk speech synthesis system》,《Unit selection in a concatenative speech synthesis system using a large speech database》,《The festival speech synthesis system》)。
后来,随着统计机器学习的发展,统计参数语音合成( statistical parametric speech synthesis, SPSS )被提出(《Simultaneous modeling of spectrum, pitch and duration in hmm-based speech synthesis》,《Speech parameter generation algorithms for hmm-based speech synthesis》,《Statistical parametric speech synthesis》,《Speech synthesis based on hidden markov models》),用于预测语音合成的频谱、基频、持续时间等参数。
从 2010 年开始,基于神经网络的语音合成(《Statistical parametric speech synthesis using deep neural networks》,《On the training aspects of deep neural network (dnn) for parametric tts synthesis》,《TTS synthesis with bidirectional lstm based recurrent neural networks》,《Unidirectional long short-term memory recurrent neural network with recurrent output layer for low-latency speech synthesis》,《First step towards end-to-end parametric tts synthesis: Generating spectral parameters with neural attention》,《Emphasis: An emotional phoneme-based acoustic model for speech synthesis system》,《Wavenet: A generative model for raw audio》,《Tacotron: Towards end-to-end speech synthesis》)逐渐成为语音合成的主导方法,取得了更好的语音质量。
发音参数合成
发音合成通过模拟人类的发音器官如嘴唇、舌头、声门和活动声道的行为来产生语音。
理想情况下,发音合成是最有效的语音合成方法,因为它是人类产生语音的方式。
然而,在实践中很难对这些关节行为进行建模。
例如,关节模拟的数据收集是困难的。
因此,发音合成的语音质量通常比后共振峰合成和串联合成的语音质量差。
共振峰合成法
共振峰合成基于一组控制简化源滤波器模型的规则产生语音。
这些规则通常是由语言学家开发的,以尽可能接近地模仿共振峰结构和语音的其他光谱特性。
语音是由一个附加的合成模块和一个具有不同参数如基频、语音和噪声水平的声学模型合成的。
共振峰合成可以产生高度可理解的语音,计算资源适中,非常适合于嵌入式系统,而且不像串联合成那样依赖于大规模的人类语音语料库。
然而,合成的语音听起来不那么自然,而且有人工痕迹。
此外,很难为合成指定规则。
拼接合成
连接合成依赖于存储在数据库中的语音片段的连接。
通常,该数据库由语音单元组成,从完整的句子到配音演员录制的音节。
在推理中,串联式 TTS 系统搜索语音单元以匹配给定的输入文本,并通过串联这些单元产生语音波形。
一般来说,串联式 TTS 可以产生具有高清晰度和真实音色接近原始声优的音频。
然而,串联式 TTS 需要庞大的录音数据库来覆盖所有可能的语音单元组合。
另一个缺点是生成的声音不那么自然和情绪化,因为串联会导致在重音、情绪、韵律等方面不那么流畅。
统计参数语音合成
为了解决串联式 TTS 的缺点,提出了统计参数语音合成( SPSS )。
其基本思想是,我们可以先生成生成语音所需的声学参数(《An adaptive algorithm for mel-cepstral analysis of speech》,《Mel-generalized cepstral analysis-a unified approach to speech spectral estimation》,《Restructuring speech representations using a pitch-adaptive time frequency smoothing and an instantaneous-frequencybased f0 extraction: Possible role of a repetitive structure in sounds》),然后使用一些算法(《Mel log spectrum approximation (mlsa) filter for speech synthesis》,《Cepstral analysis synthesis on the mel frequency scale》,《Straight, exploitation of the other aspect of vocoder: Perceptually isomorphic decomposition of speech sounds》,《World: a vocoder-based high-quality speech synthesis system for real-time applications》)从生成的声学参数中恢复语音,而不是通过串联直接产生波形。
SPSS 通常由三部分组成:文本分析模块、参数预测模块(声学模型)和声码器分析/合成模块(声码器)。
文本分析模块首先对文本进行处理,包括文本归一化(《Normalization of non-standard words》)、字素音素转换(《Joint-sequence models for grapheme-to-phoneme conversion》)、分词等,然后从不同粒度中提取语音、持续时间、词性标签等语言特征。
使用配对的语言特征和参数(声学特征)来训练声学模型(例如,基于隐马尔科夫模型( HMM )),其中声学特征包括基频、频谱或倒谱等,并通过声码分析从语音中提取。
声码器根据预测的声学特征合成语音。
SPSS 比以前的TTS系统有几个优势:
1)自然,音频更自然;
2)灵活性,方便修改参数控制语音生成;
3)数据成本低,比串联合成需要更少的记录。
然而, SPSS 也有它的缺点:
1)生成的语音具有较低的可理解性,由于人为因素,如低沉的,嗡嗡声或嘈杂的音频;
2)生成的声音仍然是机器人的,可以很容易地区别于人类录音的语音。
近 2010 年,随着神经网络和深度学习的快速发展,一些工作首先将深度神经网络引入 SPSS ,如基于深度神经网络( DNN )(《Statistical parametric speech synthesis using deep neural networks》,《On the training aspects of deep neural network (dnn) for parametric tts synthesis》)和基于循环神经网络( RNN )(《Acoustic modeling in statistical parametric speech synthesis-from hmm to lstm-rnn》,《Unidirectional long short-term memory recurrent neural network with recurrent output layer for low-latency speech synthesis》)。
然而,这些模型用神经网络代替了 HMM ,仍然可以从语言特征中预测声音特征,这是遵循 SPSS 的范式。
后来, Wang 等人(《First step towards end-to-end parametric tts synthesis: Generating spectral parameters with neural attention》)提出直接从音位序列生成声学特征,而不是语言特征,这可以说是端到端语音合成的第一次探索。
在这个调查中,我们关注基于神经的语音合成,主要是端到端模型。
由于后来的 SPSS 也使用神经网络作为声学模型,我们简要描述这些模型,但不深入的细节。

神经语音合成
随着深度学习的发展,基于神经网络的语音合成被提出,它采用(深度)神经网络作为语音合成的模型主干。
SPSS 中采用了一些早期的神经模型来代替 HMM 进行声学建模。
后来又提出了 WaveNet ,直接从语言特征中生成波形,可视为现代第一个神经 TTS 模型。
其他模型如 DeepVoice 1/2 (《Deep voice: Real-time neural text-to-speech》,《Deep voice 2: Multi-speaker neural text-to-speech》)在统计参数综合中仍然遵循这三个成分,但使用相应的基于神经网络的模型对其进行升级。
此外,我们还提出了一些端到端模型(例如 Tacotron 1/2 (《Tacotron: Towards end-to-end speech synthesis》,《Natural tts synthesis by conditioning wavenet on mel spectrogram predictions》), Deep Voice 3 (《Deep voice 3: 2000-speaker neural text-to-speech》), FastSpeech 1/2 (《Fastspeech: Fast, robust and controllable text to speech》,《Fastspeech 2: Fast and high-quality end-to-end text to speech》))来简化文本分析模块,直接将字符/音素序列作为输入,并利用梅尔谱图简化声学特征。
后来,开发了完全端到端 TTS 系统,直接从文本生成波形,如 ClariNet (《Clarinet: Parallel wave generation in end-to-end text-to-speech》), WaveGlow (《Waveglow: A flow-based generative network for speech synthesis》)和 EATS (《End-to-end adversarial text-to-speech》)。
与以往基于串联合成和统计参数合成的语音合成系统相比,基于神经网络的语音合成的优点是语音质量高,在可理解性和自然度方面,而且对人的预处理和特征开发要求较少。
1.2 调查的组成
本文主要综述了神经 TTS 的研究工作,主要分为两部分,如图 2 所示。

TTS 中的关键组件
现代的 TTS 系统由三个基本组件组成:文本分析模块、声学模型和声码器。
如图 1 所示,文本分析模块将文本序列转化为语言特征,声学模型由语言特征生成声学特征,声码器根据声学特征合成波形。
我们在第二节中对神经 TTS 的三个组成部分进行了综述。
具体来说,我们首先在第 2.1 节介绍了神经 TTS 的基本组成部分的主要分类,然后分别在第 2.2 节、 2.3 节和 2.4 节介绍了文本分析、声学模型和声码器的工作。
我们在第 2.5 节中进一步介绍了对完全端到端 TTS 的研究。
虽然我们主要从神经 TTS 中关键成分的分类来回顾研究工作,但我们也在 2.6 节中描述了其他几个分类,包括序列生成的方式(自回归或非自回归)、不同的生成模型和不同的网络结构。
此外,我们还在 2.6 节中说明了一些具有代表性的 TTS 工作的时间演化。
TTS 中的前沿问题
除了神经 TTS 的关键组成部分外,我们还进一步综述了神经 TTS 的几个前沿问题,这些问题推动了 TTS 研究的前沿领域,解决了 TTS 产品中的实际挑战。
例如,由于 TTS 是一个典型的序列到序列生成任务,输出序列通常很长,如何加快自回归生成,减少模型规模以实现快速语音合成是目前的研究热点(第 3.2 节)。
一个好的语音合成系统应该生成自然和可理解的语音,而大量的语音合成研究工作旨在提高语音合成的可理解性和自然度。
例如,在用于训练 TTS 模型的数据不足的低资源场景中,合成的语音可能具有低的可理解性和自然度。
因此,许多工作的目标是在低资源设置下建立数据高效的 TTS 模型(第 3.3 节)。
由于 TTS 模型面临鲁棒性问题,生成的语音中存在跳词和重复问题会影响语音质量,因此很多工作都是为了提高语音合成的鲁棒性(第 3.4 节)。
为了提高语言的自然性和表现力,很多作品对语言的风格/韵律进行建模、控制和转换,以生成富有表现力的语言(第 3.5 节)。
通过调整 TTS 模型来支持任何目标说话人的语音,对于 TTS 的广泛应用是非常有帮助的。
因此,在有限的适配数据和参数下进行有效的语音适配对于实际 TTS 应用至关重要(章节 3.6 )。
为了进一步丰富这个调查,我们在第 4 节中总结了 TTS 的相关资源,包括开源实现、语料库和其他有用的资源。
我们在第 5 节中总结了这一调查,并讨论了未来的研究方向。
2 TTS 中的关键组件
在本节中,我们将从神经 TTS 的关键组成部分(文本分析、声学模型和声码器)的角度回顾研究工作。
我们首先在第 2.1节介绍这个观点下的主要分类,然后分别在第 2.2 节、第 2.3 节和第 2.4 节介绍三个 TTS 组件。
此外,我们在第 2.5 节中回顾了关于完全端到端 TTS 的工作。
除了主要的分类法,我们还在 2.6 节中介绍了更多的分类法,如自回归/非自回归序列生成、生成模型、网络结构,以及关于 TTS 的代表性研究工作的时间轴。


2.1 主要分类
我们主要从 TTS 的基本组成部分:文本分析、声学模型、声码器和完全端到端模型的角度对神经 TTS 的工作进行分类,如图 3a 所示。
我们发现这种分类与文本到波形的数据转换流程是一致的:
1)文本分析将字符转换为音位或语言特征;
2)声学模型从语言特征或字符/音素生成声学特征;
3)声码器通过语言特征或声学特征生成波形;
4)全端到端模型直接将字符/音素转换成波形。
我们根据从文本到波形的数据流重新组织 TTS 工作,如图 3b 所示。在文本到语音的转换过程中,有几种数据表示形式:
1)字符,即文本的原始格式。
2)通过文本分析得到的语言特征,包含丰富的语音、韵律等语境信息。音素是语言特征中最重要的元素之一,在基于神经网络的语篇识别模型中,音素通常单独用于表示文本。
3)声学特征是语音波形的抽象表示。在统计参数语音合成中,LSP (line spectral pairs)(《Line spectrum representation of linear predictor coefficients of speech signals》) , MCC ( mel- 倒谱系数)(《An adaptive algorithm for mel-cepstral analysis of speech》) ,MGC ( mel- 广义系数)(《Mel-generalized cepstral analysis-a unified approach to speech spectral estimation》) , F0 和 BAP ( band aperiodicities )(《Restructuring speech representations using a pitch-adaptive time frequency smoothing and an instantaneous-frequencybased f0 extraction: Possible role of a repetitive structure in sounds》,《Aperiodicity extraction and control using mixed mode excitation and group delay manipulation for a high quality speech analysis, modification and synthesis system straight》) 作为声学特征,可以通过诸如 STRAIGHT (《Straight, exploitation of the other aspect of vocoder: Perceptually isomorphic decomposition of speech sounds》) 和 WORLD (《World: a vocoder-based high-quality speech synthesis system for real-time applications》) 等声码器轻松转换成波形。
4)波形,语音的最终格式。在基于神经网络的端到端 TTS 模型中,通常使用 mel 谱图或线性谱图作为声学特征,通过神经网络的声码器将其转换为波形。
从图 3b 可以看出,从文本到波形可以有不同的数据流,包括:
1)字符→语言特征→声学特征→波形;
2)字符→音素→声学特征→波形;
3)字符→语言特征→波形;
4)字符→音素→声学特征→波形;
5)字符→音素→波形,或字符→波形。
2.2 文本分析
文本分析( Text analysis , TTS )将输入文本转换为包含丰富语音和韵律信息的语言特征,以方便语音合成。
在统计参数合成中,文本分析用于提取语言特征向量序列(《Speech synthesis based on hidden markov models》),包含文本归一化(《Rnn approaches to text normalization: A challenge》,《A hybrid text normalization system using multi-head self-attention for mandarin》)、分词(《Chinese word segmentation as character tagging》)、词性标注(《The effects of part of speech tagging on text to speech synthesis for resource scarce languages》)、韵律预测(《Locating boundaries for prosodic constituents in unrestricted mandarin texts》)和字素-音素转换(《Sequence-to-sequence neural net models for grapheme-tophoneme conversion》)等功能。
在端到端神经 TTS 中,由于基于神经网络的模型建模能力大,直接将字符或音素序列作为输入进行合成,大大简化了文本分析模块。
在这种情况下,仍然需要进行文本规范化以从字符输入获得标准的单词格式,还需要进一步进行字素到音素转换以从标准的单词格式获得音素。
虽然一些 TTS 模型声称完全端到端综合,直接从文本产生波形,但文本规范化仍然需要处理任何可能的非标准格式的原始文本以供实际使用。
此外,一些端到端 TTS 模型结合了传统的文本分析功能。
例如, Char2Wav (《Char2wav: End-to-end speech synthesis》)和 DeepVoice 1/2 (《Deep voice: Real-time neural text-to-speech》,《Deep voice 2: Multi-speaker neural text-to-speech》)将字符到语言的特征转换到其管道中,纯粹基于神经网络,一些作品(《Predicting expressive speaking style from text in end-to-end speech synthesis》)通过文本编码器明确预测韵律特征。
在本小节的其余部分中,我们首先介绍统计参数综合中的文本分析的典型任务,然后讨论端到端 TTS 模型中的文本分析的发展。

我们在表 1 中总结了文本分析中的一些典型任务,并介绍了每个任务的一些代表性工作如下。
文本标准化
将原始的书面文本(非标准词)通过文本规范化转换为口语词,使 TTS 模型更容易发音。
例如, “1989” 年被标准化为"nineteen eighty nine"年, “Jan. 24"被标准化为"Janunary twenty-fourth”。
文本归一化的早期工作是基于规则的(《Normalization of non-standard words》),然后利用神经网络将文本归一化建模为序列到序列的任务,其中源和目标序列分别是非标准词和口语形式的词(《Rnn approaches to text normalization: A challenge》,《Neural text normalization with subword units》,《Neural models of text normalization for speech applications》)。
最近,一些工作(《A hybrid text normalization system using multi-head self-attention for mandarin》)提出将基于规则的模型和基于神经的模型的优点结合起来,进一步提高文本规范化的性能。
词语切分
对于基于字符的语言,如汉语,分词(《Deep learning for chinese word segmentation and pos tagging》,《Max-margin tensor neural network for chinese word segmentation》)是从原始文本中检测词边界是必要的,这对于确保以后的词性标注、韵律预测和字素到音素转换过程的准确性是重要的。
词性标注
词的词性(词性),如名词、动词、介词等,对于字音素转换和韵律预测也很重要。
已有一些研究研究了词性标注在语音合成中的作用(《The effects of part of speech tagging on text to speech synthesis for resource scarce languages》,《Improved pos tagging for text-to-speech synthesis》,《Morphological analysis based part-of-speech tagging for uyghur speech synthesis》,《Application of neural networks for pos tagging and intonation control in speech synthesis for polish》)。
韵律短语预测
语音的节奏、重音、语调等韵律信息对应着音节长度、响度和音高的变化,在人类语音交流中起着重要的感知作用。
韵律预测依赖于标注系统对每种韵律进行标注。
不同的语言有不同的韵律标注系统和工具(《Tobi: A standard for labeling english prosody》,《Autobi-a tool for automatic tobi annotation》,《The tilt intonation model》,《Automatic analysis of prosody for multilingual speech corpora》,《Slam: Automatic stylization and labelling of speech melody》)。
对于英语, ToBI (音调和分音索引)是一个流行的标签系统,它描述了音调(例如,音调重音,短语重音和边界音调)和分音(单词之间的分音有多强)的标签。
例如,在这个句子中 “Mary went to the store ?”, "Mary"和"store"可以强调,这个句子是升调。
许多著作(《Exploiting acoustic and syntactic features for prosody labeling in a maximum entropy framework》,《Automatic prosodic labeling with conditional random fields and rich acoustic features》,《Automatic prosodic events detection using syllable-based acoustic and syntactic features》,《Automatic prosody prediction and detection with conditional random field (crf) models》)研究了基于 ToBI 的不同模型和特征来预测韵律标签。
在汉语语音合成中,典型的韵律边界标签由韵律词( PW )、韵律短语( PPH )和语调短语( IPH )组成,可以构造三层层次的韵律树(《Locating boundaries for prosodic constituents in unrestricted mandarin texts》,《Chinese prosody structure prediction based on conditional random fields》,《Automatic prosody prediction for chinese speech synthesis using blstm-rnn and embedding features》)。
一些研究(《一种用于统计参数语音合成的具有振幅和相位谱分层生成的神经声码器》,《Self-attention based prosodic boundary prediction for chinese speech synthesis》,《Implementing prosodic phrasing in chinese endto-end speech synthesis》)探讨了不同的模型结构,如 CRF (《Conditional random fields: Probabilistic models for segmenting and labeling sequence data》), RNN (《Long short-term memory》)和自我注意(《Attention is all you need》)用于汉语韵律预测。
字素到音素 ( G2P ) 转换
将字符(字素)转换为语音(音素)可以大大简化语音合成。
例如, “speech” 这个词被转换成 “s p iy ch” ,通常利用手工收集的字素-音素词典进行转换。
然而,对于像英语这样的字母语言,词典不能涵盖所有单词的发音。
因此,英语的 G2P 转换主要负责生成词汇外的单词的发音(《Conditional and joint models for grapheme-to-phoneme conversion》,《Joint-sequence models for grapheme-to-phoneme conversion》,《Sequence-to-sequence neural net models for grapheme-tophoneme conversion》,《Grapheme-to-phoneme conversion using long short-term memory recurrent neural networks》,《Convolutional sequence to sequence model with non-sequential greedy decoding for grapheme to phoneme conversion》,《Token-level ensemble distillation for grapheme-to-phoneme conversion》)。
对于像汉语这样的语言,虽然词典可以涵盖几乎所有的字符,但有很多多音字只能根据一个字符的上下文来决定。
因此,这类语言的 G2P 转换主要负责多音字消歧,即根据当前语境决定合适的发音(《An efficient way to learn rules for grapheme-tophoneme conversion in chinese》,《Grapheme-to-phoneme conversion for chinese text-tospeech》,《Inequality maximum entropy classifier with character features for polyphone disambiguation in mandarin tts systems》,《A bi-directional lstm approach for polyphone disambiguation in mandarin chinese》,《Knowledge distillation from bert in pre-training and fine-tuning for polyphone disambiguation》,《Polyphone disambiguation for mandarin chinese using conditional neural network with multi-level embedding features》,《g2pm: A neural grapheme-to-phoneme conversion package for mandarin chinese based on a new open benchmark dataset》)。
通过以上文本分析,我们可以进一步构建语言特征,并将其作为 TTS 管道的后期输入,如 SPSS 中的声学模型或声码器中的声学模型(《Wavenet: A generative model for raw audio》)。
通常,我们可以从音位、音节、单词、短语和句子等不同层次对文本分析结果进行聚合,构建语言特征(《Speech synthesis based on hidden markov models》)。
讨论
虽然与 SPSS 相比,文本分析在神经 TTS 中似乎较少受到重视,但它已经以各种方式被纳入神经 TTS 中:
1)多任务统一的前端模型。最近, Pan 等人(《A unified sequence-to-sequence front-end model for mandarin text-to-speech synthesis》)、 Zhang 等人(《Unified mandarin tts front-end based on distilled bert model》)设计了统一的模型来覆盖多任务范式下的文本分析中的所有任务,并取得了良好的效果。
2)韵律预测。韵律对语音合成的自然程度至关重要。
虽然神经 TTS 模型简化了文本分析模块,但在文本编码中加入了一些韵律预测的特征,如音高(《Fastspeech 2: Fast and high-quality end-to-end text to speech》)、持续时间(《Fastspeech: Fast, robust and controllable text to speech》)、呼吸或填充停顿(《Adaspeech 3: Adaptive text to speech for spontaneous style》)的预测是建立在 TTS 模型中的文本(字符或音素)编码之上的。
其他一些融合韵律特征的方法包括:
1)参考编码从参考语音中学习韵律表征;
2)文本预处理训练通过自我监督预处理训练学习带有内隐韵律信息的好的文本表征(《Pre-trained text embeddings for enhanced text-to-speech synthesis》,《Exploiting syntactic features in a parsed tree to improve end-to-end tts》);
3)通过专门的建模方法(如图网络)整合语法信息(《Graphspeech: Syntax-aware graph attention network for neural speech synthesis》)。
2.3 声学模型
在这一节中,我们回顾了声学模型的工作,它从语言特征或直接从音素或字符生成声学特征。
TTS 的发展,采取了不同的声学模型,包括早期嗯和基础款模型在统计参数语音合成( SPSS )(《Simultaneous modeling of spectrum, pitch and duration in hmm-based speech synthesis》,《Speech parameter generation algorithms for hmm-based speech synthesis》,《Statistical parametric speech synthesis using deep neural networks》,《On the training aspects of deep neural network (dnn) for parametric tts synthesis》,《TTS synthesis with bidirectional lstm based recurrent neural networks》,《Unidirectional long short-term memory recurrent neural network with recurrent output layer for low-latency speech synthesis》),然后顺序序列模型基于 encoder-attention-decoder 框架(包括 LSTM 、 CNN 和 self-attention )(《Tacotron: Towards end-to-end speech synthesis》,《Natural tts synthesis by conditioning wavenet on mel spectrogram predictions》,《Deep voice 3: 2000-speaker neural text-to-speech》,《Neural speech synthesis with transformer network》)和最新的前馈网络( CNN 或 self-attention )(《Fastspeech: Fast, robust and controllable text to speech》,《Non-autoregressive neural text-to-speech》)用于并行生成。
声学模型的目的是生成声学特征,并利用声码器进一步转换成波形。
声学特征的选择在很大程度上决定了 TTS 管道的类型。
人们尝试了各种不同的声学特征,如 mel- 倒谱系数( MCC )(《An adaptive algorithm for mel-cepstral analysis of speech》)、梅尔广义系数( MGC )(《Mel-generalized cepstral analysis-a unified approach to speech spectral estimation》)、频带非周期( BAP )(《Restructuring speech representations using a pitch-adaptive time frequency smoothing and an instantaneous-frequencybased f0 extraction: Possible role of a repetitive structure in sounds》,《Aperiodicity extraction and control using mixed mode excitation and group delay manipulation for a high quality speech analysis, modification and synthesis system straight》)、基频( F0 )、浊音/浊音( V/UV )、 bark-frequency 倒谱系数( BFCC ),以及最常用的梅尔谱图。
因此,我们可以将声音模型划分为两个时期:
1)在 SPSS 声学模型,通常预测声学特性,比如 MGC , BAP 和 F0 等语言特征;
2)声学模型基于神经端到端 TTS ,预测的声学特性,比如从音素或字符到梅尔频谱图。
2.3.1 SPSS 中的声学模型
在 SPSS (《Statistical parametric speech synthesis》,《Speech synthesis based on hidden markov models》)中,利用 HMM (《Simultaneous modeling of spectrum, pitch and duration in hmm-based speech synthesis》,《Speech parameter generation algorithms for hmm-based speech synthesis》)、 DNN (《Statistical parametric speech synthesis using deep neural networks》,《On the training aspects of deep neural network (dnn) for parametric tts synthesis》)或 RNN 等统计模型从语言特征中生成声学特征(语音参数),使用诸如 STRAIGHT (《Straight, exploitation of the other aspect of vocoder: Perceptually isomorphic decomposition of speech sounds》)和 WORLD (《World: a vocoder-based high-quality speech synthesis system for real-time applications》)等声码器将生成的语音参数转换为语音波形。
这些声学模型的发展是由以下几个因素驱动的:
1)将更多的上下文信息作为输入;
2)输出帧之间的相关性建模;
3)更好地解决过平滑预测问题(《Statistical parametric speech synthesis》),因为从语言特征到声学特征的映射是一对多的。
我们在下文简要回顾了一些工作。
Yoshimura 等人(《Simultaneous modeling of spectrum, pitch and duration in hmm-based speech synthesis》)、 Tokuda 等人(《Speech parameter generation algorithms for hmm-based speech synthesis》)利用 HMM (《An introduction to hidden markov models》)生成语音参数,HMM的观测向量由梅尔倒谱系数系数( melcepstral coefficient, MCC )和 F0 等谱参数向量组成。
与以往的串联式语音合成相比,基于 HMM 的参数化合成在改变说话人身份、情感和说话风格方面更加灵活。
读者可以参考 Zen 等人(《Acoustic modeling in statistical parametric speech synthesis-from hmm to lstm-rnn》,《Statistical parametric speech synthesis》)、 Tokuda 等人(《Speech synthesis based on hidden markov models》)对基于 HMM 的 SPSS 的优缺点进行一些分析。
基于 HMM 的 SPSS 的一个主要缺点是合成语音的质量不够好,主要是由于两个原因:1)声学模型的精度不好,而预测的声学特征是过于平滑和缺乏细节,2)语音编码技术还不够好。
第一个原因主要是由于 HMM 的建模能力不足。
因此,在 SPSS 中提出了基于 DNN 的声学模型,提高了基于 HMM 模型的综合质量。
之后,为了更好地建模语音中的长时间上下文效应,利用基于 LSTM 的递归神经网络来更好地建模上下文相关性。
随着深度学习的发展,一些先进的网络结构如 CBHG (《Tacotron: Towards end-to-end speech synthesis》)被用来更好地预测声学特征(《Emphasis: An emotional phoneme-based acoustic model for speech synthesis system》)。
VoiceLoop (《Voiceloop: Voice fitting and synthesis via a phonological loop》)采用一种称为语音循环的工作记忆从音素序列中生成声学特征(如 F0 、 MGC 、 BAP ),然后使用 WORLD 声码器从这些声学特征合成波形。
Yang 等人(《Statistical parametric speech synthesis using generative adversarial networks under a multitask learning framework》)利用 GAN (《Generative adversarial nets》)来提高声学特征的生成质量。
Wang 等人(《First step towards end-to-end parametric tts synthesis: Generating spectral parameters with neural attention》)探索了一种端到端的方式,利用基于注意的循环序列传感器模型直接从音素序列生成声学特征,这可以避免之前基于神经网络的声学模型中要求的逐帧对齐。
Wang 等人(《A comparison of recent waveform generation and acoustic modeling methods for neural-networkbased speech synthesis》)对不同的声学模型进行了深入的实验研究。
SPSS 中的一些声学模型如表 2 所示。


2.3.2 端到端 TTS 中的声学模型
与 SPSS 相比,基于神经的端到端 TTS 的声学模型有几个优势:
1)传统的声学模型要求语言特征和声学特征之间的对齐,而基于序列到序列的神经模型通过注意隐式学习对齐或联合预测对齐的持续时间,这是端到端的,需要较少的预处理。
2)神经网络建模能力的增加,语言特征被简化到只有字符或音素序列,和声学特性改变了从低维压缩倒频谱(如 MGC )高维梅尔频谱图甚至更高维线性频谱图。
下面我们将介绍神经 TTS 中一些具有代表性的声学模型,并在表 2 中提供了一个完整的声学模型列表。
基于 RNN 的模型(例如, Tacotron 系列)
Tacotron (《Tacotron: Towards end-to-end speech synthesis》)利用编码器-注意-解码器框架,将字符作为输入和输出线性谱图,并使用 GriffinLim 算法(《Signal estimation from modified short-time fourier transform》)生成波形。
我们提出了 Tacotron 2 (《Natural tts synthesis by conditioning wavenet on mel spectrogram predictions》)来生成 mel 谱图,并使用附加的 WaveNet (《Wavenet: A generative model for raw audio》)模型将 mel 谱图转换为波形。
与 Tacotron 、参数 TTS 、神经 TTS 等之前的方法相比, Tacotron 2 大大提高了语音质量。
后来,很多工作从不同的方面对 Tacotron 进行了改进:
1)使用参考编码器和风格标记来增强语音合成的表达性,如 GST-Tacotron (《Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis》)和 Ref-Tacotron (《Towards end-to-end prosody transfer for expressive speech synthesis with tacotron》)。
2)移除 Tacotron 中的注意机制,使用持续时间预测器进行自回归预测,如 DurIAN (《Durian: Duration informed attention network for speech synthesis》)和 Non-attentative Tacotron (《Non-attentive tacotron: Robust and controllable neural tts synthesis including unsupervised duration modeling》)。
3)将 Tacotron 中的自回归生成转化为非自回归生成,如 Parallel Tacotron 1/2 (《Parallel tacotron: Non-autoregressive and controllable tts》,《Parallel tacotron 2: A non-autoregressive neural tts model with differentiable duration modeling》)。
4)基于 Tacotron 构建端到端文本到波形模型,如 Wave-Tacotron (《Wave-tacotron: Spectrogram-free end-to-end text-to-speech synthesis》)。
基于 CNN 的模型(如 DeepVoice 系列)
DeepVoice (《Deep voice: Real-time neural text-to-speech》)实际上是一个通过卷积神经网络增强的 SPSS 系统。
DeepVoice 通过神经网络获取语言特征后,利用基于 WaveNet (《Wavenet: A generative model for raw audio》)的声码器生成波形。
DeepVoice 2 (《Deep voice 2: Multi-speaker neural text-to-speech》)遵循了 DeepVoice 的基本数据转换流程,并通过改进的网络结构和多说话人建模对 DeepVoice 进行了改进。
此外, DeepVoice 2 还采用了 Tacotron + WaveNet 模型管道,首先使用 Tacotron 生成线性谱图,然后使用 WaveNet 生成波形。
DeepVoice 3 (《Deep voice 3: 2000-speaker neural text-to-speech》)利用全卷积网络结构进行语音合成,从字符生成语音谱图,并可扩展到真实的多说话人数据集。
DeepVoice 3 改进了之前的 DeepVoice 1/2 系统,使用了更紧凑的序列到序列模型,直接预测梅尔声谱图,而不是复杂的语言特征。
后来, ClariNet (《Clarinet: Parallel wave generation in end-to-end text-to-speech》)被提出以完全端到端的方式从文本中生成波形。
ParaNet (《Non-autoregressive neural text-to-speech》)是一种基于全卷积的非自回归模型,可以加快梅尔谱图的生成,获得较好的语音质量。
DCTTS (《Efficiently trainable textto-speech system based on deep convolutional networks with guided attention》)与 Tacotron 共享类似的数据转换管道,并利用一个完全卷积的基于编码器-注意-解码器网络从字符序列生成梅尔谱图。
然后使用谱图超分辨率网络获得线性谱图,并使用 GriffinLim 合成波形(《* Signal estimation from modified short-time fourier transform*》)。
基于 Transformer 的模型(例如, FastSpeech 系列)
TransformerTTS (《Neural speech synthesis with transformer network》)利用基于 Transformer (《Attention is all you need》)的编码器-注意-解码器架构从音素生成梅尔声谱图。
他们认为,基于 RNN 的编码器-注意力-解码器模型,如 Tacotron 2 ,存在以下两个问题:
1)基于 RNN 的编码器和解码器由于具有周期性,不能并行训练,基于 RNN 的编码器不能并行推理,影响了训练和推理的效率。
2)由于文本和语音序列通常很长, RNN 不擅长建模这些序列的长相关性。
TransformerTTS 采用了 Transformer 的基本模型结构,并吸收了 Tacotron 2 的解码器、前置/后置网络、停止标志预测等设计。
它的语音质量与 Tacotron 2 类似,但训练时间更快。
然而,与利用位置敏感注意等稳定注意机制的基于 RNN 的模型(如 Tacotron )相比, Transformer 中的编码器-解码器注意由于并行计算而不具有鲁棒性。
因此,一些工作提出了增强基于 Transformer 的声学模型的鲁棒性。
例如, MultiSpeech (《Multispeech: Multi-speaker text to speech with transformer》)通过编码器归一化、解码器瓶颈和对角注意约束来提高注意机制的鲁棒性,而 RobuTrans (《Robutrans: A robust transformer-based text-to-speech model》)利用持续时间预测来增强自回归生成的鲁棒性。
之前的基于神经的声学模型,如 Tacotron 1/2 , DeepVoice 3 和 TransformerTTS 均采用自回归生成,但存在几个问题:
1)推理速度慢。自回归梅尔谱图的生成速度较慢,尤其是对于长序列(例如,对于 1 秒钟的语音,如果跳数为 10ms ,这是一个长序列,则有近 500 帧梅尔谱图)。
2)鲁棒问题。在基于编码器-注意-解码器的自回归生成中,文本和梅尔谱图之间的注意对齐不准确是导致生成的语音存在跳词和重复等问题的主要原因。
因此, FastSpeech 被提出来解决这些问题:
1)采用前馈 Transformer 网络并行生成梅尔谱图,大大加快推理速度。
2)去掉了文本和语音之间的注意机制,避免了跳过词和重复的问题,提高了鲁棒性。
相反,它使用一个长度调节器来连接音素和梅尔谱图序列之间的长度不匹配。
长度调节器利用持续时间预测器预测每个音位的持续时间,并根据音位持续时间扩展音位隐藏序列,扩展后的音位隐藏序列可以匹配梅尔谱图序列的长度,便于并行生成。
. FastSpeech 有几个优点:
1)极快的推理速度(例如,梅尔谱图生成的推理速度提高 270 倍,波形生成的推理速度提高 38 倍);
2)无跳过词和重复问题的鲁棒语音合成;
3)与以前的自回归模型相同的语音质量。
FastSpeech 已经部署在微软 Azure Text to Speech Service 中,以支持 Azure TTS 中的所有语言和地区。
FastSpeech 利用一个明确的持续时间预测器来扩展音素隐藏序列,以匹配梅尔声谱图的长度。
如何获得持续时间标签来训练持续时间预测器对生成语音的韵律和质量至关重要。
我们在第 3.4.2 节简要回顾了具有持续时间预测的 TTS 模型。
接下来,我们将介绍一些基于 FastSpeech 的其他改进。
FastSpeech 2 被提出来进一步增强 FastSpeech ,主要从两个方面:
1)使用真实的 mel 谱图作为训练目标,而不是从自回归教师模型中提取 mel 谱图。这简化了 FastSpeech 中两阶段的师生蒸馏管道,也避免了蒸馏后目标谱图中的信息损失。
2)提供更多的变化信息,如音高、持续时间和能量作为解码器的输入,从而简化了文本到语音的一对多映射问题(《One-to-many neural network mapping techniques for face image synthesis》,《An asymmetric cycle-consistency loss for dealing with many-to-one mappings in image translation: a study on thigh mr scans》,《Tacotron: Towards end-to-end speech synthesis》,《Toward multimodal image-to-image translation》)。
FastSpeech 2 实现了比 FastSpeech 更好的语音质量,并保持了 FastSpeech 中快速、鲁棒、可控语音合成的优势。
FastPitch (《Fastpitch: Parallel text-to-speech with pitch prediction》)通过使用音高信息作为解码器输入来改进 FastSpeech ,这与 FastSpeech 2 中的方差预测相似。
其他声学模型(如 Flow 、 GAN 、 VAE 、 Diffusion )
除了上述声学模型之外,还有很多其他声学模型(《Melnet: A generative model for audio in the frequency domain》,《Deep feed-forward sequential memory networks for speech synthesis》,《Devicetts: A small-footprint, fast, stable network for on-device text-to-speech》,《Bidirectional variational inference for non-autoregressive text-to-speech》),如表 2 所示。
基于流的模型长期以来一直被用于神经 TTS 。
在声码器(如 Parallel WaveNet (《Parallel wavenet: Fast high-fidelity speech synthesis》), WaveGlow (《Waveglow: A flow-based generative network for speech synthesis》), FloWaveNet (《Flowavenet: A generative flow for raw audio》))早期的成功应用之后,基于流的模型也被应用于声学模型,如 Flowtron (《Flowtron: an autoregressive flow-based generative network for text-to-speech synthesis》),这是一种自回归的基于流的梅尔谱生成模型, Flow-TTS (《Flow-tts: A non-autoregressive network for text to speech based on flow》)和 Glow-TTS (《Glow-tts: A generative flow for text-to-speech via monotonic alignment search》)利用生成流进行非自回归梅尔谱生成。
除了基于流的模型,其他生成模型也被用于声学模型:
1) 基于 VAE 的 GMVAE-Tacotron (《Hierarchical generative modeling for controllable speech synthesis》),BVAE-TTS (《Bidirectional variational inference for non-autoregressive text-to-speech》) 和 VAE-TTS (《Learning latent representations for style control and transfer in end-to-end speech synthesis》)。
2) GAN exposure (《A new gan-based end-to-end tts training algorithm》)、 TTS-Stylization (《Neural tts stylization with adversarial and collaborative games》)和 Multi-SpectroGAN (《Multi-spectrogan: High-diversity and high-fidelity spectrogram generation with adversarial style combination for speech synthesis》)均基于 GAN 。
3) Diff-TTS (《Diff-tts: A denoising diffusion model for text-to-speech》), Grad-TTS (《Grad-tts: A diffusion probabilistic model for text-to-speech》)和 PriorGrad (《Priorgrad: Improving conditional denoising diffusion models with data-driven adaptive prior》)基于扩散模型 (《Deep unsupervised learning using nonequilibrium thermodynamics》,《Denoising diffusion probabilistic models》)。
2.4 声码器
总的来说,声码器的发展可以分为两个阶段:用于统计参数语音合成( SPSS )的声码器(《Straight, exploitation of the other aspect of vocoder: Perceptually isomorphic decomposition of speech sounds》,《World: a vocoder-based high-quality speech synthesis system for real-time applications》,《A neural vocoder with hierarchical generation of amplitude and phase spectra for statistical parametric speech synthesis》)和基于神经网络的声码器(《Wavenet: A generative model for raw audio》,《Char2wav: End-to-end speech synthesis》,《Efficient neural audio synthesis》,《Waveglow: A flow-based generative network for speech synthesis》)。
SPSS 中一些流行的声码器包括 STRAIGHT 和 WORLD 。
我们以 WORLD 声码器为例,它包括声码器分析和声码器合成两个步骤。
在声码器分析中,它对语音进行分析,得到梅尔倒谱系数、频带非周期性和 F0 等声学特征。
在声码合成中,它根据这些声学特征产生语音波形。
在这一节中,我们主要回顾了基于神经的声码器的工作,因为它们的高语音质量。
早期的神经声码器如 WaveNet (《Wavenet: A generative model for raw audio》,《Parallel wavenet: Fast high-fidelity speech synthesis》), Char2Wav (《Char2wav: End-to-end speech synthesis》), WaveRNN (《Efficient neural audio synthesis》)直接将语言特征作为输入生成波形。
后来, Prenger 等人 (《Waveglow: A flow-based generative network for speech synthesis》)、 Kumar 等人(《Melgan: Generative adversarial networks for conditional waveform synthesis》)、 Yamamoto 等人(《Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram》)将梅尔谱图作为输入并生成波形。
由于语音波形很长,自回归波形的产生需要大量的推理时间。
因此,生成模型如 Flow (《Nice: Non-linear independent components estimation》,《Improved variational inference with inverse autoregressive flow》,《Glow: generative flow with invertible 1 1 convolutions》)、 GAN 、 VAE 、 DDPM ( Denoising Diffusion probability Model,简称 Diffusion )(《Deep unsupervised learning using nonequilibrium thermodynamics》,《Denoising diffusion probabilistic models》)用于波形生成。
据此,我们将神经声码器划分为不同的类别:
1)自回归声码器,
2)基于 Flow 的声码器,
3)基于 GAN 的声码器,
4)基于 VAE 的声码器,
5)基于 Diffusion 的声码器。
我们在表 3 中列出了一些具有代表性的声码器,并描述如下。

自回归语音编码器
WaveNet 是第一个基于神经的声码器,它利用膨胀卷积自回归生成波形点。
不同于 SPSS 中的声码分析和合成, WaveNet 几乎没有整合关于音频信号的先验知识,完全依赖端到端学习。
最初的 WaveNet 以及随后利用 WaveNet 作为声码器的一些作品(《Deep voice: Real-time neural text-to-speech》,《Deep voice 2: Multi-speaker neural text-to-speech》),根据语言特征生成语音波形,而 WaveNet 可以很容易地适应线性谱图(《Deep voice 2: Multi-speaker neural text-to-speech》)和梅尔谱图(《Speaker-dependent wavenet vocoder》,《Deep voice 3: 2000-speaker neural text-to-speech》,《Natural tts synthesis by conditioning wavenet on mel spectrogram predictions》)的条件。
虽然 WaveNet 的语音质量很好,但其推理速度较慢。
因此,大量的工作(《Fast wavenet generation algorithm》,《Wg-wavenet: Real-time high-fidelity speech synthesis without gpu》,《Samplernn: An unconditional end-to-end neural audio generation model》)研究轻量级和快速声码器。
SampleRNN (《Samplernn: An unconditional end-to-end neural audio generation model》)利用层次递归神经网络进行无条件波形生成,并进一步集成到 Char2Wav (《Char2wav: End-to-end speech synthesis》)中,以生成基于声学特征的波形。
此外, WaveRNN (《An efficient way to learn rules for grapheme-tophoneme conversion in chinese》)被开发用于高效的音频合成,使用循环神经网络并利用包括双 softmax 层、权剪枝和子尺度技术在内的多种设计来减少计算量。
Lorenzo-Trueba 等人(《Towards achieving robust universal neural vocoding》), Paul 等人(《Speaker conditional wavernn: Towards universal neural vocoder for unseen speaker and recording conditions》), Jiao 等人(《Universal neural vocoding with parallel wavenet》)进一步提高了声码器的鲁棒性和通用性。
LPCNet (《Lpcnet: Improving neural speech synthesis through linear prediction》,《A real-time wideband neural vocoder at 1.6 kb/s using lpcnet》)将传统的数字信号处理引入神经网络,利用线性预测系数计算下一个波形点,同时利用轻量级 RNN 计算残差。
LPCNet 根据梅尔倒谱系数( BFCC )特征生成语音波形,可以很容易地适应梅尔频谱的条件。
接下来的一些工作从不同的角度对 LPCNet 进行了进一步的改进,如降低复杂度以实现加速(《Bunched lpcnet: Vocoder for low-cost neural text-to-speech systems》,《Gaussian lpcnet for multisample speech synthesis》,《Lightweight lpcnet-based neural vocoder with tensor decomposition》),提高稳定性以获得更好的质量(《Improving lpcnet-based text-to-speech with linear prediction-structured mixture density network》)。
基于 Flow 的语音编码器
规范化 Flow (《Nice: Non-linear independent components estimation》,《Density estimation using real nvp》,《Variational inference with normalizing flows》,《Improved variational inference with inverse autoregressive flow》,《Glow: generative flow with invertible 1× 1 convolutions》)是一种生成模型。
它用一系列可逆映射来变换概率密度。
由于我们可以通过基于变量变化规则的可逆映射序列得到一个标准/归一化的概率分布(如高斯),这种基于流的生成模型称为归一化流。
在采样期间,它通过这些变换的逆从一个标准概率分布生成数据。
神经 TTS 中使用的基于流的模型根据两种不同的技术(《Normalizing flows for probabilistic modeling and inference》)可以分为两类:1)自回归变换(如平行 WaveNet 中的逆自回归流);2)二部变换(如 WaveGlow 中的 Glow ),如表 4 所示。

自回归变换,如逆自回归流( IAF )(《Improved variational inference with inverse autoregressive flow》)。
IAF 可以看作是自回归流( AF )的双重公式。AF训练是并行的,采样是顺序的。相比之下, IAF 中的抽样是并行的,而似然估计的推断是序列的。
Parallel WaveNet 利用概率密度蒸馏将 IAF 的高效采样与 AR 建模的高效训练结合起来。它使用一个自回归的 WaveNet 作为教师网络来指导学生网络的训练( Parallel WaveNet )来近似数据的可能性。
类似地, ClariNet 使用了 IAF 和教师蒸馏,并利用封闭式的 KL 散度来简化和稳定蒸馏过程。虽然 Parallel Wavenet 和 ClariNet 可以并行生成语音,但它依赖于复杂的师生训练,仍然需要大量的计算。
二部变换,例如 Glow 或 RealNVP 。
为了保证变换是可逆的,二部变换利用仿射耦合层,确保输出可以从输入计算,反之亦然。一些基于二部变换的声码器包括 WaveGlow 和 FloWaveNet ,它们实现了高语音质量和快速推理速度。
自回归变换和二部变换都有各自的优缺点(《Waveflow: A compact flow-based model for raw audio》):
1)自回归变换通过建模数据分布 x 和标准概率分布 z 之间的依赖关系,比二部变换更具表现力,但需要教师模型精馏,训练时比较复杂。
2)两部分变换具有更简单的训练管道,但通常需要更多的参数(例如,更深的层,更大的隐藏尺寸)来达到与自回归模型相比较的能力。
为了结合自回归和二部变换的优点, WavFlow 为音频数据提供了基于似然的模型的统一视图,以明确地交换模型容量的推理并行性。
这样, WaveNet 和 WaveGlow 可以看作是 WaveFlow 的特例。
基于 GAN 的语音编码器
生成对抗网络( GANs )已广泛应用于数据生成任务,如图像生成、文本生成和音频生成。
GAN 包括用于生成数据的生成器和用于判断生成数据真实性的鉴别器。
许多声码器利用 GAN 来确保音频生成质量,包括 WaveGAN (《Adversarial audio synthesis》), GAN-TTS (《High fidelity speech synthesis with adversarial networks》), MelGAN (《Melgan: Generative adversarial networks for conditional waveform synthesis》), Parallel WaveGAN (《Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram》), HiFi-GAN (《Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis》),以及其他基于 GAN 的声码器 (《Probability density distillation with generative adversarial networks for high-quality parallel waveform generation》,《Quasiperiodic parallel wavegan vocoder: A non-autoregressive pitch-dependent dilated convolution model for parametric speech generation》,《Improved parallel wavegan vocoder with perceptually weighted spectrogram loss》,《Gan vocoder: Multi-resolution discriminator is all you need》,《Improve gan-based neural vocoder using pointwise relativistic leastsquare gan》,《Universal melgan: A robust neural vocoder for high-fidelity waveform generation in multiple domains》)。

我们总结了表 5 中每个声码器中使用的生成器、鉴别器和损耗的特征。
生成器
大多数基于神经网络的声码器使用扩张性卷积来增加感受场来模拟波形序列的长依赖关系,并使用转置卷积来对条件信息(如语言特征或梅尔声谱图)进行采样以匹配波形序列的长度。
Yamamoto 等人(《Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram》)选择对条件信息进行一次上采样,然后进行扩张卷积以保证模型容量。然而,这种上采样过早地增加了序列长度,导致较大的计算代价。
因此,一些声码器(《Melgan: Generative adversarial networks for conditional waveform synthesis》,《Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis》)选择迭代上采样条件信息,进行扩大化卷积,避免了下层序列过长。具体来说, VocGAN (《Vocgan: A high- fidelity real-time vocoder with a hierarchically-nested adversarial network》)提出了一种多尺度发生器,可以从粗粒度到细粒度逐步输出不同尺度的波形序列。
HiFi-GAN 通过多接受场融合模块并行处理不同长度的不同模式,并且还具有在合成效率和样品质量之间权衡的灵活性。
鉴别器
关于鉴别器的研究集中在如何设计模型来捕获波形特征,以便为发生器提供更好的引导信号。
我们对这些努力的回顾如下:
1) GAN-TTS 中提出的随机窗鉴权器,该鉴权器使用多个鉴权器,每个鉴权器都输入不同的有条件信息和无条件信息的波形随机窗。随机窗口鉴别器有几个优点,如以不同的互补方式评估音频,与全音频相比简化真/假判断,以及作为数据增强效应等。
2) MelGAN 提出的多尺度鉴别器,利用多个鉴别器来判断不同尺度下的音频(与原始音频相比的降采样比不同)。多尺度鉴别器的优点是每个尺度的鉴别器可以聚焦于不同频率范围内的特征。
3) HiFiGAN 中提出的多周期鉴别器,利用多个鉴别器,每个鉴别器接受具有周期的输入音频的等间隔采样。具体来说,将长度为T的一维波形序列重塑为 2D 数据 [ p , T / p ] [p, T /p] [p,T/p] ,其中 p p p 为周期,并进行 2D 卷积处理。多周期鉴别器可以通过观察输入音频在不同周期的不同部分来捕获不同的隐式结构。
4) VocGAN 利用分级鉴别器对生成的波形进行从粗粒度到细粒度不同分辨率的判断,指导生成器学习低频和高频声波特征与波形之间的映射。
损失
除了常规的 GAN 损耗,如 WGAN-GP (《Improved training of wasserstein gans》)、铰链损耗 GAN (《Geometric gan》)和 LS-GAN (《Least squares generative adversarial networks》),其他特定损耗,如 STFT 损耗(《Fast spectrogram inversion using multi-head convolutional neural networks》,《Probability density distillation with generative adversarial networks for high-quality parallel waveform generation》)和特征匹配损耗(《Autoencoding beyond pixels using a learned similarity metric》)也被利用。这些额外的损失可以提高对抗性训练的稳定性和效率(《Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram》),提高感知音频质量。 Gritsenko 等(《A spectral energy distance for parallel speech synthesis》)提出了带有排斥项的广义能量距离,以便更好地捕获多模态波形分布。
基于 Diffusion 的语音编码器
最近,有一些工作利用去噪扩散概率模型( DDPM 或 Diffusion )(《Denoising diffusion probabilistic models》)用于声码器,如 DiffWave (《Diffwave: A versatile diffusion model for audio synthesis》)、 WaveGrad (《Wavegrad: Estimating gradients for waveform generation》)和 PriorGrad (《Priorgrad: Improving conditional denoising diffusion models with data-driven adaptive prior》)。其基本思想是用扩散过程和反向过程来建立数据与潜伏分布的映射:在扩散过程中,波形数据样本逐渐加入一些随机噪声,最终变成高斯噪声;在反向过程中,将随机高斯噪声逐步去噪为波形数据样本。
基于扩散的声码器可以产生高质量的语音,但由于迭代过程较长,推理速度较慢。因此,许多关于扩散模型的研究(《Denoising diffusion implicit models》,《Learning to efficiently sample from diffusion probabilistic models》,《On fast sampling of diffusion probabilistic models》)正在研究如何在保持生成质量的同时减少推理时间。
其他声码器
一些工作利用基于神经的源滤波模型产生波形(《Neural source-filter-based waveform model for statistical parametric speech synthesis》,《Neural source-filter waveform models for statistical parametric speech synthesis》,《Neural harmonic-plus-noise waveform model with trainable maximum voice frequency for text-to-speech synthesis》),目的是在保持可控语音生成的同时获得高语音质量。 Govalkar 等人(《A comparison of recent neural vocoders for speech signal reconstruction》)对不同类型的声码器进行了全面的研究。 Hsu 等人(《Towards robust neural vocoding for speech generation: A survey》)通过综合实验对几种常用的声码器进行评估,研究了声码器的鲁棒性。
讨论
我们总结了声码器中使用的各种生成模型的特点,如表 6 所示:
1)在数学的简单性方面,基于自回归( AR )的模型比其他生成模型(如 VAE , Flow , Diffusion , GAN )更容易。
2)除 AR 外的所有生成模型都支持并行语音生成。
3)除 AR 模型外,所有生成模型都能在一定程度上支持潜在操作(部分基于 GAN 的声码器不以随机高斯噪声作为模型输入,因此不支持潜在操作)。
4)基于 GAN 的模型不能估计数据样本的可能性,而其他模型则有这一优势。
2.5 面向完全端到端 TTS
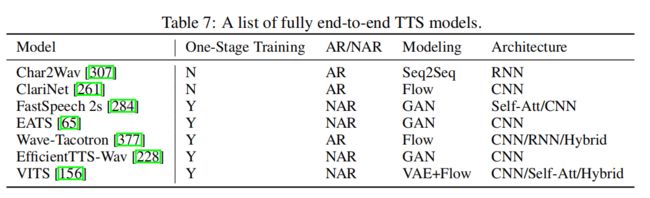
完全端到端 TTS 模型可以直接从字符或音素序列生成语音波形,具有以下优点:
1)它需要较少的人的标注和特征开发(例如,文本和语音之间的对齐信息)
2)联合优化和端到端优化可以避免级联模型(如文本分析 + 声学模型 + 声码器)中的误差传播;
3)降低培训、开发和部署成本。
然而, TTS 模型的端到端的训练面临很大的挑战,主要是由于文本和语音波形之间的模态不同,以及字符/音素序列与波形序列之间存在巨大的长度不匹配。
例如,对于一个长度为 5 秒、约 20 个单词的语音,音素序列的长度约为 100 ,而波形序列的长度为 80k (如果采样率为 16kHz )。由于记忆的限制,很难将整个话语的波形点进行模型训练。如果只使用一个简短的音频剪辑进行端到端训练,就很难捕获上下文表示。
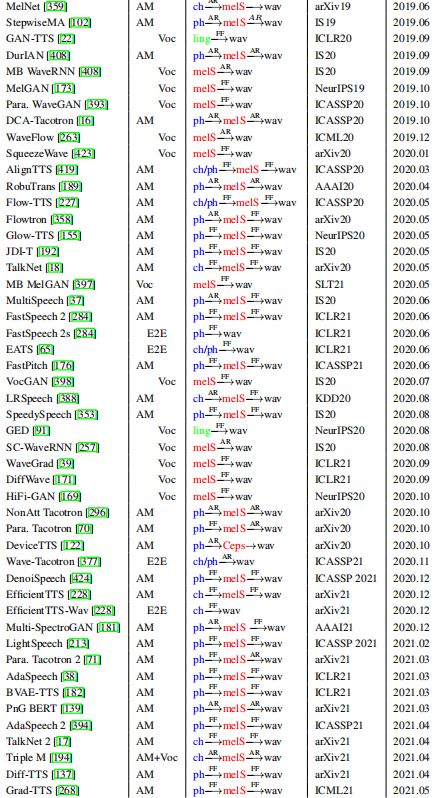
由于完全端到端训练的困难,神经 TTS 的发展遵循着一个逐步向全端到端模型发展的过程。图 4 说明了这个从早期统计参数综合开始的渐进过程。走向完整的端到端模型的过程通常包含这些升级:
1)简化文本分析模块和语言特征。在 SPSS 中,文本分析模块包含了文本归一化、短语/单词/音节分词、词性标注、韵律预测、字-音转换(包括多音消歧)等功能。在端到端模型中,只保留文本规范化和字音素转换,将字符转换为音素,或者直接以字符作为输入,删除整个文本分析模块。
2)声学特征简化,将 SPSS 中复杂的声学特征如 MGC 、 BAP 、 F0 简化为梅尔谱图。
3)单个端到端模型替代两个或三个模块。例如,声学模型和声码器可以被单一的声码器模型(如 WaveNet )取代。

阶段 0 。统计参数综合使用了三个基本模块,其中文本分析模块将字符转换为语言特征,声学模型从语言特征生成声学特征(其中通过声码分析获得目标声学特征),然后声码器通过参数计算合成语音波形。
阶段 1 。 Wang 等人(《First step towards end-to-end parametric tts synthesis: Generating spectral parameters with neural attention》)在统计参数综合中探索将文本分析与声学模型结合成端到端声学模型,该模型直接从音素序列生成声学特征,然后使用SPSS中的声码器生成波形。
阶段 2 。 WaveNet 首次提出从语言特征直接生成语音波形,可以看作是声模型和声码器的结合。这类模型仍然需要文本分析模块来生成语言特征。
阶段 3 。我们进一步提出了 Tacotron 来简化语言和声学特征,利用编码器-注意-解码器模型直接预测字符/音素的线性声谱图,并利用 Griffin-Lim 将线性声谱图转换为波形。接下来的工作如 DeepVoice 3 、 Tacotron 2 、 TransformerTTS 和 FastSpeech 1/2 从字符/音素中预测出语音谱图,并进一步使用神经声码器如 WaveNet、 WaveRNN 、 WaveGlow 和 Parallel WaveGAN 来生成波形。
阶段 4 。一些完全端到端 TTS 模型被开发用于直接文本到波形合成,如表 7 所示。 Char2Wav 利用基于 RNN 的编码器-注意-解码器模型从字符中生成声学特征,然后使用 SampleRNN 生成波形。将这两个模型联合用于直接语音合成。类似地, ClariNet 联合调整了一个自回归声学模型和一个非自回归声码器来产生直接波形。 FastSpeech 2 通过完全平行的结构直接从文本中生成语音,可以大大加快推理速度。为了降低文本-波形联合训练的难度,该方法利用一个辅助梅尔谱图解码器来帮助学习音素序列的上下文表示。一项名为 EATS 的并发工作也直接从字符/音素中生成波形,它利用了持续时间插值和软动态时间包装损耗来进行端到端对齐学习。 Wave-Tacotron 在 Tacotron 上构建了一个基于流的解码器来直接生成波形,该解码器在流部分使用并行波形生成,但在 Tacotron 部分仍然使用自回归生成。
2.6 其他分类
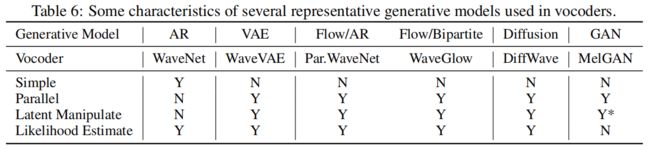
除了从图 3 所示的关键组件和数据流的角度来看的主要分类之外,我们还可以从几个不同的分类中对 TTS 工作进行分类,如图 5 所示:
1)自回归或非自回归。我们可以将这些工作分为自回归和非自回归生成模型。
2)生成模型。由于TTS是一个典型的序列生成任务,可以通过典型的生成模型进行建模,我们可以按照生成模型的不同进行分类:正常序列生成模型、FLOW模型、GAN模型、VAE模型和Diffusion模型。
3)网络结构。我们可以根据作品的网络结构进行划分,如CNN、RNN、self-attention、hybrid structures(其中包含不止一种结构,如CNN+RNN、CNN+self-attention)。

神经 TTS 模型的进化
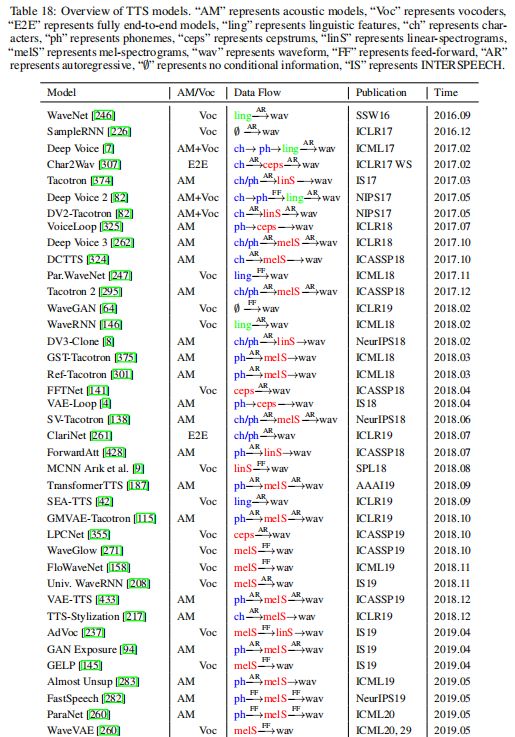
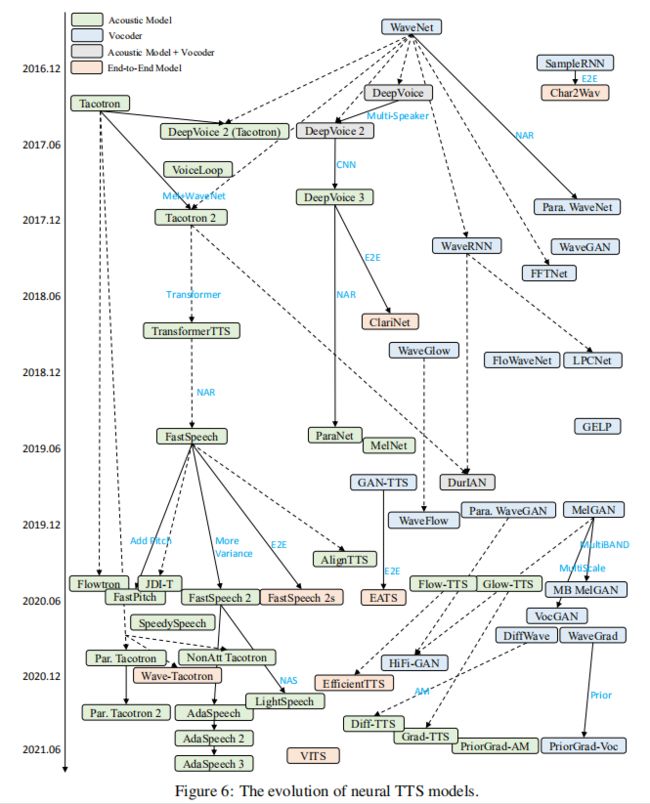
为了更好地理解神经TTS的各种研究工作及其关系的发展,我们阐述了神经TTS模型的演变,如图6所示。需要注意的是,我们是根据论文公开的时间(如放到arXiv上)来组织研究工作的,而不是之后正式发表。我们选择早期,因为我们欣赏研究人员尽早公开他们的论文,以鼓励知识共享。由于关于神经TTS的研究工作非常丰富,我们在图6中只选取了一些有代表性的工作,在表18中列出了更多的工作。
3 TTS 中的高级主题
3.1 背景与分类
在前一节中,我们已经从基本模型组件的角度介绍了神经TTS。在本节中,我们回顾了神经TTS中的一些高级主题,旨在推动前沿和覆盖更多实际产品的使用。具体而言,由于TTS是典型的序列到序列生成任务,自回归生成速度较慢,如何加快自回归生成或减小模型规模以实现快速语音合成是一个热门的研究课题(第3.2节)。
一个好的语音合成系统应该生成自然和可理解的语音,而大量的语音合成研究工作旨在提高语音合成的可理解性和自然度。例如,在训练TTS模型的数据不足的低资源场景中,合成语音可能具有低的可理解性和自然度。因此,很多工作的目标是在低资源设置下建立数据高效的TTS模型(第3.3节)。
由于TTS模型容易出现鲁棒性问题,生成的语音通常存在跳词和重复问题,影响语音的可理解性,因此很多工作都是为了提高语音合成的鲁棒性(第3.4节)。
为了提高自然度,许多作品的目的是模拟、控制和转移言语的风格/韵律,以产生表达性的言语(第3.5节)。
调整TTS模型以支持任何目标讲话者的声音对于广泛使用TTS是非常有帮助的。因此,在有限的适配数据和参数下,以高质量的语音进行高效的语音适配对于实际应用至关重要(第3.6节)。
图7显示了这些高级主题的分类。

3.2 快速 TTS
文本语音合成系统通常部署在云服务器或嵌入式设备中,对合成速度要求较高。然而,早期的神经TTS模型通常采用自回归的mel谱图和波形生成,这对于较长的语音序列来说是非常缓慢的(例如,如果跳数为10ms, 1秒的语音通常有500个mel谱图,如果采样率为24kHz,波形点为24k)。
为了解决这个问题,人们利用了不同的技术来加快TTS模型的推导:
(1)非自回归生成,它并行生成熔点谱图和波形;
(2)轻量化高效的模型结构;
(3)利用语音领域知识进行快速语音合成的技术。我们将如下介绍这些技术。
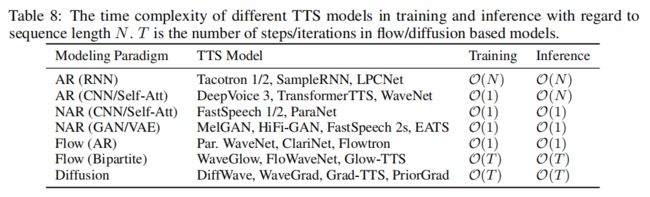
并行生成
表8总结了典型的建模范式、相应的TTS模型以及训练和推理的时间复杂度。可以看出,使用基于RNN的自回归模型(《Tacotron: Towards end-to-end speech synthesis》,《Natural tts synthesis by conditioning wavenet on mel spectrogram predictions》,《Samplernn: An unconditional end-to-end neural audio generation model》,《Lpcnet: Improving neural speech synthesis through linear prediction》)的TTS模型在训练和推理方面都比较慢,计算速度为O(N),其中N为序列长度。
为了避免RNN结构导致的慢训练时间,DeepVoice 3和TransformerTTS利用了CNN或基于自我注意的结构,这种结构可以支持并行训练,但仍然需要自回归推理。为了加快推理速度,FastSpeech 1/2设计了一个前馈Transformer,利用自注意结构进行并行训练和推理,其中计算减少到O(1)。
大多数基于GAN的mel谱图和波形生成模型(《Melgan: Generative adversarial networks for conditional waveform synthesis》,《Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis》,《Fastspeech 2: Fast and high-quality end-to-end text to speech》,《End-to-end adversarial text-to-speech》)是非自回归的,在训练和推断中都使用O(1)计算。Parallel WaveNet和ClariNet利用逆自回归流,可以实现并行推理,但需要教师精馏进行并行训练。
WaveGlow和FloWaveNet利用生成流进行并行训练和推理。然而,他们通常需要堆叠多个流迭代T,以确保数据和之前分布之间映射的质量。与基于流的模型相似,基于扩散的模型(《Wavegrad: Estimating gradients for waveform generation》,《Diffwave: A versatile diffusion model for audio synthesis》,《Priorgrad: Improving conditional denoising diffusion models with data-driven adaptive prior》,《Diff-tts: A denoising diffusion model for text-to-speech》,《Fast and lightweight on-device tts with tacotron2 and lpcnet》)在正向和反向过程中也需要多个扩散步骤T,这增加了计算量。
轻量化模型
虽然非负自回归可以充分利用推理加速的并行计算,模型参数的数量和计算总成本不降低,这使它慢当部署在移动电话或嵌入式设备,因为这些设备不够强大的并行计算能力。
因此,即使使用自回归生成,我们也需要设计计算成本更低的轻量级高效模型来提高推理速度。设计轻量化模型的一些广泛使用的技术包括剪枝、量化、知识蒸馏(《Distilling the knowledge in a neural network》)和神经结构搜索(《Lightspeech: Lightweight and fast text to speech with neural architecture search》,《Nas-bert: Taskagnostic and adaptive-size bert compression with neural architecture search》)等。
WaveRNN使用双softmax、权值剪枝、子尺度预测等技术来加速推理。LightSpeech利用神经架构搜索来寻找轻量级架构,进一步将FastSpeech 2的推理速度提高6.5倍,同时保持语音质量。SqueezeWave利用波形重塑来减少时间长度,并将一维卷积替换为深度可分离卷积来降低计算成本,同时实现类似的音频质量。
Kanagawa和Ijima(《Lightweight lpcnet-based neural vocoder with tensor decomposition》)利用张量分解对LPCNet的模型参数进行压缩。Hsu和Lee(《Wg-wavenet: Real-time high-fidelity speech synthesis without gpu》)提出了一个基于大量压缩流的模型来减少计算资源,以及一个基于wavenet的后过滤器来保持音频质量。DeviceTTS(《Devicetts: A small-footprint, fast, stable network for on-device text-to-speech》)利用DFSMN(《Deep-fsmn for large vocabulary continuous speech recognition》)和混合分辨率解码器的模型结构在一个解码步骤中预测多帧以加快推理。
LVCNet对不同的波形间隔采用位置变量卷积,其中卷积系数由mel谱图预测。它加快了平行波根声码器的4倍没有任何退化的音质。Wang等人(《Fcl-taco2: Towards fast, controllable and lightweight text-to-speech synthesis》)提出了一种半自回归生成mel谱图的模式,其中mel谱图对单个音位以自回归模式生成,对不同音位以非自回归模式生成。
加速领域知识
可以利用来自语音的领域知识来加快推理,如线性预测(《Lpcnet: Improving neural speech synthesis through linear prediction》)、多波段建模(《Durian: Duration informed attention network for speech synthesis》)、子尺度预测(《Efficient neural audio synthesis》)、多帧预测(《Fast, compact, and high quality lstm-rnn based statistical parametric speech synthesizers for mobile devices》)、流合成(《High quality streaming speech synthesis with low, sentence-length-independent latency》)等。LPCNet将数字信号处理与神经网络相结合,利用线性预测系数计算下一个波形,利用轻量级模型预测残差值,加快了自回归波形生成的推理。
另一种用于加快声码器推理速度的技术是子带建模,它将波形划分为多个子带以实现快速推理。典型模型包括DurIAN、多波段MelGAN、子波段WaveNet和多波段LPCNet。集束LPCNet通过样本集束和比特集束降低了LPCNet的计算复杂度,实现了2倍以上的加速。流TTS 一旦有输入标记出现,就可以合成语音,而无需等待整个输入句子,也可以加快推理速度。
FFTNet使用一个简单的架构来模拟快速傅里叶变换(FFT),它可以实时生成音频样本。Okamoto等人(《Improving fftnet vocoder with noise shaping and subband approaches》)利用噪声整形和子带技术进一步增强了FFTNet,在保持小模型尺寸的同时提高了语音质量。
Popov等人(《Fast and lightweight on-device tts with tacotron2 and lpcnet》)提出帧分裂和交叉衰落并行合成波形的某些部分,然后将合成的波形连接在一起,以确保在低端设备上快速合成。Kang等人(《Fast dctts: Efficient deep convolutional text-to-speech》)利用网络缩减和保真度改善技术(如组高速公路激活)加速DCTTS(《Efficiently trainable textto-speech system based on deep convolutional networks with guided attention》),该技术可以用单个CPU线程实时合成语音。
3.3 低资源 TTS
构建高质量的 TTS 系统通常需要大量高质量的成对文本和语音数据。然而,世界上有7000多种语言,而大多数语言都缺乏用于开发TTS系统的培训数据。因此,流行的商业化语音服务只能支持数十种语言。对低资源语言支持TTS不仅具有商业价值,而且有利于社会公益。
因此,很多研究工作都是在低数据资源场景下构建TTS系统。我们在表9中总结了一些用于低资源TTS的代表性技术,并将这些技术介绍如下。

自我指导训练。虽然配对的文本和语音数据很难收集,但不配对的语音和文本数据(特别是文本数据)相对容易获得。自我监督的预训练方法可以用来提高语言理解或语音生成能力(《Semi-supervised training for improving data efficiency in end-to-end speech synthesis》,《Word embedding for recurrent neural network based tts synthesis》,《Joint training framework for text-to-speech and voice conversion using multi-source tacotron and wavenet》,《Towards transfer learning for end-to-end speech synthesis from deep pre-trained language models》)。例如,TTS中的文本编码器可以通过预先训练的BERT模型进行增强(《Png bert: Augmented bert on phonemes and graphemes for neural tts》),TTS中的语音解码器可以通过自回归的mel谱图预测进行预先训练或与语音转换任务联合训练。
此外,语音可以量化为离散的标记序列,类似于音素或字符序列(《Vqvae unsupervised unit discovery and multi-scale code2spec inverter for zerospeech challenge 2019》)。这样,可以将量化的离散标记和语音视为伪配对数据,预先训练一个TTS模型,然后对少数真正配对的文本和语音数据进行微调(《Towards unsupervised speech recognition and synthesis with quantized speech representation learning》,《Semi-supervised learning for multi-speaker text-to-speech synthesis using discrete speech representation》,《Unsupervised learning for sequence-to-sequence text-to-speech for low-resource languages》)。
跨语言转移。尽管配对文本和语音数据在低资源语言中是稀缺的,但在丰富资源语言中却是丰富的。由于人类语言拥有相似的发音器官、发音(《The evolutionary history of the human speech organs》)和语义结构(《Multilingual neural machine translation with language clustering》),在丰富资源语言上预先训练TTS模型可以帮助在低资源语言中实现文本和语音之间的映射(《End-to-end text-to-speech for low-resource languages by cross-lingual transfer learning》,《Lrspeech: Extremely low-resource speech synthesis and recognition》,《Hierarchical transfer learning for multilingual, multi-speaker, and style transfer dnn-based tts on low-resource languages》,《Efficient neural speech synthesis for lowresource languages through multilingual modeling》,《A dnn-based mandarin-tibetan cross-lingual speech synthesis》,《A study of multilingual neural machine translation》,《Deep learning for mandarintibetan cross-lingual speech synthesis》,《One model, many languages: Meta-learning for multilingual text-to-speech》,《Uwspeech: Speech to speech translation for unwritten languages》)。
通常,丰富语言和低资源语言之间有不同的音素集。因此,Chen等人(《End-to-end text-to-speech for low-resource languages by cross-lingual transfer learning》)提出将不同语言的音素集之间的嵌入映射,LRSpeech摒弃了预先训练的音素嵌入,对低资源语言从头开始进行音素嵌入。采用国际音标字母(IPA)或字节表示来支持多种语言的任意文本。此外,在进行跨语言迁移时,也可以考虑语言相似性。
交叉说话人转换。当某一个说话人的语音数据有限时,可以利用其他说话人的数据来提高该说话人的合成质量。这可以通过将其他发言者的声音转化为这个目标声音通过转换来增加训练数据(《Low-resource expressive text-to-speech using data augmentation》),或通过调整TTS模型训练其他声音这一目标声音通过声音的适应或克隆(《Sample efficient adaptive text-to-speech》,《Adaspeech: Adaptive text to speech for custom voice》)将在3.6节中介绍。
语音链/转换。文本到语音(TTS)和自动语音识别(ASR)是两个双重任务(《Dual Learning》),可以相互利用以改善彼此。语音链(《Listening while speaking: Speech chain by deep learning》,《Machine speech chain with one-shot speaker adaptation》)和反向转换(《Almost unsupervised text to speech and automatic speech recognition》,《Lrspeech: Extremely low-resource speech synthesis and recognition》)等技术利用额外的未配对文本和语音数据来提高TTS和ASR的性能。
陌生数据集挖掘。在某些情况下,Web中可能存在一些低质量的成对文本和语音数据。Cooper (《Text-to-speech synthesis using found data for low-resource languages》), Hu等人(《Neural text-to-speech adaptation from low quality public recordings》)提出挖掘这类数据并开发复杂的技术来训练TTS模型。一些技术如语音增强(《Speech enhancement of noisy and reverberant speech for text-to-speech》)、去噪(《Denoispeech: Denoising text to speech with frame-level noise modeling》)和解纠缠(《Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis》,《Disentangling correlated speaker and noise for speech synthesis via data augmentation and adversarial factorization》)可以用来提高陌生挖掘的语音数据的质量。
3.4 鲁棒 TTS
一个好的TTS系统应该是健壮的,即使遇到问题也能根据文本生成正确的语音。在神经TTS中,当从字符/音素序列生成mel谱图序列时,声学模型中经常出现如单词跳过、重复和注意力崩溃等鲁棒性问题。
从根本上说,这些健壮问题的原因有两类:
1)学习字符/音素和mel声谱之间的排列困难;
2)自回归生成中产生的曝光偏差和误差传播问题。
声码器不会面临严重的鲁棒问题,因为声学特征和波形已经明智地对齐(即,每一帧的声学特征对应一定数量(跳数)的波形点)。因此,现有的鲁棒TTS研究分别解决了上述两个问题。
对于文字/音素与mel谱图的对齐学习,作品可分为两个方面:
1)增强注意机制的稳健性(《Tacotron: Towards end-to-end speech synthesis》,《Char2wav: End-to-end speech synthesis》,《Natural tts synthesis by conditioning wavenet on mel spectrogram predictions》,《Forward attention in sequence-tosequence acoustic modeling for speech synthesis》,《Efficiently trainable textto-speech system based on deep convolutional networks with guided attention》,《Robust sequence-to-sequence acoustic modeling with stepwise monotonic attention for neural tts》,《Multispeech: Multi-speaker text to speech with transformer》);
2)移除注意,明确预测持续时间,以连接文本和语音之间的长度不匹配(《Fastspeech: Fast, robust and controllable text to speech》,《Durian: Duration informed attention network for speech synthesis》,《End-to-end adversarial text-to-speech》,《Parallel tacotron 2: A non-autoregressive neural tts model with differentiable duration modeling》)。
对于自回归生成中的曝光偏差和误差传播问题,工作还可以分为两个方面:
1)改进自回归生成以缓解暴露偏差和误差传播问题(《A new gan-based end-to-end tts training algorithm》,《A new end-to-end long-time speech synthesis system based on tacotron2》,《Teacher-student training for robust tacotron-based tts》,《Almost unsupervised text to speech and automatic speech recognition》);
2)去除自回归生成,而使用非自回归生成(《Fastspeech: Fast, robust and controllable text to speech》,《Fastspeech 2: Fast and high-quality end-to-end text to speech》,《Non-autoregressive neural text-to-speech》,《End-to-end adversarial text-to-speech》)。
我们总结了这些类别中用于提高健壮性的一些流行技术,如表10所示。解决这两个问题的工作可能有重叠之处,比如一些工作可能增强了AR或NAR生成的注意机制,同样的,时间预测可以同时应用于AR和NAR生成。我们将在下文回顾这些类别。
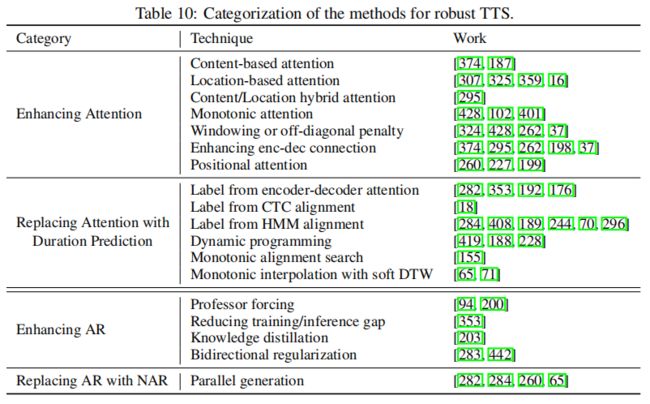
3.4.1 增强注意力
在自回归声学模型中,大量的单词跳过/重复和注意崩溃问题是由编码器-解码器注意中学习到的不正确的注意对齐引起的。为了缓解这一问题,我们考虑了文本(字符/音素)序列和mel谱图序列之间的对齐的一些特性:
1) 局部性:一个字/音素标记可以对齐一个或多个连续的mel谱帧,而一个mel谱帧只能对齐一个字/音素标记,这样可以避免注意模糊和注意崩溃;
2)单调性:如果A字在B字后面,A字对应的mel谱图也在B字对应的mel谱图后面,这样可以避免单词重复;
3)完整性:每个字符/音素标记必须包含至少一个梅尔频谱帧,避免跳过单词。
根据是否满足上述三个属性,我们分析了增强注意力的技术(见表10),并在表11中列出了它们。我们将在下文描述这些技术。

基于内容的关注。TTS采用的早期注意机制(例如Tacotron)是基于内容的(《Neural machine translation by jointly learning to align and translate》),其中注意分布是由来自编码器和解码器的隐藏表征之间的匹配程度决定的。基于内容的注意适用于神经机器翻译等任务,其中源标记和目标标记之间的对齐纯粹基于语义(内容)。
然而,对于自动语音识别(《Attention-based models for speech recognition》,《Listen, attend and spell: A neural network for large vocabulary conversational speech recognition》,《State-of-the-art speech recognition with sequence-to-sequence models》)和文本到语音合成(《Tacotron: Towards end-to-end speech synthesis》)等任务,文本和语音之间的对齐具有一些特定的属性。例如,在TTS(《Robust sequence-to-sequence acoustic modeling with stepwise monotonic attention for neural tts》)中,注意对齐应该是局部的、单调的和完整的。因此,应该设计先进的注意机制来更好地利用这些特性。
基于位置的注意。考虑到文本和语音的对齐依赖于它们的位置,基于位置的注意力(《Generating sequences with recurrent neural networks》,《Location-relative attention mechanisms for robust long-form speech synthesis》)被提出利用位置信息进行对齐。Char2Wav、VoiceLoop和MelNet等几个TTS模型采用了基于位置的注意力。如表11所示,如果处理得当,基于位置的注意力可以保证单调性。
内容/位置混合的注意。为了结合基于内容的注意和基于位置的注意的优点,Chorowski等人(《Attention-based models for speech recognition》)、Shen等人(《Natural tts synthesis by conditioning wavenet on mel spectrogram predictions》)引入了位置敏感注意:在计算当前的注意对齐时,使用之前的注意对齐。这样,由于单调对齐,注意力会更加稳定。
单调的注意。对于单调注意(《Online and linear-time attention by enforcing monotonic alignments》,《Monotonic chunkwise attention》,《Initial investigation of an encoder-decoder end-to-end tts framework using marginalization of monotonic hard latent alignments》,《Feathertts: Robust and efficient attention based neural tts》),注意位置是单调增加的,这也利用了文本和语音之间的对齐是单调的先验。这样可以避免跳过和重复的问题。然而,在上述单调注意中不能保证完备性。因此,He等人(《Robust sequence-to-sequence acoustic modeling with stepwise monotonic attention for neural tts》)提出了逐级单调注意,在每个解码步骤中,注意对齐位置最多向前移动一步,不允许跳过任何输入单元。
窗口或非对角线罚款。由于注意对齐是单调的、对角线的,所以Chorowski等人(《Attention-based models for speech recognition》)、Tachibana等人(《Efficiently trainable textto-speech system based on deep convolutional networks with guided attention》)、Zhang等人(《Forward attention in sequence-tosequence acoustic modeling for speech synthesis》)、Ping等人(《Deep voice 3: 2000-speaker neural text-to-speech》)、Chen等人(《Multispeech: Multi-speaker text to speech with transformer》)提出将编码结果的注意限制在窗口子集中。这样,学习的灵活性和难度都降低了。Chen等利用惩罚损失进行非对角注意分配,通过构建频带掩模并鼓励在对角频带内学习注意。
加强编码器-解码器连接。由于语音相邻帧间的相关性更强,解码器本身包含了足够的信息来预测下一帧,从而容易忽略编码器的文本信息。因此,一些研究提出了增强编码器和解码器之间的连接,从而提高注意对齐。Wang等人(《Tacotron: Towards end-to-end speech synthesis》),Shen等人(《Natural tts synthesis by conditioning wavenet on mel spectrogram predictions》)使用多帧预测,在每个解码器步生成多个不重叠的输出帧。这样,为了预测连续帧,解码器被迫利用编码器侧的信息,这可以提高对齐学习。
其他作品也使用在解码器前的prenet中一个大的dropout,或者在prenet中一个小的隐藏大小作为瓶颈,这可以防止在预测当前帧时简单地复制最后一帧。解码器可以从编码器侧获得更多的信息,有利于对齐学习。Ping等人(《Deep voice 3: 2000-speaker neural text-to-speech》),Chen等人提出增强源与目标序列之间位置信息的连接,有利于注意对齐学习。Liu等人(《Maximizing mutual information for tacotron》)利用基于CTC(《Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks》)的ASR作为周期损失来鼓励生成的mel谱图包含文本信息,这也可以增强编码器-解码器连接,从而更好地进行注意对齐。
位置的注意。一些非自回归生成模型(《Non-autoregressive neural text-to-speech》,《Flowtts: A non-autoregressive network for text to speech based on flow》)利用位置信息作为查询来参加来自编码器的键和值,这是另一种建立编码器和解码器之间的连接以进行并行生成的方法。
3.4.2 用持续时间预测取代注意力
改进语篇注意对齐可以在一定程度上缓解鲁棒性问题,但不能完全避免鲁棒性问题。因此,一些著作(《Fastspeech: Fast, robust and controllable text to speech》,《Durian: Duration informed attention network for speech synthesis》,《Glow-tts: A generative flow for text-to-speech via monotonic alignment search》,《End-to-end adversarial text-to-speech》)提出了完全去除编码器-解码器-注意,明确预测每个字符/音素的持续时间,并根据持续时间扩展文本隐藏序列,以匹配梅尔谱图序列的长度。
然后,模型可以以自回归或非自回归的方式生成mel谱图序列。有趣的是,早期的SPSS使用持续时间进行对齐,然后序列到序列的模型去掉了持续时间,而使用注意,而后期的TTS模型丢弃了注意,再次使用持续时间,这是一种技术复兴。
现有的神经TTS持续时间预测研究主要从两个方面进行:1)使用外部对齐工具获得持续时间标签或联合训练获得持续时间标签;2)端到端优化持续时间预测,或者在训练中使用ground-truth持续时间,在推理中使用predicted持续时间。我们根据表12中的两个透视图对工作进行了总结,并描述如下。

外部校准。利用外部对齐工具(《The aligner: Text-to-speech alignment using markov models》,《Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks》,《Montreal forced aligner: Trainable text-speech alignment using kaldi》,《Moboaligner: A neural alignment model for non-autoregressive tts with monotonic boundary search》)的作品根据对齐工具可以分为几个类别:
1)编码器-解码器注意:FastSpeech从一个自回归声学模型的注意对齐中获得持续时间标签。SpeedySpeech遵循了FastSpeech的类似管道,从自回归教师模型中提取时长,但用纯CNN代替了整个网络结构。
2) CTC对齐。Beliaev等人的(《Talknet: Fully-convolutional nonautoregressive speech synthesis model》)利用基于CTC的ASR模型提供音位和mel谱图序列之间的对齐。
3) HMM对齐:FastSpeech 2利用基于HMM的蒙特利尔强制对齐(MFA)来获取持续时间。其他作品如DurIAN , RobuTrans , Parallel Tacotron , Non-Attentive Tacotron使用强制对齐或语音识别工具进行对齐。
内部校准。AlignTTS遵循FastSpeech的基本模型结构,但利用基于动态规划的方法,使用多阶段训练学习文本和mel谱图之间的对齐。JDI-T遵循FastSpeech从自回归教师模型中提取时长,但联合训练自回归和非自回归模型,不需要两阶段训练。Glow-TTS利用一种新的单调对齐搜索来提取持续时间。EATS利用插值和软动态时间扭曲(DTW)损失,以完全端到端方式优化持续时间预测。
非端到端优化。典型的持续时间预测方法通常使用外部/内部对齐工具获得的持续时间进行训练,并使用预测的持续时间进行推断。预测的持续时间不是端到端的优化接收引导信号(梯度)从mel谱图损失。
端到端优化。为了联合优化持续时间以获得更好的韵律效果,EATS利用一个内部模块预测持续时间,并借助持续时间插值和软DTW损失来端到端优化持续时间。Parallel Tacotron 2遵循了EATS的实践,以确保可区分的持续时间预测。非专注的Tacotron提出了一种时长预测的半监督学习,在没有时长标签的情况下,预测的时长可以用于上采样。
3.4.3 增强 AR 生成
自回归序列生成通常存在暴露偏差和误差传播(《Scheduled sampling for sequence prediction with recurrent neural networks》,《Beyond error propagation in neural machine translation: Characteristics of language also matter》)。暴露偏差是指序列生成模型通常以之前的ground-truth值作为输入(即teacher- forced)进行训练,而在推理中以之前的预测值作为输入进行序列自回归生成。训练和推理之间的不匹配会导致错误传播推理,其中预测错误可以沿着生成的序列快速积累。
一些工作已经研究了不同的方法来缓解曝光偏差和误差传播问题。Guo等人(《A new gan-based end-to-end tts training algorithm》)杠杆教授强迫来缓解真实数据和预测数据的不同分布之间的不匹配。刘等人(《Teacherstudent training for robust tacotron-based tts》)进行师生蒸馏来减少暴露的偏见问题,老师与teacher-forcing训练模式,学生以先前预测的值作为输入和优化来减少老师和学生之间的距离隐状态模型。
由于错误传播,生成的mel谱图序列的右部分通常比左部分差,一些工作利用从左到右和从右到左的生成(《Efficient bidirectional neural machine translation》)来进行数据增强(《Almost unsupervised text to speech and automatic speech recognition》)和正则化(《Forward-backward decoding sequence for regularizing end-to-end tts》)。Vainer和Dušek(《Speedyspeech: Efficient neural speech synthesis》)通过向每个输入谱图像素添加一些随机高斯噪声来模拟预测误差,利用一些数据增强来缓解暴露偏差和误差传播问题,通过用随机帧替换若干帧来降低输入谱图的质量,以鼓励模型使用暂时更远处的帧,等等。
3.4.4 用 NAR 代取代 AR 生成
虽然上述方法可以缓解AR产生中的曝光偏差和误差传播问题,但不能彻底解决问题。因此,一些作品直接采用非自回归生成来避免这些问题。根据注意使用情况和持续时间预测情况可分为两类。一些工作,如ParaNet和Flow-TTS使用位置注意(《Deep voice 3: 2000-speaker neural text-to-speech》)在文本和语音对齐并行生成。剩下的工作如FastSpeech , EATS使用持续时间预测来桥接文本和语音序列之间的长度不匹配。
基于以上小节的介绍,我们根据对齐学习和AR/NAR生成,有了一个新的TTS类别,如表13所示:1)AR+Attention,如Tacotron , DeepVoice 3 , TransformerTTS;2) AR + Non-Attention(持续时间),如DurIAN , RobuTrans,和Non-Attention Tacotron;3)Non-AR+Attention,如ParaNet , Flow-TTS, VARA-TTS;4) NOn-AR + Non-Attention,如FastSpeech 1/2 , Glow-TTS,和EATS。

3.5 富有表现力的 TTS
从文本到语音的目标是合成可理解和自然的语音。合成声音的自然程度在很大程度上取决于合成声音的表现力,而表现力是由合成声音的内容、音色、韵律、情感、风格等多种特征所决定的。表现性TTS的研究涉及内容、音色、韵律、风格、情感等的建模、解缠、控制和传递。我们将在本小节中回顾这些主题。
表达性语音合成的关键是处理一对多映射问题,即同一文本在时长、音高、音量、说话人风格、情感等方面有多个语音变体对应。在没有足够的输入信息的情况下,在正则L1损失(《Speech probability distribution》,《Probabilistic modeling of speech in spectral domain using maximum likelihood estimation》)下建模一对多映射会导致过平滑的梅尔谱图预测(《A speech parameter generation algorithm considering global variance for hmm-based speech synthesis》,《Postfilters to modify the modulation spectrum for statistical parametric speech synthesis》)。,而不是捕捉每一个语音表达的表现力,这将导致低质量和表达性的语音。因此,将这些变异信息作为输入,并对这些变异信息进行更好的建模,对于缓解这一问题,提高合成语音的表达性具有重要意义。
此外,通过提供变异信息作为输入,我们可以对变异信息进行分解、控制和传输:1)通过调整推理中的这些变异信息(任何特定说话人的音色、风格、重音、语速等),我们可以控制合成的语音;2)通过提供另一种风格对应的变体信息,可以将语音转换为该风格;3)为了实现细粒度的语音控制和传递,我们需要理清内容与韵律、音色与噪声等不同的变异信息。
在本小节的其余部分中,我们首先对这些变异信息进行综合分析,然后介绍一些对这些变异信息进行建模、解纠缠、控制和传递的高级技术。
3.5.1 变异信息的分类
我们首先将合成声音所需的信息分为四个方面:
(1)文本信息,可以是字符,也可以是音素,代表合成语音的内容(即要说什么)。一些研究通过增强的词嵌入或文本预处理来改进文本的表示学习(《Towards transfer learning for end-to-end speech synthesis from deep pre-trained language models》,《Pre-trained text embeddings for enhanced text-to-speech synthesis》,《Improving prosody with linguistic and bert derived features in multi-speaker based mandarin chinese neural tts》,《Png bert: Augmented bert on phonemes and graphemes for neural tts》),目的是提高合成语音的质量和表达能力。
(2)说话人或音色信息,即代表说话人的特征(即说话人是谁)。一些多扬声器TTS系统通过扬声器查找表或扬声器编码器显式地建模扬声器表示(《Deep voice 2: Multi-speaker neural text-to-speech》,《Deep voice 3: 2000-speaker neural text-to-speech》,《Transfer learning from speaker verification to multispeaker text-to-speech synthesis》,《Boffin tts: Few-shot speaker adaptation by bayesian optimization》,《Multispeech: Multi-speaker text to speech with transformer》)。
(3)韵律、风格或情感信息,包括语音的语调、重音和节奏,代表了如何读出文本(《Experimental and theoretical advances in prosody: A review》,《Intonational phonology》)。韵律/风格/情感是提高言语表达性的关键信息,绝大多数表现性TTS研究的重点是提高言语的韵律/风格/情感(《Towards end-to-end prosody transfer for expressive speech synthesis with tacotron》,《Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis》,《Predicting expressive speaking style from text in end-to-end speech synthesis》,《Interactive text-to-speech via semi-supervised style transfer learning》,《Emotional speech synthesis with rich and granularized control》,《Generating diverse and natural text-to-speech samples using a quantized fine-grained vae and autoregressive prosody prior》)。
(4)录音设备或噪声环境,是传达语音的通道,与语音的内容/说话人/韵律无关,但会影响语音的质量。该领域的研究主要集中在纯净语音合成的解缠、控制和去噪等方面(《Disentangling correlated speaker and noise for speech synthesis via data augmentation and adversarial factorization》,《Adaspeech: Adaptive text to speech for custom voice》,《Denoispeech: Denoising text to speech with frame-level noise modeling》)。
3.5.2 建模变异信息
对于不同粒度下不同类型的变异信息,有很多方法被提出,如表14所示。

信息类型
我们可以根据被建模的信息类型对作品进行分类:1)显性信息,我们可以显式地获得这些变异信息的标签;2)隐性信息,我们只能隐式地获得这些变异信息。
对于显式信息,我们直接使用它们作为输入,以增强模型的表现力合成。我们可以通过不同的方式获取这些信息:1)从标注数据中获取语言、风格、说话人ID ;2)从语音中提取音高和能量信息或从配对的文本和语音数据中提取持续时间。在早期的TTS系统中,可以根据标注模式对韵律信息进行标注:ToBI , AuToBI , Tilt , INTSINT , SLAM。
在某些情况下,没有可用的显式标签,或者显式标签通常需要大量人力,并且不能覆盖特定的或细粒度的变化信息。因此,我们可以隐式地从数据中建模变异信息。典型的隐式建模方法包括:
参考编码器。skry - ryan等人(《Towards end-to-end prosody transfer for expressive speech synthesis with tacotron》)将韵律定义为在考虑了文本内容、说话人音色和通道效应以及不需要通过参考编码器进行显式注释的模型韵律变化后仍存在的语音信号变化。具体来说,它从参考音频中提取韵律嵌入,并将其作为解码器的输入。训练时使用ground-truth参考音频,推理时使用另一个参考音频合成具有相似韵律的语音。
Wang等人(《Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis》)从参考音频中提取一个嵌入,并将其作为查询来参加(通过基于Q/K/V的注意(《Attention is all you need》))样式标记库,并将注意结果用作表达性语音合成TTS模型的韵律条件。样式标记可以增加TTS模型学习不同类型样式的能力和多样性,并实现数据集中数据样本之间的知识共享。风格标记库中的每个标记可以学习不同的韵律表征,如不同的语速和情绪。在推理过程中,它可以使用参考音频参加并提取韵律表示,类似于训练,或者简单地选择一个或一些风格标记来合成语音。
变分自编码器。Zhang等人(《Learning latent representations for style control and transfer in end-to-end speech synthesis》)利用高斯先验作为正则化,利用VAE对潜在空间中的方差信息进行建模,这可以实现表达建模,控制合成风格。一些研究(《Expressive speech synthesis via modeling expressions with variational autoencoder》,《* Disentangling correlated speaker and noise for speech synthesis via data augmentation
and adversarial factorization*》,《Using vaes and normalizing flows for one-shot text-to-speech synthesis of expressive speech》,《Parallel tacotron: Non-autoregressive and controllable tts》)也利用VAE框架更好地建模表达合成的方差信息。
高级生成模型。解决一对多映射问题和对抗过平滑预测的一种方法是使用高级生成模型隐式学习变化信息,从而更好地建模多模态分布。我们知道,不同的损失适用于不同的分布假设。
例如,L1适用于拉普拉斯分布,L2适用于高斯分布,高斯/拉普拉斯/Logistic混合分布适用于多模态分布,其他损耗如SSIM适用于高阶统计,GAN基损耗可用于任何分布。因此,为了缓解过平滑问题,我们需要选择能够更好地模拟多模态分布的损失,如基于混合分布、SSIM、Flow、GAN或基于扩散的损失。
文本预训练。通过使用预训练的词嵌入或模型参数,可以提供更好的文本表示。
信息粒度
变体信息可以以不同的粒度建模。我们从粗粒度到细粒度对这些信息进行描述:
1)语言级别和说话人级别,其中多语言和多说话人TTS系统使用语言ID或说话人ID来区分语言和说话人。
2)段落水平,其中TTS模型需要考虑长形式阅读中话语/句子之间的关系。
3)话语层次,其中从参考语音中提取一个单独的隐藏向量来代表该话语的木材/风格/韵律。
4)单词/音节级,可以对话语级信息无法覆盖的细粒度风格/韵律信息进行建模。
5)字符/音素层次,如音长、音高或韵律信息。
6)帧级,最细粒度信息。相关工作见表14。
此外,用覆盖不同粒度的层次结构对方差信息进行建模有助于表达合成。Suni等人(《Hierarchical representation and estimation of prosody using continuous wavelet transform》)论证了韵律的层次结构本质上存在于口语中。Kenter等人(《Chive: Varying prosody in speech synthesis with a linguistically driven dynamic hierarchical conditional variational network》)从框架和音素水平预测韵律特征到音节水平,并连接单词和句子水平特征。Hono等人(《Hierarchical multi-grained generative model for expressive speech synthesis》)利用多粒度的VAE获取不同时间分辨率的潜变量,并从粗级别(例如,从话语级到短语级,再到单词级)抽取更细级别的潜变量。Sun等人(《Fullyhierarchical fine-grained prosody modeling for interpretable speech synthesis》)利用VAE对音位级和词级的方差信息建模,并将它们组合在一起作为译码器的输入。Chien和Lee对韵律预测进行了(《Hierarchical prosody modeling for non-autoregressive speech synthesis》)研究,提出了一个从词到音位的层次结构来提高韵律预测。
3.5.3 解缠、控制和转移
在本小节中,我们回顾了分离、控制和转移变异信息的技术,如表15所示。

解除对抗训练
当多种风格或韵律信息纠缠在一起时,为了更好地进行表达性语音合成和控制,需要在训练中对它们进行解缠。Ma等人(《Neural tts stylization with adversarial and collaborative games》)通过对抗性和合作性游戏增强了内容风格的解缠能力和可控性。Hsu等人(《Disentangling correlated speaker and noise for speech synthesis via data augmentation and adversarial factorization》)利用VAE框架进行对抗性训练,从说话人信息中分离噪声。
Qian等人(《Unsupervised speech decomposition via triple information bottleneck》)提出使用三种瓶颈重构来分离语音流的节奏、音高、内容和音色。Zhang等人(《Denoispeech: Denoising text to speech with frame-level noise modeling》)提出通过帧级噪声建模和对抗性训练从说话人中分离噪声。
控制的周期一致性/反馈损失
当提供样式标签等变异信息作为输入时,TTS模型应该用相应的样式合成语音。然而,如果不添加约束,TTS模型往往忽略方差信息和不遵循风格的合成语音。为了增强输入方差信息的可控性,一些研究提出了使用周期一致性或反馈来鼓励合成语音在输入中包含方差信息。Li等人(《Controllable emotion transfer for end-toend speech synthesis》)通过添加一个带有反馈循环的情感风格分类器来进行可控的情感迁移,该分类器鼓励TTS模型合成带有特定情感的语音。
. Whitehill等人(《Multi-reference neural tts stylization with adversarial cycle consistency》)使用风格分类器提供反馈损失,以鼓励合成给定的风格。同时,结合不同风格分类器之间的对抗性学习,保证了多重参考音频中不同风格的保存。Liu等人(《Improving unsupervised style transfer in end-to-end speech synthesis with end-to-end speech recognition》)利用ASR提供反馈损失来训练不匹配的文本和语音,其目的是减少训练和推理之间的不匹配,因为随机选择的音频被用作推理的参考。其他作品(《Fitting new speakers based on a short untranscribed sample》,《Expressive tts training with frame and style reconstruction loss》,《From speaker verification to multispeaker speech synthesis, deep transfer with feedback constraint》,《Aishell-3: A multi-speaker mandarin tts corpus and the baselines》)利用反馈损失来确保风格、说话人嵌入等方面的可控性。
半监督学习控制
一些用来控制演讲的属性包括音调、持续时间、能量、韵律、情绪、说话人、噪音等。如果每个属性都有标签,我们可以很容易地控制合成语音,使用标签作为模型训练的输入,并使用相应的标签在推理中控制合成语音。然而,当没有可用的标签/标签时,或只有一部分可用时,如何解缠和控制这些属性是具有挑战性的。当部分标签可用时,Habib等人(《Semi-supervised generative modeling for controllable speech synthesis》)提出了半监督学习方法来学习VAE模型的潜变量,以控制情感或语率等属性。当没有可用的标签时,Hsu等人(《Hierarchical generative modeling for controllable speech synthesis》)提出使用高斯混合VAE模型解纠缠不同的属性,或使用梯度反转或对抗训练解纠缠说话人和噪声,可以为有噪声的说话人合成纯净语音。
变更转让方差信息
我们可以通过改变变异信息来转换合成语音的风格。如果在已标注的标签中提供变异信息,我们就可以在训练中使用该语音和相应的标签,在推理中传递带有不同标签的语音风格(《Learning to speak fluently in a foreign language: Multilingual speech synthesis and cross-language voice cloning》,《One model, many languages: Meta-learning for multilingual text-to-speech》,《Controllable emotion transfer for end-toend speech synthesis》,《Multispeech: Multi-speaker text to speech with transformer》)。或者,如果没有已标注的标签作为变异信息,我们可以在训练过程中从言语中获取变异信息,无论是通过如上所述的显式建模还是隐式建模:语音的音高、持续时间和能量可以通过参考编码器(VAE)显式提取,一些潜在表征可以通过参考编码器(VAE)隐式提取。这样,为了在推理中实现语体迁移,我们可以通过三种方式获取变异信息:1)从参考语音中提取;2)从文本预测;3)从潜空间取样获得。
3.6 自适应 TTS
自适应TTS是TTS的一个重要功能,它可以为任何用户合成语音。学术界和业界有不同的术语,如语音适应(《Sample efficient adaptive text-to-speech》)、语音克隆(《Neural voice cloning with a few samples》)、自定义语音(《Adaspeech: Adaptive text to speech for custom voice》)等。自适应TTS一直是国内外研究的热点。大量的统计参数语音合成研究了语音自适应(《Multi-speaker modeling and speaker adaptation for dnn-based tts synthesis》,《A study of speaker adaptation for dnn-based speech synthesis.》,《Speaker representations for speaker adaptation in multiple speakers blstm-rnn-based speech synthesis》,《Speaker adaptation in dnnbased speech synthesis using d-vectors》,《Linear networks based speaker adaptation for speech synthesis》),最近的语音克隆挑战也吸引了很多参与者(《The multi-speaker multi-style voice cloning challenge 2021》,《The as-nu system for the m2voc challenge》,《Cuhk-ee voice cloning system for icassp 2021 m2voc challenge》,《Investigating on incorporating pretrained and learnable speaker representations for multi-speaker multi-style text-to-speech》)。在自适应TTS场景中,源TTS模型(通常在多说话人语音数据集上训练)通常对每个目标语音进行少量的自适应数据调整。
本文从两个方面综述了自适应语篇模型的研究进展:1)一般适应设置,其中包括改进源语篇模型在支持新说话人方面的泛化,以及对不同领域的适应;2)高效的适应设置,其中我们回顾了减少每个目标说话人的适应数据和适应参数的工作。我们总结了表16中两种方向的工作,并将这些工作介绍如下:

3.6.1 一般适应
源模型泛化
这类工作的目的是提高源TTS模型的可生成性。在源模型训练中,源文本没有包含足够的声学信息,如韵律、说话人音色、录音环境等来生成目标语音。因此,TTS模型对训练数据容易过拟合,对新说话人的适应泛化能力较差。Chen等人(《Adaspeech: Adaptive text to speech for custom voice》)提出声学条件建模,提供必要的声学信息作为模型输入,学习文本-语音映射,更好地泛化,而不是记忆。提高源TTS模型可生成性的另一种方法是增加训练数据的数量和多样性。Cooper等人在训练源TTS模型时,利用(《Can speaker augmentation improve multi-speaker end-to-end tts?》)的speaker augmented来增加说话人的数量,在适应中可以很好地推广到未出现过的说话人。
跨域的适应
在自适应TTS中,一个重要的因素是适应语音与用于训练源TTS模型的语音数据具有不同的声学条件或风格。在这种情况下,需要考虑特殊的设计来提高源TTS模型的泛化程度,并支持目标说话人的风格。AdaSpeech设计了声学条件建模,以更好地模拟录音设备、环境噪声、口音、扬声器速率、扬声器音色等声学条件。这样,该模型更倾向于泛化而不是记忆声学条件,能够很好地适应不同声学条件下的语音数据。AdaSpeech 3通过设计特定的填充停顿适应、节奏适应和音质适应,将阅读风格的TTS模型调整为自发风格。其他一些作品考虑了不同说话风格的改编,如Lombard或whisper。一些作品(《Learning to speak fluently in a foreign language: Multilingual speech synthesis and cross-language voice cloning》,《Cross-lingual, multi-speaker text-to-speech synthesis using neural speaker embedding》,《Cross-lingual multi-speaker text-to-speech synthesis for voice cloning without using parallel corpus for unseen speakers》,《Towards natural bilingual and code-switched speech synthesis based on mix of monolingual recordings and cross-lingual voice conversion》,《Speaker adaptation of a multilingual acoustic model for cross-language synthesis》,《Phonological features for 0-shot multilingual speech synthesis》,《Generating multilingual voices using speaker space translation based on bilingual speaker data》,《End-toend code-switching tts with cross-lingual language model》,《Using ipa-based tacotron for data efficient cross-lingual speaker adaptation and pronunciation enhancement》)提出跨语言转换声音,例如,在英语讲话者没有任何普通话语音数据的情况下,使用英语讲话者合成普通话语音。
3.6.2 高效适应
大致来说,适配数据越多,语音质量越好,但采集数据的成本也就越高。对于自适应参数,整个TTS模型(《Sample efficient adaptive text-to-speech》,《High quality, lightweight and adaptable tts using lpcnet》),或部分模型(如解码器)(《Boffin tts: Few-shot speaker adaptation by bayesian optimization》,《Adadurian: Few-shot adaptation for neural text-to-speech with durian》),或仅扬声器嵌入(《Neural voice cloning with a few samples》,《Sample efficient adaptive text-to-speech》,《Adaspeech: Adaptive text to speech for custom voice》)可以进行微调。类似地,对更多参数进行微调将获得良好的语音质量,但会增加内存和部署成本。在实践中,我们的目标是适应尽可能少的数据和参数,同时实现高适应的语音质量。
我们将这类工作分为以下几个方面:1)少量数据适应;2)少量参数适应;3)非转录数据适应;4) zero-shot适应。我们将这些工作介绍如下:
少量数据适应。一些作品进行了开展few-shot适应,只使用少数成对的文本和语音数据,从几分钟到几秒不等。Chien等人探索了不同的说话人嵌入以适应少量镜头。Yue等人(《Exploring machine speech chain for domain adaptation and few-shot speaker adaptation》)利用语音链进行少镜头适应。Chen等人, Arık等人对不同适配量的语音质量进行了比较,发现数据量小(小于20句)时,随着适配量的增加,语音质量提高很快,而当适配量达到几十句时,语音质量提高缓慢。
少量参数适应。为了支持许多用户/客户,适应参数需要足够小,以满足每个目标扬声器,以减少内存使用,同时保持高质量的语音。例如,如果每个用户/语音需要消耗100 MB的参数,那么对于1 M个用户来说,总内存存储为100PB,这是一个巨大的内存成本。一些研究提出在保持适应质量的同时,尽量减少适应参数。
AdaSpeech 在上下文参数生成的基础上提出了条件层归一化,从说话人嵌入中生成层归一化中的尺度和偏置参数,只微调与条件层归一化和说话人嵌入相关的参数即可获得良好的自适应质量。Moss等人提出了一种微调方法,为不同的说话人选择不同的模型超参数,实现了用少量语音样本合成特定说话人语音的目的,其中超参数的选择采用贝叶斯优化方法。
非转录数据适应。在许多情况下,只有语音数据可以很容易地收集,例如在转换或在线会议中,没有相应的文本。AdaSpeech 2利用未转录的语音数据进行语音适应,通过语音重建和潜在对齐(《Nautilus: a versatile voice cloning system》)。Inoue等人(《Semi-supervised speaker adaptation for end-to-end speech synthesis with pretrained models》)使用ASR模型转录语音数据,并使用转录的成对数据进行语音适配。
Zero-shot适应。一些作品进行了Zero-shot自适应,利用扬声器编码器提取给定参考音频的扬声器嵌入。这种方案很有吸引力,因为不需要适应数据和参数。但是,当目标说话人与源说话人有很大差异时,其适应质量还不够好。
4 资源
我们收集了TTS的一些资源,包括开源实现、TTS教程和要点、TTS挑战和TTS语料库,如表17所示。



5 未来方向
在本文中,我们对神经文本到语音进行了研究,主要关注:(1)神经文本到语音的基本模型,包括文本分析、声学模型、声码器和全端到端模型;(2)快速语音分析、低资源语音分析、鲁棒语音分析、表达型语音分析和自适应语音分析。作为一个快速总结,我们在表18中列出了代表性的TTS算法。由于页面限制,我们只回顾了TTS的核心算法;对于TTS相关的问题和应用,读者可以参考其他论文,如语音转换(《An overview of voice conversion and its challenges: From statistical modeling to deep learning》),唱歌语音合成(《Xiaoicesing: A high-quality and integrated singing voice synthesis system》,《Singing voice synthesis based on generative adversarial networks》,《Hifisinger: Towards high-fidelity neural singing voice synthesis》
),说话人脸合成(《What comprises a good talking-head video generation?: A survey and benchmark》)等。
根据神经TTS的最终目标,提出了今后神经TTS的研究方向,主要分为两类。
高质量的语音合成
TTS最重要的目标是合成高质量的语音。语音质量是由影响语音感知的许多方面决定的,包括可理解性、自然度、表现力、韵律、情感、风格、稳健性、可控性等。虽然神经方法显著提高了合成语音的质量,但仍有很大的空间进行进一步的改进。
(1)强大的生成模型。TTS是一个生成任务,包括波形和/或声学特征的生成,可以通过强大的生成模型更好地处理。虽然在声学模型、声码器和完全端到端模型中已经采用了基于VAE、GAN、流或扩散的高级生成模型,但为了进一步提高合成语音的质量,更强大、更高效的生成模型的研究正处于起步阶段。
(2)学习更好的特征。良好的文本和语音特征有利于神经TTS模型,提高合成语音的质量。一些对文本预处理的初步探索表明,更好的文本特征确实可以改善语音韵律。如何通过无监督/自我监督学习和预训练学习文本/音素序列,特别是语音序列的强大表示,具有挑战性,值得进一步探索。
(3)强大的语音合成。虽然目前的TTS模型消除了不正确的注意匹配导致的单词跳过和重复问题,但在遇到训练集未涵盖的关键情况时,如较长的文本长度、不同的文本域等,仍然存在鲁棒性问题。提高TTS模型在不同领域的通用性是实现鲁棒综合的关键。
(4)表达/控制/可转换的语音合成。TTS模型的表达性、可控性和可移植性依赖于更好的变异信息建模。现有的方法利用参考编码器或显式韵律特征(例如,音高、持续时间、能量)来进行变化建模,它在推理过程中具有良好的可控性和可移动性,但由于训练中使用的ground-truth 参考语音或韵律特征在推理中往往无法使用,导致训练/推理不匹配。高级的TTS模型隐式捕获变化信息,在合成语音中具有良好的表达性,但在控制和迁移方面表现不理想,因为从隐式空间采样不能明确、准确地控制和迁移每一个韵律特征(如音高、风格)。如何设计更好的表达/可控/可转移语音合成方法也是一个很有吸引力的问题。
(5)更像人类的语音合成。目前在TTS训练中使用的语音录音通常是正式的阅读风格,没有停顿、重复、变化的速度、不同的情绪和错误是允许的。然而,在日常交谈中,人们很少像标准阅读那样说话。因此,更好地塑造随意、情感和自发的风格是提高合成语音的自然度的关键。
高效的语音合成
一旦我们能够合成出高质量的语音,接下来最重要的任务就是高效合成,即如何降低语音合成的成本,包括收集和标记训练数据、训练和服务TTS模型等成本。
(1)高效的TTS数据。许多低资源语言缺乏训练数据。如何利用无监督/半监督学习和跨语言迁移学习来帮助低资源语言是一个有趣的方向。例如,零语音挑战是一个很好的倡议,它探索了只从语音中学习,而不涉及任何文本或语言知识的技术。另外,在语音适配中,目标说话人的适配数据很少,这也是数据高效的TTS的另一个应用场景。
(2)高效的TTS参数。目前的神经TTS系统通常使用具有数千万参数的大型神经网络来合成高质量的语音,但由于其内存和功耗有限,阻碍了移动、物联网和其他低端设备的应用。设计具有更少内存占用、功耗和延迟的紧凑和轻量级模型对于这些应用场景至关重要。
(3)节能的TTS。培训和服务一个高质量的TTS模式消耗了大量的能量,排放了大量的碳。提高能源效率,例如减少TTS训练和推断中的失败,对于让更多的人受益于先进的TTS技术,同时减少碳排放,保护我们的环境是非常重要的。