正则表达式-01-入门
目录
前言
1.1匹配
1.2查找替换
1.3python正则表达式
1.3.1re.函数
1.3.2对象
1.4示例
1.4.1转换数字
1.4.3匹配邮箱
1.4.4匹配超链接
1.4.5匹配重复单词
前言
通俗的讲正则表达式,其作用可以理解成查找替换,我们编辑文本的时候,经常用到的一个快捷键就是ctrl+f,这就是正则匹配,不过匹配的只是普通字符。正则表达式只是一套规则,需要语言来实现它,所以我们先学一下perl的基础。
就像学一门语言最快的方法不是拿一个大厚本去读,而是边写边查,循序渐进,虽然做不到像前者面面俱到。但是很多人包括我,一开始也抵触这种做法,想要追求系统化的学习,这其实是学生时代的陋习,相信各位都有完整的学完一门语言,编程语言不像是物理数学,每一章都是割裂的,因此不按顺序学完全是聪明人的做法。
首先创建一个文件hello.pl 内容如下,语法类似shell编程
#!/usr/bin/perl
$s="Hello, world\n";
print $s;如果是在windows下创建的文件,文档格式记得转为Unix
赋权后执行,结果如下

接下来我们就可以写我们的正则表达式
1.1匹配
正则表达式本身,由元字符和普通字符组成,元字符类比我们上面的hello.pl里面的$ = ;等特殊符号,下面给出一个简单的表格,当遇到不认识的元字符,就可以翻到这里来查阅
| 符号 | 描述 | 示例 |
| ^ | 一行开始 | |
| $ | 一行结束 | |
| [] | 字符组 | |
| | | 选择 | [0|1|2|3|4|5|6|7|8|9] 匹配一个数字 |
| - | 范围 | [0-9] 匹配一个数字 |
| [^] | 排除 | |
| . | 任意一个字符,不能为空 | |
| i | 忽略大小写(不能称之为元字符,但是放在这里) | |
| \< | 单词开始 | |
| \> | 单词结束 | |
| + | 出现1次或多次 | |
| * | 出现0次或多次 | |
| ? | 出现0次或1次 | |
| \ | 转义 | |
| () | 反向引用 |
首先我们输入123,在代码中打印出结果
#!/usr/bin/perl
$input=;
chomp($input);
if($input eq "123"){
print("匹配成功");
} 
其中
chomp($input)去掉换行符、
换成正则表达式的写法
eq 判断字符串是否相等
#!/usr/bin/perl
$input=;
chomp($input);
if($input=~ m/123/){
print("匹配成功");
} 
这里出现了三个新东西
=~ 表示匹配 !~表示不匹配
m 匹配
// 正则表达式的界定符,也就是//里面的内容就是正则表达式
那么如果我要匹配一个数字,可以这么写
#!/usr/bin/perl
$input=;
chomp($input);
if($input=~ m/[0123456789]/){
print("匹配成功");
} []表示分组,[012]匹配0 或者1 或者 2,因此上面的代码只能匹配一个数字,若有多个数字,就可以才用我们的+,表示匹配一次或多次
#!/usr/bin/perl
$input=;
chomp($input);
if($input=~ m/[0123456789]+/){
print("匹配成功");
} 现在我输入456仍然是成功的
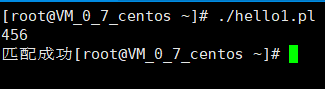
上面的写法太繁琐,优化一下
#!/usr/bin/perl
$input=;
chomp($input);
if($input=~ m/[0-9]+/){
print("匹配成功");
} -表示范围,现在随便输入数字,结果如下

现在我们测试一下,假如除了数字还有别的字母
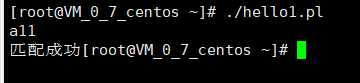
可以看到仍旧匹配成功了,我们需要使用$和^来匹配行首和行尾
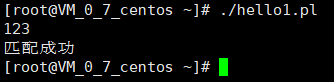
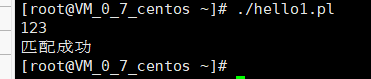
#!/usr/bin/perl
$input=;
chomp($input);
if($input=~ m/^[0-9]+$/){
print("匹配成功\n");
}else{
print("匹配失败\n")} 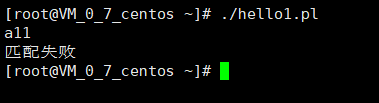
我们加上负号和小数点试试
#!/usr/bin/perl
$input=;
chomp($input);
if($input=~ m/^-?[0-9]+(\.[0-9]+)?+$/){
print("匹配成功\n");
}else{
print("匹配失败\n")} 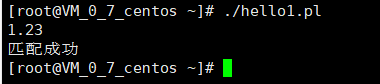
现在可以在上面的基础上使用反向引用了,表达式
^-?[0-9]+(\.[0-9]+)?+$括号里的内容是(\.[0-9]+)表示小数部分
构造一个字符串0.123123
#!/usr/bin/perl
$input=;
chomp($input);
if($input=~ m/^-?[0-9]+\.([0-9]{3})?\1+$/){
print("匹配成功\n");
}else{
print("匹配失败\n")} \1表示引用前面的数字
现在我们输出重复的数字
#!/usr/bin/perl
$input=;
chomp($input);
if($input=~ m/^-?[0-9]+\.([0-9]{3})?\1+$/){
print("匹配成功\n");
print("重复的数字是$1")
}else{
print("匹配失败\n")} 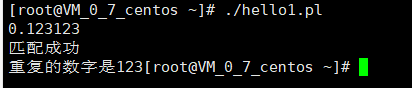
但是用[0-9]代表一个数字有点长了,我们可以使用\d
其它特殊字符如下
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
1.2查找替换
现在有一个需求,为小数保留两位有效数字,比如1.234=1.23,1.256=1.26,1=1.00,1.2=1.20
执行的时候出了问题:
-bash: ./r.pl: /usr/bin/perl^M: bad interpreter: No such file or directory
原来是忘记修改文档类型为Unix
#!/usr/bin/perl
$input=;
chomp($input);
$input=~ s/(\.\d{2})\d*/$1/;
print("$input\n") 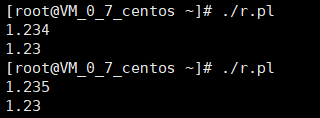
解释一下上述代码
$input=~ s/(\.\d{2})\d*/$1/;
=~表示符合的情况
s表示替换
紧接着有三个///,/A/B/表示把A替换成B
A:(\.\d{2})\d*
B:$1
接着看A,\.是小数点,单独的.表示任意字符,因此要表示小数点必须用转义
\d表示数字,{2}表示数字出现两次,括号内容是(\.\d{2}),也就是匹配前两位小数
而B中的$1表示反向引用前面的数字,也就是两位有效数字,当然$1也可以换成\1,只不过$1也作为变量,可以直接打印
最后整体看过来,就是截取两位有效数字,而不是四舍五入。如何做到四舍五入呢,这个我们学到后面再回过头解决这个问题。
1.3python正则表达式
python与perl没有什么本质上的区别,我们需要新学习的内容主要是两类,五个方法
python元字符我也记不住,比如\b代表单词分隔符,\s代表空白字符,\w代表所有字符,只能要搜索什么去查找。
两类是re.函数和re对象,五个方法是match search findall finditer sub
1.3.1re.函数
- match:从字符串开头进行匹配,匹配成功后停止往下查找,返回Match对象
- search:匹配整个字符串,匹配成功后停止往下查找,返回Match对象
- findall:匹配整个字符串,匹配成功后继续往下查找,返回列表
- finditer:匹配整个字符串,匹配成功后继续往下查找,返回迭代器
有一个字符串"how are you",我们需要匹配出三个单词,how are you
我们可以这样写
import re
s="how are you"
s=re.match(r"\b\w+\b",s)
print(s)

结果是一个Match对象,我们可以用他提供的group和groups方法
import re
s="how are you"
s=re.match(r"\b\w+\b",s)
print(s.group())

但是只获取了how,后面are和you未能匹配出来,因为match方法只会匹配一次,匹配how成功后不会往下找。
如果我把how前面加两个汉字,同时修改正则表达式
import re
s="我说 how are you"
s=re.match(r"\b[a-z]+\b",s)
print(s.groups())
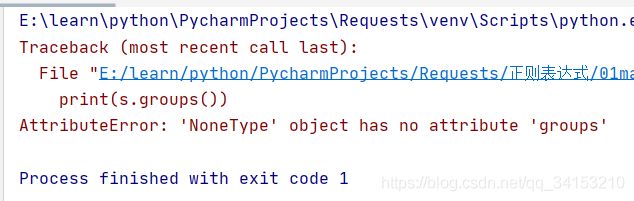
直接报错了,因为字符串开头不是字母,所有我们使用search方法,不从字符串开头进行匹配
import re
s="我说 how are you"
s=re.search(r"\b[a-z]+\b",s)
print(s.group())
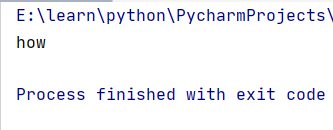
但是还是没能解决我们的问题,这时我们需要使用findall方法
import re
s="我说 how are you"
s=re.findall(r"\b[a-z]+\b",s)
print(s)

以及finditer
import re
s="我说 how are you"
s=re.finditer(r"\b[a-z]+\b",s)
for i in s:
print(i.group())

但我仍然想使用search方法
import re
s="我说 how are you"
s=re.search(r"\s([a-z]+)\s([a-z]+)\s([a-z]+)",s)
print(s.groups())

这里的括号作用就是反向引用,类似perl的$1 $2,在这里就是group(1),group(2),同样?:也是适用
1.3.2对象
我们以上面的findall举例
import re
s="how are you"
m=re.compile("[a-z]+")
s=m.findall(s)
print(s)

1.4示例
我们用perl掌握了了正则表达式的基本写法,为了方便,我们转为python语言描述,来实现正则匹配和替换。下面给出几个示例,在编写过程中掌握更多的正则表达式用法
1.4.1转换数字
现在有一个需求,一个字符串
"我有1234556块钱"如何把里面的金额加上千分位符号,变成
"我有1,234,556块钱"在处理这个问题前,我们先接触一个“环视”的概念,也有一说“零宽断言”
环视,就是找一个位置,比如排队,有一个队
伍,ABDEF,都排好了,我作为C,只需要记住我前面是B,后面是D,也就是说,我只需要关注我在B的后面,或者D的前面就行。
我们可以用我们之前学的知识,将B改成BC,或者将D改成CD
import re
s="ABDEF"
s=re.sub(r'B','BC',s)
print(s)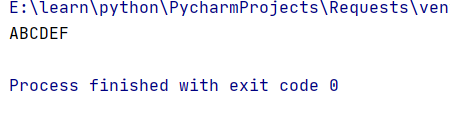
上面代码的第三行的re.sub就是perl的替换功能,三个参数
r'B':r后跟的引号内的字符串就是正则表达式
'BC':类比replace函数,替换成BC
s:待替换的字符串
返回值是替换结果
如果用环视的方法去写,可以这样
import re
s="ABDEF"
s=re.sub(r'(?<=B)','C',s)
print(s)
其中(?<=)五个字符是一个整体,代表逆向环视,(?<=B)对应的是B右边的位置
同样我们可以找D左边的位置
import re
s="ABDEF"
s=re.sub(r'(?=D)','C',s)
print(s)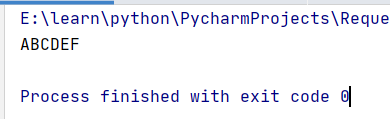
回到我们上面的问题,则可以这样写
import re
s="我有1234556块钱"#1,234,556
s=re.sub(r"(?=\d{3})",",",s)
print(s)?=表示左边位置,\d{3}表示连续的三个数字,所以(?=\d{3})代表是三个数字左边的位置,re.sub(r"(?=\d{3})",",",s)表示在该位置添上逗号(如果忘记了?=到底是左边还是右边,可以测试一下我上面的ABDEF排队的写法,所以不用记忆)
而结果如下

这是因为字符串1234556从右往左看将会是556是三个数字,455也是三个数字,345也是三个数字。
好像我们要做的就是只匹配一次正则表达式,得到1234,556,且将结果进行匹配而不是原字符串1234556,得到1,234,556.
我们可以改成这样
import re
s="我有1234556块钱"#1,234,556
s=re.sub(r"(?=(\d{3})+[^0-9])",",",s)
print(s)
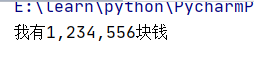
但是如果是9个数字呢
import re
s="我有123456789块钱"#1,234,556
s=re.sub(r"(?=(\d{3})+[^0-9])",",",s)
print(s)

所以前面也要加上非数字限制
import re
s="我有123456789块钱"#1,234,556
s=re.sub(r"(?<=[0-9])(?=(\d{3})+[^0-9])",",",s)
print(s)

(?<=[0-9])表示逗号必须加在数字右边
(?=(\d{3})+[^0-9])表示匹配的数字最右边是非数字
那如果字符串不满足这些条件呢,比如"123456789",读者自己思考一下,能不能给出更优的写法
import re
s="123456789"
s=re.sub(r"(?<=\d)(?=(\d{3})+($|[^0-9]))",",",s)
print(s)import re
s="123456789"
s=re.sub(r"(?<=\d)(?=(\d{3})+(?!\d))",",",s)
print(s)1.4.2修改cookies
import re
cookies='''Bdpagetype: 2
Bdqid: 0x8ccffb2200010cd0
Cache-Control: private
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
Date: Wed, 09 Sep 2020 04:59:06 GMT
Expires: Wed, 09 Sep 2020 04:59:06 GMT
Server: BWS/1.1
Set-Cookie: BDSVRTM=215; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=7541_32606_1420_7566_31253_32115_31709_26350; path=/; domain=.baidu.com
Strict-Transport-Security: max-age=172800
Traceid: 1599627546023792487410146604608936545488
Transfer-Encoding: chunked
X-Ua-Compatible: IE=Edge,chrome=1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: max-age=0
Connection: keep-alive
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36'''
cookies=re.sub(r"(.*):(?:\s(.*))",'"\\1":"\\2"',cookies)
print(cookies)
1.4.3匹配邮箱
import re
s='''联系BOSS直聘
北京华品博睿网络技术有限公司
公司地址 北京市朝阳区太阳宫中路8号冠捷大厦302
联系电话 010-84150633
举报邮箱 [email protected]
'''
result=re.findall(r"\w[-\.\w]*\@\w[\.\w]*\.\w*",s)
print(result)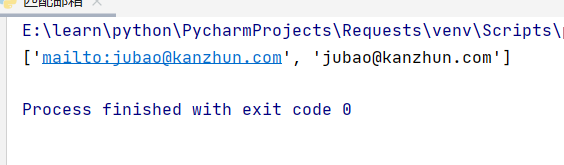
1.4.4匹配超链接
import re
s='''
「Linux Kernel Engineer招聘」_vivo招聘-BOSS直聘
'''
result=re.findall(r'https?://[//~\.\w]*(?
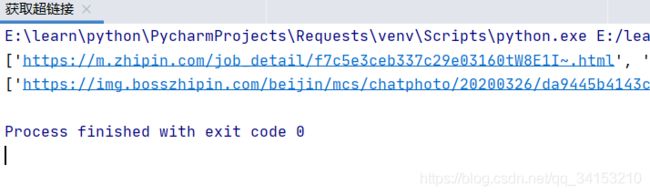
1.4.5匹配重复单词
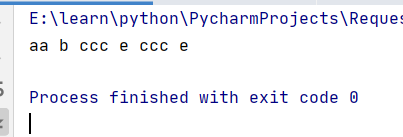
import re
s="aa b b ccc e ccc e e "
s=re.sub(r"\b(\w+)\s\1",'\\1',s)
print(s)