精通Python——正则表达式
1 正则表达式
1.1 常见正则表达式符号和特殊字符
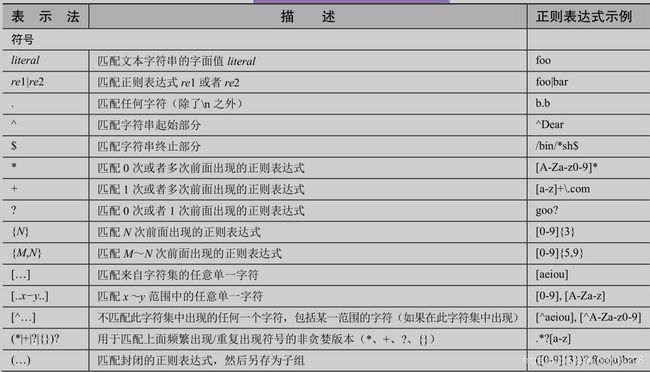
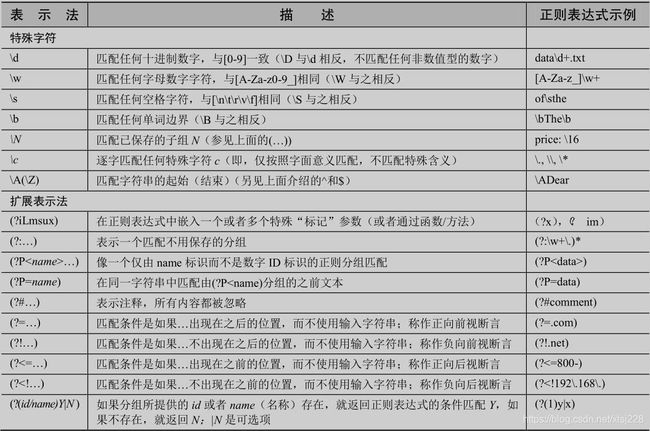
1.2 举例分析
1)择一匹配符号

2)匹配任意单个字符

3)从字符串起始或者结尾或者单词边界匹配

特殊字符\b 和\B 可以用来匹配字符边界。\b 将用于匹配一个单词的边界, \B 将匹配出现在一个单词中间的模式。

4) 创建字符集

5)限定范围和否定

6)使用闭包操作符实现存在性和频数匹配
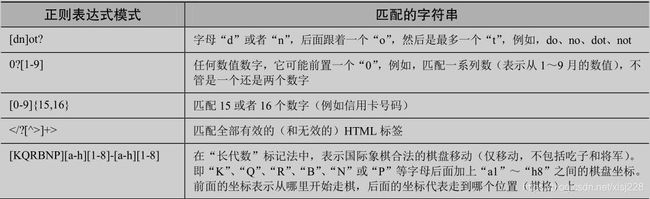
7)表示字符集的特殊字符

8)使用圆括号指定分组

9)扩展表示法

2 RE模块
2.1 re 模块:核心函数和方法:
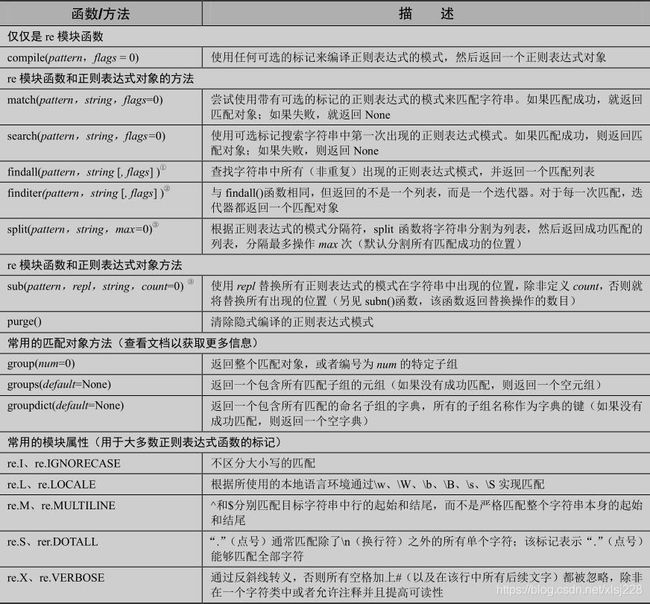
2.2 应用
1)假设网页上有几个商品图片——它们的源代码形式如下:
如果我们想抓取所有图片的 URL 链接,非常直接的做法就是用 findAll("img") 抓取所有图片,但是网站里都有一些隐藏图片,用于网页布局留白和元素对齐的空白图片,以及一些不容易察觉到的图片标签,都会被一起下载下来。
我们使用正则表达式——源码如下:
images = bsObj.findAll("img",{"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")})
这会匹配以下的图片形式:
../img/gifts/img1.jpg
../img/gifts/img2.jpg
2)在网络数据采集时你经常不需要查找标签的内容,而是需要查找标签属性。比如标签 指向的 URL 链接包含在 href 属性中。对于一个标签对象,可以用下面的代码获取它的全部属性:myTag.attrs
我们可以使用Lambda表达式:
Lambda 表达式本质上就是一个函数,可以作为其他函数的变量使用。一个函数不是定义成 f(x, y) ,而是定义成 f(g(x), y) ,或 f(g(x), h(x)) 的形式。BeautifulSoup 允许我们把特定函数类型当作 findAll 函数的参数。唯一的限制条件是这些函数必须把一个标签作为参数且返回结果是布尔类型。
下面的代码就是获取有两个属性的标签:
soup.findAll(lambda tag: len(tag.attrs) == 2)