opencv-python3 | cv2.findContours()检测图像中物体轮廓
cv2.findContours检测物体轮廓
- 什么是物体轮廓
- cv2.findContours
- cv2.drawContours
- 代码示例
什么是物体轮廓
轮廓可以简单地理解为连接所有连续点(沿物体边界)的曲线,这些点通常具有相同的颜色或强度。 轮廓在图像分析中具有重要意义,是物体形状分析和对象检测和识别的有用工具,是理解图像语义信息的重要依据。
cv2.findContours
通常,为了提高物体轮廓检测的准确率,首先要将彩色图像或者灰度图像处理成二值图像(黑白图像)或者使用Canny边缘检测算法对原图像进行一次滤波处理,这样可以在不丢失轮廓信息的前提下降低图像语义信息的复杂度,更有助于我们准确地分析物体轮廓。因此,在opencv里边,寻找轮廓的过程更像是在黑色背景中寻找白色物体。
下边是一段使用opencv-python里的cv2.findConttours()检测物体轮廓的代码。
import numpy as np
import cv2
im = cv2.imread('test.jpg')
imgray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(imgray, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
从上边的代码中,我们可以看到cv2.findContours()有三个参数:thresh、cv2.RETR_TREE、cv2.CHAIN_APPROX_SIMPLE。
参数说明:
- thresh:图像数据(二值图像或经过Canny算法处理之后的图像)
- cv2.RETR_TREE:轮廓检索方式,还有cv2.RETR_LIST、cv2.RETR_EXTERNAL、cv2.RETR_CCOMP
- cv2.CHAIN_APPROX_SIMPLE:轮廓的估计方法,除此之外还有 cv2.CHAIN_APPROX_NONE
第二个参数指定的不同轮廓检索方法有什么区别呢?
| 轮廓检索方法 | 作用 |
|---|---|
| cv2.RETR_LIST | 这是最简单的一种寻找方式,它不建立轮廓间的子属关系,也就是所有轮廓都属于同一层级 |
| cv2.RETR_TREE | 完整建立轮廓的层级从属关系 |
| cv2.RETR_EXTERNAL | 只寻找最高层级的轮廓 |
| cv2.RETR_CCOMP | 把所有的轮廓只分为2个层级,不是外层的就是里层的 |
详情请参考 cv2.findContours()的轮廓层级关系.
前边说了物体轮廓是具有相同灰度值的形状的边界。它是以形状边界上的点的坐标(x,y)储存的,但是cnts里边是储存了边界上所有点的坐标吗?还是只储存了个别点的坐标?这是由第三个参数轮廓的估计方法指定的。如果传递 cv2.CHAIN_APPROX_NONE,则存储所有边界点。 但实际上我们需要所有的点吗? 例如,您找到了一条直线的轮廓。 你需要线上的所有点来代表那条线吗? 不,我们只需要那条线的两个端点。 这就是 cv.CHAIN_APPROX_SIMPLE 所做的。 它去除所有冗余点并压缩轮廓,从而节省内存。如图1所示。

图1. 不同轮廓估计方法的效果图
cv2.findContours()返回了两个变量:contours, hierarchy。
输出变量说明:
- contours:一个包含了图像中所有轮廓的list对象。其中每一个独立的轮廓信息以边界点坐标(x,y)的形式储存在numpy数组中。
- hierarchy:一个包含4个值的数组:[Next, Previous, First Child, Parent]。
Next:与当前轮廓处于同一层级的下一条轮廓
Previous:与当前轮廓处于同一层级的上一条轮廓
First Child:当前轮廓的第一条子轮廓
Parent:当前轮廓的父轮廓
因为一般不使用hierarchy,所以这里不讨论轮廓的层级关系,想深入研究的朋友请移步:cv2.findContours()的轮廓层级关系.
cv2.drawContours
计算得到图像中物体轮廓之后,我们需要将轮廓在图像中绘制出来才能更直观地体验到。这时候需要用到cv2.drawContours()方法。它的第一个参数是图像,第二个参数是储存轮廓信息的python 列表,第三个参数是轮廓的索引(在绘制单个轮廓时很有用。要绘制所有轮廓,传递 -1),其余参数是颜色、厚度 等等。
绘制检索到的所有轮廓
cv.drawContours(img, contours, -1, (0,255,0), 3)
绘制检索到的所有轮廓中的第四个
cv.drawContours(img, contours, 3, (0,255,0), 3)
但是更多时候我们使用下边这种方法绘制单独的某一个轮廓。
第二种方法绘制检索到的所有轮廓中的第四个
cnt = contours[4]
cv.drawContours(img, [cnt], 0, (0,255,0), 3)
代码示例
import cv2
import imutils
import numpy as np
# 读取图片
img_dir = r'C:\Users\Lei\Desktop\8.jpg'
img = cv2.imread(img_dir)
# 图像预处理
img = imutils.resize(img, height=500)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
binary = cv2.Canny(gray, 30, 120)
# 轮廓检索
contours, hierarchy = cv2.findContours(binary,
cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cv2.imshow('origin', img)
if cv2.waitKey(0) & 0xFF == ord('q'):
cv2.destroyWindow('origin')
cv2.imshow('binary', binary)
if cv2.waitKey(0) & 0xFF == ord('q'):
cv2.destroyWindow('binary')
# 轮廓过滤以及绘制
draw_img = img.copy()
for i in range(len(contours)):
# 筛掉面积过小的轮廓
area = cv2.contourArea(contours[i])
if area < 800:
continue
# 找到包含轮廓的最小矩形框
rect = cv2.minAreaRect(contours[i])
# 计算矩形框的四个顶点坐标
box = cv2.boxPoints(rect)
box = np.int0(box)
# 绘制轮廓
cv2.drawContours(draw_img, [box], 0, (0, 0, 255), 5)
cv2.imshow('origin with contours', draw_img)
if cv2.waitKey(0) & 0xFF == ord('q'):
cv2.destroyWindow('origin with contours')
代码中首先对读取的RGB图像(图2)转灰度图,然后进行高斯滤波去噪,再使用Canny算子进行边缘检测得到黑白图像(图3)。对黑白图像进行轮廓检索,检索到的轮廓再根据cv2.contourArea()计算得到的面积大小进行一次筛选,去掉因噪声引起的检测。根据检测到的轮廓信息,使用cv2.minAreaRect()得到包含轮廓信息的最小矩形框rect,再使用cv2.boxPoints()计算出rect的四个顶点。最后,使用cv2.drawContours()绘制出rect(图4)。

图2. RGB原图像

图3. Canny算子得到的黑白图像
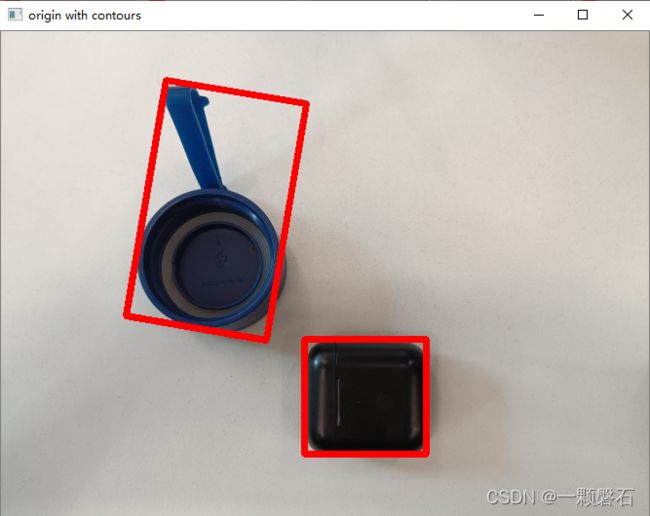
图4. 使用矩形框显示轮廓检测结果