分类器评估:混淆矩阵和ROC曲线
前言
本文是自己在学习机器学习当中遇到的一些问题,为了便于自己学习和记忆进行总结,写的有不正确的地方欢迎大家指正。
在此附上大佬的个人博客链接:链接,主要是学习此博客中的一些理解,感谢大佬的帮助。
混淆矩阵
| 预测为正样本: +1 | 预测为负样本 : -1 | |
|---|---|---|
| 原正样本: +1 | 真阳 (TP) | 假阴(FN) |
| 原负样本 : -1 | 假阳(FP) | 真阴(TN) |
这里以二分类问题来讨论:
- 如果对一个正例正确地判为正例,那么就可以认为产生了一个真正例(True Positive,TP,也称真阳);
- 如果对一个反例正确地判为反例,则认为产生了一个真反例(True Negative,TN,也称真阴);
- 如果对一个正例错误地判为反例,那么就可以认为产生了一个伪反例(False Negative,FN,为称假阴);
- 如果对一个反例错误地判为正例,则认为产生了一个伪正例(False Positive,FP,也称假阳);
很明显,理想完美的分类器的对角线为0,即所有正样本预测为正样本,所有负样本预测为负样本。
由混淆矩阵可以得出的一些参数:
(1)Accuracy:模型的精度,模型预测正确个数/样本的总个数;

(2)Positive predictive value(PPV,Precision):正确率,阳性预测值,在模型预测为正类的样本中,真正的正样本所占的比例;

(3)False discovery rate(FDR):伪发现率,也是错误发现率,表示在模型预测为正类的样本中,真正的负类的样本所占的比例;
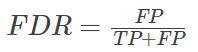
(4)False omission rate(FOR):错误遗漏率,表示在模型预测为负类的样本中,真正的正类所占的比例。即评价模型"遗漏"掉的正类的多少。
![]()
(5)Negative predictive value(NPV):阴性预测值,在模型预测为负类的样本中,真正为负类的样本所占的比例。

(6)True positive rate(TPR,Recall):召回率,真正类率,表示的是,模型预测为正类的样本的数量,占总的正类样本数量的比值。

(7)False positive rate(FPR),Fall-out:假正率,表示的是模型预测为正类的样本中,占模型负类样本数量的比值。

(8)False negative rate(FNR),Miss rate:假负类率,缺失率,模型预测为负类的样本中,是正类的数量,占真实正类样本的比值。

以上这么多参数的值,越大越好,有的则越小越好,不再一一讨论~
ROC曲线
ROC全称:代表接收者操作特征(receiver operating characteristic)。ROC曲线是一种可以直观观察分类器分类效果的图线。
首先说明一下,ROC的横坐标为假阳率即(FP/(FP+TN)) ;纵坐标为真阳率即(TP/(TP+FN));ROC曲线越靠近左上角,分类器的分类效果越好。
接下来,就如何绘制出ROC曲线,通俗的表达一下我的理解:
首先,我们知道分类器分类出来的结果是0~1的小数值,我们可以认为是大于等于0.5(阈值)的为正样本,其余为负样本。举个栗子,如果测试数据集标签为[-1,+1,+1,-1,+1],而我们分类器得到标签为[0.2, 0.8, 0.7, 0.1, 0.9];这说明我们分类器准确率为100%,这是最好的情况!
绘制ROC曲线采用的是阈值是动态变化的,将预测出的标签值按从大到小排序,然后依次取值作为阈值。
假如 测试集标签不变,我们预测的结果为:[0.2, 0.4, 0.7, 0.6, 0.9] 有两个是错误的。我们对其从大到小排序并返回索引值为[4,2,3,1,0]
接下来我们开始一步步绘制:规定X轴的移动步长为(1/FP+TN),其实就是真实数据集标签中,负样本的个数;Y轴的移动步长为(1/TP+FN),其实就是真实数据集标签中,正样本的个数。
具体操作如下:
- 首先取第一个索引值4,它对应的预测值为0.9,把它当做阈值,>=0.9的才被看做正样本,所以只有一个正样本,我们再判断真实数据集标签中,所对饮的标签为+1 所以这是一个TP 真正样本,我们需要向上移动Y轴坐标。
- 取第二个索引值2,它对应的预测值为0.4,把它当做阈值,>=0.4的才被看做正样本,所以产生了两个正样本,对应4,2两个索引值到真实数据集标签,判断为这是2个TP,相对第一步,增加一个TP,再次向上移动一次Y州
- 第三个索引值3,去0.6为阈值,这次得到三个正样本中,但是其实3这个索引对应的真实数据集标签为负样本,所以,这是一个FP,假正样本,此时需要X轴移动一步。
- … …
- 一直到最后一个索引,此时所有的样本都被认为正样本,但是其中有两个 假正样本,此时,Y轴移动到了 1/3 *3 =1, X 轴移动到了1/2 *2 =1
大致过程就是这样,可以看到 核心思想就是!!! 每增加一个真正样本(TP)Y轴就会移动一步;每增加一个假正样本(NP)X轴就会移动一步。
所以我理解的就是,如果是一个准确率为100%的分类器,按照从大到小对预测值排序;这个ROC曲线就会先一直移动Y轴,直到移动到(0,1)坐标,其次开始移动X轴到(1,0)坐标,构成一个直角。
但事实往往是,在Y轴移动的过程中,挨个对排好序的索引值对应的真实数据集标签检查时,发现这个索引对应的值 不是正样本,所以就被迫改变绘制路径,水平移动一步!!!
所以如果移动的步长不算太小,可以看出ROC曲线是锯齿状的:

同样,涉及到的AUC(Area Unser the Curve)就是指的是曲线下方的面积,就是无数个小矩形的和。肯定是越大越好了~
以上所有内容,是我参考大佬的文章,以及自己的理解进行叙述,如果有什么地方不正确,请多多包容并欢迎指出,同时也感谢你能点进这篇博客。
2020/4/2 byGSQ