云智慧 AIOps 社区是由云智慧发起,针对运维业务场景,提供算法、算力、数据集整体的服务体系及智能运维业务场景的解决方案交流社区。该社区致力于传播 AIOps 技术,旨在与各行业客户、用户、研究者和开发者们共同解决智能运维行业技术难题,推动 AIOps 技术在企业中落地,建设健康共赢的AIOps 开发者生态。
前言
本篇我们主要从以下几个方面对多指标系统的异常检测方法进行了论述:第一部分从分布的角度定义了多指标系统的异常,并介绍了为什么单指标异常检测方法可能会在多指标系统中失效。第二部分从统计、机器学习两方面,梳理现有的部分多指标异常检测方法的思路。第三部分介绍了一种基于投影降维的多指标异常检测思路,并讨论了后续待解决的几个关键问题。
多指标异常定义
这里我们仅基于数据的统计学特征定义异常,不考虑数据异常是否是业务异常。设有 N 条长度为 T 的时间序列,记为

对时刻 t ,定义异常区域
![]()
![]()
若
![]()
则认为此多元时间序列在时刻 t 出现异常。相应的,正常域为异常区域的补集。
在此定义下,单点异常、上下文异常、集体异常 [[1]](https://yunzhihui.feishu.cn/d...) 可统一形式。单点异常可通过设定一个不随时间变化的异常域 A 定义,而上下文异常和集体异常所对应的异常域 A t [](https://yunzhihui.feishu.cn/d...)随时间动态变化。
下面两图是两指标系统的示例,正常区域为图中封闭图形,异常区域为图中封闭图形的外部。正常域随着时间在变化,可以刻画上下文异常、单点异常、集体异常。


多指标异常与单指标异常的关系
若各个指标之间是独立的,则此时多指标异常检测等价于 N 个单指标异常检测。由此可见,对多指标数据做异常检测重点在于如何刻画指标之间的相依结构。下面举两个单指标异常检测方法在多指标场景下失效的例子:
例1 设 X , Y 均为伯努利随机变量,它们的联合分布为
![]()

![]()
则 X , Y 分别定义了一个只有两个状态{0,1},转移概率均为0.5的随机游走过程。若某个时刻观察到( X , Y )=(0,0),边际来看,X , Y 依然是只有两个状态{0,1},转移概率均为0.5的随机游走,无法检测出异常。
以下两图是按上述模型生成的长度为100的序列,其中第50个点出现异常( X , Y )=(0,0)。
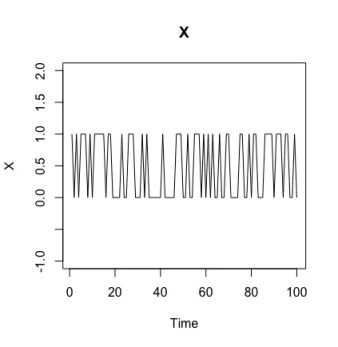
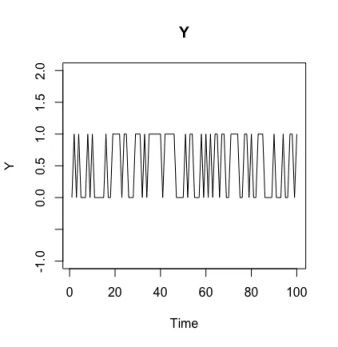
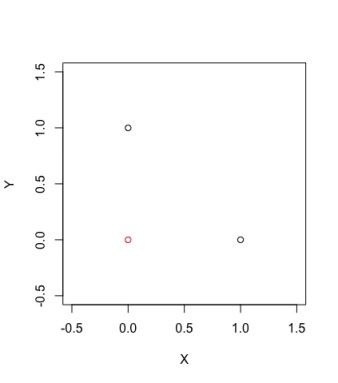
状态空间示例,红色点为异常
例2 设有随机序列
![]()
![]()
![]()
![]()
相互独立。观测序列
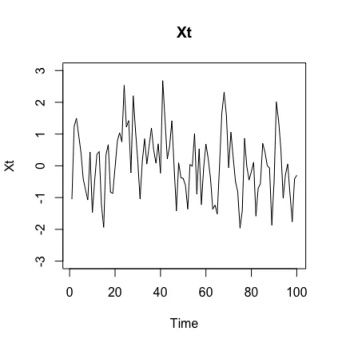
边际来看 X t , Y t 的分布不变,但 ( X t , Y t )的联合分布改变。
以下两图是按上述模型生成的长度为100的序列,其中第51个点是一个变点。

现有多指标异常检测统计方法总结
- 基于密度的方法
此类方法通常估计指标数据的密度分布,将密度值较小的区域划定为异常值。
Breunig et al (2000)[[29] ](https://yunzhihui.feishu.cn/d...)提出的经典算法LOF将数据点与其周围数据点的密度做比较,从而判断点远离正常区域的程度。
Tomá (2016) [[4]](https://yunzhihui.feishu.cn/d...)随机生成k-sparse的正态投影向量,将多元时序数据投影到一维,以直方图估计一维投影后的概率,异常得分由多次投影后得到的对数似然的平均值来构造。
Yamanishi et al (2000) [[5]](https://yunzhihui.feishu.cn/d...) 针对混合属性类型的数据(含类别变量和连续型变量),分别用直方图和高斯混合模型估计类别变量 X 和连续变量 Y 的密度,最后形成联合分布P( X , Y )=P( Y | X ) * P( X ),根据添加数据点后分布的变化程度计算异常得分。
Subramaniam et al (2006) [[6]](https://yunzhihui.feishu.cn/d...) 采用核密度估计密度,判断某个取值邻域内的密度,若小于阈值则认为是异常值。
Faulkner et al (2011) [[7]](https://yunzhihui.feishu.cn/d...)用核密度方法估计密度后不直接基于密度划定阈值,而是由指标的分位数判断异常,可控制数据中异常的比例。由于维数诅咒,密度估计在多元时通常效果较差,因此此类方法往往不适用于维数较大的数据
- 基于距离的方法
这里基于距离的方法也包括基于相似度(如各种kernel function)的方法。统计上来看,基于距离的方法和基于相似度的方法在假设检验问题上是等价的 [[8]](https://yunzhihui.feishu.cn/d...) 。此类方法计算各个时刻到近邻的距离,或相似度指标,进而判断是否异常。
Angiulli and Fassetti (2007) [[9] ](https://yunzhihui.feishu.cn/d...)计算点在窗口内的邻节点,若少于阈值则认为异常。类似的还有Pokrajac et al (2007) [[10]](https://yunzhihui.feishu.cn/d...)等。
Ro et al (2015) [[11]](https://yunzhihui.feishu.cn/d...)对Mahalanobis距离改进,将协方差矩阵换成协方差矩阵的对角阵,未考虑变量间的相关性。估计方差时随机抽取观测样本的子样本计算方差,选取方差乘积最小的估计作为最终估计从而过滤掉异常点的影响。
Cheng (2008) [[12]](https://yunzhihui.feishu.cn/d...) 将多元时间序列中的每条序列分别当作因变量(记为 Y ),将其他序列当成自变量(记为 X ),对 X 构造多元核矩阵 K X ,对 Y 构造多元核矩阵 K Y 。然后将 K Y 对 K X 的列空间投影,记为
![]()
将其归一化后作为马尔可夫链的转移矩阵,随机游走后统计各个时刻的访问次数,次数少的时刻认为异常。该方法对概念漂移问题效果较差。随机游走计算量较大,通常可以对状态转移矩阵转置后谱分解直接求解平稳分布。
下面两图是总长度为600的分段正弦曲线及基于10万次随机游走模拟的访问次数:
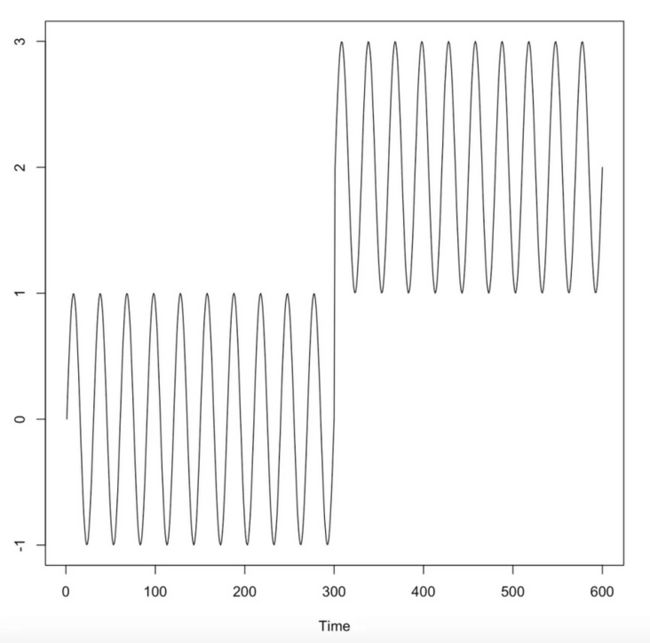

变点300的访问次数并不明显低于其他时刻,该方法失效。
Kriegel et al (2008)[ [13] ](https://yunzhihui.feishu.cn/d...)从几何角度,计算每个样本点关于任意一组点对的夹角,对夹角关于点对计算方差,作为angle-based outlier factor。离群点所对应的angle-based outlier factor应较小。

(Kriegel et al (2008)[ [13] ](https://yunzhihui.feishu.cn/d...)Figure 1)
此类方法依然受维数诅咒影响较大。下面两图是不同维数下由相关系数为0.3的AR(1)(一阶自回归)过程(变量之间相关系数为0.3,时间上独立)生成的长度为100的序列计算核函数后的直方图,核函数选尺度参数为1的高斯核。


从上面两图可以看出,维数为3时,核函数计算的各点之间的相似度还有一定的区分度。当维数提高到10时,所有点两两之间的相似度集中在0附近,核函数计算的相似度已经没有任何区分度。
- 基于预测的方法
该类方法对时间序列的趋势成分建模,预测下一期取值,由预测误差判断异常。
Park et al (2021)[ [14]](https://yunzhihui.feishu.cn/d...) 对多指标数据做函数型PCA,得到主成分,基于主成分预测下一时刻的取值,重构误差在误差分布的25%~75%范围内认为正常。
Singer et al (1996)[ [15]](https://yunzhihui.feishu.cn/d...)选取正常时刻的指标向量来表示正常点所组成的线性空间,对新的时序数据,给出其最优逼近,逼近误差为异常得分。该方法为有监督方法。
Jones et al (2014) [[16] ](https://yunzhihui.feishu.cn/d...)对多指标系统的每个维度寻找最相关的维度(以非线性重构误差来计,如多项式回归),以各个时间点的重构误差作为异常得分。
Lee and Roberts (2008) [[17]](https://yunzhihui.feishu.cn/d...)采用多元时序自回归预测,对预测值和观测值计算Mahalanobis距离。假设观测服从正态分布,则Mahalanobis距离服从|N(0,1)|分布,对其做极值分布,划定阈值。
Taylor and Letham (2017) [[33] ](https://yunzhihui.feishu.cn/d...)提出了一种同时拟合时间序列中的趋势性、周期性、假期效应的分段线性模型,通过将不同项作为协变量,求解法方程以同时估计各项参数。预测的误差可作为异常程度的度量。
- 基于投影的方法
该类方法将多指标数据投影到某个子空间以克服维数诅咒,在子空间上计算异常得分。
Inka (2017) [[18]](https://yunzhihui.feishu.cn/d...) 将多元时间序列做随机投影,估计一维投影的直方图从而估计当前点的概率。对一维投影下的对数似然求均值,取负作为异常得分。

Liu et al (2010) [[19] ](https://yunzhihui.feishu.cn/d...)对多指标在滑动窗口中应用PCA,第一主成分构成正常部分,最后一主成分构成异常部分。异常部分的范数定义了异常距离,如果距离高于阈值,则认为该点异常。
Huang and Kasiviswanathan (2015) [[20]](https://yunzhihui.feishu.cn/d...)定义一组左奇异向量以表征正常,若数据点在左奇异向量上投影残差大,则认为异常。
Kamalov et al (2020) [[21]](https://yunzhihui.feishu.cn/d...)对高维数据做PCA降维,降维后用KDE估计多元似然,似然小的点认为是异常。
现有多指标异常检测机器学习方法总结
- 基于分类的方法
该类方法将异常标签看作类别标签,将异常检测问题当作分类问题考虑,需要对数据预先标注。基于分类的多指标异常检测方法可基于正常类个数继续分为两类:Multi-class和One-class。

One-class异常检测技术假设所有训练实例只有一个类标签(正常/异常) 。这些技术使用单个类分类算法,如单类支持向量机[[22]](https://yunzhihui.feishu.cn/d...)、单分类Fisher判别分析[[23, 24]](https://yunzhihui.feishu.cn/d...) 来学习正常实例周围的判别边界。
Multi-class异常检测技术假设训练数据包含属于多个正常类的标记实例。这种异常检测技术使用一个分类器来区分每个正常类和其他类[ [25, 26]](https://yunzhihui.feishu.cn/d...),如上图所示。如果一个测试实例没有被任何一个分类器归类为正常,那么它就被认为是异常的。
- 基于树的方法
该类方法不同于决策树直接判断实例是否是异常,而是基于树结构计算实例的异常得分。
Tan et al (2011) [[27] ](https://yunzhihui.feishu.cn/d...)提出基于半空间树的异常检测,该方法使用滑动窗口基于属性对参数空间二分,计算每个子空间的质量(mass)。这些树由一组节点组成,其中每个节点捕获数据流特定子空间中的数据项数量或质量。窗口中落在参考窗低质量子空间中的数据点被认为是异常。
Guha et al (2016)[ [28]](https://yunzhihui.feishu.cn/d...)随机划分属性以建立随机分割树,稳健随机分割森林是独立稳健随机分割树的集合。当包含该点的联合分布与排除该点的分布显著不同时,该点被识别为异常。
Liu et al (2008) [[34]](https://yunzhihui.feishu.cn/d...)提出孤立森林算法,构造多棵决策树对样本点进行分类,以样本点的层级作为异常程度的判定标准。若某个样本点在森林中的平均层级较浅,即很容易被区分出来,则认为异常。
Staerman et al (2019)[ [30]](https://yunzhihui.feishu.cn/d...)改进了针对截面数据的孤立森林算法,使其可扩展到函数型数据。该方法通过分割函数空间的问题,逐步将这个轨迹从其他轨迹中分离出来。
- 基于聚类的方法
该类方法的基本假设是正常的数据实例在总体中聚合成簇,而异常点不属于任何类或者异常点聚成较小且稀疏的类。基于以上假设的方法将已知的基于聚类的算法应用于数据集,并将不属于任何类的数据实例声明为异常。如DBSCAN(Ester et al (1996) [[31]](https://yunzhihui.feishu.cn/d...))、ROCK(Guha et al (2000) [[32]](https://yunzhihui.feishu.cn/d...))等。
除了以上涉及的基于统计的和基于机器学习算法的异常检测方法,在深度学习领域也有很多针对多元时间序列的模型,如LSTM-AutoEncoder等。这些深度学习方法往往具有训练时间长、所需数据量大等缺陷,不适用于多指标时序数据的实时异常检测的场景,因此本文不再介绍。
基于随机投影的多指标异常检测
基本思路
概率论中有一条关于分布性质的经典定理
Cramér-Wold定理:
![]()
Cramér-Wold定理表明多元分布的性质由其所有的一维投影的性质共同刻画,因此我们可以考虑将多元时间序列 {Xit}i=1,...,N;t=1,...,T 投影到一维{α T X.t}t=1,...,T,α∈SN-1,对一维时间序列应用单指标异常检测方法。考虑到一维投影方向有无穷多个,实际应用中可生成有限次随机投影方向,对这有限次投影后的单指标异常检测结果进行综合,最终判断原有的多指标系统是否出现异常。
示例
下面基于第一节中提到的两个例子展示一下随机投影异常检测的效果。
对例1,X , Y 随时间不变的特征是 X + Y 。

从 X + Y 序列的图像中可以明显看出,第50个点处出现了一个单点异常。
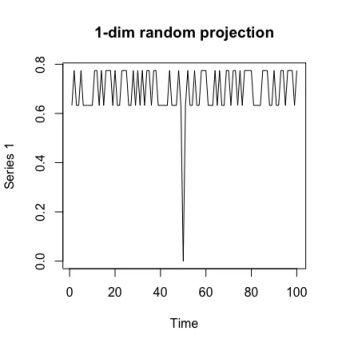
上图是一次随机投影的结果,从图中也可以明显看出,第50个点处出现了一个单点异常。
对例2,( X t , Y t ) 前半段的不变特征是 X t - Y t 。
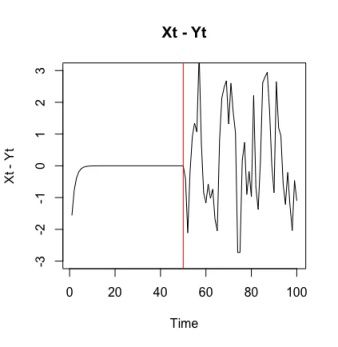
从 X t - Y t 序列的图像中可以明显看出,第50个点处出现了一个变点。该点前后序列趋势差别极大。

上图是一次随机投影的结果,从图中也可以明显看出,第50个点处出现了概念漂移,前后序列方差不同。
参考文献
[1] V. Chandola, A. Banerjee, and V. Kumar, Anomaly detection: A Survey, ACM Computing Surveys, vol. 41, no. 3, pp. 1-58, Jul. 2009.
[2] Cramér, H., & Wold, H. (1936). Some Theorems on Distribution Functions. Journal of the London Mathematical Society.
[3] Milana Gataric, Tengyao Wang and Richard J. Samworth (2020). Sparse principal component analysis via axis- aligned random projections. Journal of the Royal Statistical Society: Series B (Statistical Methodology).
[4] Tomá Pevn. Loda: Lightweight on-line detector of anomalies. Machine Learning, 2016, 102(2).
[5] Yamanishi, K. , Takeuchi, J. I. , Williams, G. , & Milne, P. . (2000). On-line unsupervised outlier detection using finite mixtures with discounting learning algorithms. Data Mining & Knowledge Discovery, 8(3), 275-300.
[6] Subramaniam, S., Palpanas, T., Papadopoulos, D., Kaloger-aki, V., and Gunopulos, D. Online outlier detection in sensordata using non-parametric models. In Proceedings of the 32nd interna-tional conference on Very large data bases(2006), VLDB Endowment, pp. 187–198.
[7] Faulkner, M., Olson, M., Chandy, R., Krause, J., Chandy,K. M., and Krause, A. The next big one: Detecting earthquakes and other rare events from community-based sensors. In Information Processing in Sensor Networks (IPSN), 2011 10th International Conference on (2011), IEEE, pp. 13–24.
[8] Sejdinovic, D., Sriperumbudur, B. , Gretton, A. , & Fukumizu, K. (2013). Equivalence of distance-based and RKHS-based statistics in hypothesis testing. Annals of Statstistics, 41(5), 2263-2291.
[9] Angiulli, F., and Fassetti, F. Detecting distance-based outliers in streams of data. In Proceedings of the sixteenth ACM conference on Conference on information and knowledge management (2007), ACM,pp. 811–820.
[10] Pokrajac D.,, Lazarevic, A. , & Latecki, L. J. (2007). Incremental Local Outlier Detection for Data Streams. IEEE Symposium on Computational Intelligence & Data Mining.
[11] Ro, K., Zou, C. & Wang, Z. (2015). Outlier detection for high-dimensional data. Biometrika.
[12] Haibin Cheng (2008). A Robust Graph-based Algorithm for Detection and Characterization of Anomalies in Noisy Multivariate Time Series. IEEE International Conference on Data Mining Workshops.
[13] Hans-Peter Kriegel, Matthias Schubert, Arthur Zimek (2008). Angle-Based Outlier Detection in High-dimensional Data. KDD.
[14] Park, S. , Han, S. , & Woo, S. S. . (2021). Forecasting Error Pattern-Based Anomaly Detection in Multivariate Time Series.
[15] Singer, R.M, Gross, K.C, King, & R.W. (1996). A pattern-recognition-based, fault-tolerant monitoring and diagnostic technique. Office of Scientific & Technical Information Technical Reports.
[16] Jones, M. , Nikovski, D. , Imamura, M. , & Hirata, T. . (2014). Anomaly detection in real-valued multidimensional time series. 2014 ASE BIGDATA/SOCIALCOM/CYBERSECURITY Conference.
[17] Lee, H.-j., and Roberts, S. J. On-line novelty detection using the kalman filter and extreme value theory. In Pattern Recognition, 2008.
[18] Inka Saarinen (2017). Adaptive real-time anomaly detection for multi-dimensional streaming data.
[19] Liu, Y., Zhang, L., and Guan, Y. Sketch-based streaming pca algorithm for network-wide traffic anomaly detection. In Distributed Computing Systems (ICDCS), 2010 IEEE 30th International Conference on (2010), IEEE, pp. 807–816.
[20] Huang, H., and Kasiviswanathan, S. P. Streaming anomaly detection using randomized matrix sketching. Proceedings of the VLDB Endowment 9, 3 (2015), 192–203.
[21] Kamalov, Firuz; Leung, Ho Hon (2020). Outlier Detection in High Dimensional Data. Journal of Information & Knowledge Management.
[22] Schölkopf, B.,Platt, J. C .,Shawe-Taylor, J. C.,Smola, A. J.,and Williamson, R. C.2001. Estimating the support of a high-dimensional distribution. Neural Comput. 13,7, 1443–1471.
[23] Roth, V. 2004. Outlier detection with one-class kernel fisher discriminants. In NIPS .
[24] Roth, V. 2006. Kernel fisher discriminants for outlier detection. Neural Computation 18,4, 942–960.
[25] Stefano, C.,Sansone, C.,and Vento, M. 2000. To reject or not to reject: that is the question–an answer in case of neural classifiers. IEEE Transactions on Systems, Management and Cybernetics 30,1, 84–94.
[26] Barbara, D.,Couto, J.,Jajodia, S.,and Wu, N. 2001. Detecting novel network intrusions using bayes estimators. In Proceedings of the First SIAM International Conference on Data Mining.
[27] Tan, S. C., Ting, K. M., and Liu, T. F. Fast anomaly detection forstreaming data. In IJCAI Proceedings-International Joint Conferenceon Artificial Intelligence (2011), vol. 22, p. 1511.
[28] Guha, S., Mishra, N., Roy, G., and Schrijvers, O. Robust random cut forest based anomaly detection on streams. In Proceedings of The 33rd International Conference on Machine Learning (2016), pp. 2712–2721.
[29] M. M. Breunig, H. P. Kriegel, R. T. Ng, J. Sander. LOF: Identifying Density-based Local Outliers. SIGMOD, 2000.
[30] Guillaume Staerman, Pavlo Mozharovskyi, Stephan Clémençon, Florence d'Alché-Buc (2019). Functional Isolation Forest. arXiv:1904.04573.
[31] Ester, M.,Kriegel, H.-P.,Sander, J.,and Xu, X. 1996. A density-based algorithm for dis-covering clusters in large spatial databases with noise. In Proceedings of Second InternationalConference on Knowledge Discovery and Data Mining.
[32] Guha, S.,Rastogi, R.,and Shim, K. 2000. ROCK: A robust clustering algorithm for categoricalattributes.Information Systems 25,5, 345–366.
[33] Sean J. Taylor & Benjamin Letham (2017): Forecasting at Scale, The American Statistician, DOI: 10.1080/00031305.2017.1380080
[34] Liu, Fei Tony, Kai Ming Ting, and Zhi-Hua Zhou. "Isolation forest."Data Mining, 2008. ICDM'08. Eighth IEEE International Conference on. IEEE, 2008.
写在最后
近年来,在AIOps领域快速发展的背景下,IT工具、平台能力、解决方案、AI场景及可用数据集的迫切需求在各行业迸发。基于此,云智慧在2021年8月发布了AIOps社区, 旨在树起一面开源旗帜,为各行业客户、用户、研究者和开发者们构建活跃的用户及开发者社区,共同贡献及解决行业难题、促进该领域技术发展。
社区先后 开源 了数据可视化编排平台-FlyFish、运维管理平台 OMP 、云服务管理平台-摩尔平台、 Hours 算法等产品。
可视化编排平台-FlyFish:
项目介绍:https://www.cloudwise.ai/flyF...
Github地址: https://github.com/CloudWise-...
Gitee地址: https://gitee.com/CloudWise/f...
行业案例:https://www.bilibili.com/vide...
部分大屏案例:

请您通过上方链接了解我们,添加小助手(xiaoyuerwie)备注:飞鱼。加入开发者交流群,可与业内大咖进行1V1交流!
也可通过小助手获取云智慧AIOps资讯,了解云智慧FlyFish最新进展!
