机器学习反爬虫
20220418
可能存在的问题
1.不存在流量数据和详细的参数信息 不能很好的扩展和深入
2.人工打标费时费力 而且的反复
3.特征的问题
如何区分自然的会话标记
http请求类型,head是什么意思
4.最后想怎么用?实时肯定是不可能的
5.下过订单的且不止一次的肯定是真实的用户,收藏,加购,根据用户特征来区分用户个人信息特征和
行为特征
https://www.fx361.com/page/2020/1223/7722833.shtml
基于机器学习的反爬虫应用策略研究
爬虫特征
为了更好的识别网络爬虫,从而进行反爬虫策略的实施,收集了网络爬虫的特征。目前网络上的网络爬虫具有以下特征:①相同IP的请求频率大、②相同的IP每次访问的时间间隔小、③IP所在地不稳定、④user-agent不是常见标识、⑤验证码的请求次数多、⑥激活爬虫陷阱、⑦图片访问百分比高、⑧错误响应高、⑨不对robot.txt进行访问。
通过爬虫技术结构的组成可以看到,反爬虫主要针对其数
据采集部分,可从 Headers 信息处理(对 Headers 的 User-Agent
结合 Referer 进行检测,通过记录和分析相关信息来挖掘和封锁
爬虫达到拒绝爬虫访问的目的)、Cookie 限制(网站通过校验
请求信息是否存在 Cookie,以及校验 Cookie 的值来判定发起访
问请求的到底是真实的用户还是爬虫)、验证码限制(验证码
的干扰线,噪点已经多到肉眼都无法轻易识别的地步。验证码
限制已成为最有效阻断技术之一)、通过用户行为检测(爬虫
的访问总数会远高于正常访问数,设定一个阈值,如果同一 IP
短时间内多次访问同一页面,或者同一账户短时间内多次进行
相同操作,超过阈值,则可判定为爬虫访问)几个方面进行。
基于机器学习的大规模网络流量识别方法研究_姜易
选由时间窗探测方法得到的特征属性的集合。
钛学术_专利_一种基于机器学习的恶意网络爬虫监测和处理方法及系统 重点
#####################
下面是比较直接的爬虫特征
5 常见基于身份识别进行反爬
1 通过headers字段来反爬
headers中有很多字段,这些字段都有可能会被对方服务器拿过来进行判断是否为爬虫
1.1 通过headers中的User-Agent字段来反爬
- 反爬原理:爬虫默认情况下没有User-Agent,而是使用模块默认设置
- 解决方法:请求之前添加User-Agent即可;更好的方式是使用User-Agent池来解决(收集一堆User-Agent的方式,或者是随机生成User-Agent)
1.2 通过referer字段或者是其他字段来反爬
- 反爬原理:爬虫默认情况下不会带上referer字段,服务器端通过判断请求发起的源头,以此判断请求是否合法
- 解决方法:添加referer字段
1.3 通过cookie来反爬
- 反爬原因:通过检查cookies来查看发起请求的用户是否具备相应权限,以此来进行反爬
- 解决方案:进行模拟登陆,成功获取cookies之后在进行数据爬取
2 通过请求参数来反爬
我们现在好像没有设置请求参数
6 常见基于爬虫行为进行反爬
1 基于请求频率或总请求数量
爬虫的行为与普通用户有着明显的区别,爬虫的请求频率与请求次数要远高于普通用户
1.1 通过请求ip/账号单位时间内总请求数量进行反爬
- 反爬原理:正常浏览器请求网站,速度不会太快,同一个ip/账号大量请求了对方服务器,有更大的可能性会被识别为爬虫
- 解决方法:对应的通过购买高质量的ip的方式能够解决问题/购买个多账号
1.2 通过同一ip/账号请求之间的间隔进行反爬
- 反爬原理:正常人操作浏览器浏览网站,请求之间的时间间隔是随机的,而爬虫前后两个请求之间时间间隔通常比较固定同时时间间隔较短,因此可以用来做反爬
- 解决方法:请求之间进行随机等待,模拟真实用户操作,在添加时间间隔后,为了能够高速获取数据,尽量使用代理池,如果是账号,则将账号请求之间设置随机休眠
1.3 通过对请求ip/账号每天请求次数设置阈值进行反爬
- 反爬原理:正常的浏览行为,其一天的请求次数是有限的,通常超过某一个值,服务器就会拒绝响应
- 解决方法:对应的通过购买高质量的ip的方法/多账号,同时设置请求间随机休眠
In order to better identify the web crawler and implement the anti crawler strategy, the characteristics of the web crawler are collected. At present, web crawlers on the network have the following characteristics: ① the request frequency of the same IP is high; ② the time interval of each visit of the same IP is small; ③ the IP location is unstable; ④ the user agent is not a common identifier; ⑤ the number of requests for verification code is high; ⑥ the trap of activating crawler; ⑦ the percentage of map access is high; Ⅷ the error response is high; and Ⅸ the error response is not correct robot.txt Visit.
为了更好地识别网络爬虫并实施反爬虫策略,对网络爬虫的特征进行了收集。目前,网络上的网络爬虫具有以下特点:对同一IP的请求频率高;同一IP每次访问的时间间隔小;IP地址不稳定;用户代理不是普通的标识符;验证码请求数过高;爬虫激活陷阱;地图访问的比例很高;误差响应高;和错误响应是不正确的robot.txt访问。
Research on the application of crawler technology in machine learning 重点
Path-based machine learning detection focuses on
checking both visiting path features from the URL markers
and visiting time features from website access logs.
基于路径的机器学习检测主要关注URL标记中的访问路径特征和网站访问日志中的访问时间特征。
Heuristic detection
Heuristic detection module performs basic analysis on the
incoming traffic and aims to discover crawlers based on
basic traffic flow features such as the referrer, User-Agent,
and cookies of all incoming traffic. Besides those general
features, this module also performs URL marker integrity
checking, a new heuristic detection feature we proposed.
Specifically, after the server extracts the marker from the
URL, the PathMarker first compares the visitor ID with
the information recorded in the URL marker. If the real
visitor of this page is not the one recorded in the URL
marker, we flag this log entry and mark this user as a
potential crawler that visits shared links obtained by other
crawlers. If the user is marked multiple times within a
time period, we mark this user as a suspicious crawler and
prompt it with a CAPTCHA.
Though heuristic detection have been deployed on
many web systems, it is still a challenge to accurately
detect distributed crawlers that share the URLs for crawling.
With the integration of URL marker, our heuristic
detection module can detect distributed crawlers by
examining the user IDs in markers.
启发式检测模块对传入流量进行基本分析,目的是基于所有传入流量的referrer、User-Agent和cookie等基本流量流特征来发现爬虫。除了这些通用特性外,该模块还实现了URL标记完整性检查,这是我们提出的一种新的启发式检测特性。具体来说,在服务器从URL中提取标记后,PathMarker首先将访问者ID与URL标记中记录的信息进行比较。如果此页面的真实访问者不是URLmarker中记录的那个,我们将标记此日志条目,并将此用户标记为访问由其他爬虫程序获得的共享链接的潜在爬虫程序。如果用户在一段时间内被多次标记,我们将该用户标记为可疑的爬虫程序,并用验证码提示它。尽管启发式检测已经在许多web系统上得到应用,但准确检测共享url的分布式爬虫仍然是一个挑战。通过整合URL标记,启发式检测模块可以通过检测标记中的用户id来检测分布式爬虫。
Machine learning detection
We first define two concepts, namely, short session and
long session, and then derive six new features to be used
in machine learning algorithms to separate crawlers from
human beings.
机器学习检测我们首先定义了两个概念,即短会话和长会话,然后推导出六个新特征,用于机器学习算法从人类中分离爬虫。
Long session and short session
PathMarker calculates the depth and width of an extended
access log based on the session that the log belongs to.
“Long session”和“short sessionPathMarker”根据日志所属会话计算日志的深度和宽度。

3是时间间隔的变异系数

长会话是固定的?60个访问日志?
短会话不固定只要超过阈值就属于下一个短会话?一个短会话只属于一个长会话
当短会话跨两个长会话的时候,撕裂成两个短会话 短会话阈值为10s
根据具体不同的真实数据自己调节这两个参数 其实还是从业务通过数据分析而来
深度指时间?宽度指url种类数? 就以这两个指标来替代好了
其基本思想是基于一个观察,即普通用户和恶意爬虫有不同的短期和长期下载行为。换句话说,爬虫对路径的短期和长期访问模式(如深度优先、宽度优先或随机访问)是相似的;而人类只有在短期内有明显的访问模式,在长期内没有一定的访问模式。这是因为爬虫是基于一定的爬行算法工作的,一旦选择了算法,爬行路径就会遵循一定的模式。
所有访问路径对深度和宽度没有偏好的爬虫都可以归类为随机型。
Web server administrators can examine their
web servers’ logs and check several fields of the HTTP
request such as referrers and cookies to detect the
abnormal requests. Some crawlers’ requests miss these
Web服务器管理员可以检查他们的Web服务器日志,并检查HTTPrequest的几个字段,如referrer和cookie,以检测异常请求。一些爬虫请求错过这些
fields while some other requests have obviously differences
comparing with normal users’ requests in these
fields. One typical field of a request is User-Agent. Each
HTTP request contains the field User-Agent and we can
tell which software is acting on behalf of the user according
to this field. For instance, one User-Agent of Google
robots is “Googlebot/2.1” while normal users’ User-
Agents in most case would be the names of browsers.
Though it is effective to detect simple crawlers by checking
these fields, armoured crawlers are able to modify
these fields in their requests to escape this type of
detection.
而其他一些请求在这些字段上与普通用户的请求有明显的区别。请求的一个典型字段是User-Agent。每个http请求都包含user - agent字段,我们可以根据这个字段判断哪个软件代表用户进行操作。例如,Googlerobots的一个User-Agent是Googlebot/2.1,而普通用户User-Agent在大多数情况下是浏览器的名称。虽然通过检查这些字段来检测简单的爬虫程序是有效的,但是装甲爬虫程序能够在他们的请求中修改这些字段来逃避这种类型的检测。
some crawlers try to “guess”
the URLs for future access, so they will visit non-existent
URLs with a high rate within a session.
一些爬虫试图猜测未来访问的url,所以他们会在一个会话中以很高的比率访问不存在的url。
Another example is
that when crawlers try to avoid visiting the same pagemultiple
times, the rate of revisiting pages will be low within a
session.
However, since the distributed
crawlers of one attacker have similar timing-based patterns,
defenders may detect them by analyzing the similarities
of each user’s time series (Jacob et al. 2012).
另一个例子是,当爬虫试图避免多次访问同一个页面时,重新访问页面的比率将会很低。然而,由于一个攻击者的分布式爬虫具有相似的基于时间的模式,防御者可以通过分析每个用户的时间序列的相似性来检测它们(Jacob et al. 2012)。
是否具有爬虫 陷阱,如果有则可以通过此来判定爬虫
爬虫账号数量有限
Specifically, there are two common patterns when a user
is viewing websites. First, one usermay openmultiple web
pages at one time, so the maximum width of the user’s
visiting path could be as large as the length of the short
session. Second, the user prefers to jump to another page
after he or she takes a glance at one page, so it will present
a large depth of short session. However, for both cases of
normal users, in a long session, the maximum depth and
width of a user’s visiting path is likely to be much smaller
than the length of a long session, since a long session may
contain several short sessions and these short sessions are
independent to each other in terms of depth and width.
Meanwhile, crawlers usually have homogeneous patterns
in visiting path. For example, a depth-first crawler would
have both large depth rates of long session and short session,
while a random-like crawler would have a small rate
of depth and width.
具体来说,当用户浏览网站时,有两种常见模式。首先,一个用户可以同时打开多个网页,因此用户访问路径的最大宽度可以和短会话的长度一样大。其次,用户更喜欢在浏览完一个页面后跳转到另一个页面,所以这将呈现短会话的大深度。然而,对于这两种情况下的普通用户,在很长一段会话,用户访问路径的最大深度和宽度的长度可能远小于长会话,因为很长一段会话可能包含多个短会议和这些短会议相互独立的深度和宽度。同时,爬虫在访问路径上通常具有同构模式。例如,深度优先的爬行器在长会话和短会话中都具有较大的深度率,而类似随机的爬行器则具有较小的深度和宽度率。
系统管理员可以使用部分或全部爬虫程序对自己的系统进行爬虫。
因此,收集爬虫的数据很简单。
System administrators may use some
of or all crawlers available to crawl their own systems.
Therefore, it is straightforward to collect data of crawlers.
However, collecting normal user data is not easy since
we need to guarantee that there is no crawler running
when collecting training data. We adopt the method in
Jacob et al. (2012) for selecting the data of normal user.
First, we use heuristic module to filter outmost suspicious
users. Then we manually check the logs of all users and
remove logs with wrong URL markers.
系统管理员可能会使用一些
所有爬虫程序的或所有爬虫程序,可以爬行自己的系统。
因此,收集爬虫的数据很简单。
然而,收集普通用户数据并不容易,因为
我们需要保证没有爬虫运行
收集培训数据时。我们采用了这种方法
Jacob等(2012)用于选择普通用户的数据。
首先,我们使用启发式模块过滤出最可疑的
用户。然后我们手动检查所有用户的日志
删除带有错误URL标记的日志。
不能识别验证码认为是爬虫,激活验证码的次数
PathMarker_ protecting web contentsagainst inside crawlers 重点 2019
( 3 ) User-Agent 是否为常用浏览器User-
Agent:通常情况下每个浏览器具有特定的User-
Agent,以让服务器识别该请求是通过哪个浏览器
发起的,但是很多爬虫在设计时,并未设置User-
Agent,所以如果非常见浏览器User-Agent 或者带
有编程语言名称的User-Agent 基本可以判定为该
行为是爬虫行为[4];
(4)请求是否为全部请求:一般情况一个网站
如果有图片或者link 标签等,这样打开一个网页通
常会加载多个资源,如CSS,JS 等,但是爬虫访问
的时候,通常不会做这些额外的请求。所以当一个
请求发起之后,只请求了页面源代码而未请求相关
关联资源,那么可以基本判定,该请求是爬虫行为;
如何判定
(5)是否请求robot:通常情况,爬虫都会请求
Robot.txt,而用户是不会请求这个文档的,所以请
求Robot.txt 的通常为爬虫行为,当然也是有一部分
爬虫不会请求该文件的,所以未请求该文档的并不
代表非爬虫行为[4];
请求时是否会带有Cookies:一般情况下
爬虫请求页面的时候,都不会带有Cookies,而人为
访问的时候,都会带有前一页面或者前一次访问的
Cookies,所以在没有前一次Cookies 的请求中,有
极大可能是爬虫发起的请求


3 根据性质判断设定反爬规则
当决策树在检验某一类请求或者某个请求之
后,确定该请求具备爬虫特性的时候,通常我们就
需要对该请求进行限制,常见的限制策略如下:
(1)禁止访问:该方法是非友好方法,但是可
以说该方法是有效方法。通常情况会返回状态为
403,表示该页面禁止访问,对某个IP 进行某段时
间内的封禁
(2)增加验证:该方法是相对友好方法,但是
不推荐使用单纯的数字验证码或者英文字母验证
码,推荐使用汉字验证码或者偏移量验证码,或者
是计算题验证码,图像识别验证码,这类验证码对
于爬虫设计者来说,通过机器识别的困难度是比较
大的
(3)增加Cookies 验证(例如目前的微博反爬
措施)[9]
(4)动态加载,Ajax 技术等(例如目前的淘宝
商品列表页面等)[10]
(5)核心数据复杂化,该方法主要通过都某些
文字增加一些特殊编码或者效果,增大爬虫提取数
据难度
(6)增加登陆功能,强迫用户只有登陆才可以
查看某些内容(例如目前的阿里妈妈平台部分内容)
(7)多模板页面,随机切换,这种方法主要
是通过修改部分页面的标签或者结构,来影响爬虫
质量[11-12]
可以这样说,如果再无法鉴定是否爬虫行为的
时候,使用了禁止访问或者增加验证无疑是影响用
户体验或者加重服务器请求负担,所以特别推荐只
有在对爬虫进行识别之后,确定请求行为是爬虫行
为再进行相关屏蔽验证操作。
基于决策树算法的爬虫识别技术_刘宇 重点
20220419
对于基于机器学习的方法,G. Jacob等人首先提出了检测分布式爬虫的解决方案,并使用大规模的真实数据集评价他们的方法[6]。通过机器学习技术提取网站流量的特征,他们将人类用户的行为与网络爬虫区分开来。Wan S.在机器学习中使用启发式规则训练样本来检测网络爬虫,使用支持向量机[7]。
G. Jacob, E. Kirda, C. Kruegel, and G. Vigna, “Pubcrawl: protecting
users and businesses from crawlers,” in Proceedings of Usenix Conference
on Security Symposium, 2013, pp. 25–25.
S. Wan, Y. Li, and K. Sun, “Protecting web contents against persistent
distributed crawlers,” in Proceedings of IEEE International Conference
on Communications, 2017, pp. 1–6.
Based on the user sessions, several features are required to
be extracted for characterizing the access requests. There are
different approaches to complete this work. We classify them
as three types. The first type is using the identities information
of the user sessions, including the source IP address, source
physical address, source port, browser type, access time,
network protocol, and others. The second type is using sthe
statistic information of the logs, including percentage of
requests with error codes, percentage of requests for image
files, and others. The third type is the exception information
in the logs.
基于用户会话,需要提取几个特征来表征访问请求。有不同的方法来完成这项工作。我们把主题分为三种类型。第一种是使用用户会话的身份信息,包括源IP地址、源物理地址、源端口、浏览器类型、访问时间、网络协议等。第二种类型是使用日志的统计信息,包括包含错误码的请求的百分比,图像文件的请求的百分比,以及其他。第三种是日志中的异常信息。
A System Framework for Efficiently Recognizing Web Crawlers 次重点
在本文中,我们提出了一个混合系统,使用启发式规则和机器学习来识别网络爬虫的访问。所提出的启发式规则可以有效地检测网络爬虫的访问情况
PhantomJS。(重点) 提出的机器学习方法具有处理分布式网络爬虫行为、自动标记样本数据、提取9个有效特征用于网络爬虫识别等优点。
我们将这些启发式规则与机器学习技术相结合,以达到更好的识别精度和较低的误差
They found out that human users tend to visit image resources
and crawlers tend to visit html text resources. In addition, human users are less frequent to trigger 404 errors than crawlers.
他们发现,人类用户倾向于访问图像资源,而爬虫程序倾向于访问html文本资源。此外,人类用户触发404错误的频率低于爬虫程序。
Jacob et al. proposed a method of crawler detection based on the difference of human users traffic and crawlers traffic, even though the web crawler visits are through proxies
Jacob等人提出了一种基于人类用户流量和爬虫流量差异的爬虫检测方法,即使网络爬虫访问是通过代理
本研究提出的爬虫识别方法结合了基于启发式规则的实时识别和基于机器学习的离线识别。通过使用启发式规则,我们可以获得良好的实时性,并帮助标记会话为基于机器学习的方法。通过机器学习,我们可以发现隐藏的网络爬虫,如分布式网络爬虫,从而提高识别精度。此外,机器学习的结果可以进一步用于提高启发式规则的准确性
用户请求是否访问robots.txt文件。一般来说,人类用户不访问robots.txt文件,但网络爬虫程序经常访问这个文件,以确定网站的哪些部分符合他们的要求
用户请求是否来自代理服务器。一些网络爬虫使用代理来隐藏自己。代理有三种类型:透明代理、匿名代理和高匿名代理。透明代理和匿名代理的使用可以通过分析请求头来检测。对于使用高匿名代理的请求,由于删除了头信息,很难将其与人工用户的访问区分开来。我们建立一个数据库来存储已知的代理服务器,并比较该数据库的web访问,以确定网络爬虫。
用户请求是否有已知的爬虫用户代理。这里有一个所有开源爬虫程序用户代理的列表1。通过检查访问列表,网络爬虫可以实时检测。
用户请求是否使用PhantomJS。PhantomJS是一个无头的web内容引擎脚本,带有一个JavaScript API[14]。它可以用来模拟浏览器的行为,从而使访问与人类的访问非常相似。我们提出了一种利用PhantomJS识别网络爬虫访问次数的方法。我们首先编写一个Javascript并将其嵌入到网页中。如果请求来自PhantomJS,这个Javascript会被触发,我们的系统会收到通知。
In order to recognize the sessions of distributed web crawlers, we proposes an improved approach. We found out that the requests from distributed web crawlers tend to have the same user agents and the same first two IP address segments. Although these access records have different IP addresses, the access time is completely coherent, and the user agents for each request are exactly the same. Therefore, it can be judged that these access requests come from the same source. Based on this, when the web log is processed, the requests with the same user agent and the first two IP segment can be grouped into the same session. Algorithm 1 shows the pseudocode of the improved method.
为了识别分布式网络爬虫的会话,我们提出了一种改进的方法。我们发现,来自分布式网络爬虫的请求往往具有相同的用户代理和相同的前两个IP地址段。尽管这些访问记录具有不同的IP地址,但访问时间是完全一致的,而且每个请求的用户代理完全相同。因此,可以判断这些访问请求来自同一个来源。基于此,在处理web日志时,具有相同用户代理和前两个IP段的请求可以被分组到相同的会话中。算法1给出了改进方法的伪代码。
这种方法的一个特点是,首先判断该会话中的访问记录之前是否被标记为网络爬虫。如果是,此会话将被标记为网络爬虫;否则下一次歧视就会发生。其次,判断此会话中的访问记录是否属于已知网络爬虫的IP。如果是,会话将被标记为网络爬虫。然后判断该会话中的访问记录是否属于已知web爬虫的用户代理。如果是,会话将被标记为网络爬虫。最后,判断该会话中的访问记录是否访问robots.txt文件。如果是,会话将被标记为网络爬虫;否则,会话将被标记为普通用户。三种启发式规则用于标记这些会话,最后一个条件用于检查会话之前是否被识别为网络爬虫,以防不一致。
Percentage of requests with error codes. The main difference between the behaviors of a human and a web crawler is that a web crawler can more easily access some non-existent links because of exploratory behaviors, and thus generates erroneous requests and responses. Therefore, web crawlers incur more requests with error codes such as 40X and 50X.
带有错误代码的请求的百分比。人类的行为和网络爬虫的主要区别在于,网络爬虫可以更容易地访问一些不存在的链接,因为探索性行为,从而产生错误的请求和响应。因此,网络爬虫会招致更多带有错误代码的请求,如40X和50X。
Percentage of requests with HEAD method. HEAD method of HTTP request is used to get the header information of a response. It is used to obtain the length of the content in advance for later processing, which is commonly used for
crawlers to determine and adjust their crawling strategies. Therefore, higher percentage of requests with HEAD method indicates higher possibilities of web crawlers.
使用HEAD方法的请求的百分比。HTTP请求的HEAD方法用于获取响应的头部信息。它用于提前获取内容的长度,以便后续处理,是爬虫程序常用来确定和调整其爬行策略的方法。因此,使用HEAD方法的请求比例越高,网络爬虫的可能性就越大。
图像文件请求的百分比。对于以收集图像文件为目标的网络爬虫来说,他们唯一关心的就是图像文件。因此,图像文件请求的百分比较高,说明网络爬虫访问了图像文件。
二进制文件请求的百分比。和之前的功能一样,一些网络爬虫关注的是二进制文件,如PDF文件、PhotoShop文件等。因此,二进制文件请求的百分比越高,网络爬虫的可能性就越大。
各种指标的异常值通常都可以判定为爬虫 重点
Percentage of requests without referrer. Requests without referrer indicates a direct access rather than jumped from other web pages. Normal humans usually browser a web page while a web crawler is often designed to directly access a web page according to the URL queue generated by the web crawler.
Therefore, higher percentage of requests without referrer indicates the access of web crawlers.
没有referer的请求的百分比。没有引用的请求表明直接访问,而不是从其他网页跳转。一般人通常使用浏览器访问网页,而网络爬虫通常设计成根据网络爬虫生成的URL队列直接访问网页。
因此,没有引用的请求的较高百分比表明网络爬虫的访问。
晚上请求的百分比。在夜间(凌晨2点到8点),请求更可能是由网络爬虫发送的,因为人们通常都在睡觉。 非工作时间大量异常访问肯定是爬虫
两个请求之间的时间偏差。两个请求之间的间隔用来衡量请求的稳定性。网络爬虫和普通人行为的不同之处在于,普通人访问网页更随机,因此两个请求之间的间隔大于网络爬虫。
一个会话中的请求数。一个会话中的请求数也称为会话长度。通过研究网络爬虫和人类的行为,我们知道网络爬虫的会话时间比人类的会话时间长。因此,在一个会话中请求的数量越大,说明web爬虫的访问。 (这里的会话也是人为划分的) 问题 如何从数据中看出
通过上述几个指标进行自动打标
A hybrid approach for recognizing web crawlers 重点 有github 2019
该日志是Web服务器日志的时间浮动快照,它的检查遵循一个较短的时间速率(通常是5或10分钟的速率)。每次检查检测日志时,它的内容都会被检索和删除,从而确保要检查的条目数量总是有限的。这使得Web会话重构更快
第一次部署模块时,决策模型基于标准启发式和“robots.org”数据库信息(即已知的用户代理和IP地址信息)。
Web服务器监视器跟踪Web服务器性能,记录以下数据:状态错误的数量、连续请求之间的驻留时间、使用的HTTP方法以及请求占每个请求类型的百分比。
我们考虑三类不同的程序:无害的、非恶意的和恶意的程序。自我识别自己并且不改变服务器性能的爬虫程序被归类为无害的。那些没有试图隐藏其身份,但由于某种原因而干扰服务器性能或执行奇怪请求的程序会被标记为潜在恶意。那些使用可疑的用户代理或使服务器过载或访问受限区域的人被认为是恶意的。


特征重点

Crawlers such as ‘asterias/2.0’,
‘blinker/incremental0.64’, ‘cfetch/1.0’, ‘DA x.x’, ‘EmailSiphon
‘findlinks/0.9xx (+http://wortschatz.uni-leipzig.de/findlinks/)’,
‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0) Fetch API
Request’, ‘htdig/3.1.6 ([email protected])’,
‘Mozilla/2.0 (compatible; NEWT ActiveX; Win32)’,
Table 4. Examples of User Agent Matching Issues.
User agent examples Description
Googlebot/2.1
(+http://www.google.com/bot.html)
Mozilla/5.0 (compatible; Googlebot/2.1;
+http://www.google.com/bot.html)
Googlebot-Image/1.0
Different identifications
for the same crawler or
family of crawlers.
googlebot ([email protected])
‘htdig ( NOT Googlebot !)’/3.1.6
([email protected])
Misleading substrings.
Mozilla/4.0 (compatible; grub-client-2.6.1)
Mozilla/4.0 (compatible; MSIE 6.0; Windows
NT 5.1; Googlebot/2.1
(+http://www.google.com/bot.html))
Mozilla/4.0 compatible ZyBorg/1.0 (wn-
[email protected];
http://www.WISEnutbot.com)
Mozilla/5.0 (compatible; Yahoo! Slurp;
http://help.yahoo.com/help/us/ysearch/slurp)
Mozilla-alike user
agents with no body
standard.
DA 5.0
Java/1.4.1_04
lg1nqq1j ubotxjFotkhrjbgrjonme
SURF
Too frequent substrings,dubious strings or senseless strings

Catching web crawlers in the act
items in a month and the service has a restriction rule that
an IP address with more than (e.g., 100) requests will be
blocked
如果客户端只持续请求特定的网页,而没有调用正常应该请求的网页,则该客户端将被视为爬虫。
Second, there is a chance to detect normal users that share a single public IP address as a crawler. 可能误将局域网中多台机子(但公网ip只有一个)的访问识别为爬虫
If items are sorted by access rates, we can see
the exponentially decreasing curve in the graph, as shown
in Figure 1. The most web traffic is concentrated on most
frequently requested items [5], and there is a long-tail region
that has low access rates. We calculated maximum request
counts of this long-tail region and set this value as 3
如果按访问率排序,我们可以看到图中的指数下降曲线,如图1所示。大多数web流量集中在最频繁请求的项目[5]上,存在一个访问率较低的长尾区域。我们计算最大request counts这个长尾区域,将该值设置为 3
访问页面长尾区
在信息理论中,不太可能事件比可能事件具有更多的信息,长尾区域的事件比其他事件更不可能。

Using this information asymmetry,
service providers can easily identify IP addresses that
accessed the items more frequently than other IP addresses
利用这种信息不对称,服务提供者可以很容易地识别访问条目频率高于其他IP地址的IP地址
If a particular IP address accesses an item in the long-tail
region with more than the 3 value determined by the above
formula, it can be included in the block list.
如果一个特定IP地址访问一个项目在long-tailregion超过Td3 上述公式中 价值决定的,它可以包含在块列表。

增加白名单
第二步过滤掉一些访问日志,以计算更准确的访问计数。有些请求被合并为一个请求,以防止重复计数。例如,当用户访问html文件时,他们也可以访问被链接的图像文件。这可能会迫使访问计数增加数倍。因此,我们删除了一些对图像文件的请求。此外,我们从实验中排除了访问结果不成功的请求日志
预处理
通常,会话识别通过以下方式执行:(1)对来自相同IP地址并由相同的用户代理字符串描述的所有HTTP请求进行分组,注意重点,相同ip并不能说明是同一个主机还需要加上相同的用户代理?
因此,会话被定义为来自相同IP地址的请求序列(由相同的用户代理字符串描述),序列中任意两个连续HTTP请求之间的时间间隔在预定义的阈值内。 (不太适合)
在大多数网络相关文献中,30分钟的时间段被作为最合适的最大会话长度(参见Ref.[13])。因此,我们的日志分析器使用相同的30分钟阈值来区分同一用户启动的不同会话。
特征
点击数量—数值属性,计算为用户在单个会话中发送的HTTP请求的数量。
HTML与图像的比率:一个数值属性,计算为在单个会话中发送的HTML页面请求数与图像文件(JPEG和PNG)请求数的比值。网络爬虫程序通常请求的大多是HTML页面,而忽略站点上的图像,这意味着Web爬虫程序的HTML与图像的比例将高于人类用户。
Percentage of HTTP requests of type HEAD a numerical attribute calculated as percentage of requests of HTTP type HEAD sent in a single session. (In the case of an HTTP HEAD request, the server returns the response header only, and not the actual source, i.e., file.) Most web crawlers, in order to reduce the amount of data requested from a site, employ the HEAD method when requesting a web page. On the other hand, requests coming from a human user browsing a web site via browsers are, by default, of type GET.
HEAD类型的HTTP请求的百分比:一个数值属性,根据在单个会话中发送的HTTP类型HEAD请求的百分比计算。(在HTTP HEAD请求的情况下,服务器只返回响应头,而不是实际的源,即文件。)大多数网络爬虫程序,为了减少从站点请求的数据量,在请求一个web页面时使用HEAD方法。另一方面,来自通过浏览器浏览网站的人类用户的请求默认类型为GET。
head是什么意思 问题
页面流行度指数
Standard deviation of requested page’s depth
对于大多数属于人类访问者的会话,请求页面深度的标准差(属性8)保持较低,而对于大多数web机器人会话,请求页面深度的标准差保持较高。
Percentage of consecutive sequential HTTP requests
基于上述论点,我们有理由认为,连续的HTTP请求数量在人类用户会话中会相对较高,而在web机器人会话中相对较低。
因此,在我们的研究中,任何试图访问robots.txt文件的web会话都被认为是由一个自动程序(即爬虫程序)生成的
打标标签
(1) Any feature vector that corresponds to a web session whose
user agent string matches a known browser and does not access the ‘robots.txt’ file is labeled as human visitors.
任何与用户代理字符串匹配已知浏览器且没有访问robots.txt文件的web会话相对应的特征向量都被标记为人类访问者。
(2) Any feature vector that corresponds to a web session whose
user agent string matches a known well-behaved web crawler
is labeled as well-behaved web crawlers.
任何与一个用户代理字符串匹配一个已知的行为良好的网络爬虫的web会话相对应的特征向量都被标记为行为良好的网络爬虫。
(3) Any feature vector that corresponds to a web session whose
user agent string matches a known malicious web crawler is
placed in a cluster of malicious web crawlers. Also any session
belonging to a human visitor or unknown visitor in which the
user accesses the ‘robots.txt’ file is also placed in a cluster of
malicious web crawlers.
任何与一个用户代理字符串匹配已知恶意网络爬虫的web会话相对应的特征向量都被放置在一个恶意网络爬虫集群中。此外,任何属于人类访问者或未知访问者的会话,其中用户访问robots.txt文件也被放置在一个恶意网络爬虫集群。
(4) All other web sessions are labeled as unknown visitors.
注意,日志分析器维护一个表,其中包含所有已知的(恶意的或行为良好的)web爬虫程序的用户代理字段。这个表可以从网站[21,22]中找到的数据构建。这些网站还维护各种浏览器的用户代理字符串列表,这些用户代理字符串也可用于识别网站的人类访问者。
白名单和黑名单

特征
除了对异常的恶意会话和异常的人类会话进行深入的评估之外,我们还仔细研究了一个知名的、行为良好的爬虫程序的特定子组。也就是说,我们的目标是调查三种流行的商业网络爬虫:GoogleBot(属于谷歌在线搜索引擎),MSNBot(属于MSN在线搜索引擎)和YahooBot(属于雅虎在线搜索引擎)之间的浏览风格是否有显著的相似性。
Detection Method for Distributed Web-Crawlers A Long-Tail Threshold Model
他们认为,根据IP地址和用户代理字段对web日志项进行分组的标准方法可能不能很好地工作,因为一个IP/用户代理对可能包含多个会话(例如,共享同一代理服务器的web用户创建的会话)。
接下来,作者通过将会话分解为片段(片段(一次访问?)对应于对HTML文件的请求),获得每个会话的25个不同属性
因为通常人类用户不会请求机器人。. txt,发送大量的HEAD请求?,或发送带有未分配引用字段的请求
观察到的用户会话被划分为已知机器人、已知浏览器、可能的机器人和可能的浏览器组
分成三类
日志分析仪的操作分三个阶段进行:(1)会话识别,(2)对每个识别会话的特征提取,和(3)会话标记(见图2)。
根据Liu和Keselj(2007)的说法,网络会话是一个用户从进入一个网站的那一刻到离开它的那一刻所执行的一组活动。会话标识通常是首先通过分组执行HTTP请求,源自相同的IP地址和用户代理,其次运用超时的方法打破这种分组到不同的群体,所以,连续两个群体之间的延时是超过一个预定义的阈值。这种方法的关键挑战是确定适当的阈值,因为不同的Web用户表现出不同的导航行为。在大多数网络相关的文献中,30分钟的时间被用作最合适的最大会话长度(见Stassopoulou &Dikaiakos, 2009;棕褐色,库马尔,2002)。因此,我们的日志分析器使用相同的30分钟阈值来区分同一用户启动的不同会话 此方式不对
特征
实验2:将人类和行为良好的爬虫会话分类为一个组,将属于恶意网络爬虫和未知访问者的会话分类为另一个组。在本实验中,日志分析器生成一个数据集,其中人类会话或已知行为良好的网络爬虫程序的会话被类标记为值0,已知恶意网络爬虫程序或未知访问者的会话被标记为值1。
日志分析器维护一个表,其中包含所有已知的(恶意的或行为良好的)web爬虫程序的用户代理字段。这个表格是根据网站(Bots vs. Browsers, 2011;User-Agents.org, 2011)。(网站还维护各种浏览器用户代理字符串的列表,这些字符串也可以用来识别网站的人类访问者。)考虑到该表所包含的信息,第一次实验中使用的数据集标注如下 问题要做的工作
Feature evaluation for web crawler detection with data mining techniques
我们的检测是基于这样的观察,即爬虫流量与用户流量显著不同,即使许多用户隐藏在单个代理后。此外,我们提出了第一个爬虫活动归因技术,发现来自多个主机的同步流量。最后,我们引入了一种遏制策略,利用我们的检测结果有效地阻止爬行程序,同时最大限度地减少对合法用户的影响。我们在一个大型、知名的社交网络站点(每天接收数千万次请求)中的实验结果表明,PUBCRAWL可以非常准确地区分爬行器和用户。我们已经完成了技术转让,社交网站PUBCRAWL目前正在生产中运行。
服务器日志条目(即输入)首先被分割成固定长度的时间窗口。系统运行在这些窗口上,提取出两种信息:(1)HTTP报头信息,包括url;(2)以时间序列形式呈现的时序信息。
交通状态检测。当爬虫程序正确设置不同的HTTP字段并伪装用户代理字符串时,区分缓慢的爬虫程序和繁忙的代理将变得更加困难,因为它们无法根据请求量来区分。流量形状检测解决了这个问题。对于给定的源IP地址,系统在固定的时间窗口上分析请求(时间戳),以构建相关的时间序列。图2描述了爬虫的时间序列
随着时间的推移,爬虫流量倾向于表现出更多的规律性和稳定性。相反,用户流量往往表现出更多的本地差异。然而,随着时间的推移,用户流量也显示出重复的模式,其规律性与人类时间尺度有关(例如,每日或每周模式)。 爬虫因为是调度所以开启时间可能非常的固定,非常的有规律 重点
我们将分布在多个位置的一组爬虫程序表示为爬行运动,这些爬虫程序显示同步的活动。
图3展示了两个时间序列,对应同一个爬虫程序分布在不同子网的两个主机上。人们可以观察到这两个时间序列之间有很高的相似性。我们的方法的关键见解是,这些相似性可以用来识别作为活动一部分的分布式爬虫程序。

识别分布式爬虫
如前所述,其他源每天被授予少量无限制访问。对于超过这个阈值的ip,系统通过在响应页面中插入验证码或爬虫陷阱进行响应。
特征
高错误率:用于提供爬虫的URL列表通常包含属于无效配置文件名称的条目。因此,爬虫程序在访问配置文件页面时往往会出现较高的出错率。
低页面访问:爬行器倾向于避免重复访问相同的页面。另一方面,用户倾向于定期访问他们网络中的相同配置文件。用户短时间重复访问相同的页面,而爬虫则避免访问相同的页面
Suspicious referrer: Many crawlers ignore the referrer field in a request, setting it to null instead. Advanced crawlers do handle the referrer field, but give themselves away by using referrers that point to the results of directory queries (listings). 重点 (网络上随处可见的user-agent列表)
Ignored cookies: Many crawlers ignore cookies. As a result, a new session identifier cookie is issued for each request by these crawlers.
不平衡的流量:当我们看到多个用户代理字符串来自一个IP时,我们希望这些不同的用户代理之间的请求在某种程度上是平衡的。如果一个代理负责99%以上的请求,这是可疑的。但不能完全确定
Suspicious profile sequence: Crawlers often access profiles in a sorted (alphabetic) order. This is because the pointers to profiles are often obtained from directory queries.
爬虫按排序的顺序进行访问
推导时间序列。我们在一个时间窗口[t0;作为一种计数过程(一种特定的时间序列)。计数进程X(t) = fX(t)gtn t0计数在固定持续时间的n个时间间隔内从给定源到达的请求的数量,其中每个间隔是整个时间窗口的一小部分。请注意,流量日志必须分割为至少两天的窗口
我们选择d = 30分钟作为每个时间间隔的长度,以平滑时间序列的形状。较短的间隔使序列对网络通信中的扰动过于敏感,而网络通信往往与源无关。相反,间隔时间越长,就越难以捕捉到交通中有趣的变化。
计算源时间序列的样本自相关函数(SAC)并分析其形状[3,第9章]。SAC捕获不同时间点上的值对前几次进程观察到的值的依赖性(两个比较值之间的时间差异称为滞后)。这个函数可以很好地指示请求计数如何随时间变化。小延迟时的强自相关表明过程稳定(规则),这是爬虫的典型特征。较高滞后的自相关峰值表明潜在的季节变化,就像用户的情况一样(例如,滞后一天的强自相关表明流量遵循常规的每日模式)。
具体序列的值是什么难道是流量?
自相关解释。解释SAC的形状传统上是一个手工过程,这是留给分析师[3]的。对于我们的系统,这个过程需要自动化。为此,我们引入三个特征来描述SAC的特性:衰减速度、符号交替和局部峰值。
麻烦事
衰减的速度反映了交通的短期稳定性。缓慢的衰减表明流量在较长的时间内是稳定的,而快速的衰减则表明流量不稳定。衰减速度特征可以假设四个值:线性衰减、指数衰减、截止衰减(系数达到悬崖并下降)、无衰减(系数与随机噪声相当)。
符号交替标识SAC符号变化的频率。其值为:无交替、单次交替、振荡或不稳定。无标志或单标志变化是典型的爬虫程序,而用户流量可能显示更多的变化。
本地峰值反映了流量的周期性。局部尖峰意味着一个重复的活动,它的出现被一个固定的时间差(滞后)隔开。这对于用户流量来说是很典型的。该特性有两个值:一个离散的峰值计数加上一个布尔值,该值指示是否在感兴趣的延迟(半天、天)观察到峰值。
Trend variation. The trend components for crawlers are often very stable, and thus, close to a square signal. To distinguish stable from noisy signals , we apply the differentiation operator r (with a lag 1 and a distance of 1) to the trend. For crawlers where the traffic is rather stable, the differentiated trend is very close to a null series, with the exception of spikes when an amplitude shift occurs. For users, the traffic shows quicker and more frequent variations, which results in a higher variation of the differentiated trend series. The variation of the differentiated trend is measured using the Index of Dispersion for Counts [12], IDC[rT(t)]. Compared to other statistical indicators such as the variance, the IDC, as a ratio, offers the advantage of being normalized.

特征
每天生成少于1,000个请求的源也会被搁置一边,因为我们基于时间序列的技术需要最少数量的数据点才能产生有统计意义的结果。这些源由主动遏制策略处理。
在下一步中,我们对源代码进行了广泛的手工分析(通过查看时间序列,检查用户代理字符串值,…)。我们对基本事实做了第二套调整。特别地,我们发现了许多启发式检测遗漏的爬虫程序。这些爬虫程序积极地试图模仿浏览器的行为:来自已知web浏览器的用户代理字符串、cookie和引用管理,以及在夜间缓慢运行。附录b中讨论了一些模拟的例子。这些例子非常有趣,因为它们强调了需要更健壮的爬虫检测方法,如PUBCRAWL。
PUBCRAWL Protecting Users and Businesses from CRAWLers 重点较难啃
特征
Percentage of HEAD requests: HTTP GET requests are
used to retrieve web-page content whereas HTTP HEAD
requests retrieve web-page metadata. It is expected that
“polite” crawlers would use the HEAD method, when
possible, in order to detect and download only recently
updated pages, so as to minimize the consumption of
Web-server resources.
header请求较多的是爬虫
3xx响应的百分比:先前的研究表明,人为引起的HTTP请求收到的频率更高
304响应代码,指示浏览器调度if-modified-since请求比爬虫程序更频繁。
AvgTime: This feature denotes the average time between
two consecutive htm, html, php and asp requests.
StdDevTime: Considering that the average can be a misleading
feature (due to outliers), we also calculate the
standard deviation for the above feature.
同时考虑平均值和标准差
Percentage of Image requests. As it can be seen from
figure 1, almost all human induced sessions have at least
10% requests for images, whereas only 1% of crawler
sessions contain image requests.
• Percentage of page requests (% of html, htm, php, jsp
requests). In figure 2, we can see that the majority
of crawler sessions have a percentage of page requests
higher that 60%, compared to that of human sessions
which is lower (only 6%).
• Percentage of 4xx response code. Our results showed
that 35% of crawlers have a percentage of 4xx response
code higher than 20% compared with humans which is
approximately 4%.
Session time-out threshold. Our analysis shows that in
75% of the crawler sessions, the time between two
consecutive page requests (html, htm, php, asp) is less
than 50 seconds.
• Maximum click-rate. The maximum click rate in 99%
of human user sessions does not exceed 10 clicks per
minute whereas 60% crawler sessions have a click rate
higher than 10.

EVALUATION METRICS OF EACH OF THE 5 EXPERIMENTS. THE EXPERIMENTS DIFFER IN THE MINIMUM NUMBER OF REQUESTS USED BY THE SYSTEM
BEFORE MAKING A CLASSIFICATION DECISION FOR AN IP ADDRESS.
Real-time web crawler detection_2011
http://www.jafsoft.com/searchengines/webbots.html#search_engine_robots_and_others
http://www.robotstxt.org/db.html
公开的搜索引擎user-agent list 重点
最大持续点击率:点击是对HTML文件的请求。这个特性对应于一个会话内的某个时间窗口内实现的HTML请求的最大数量。这背后的直觉是,在特定的时间框架t内,人类可以发出的最大点击次数有一个上限,这是由人为因素决定的。为了获得这一特性,我们首先设置时间框架值t,然后在给定会话中使用时间t的滑动窗口,以测量该会话中的最大持续点击率。例如,如果我们将t设置为12秒,并发现在该会话内的某个12秒时间窗口内的最大点击次数是36,我们得出的结论是最大持续点击率是每秒3次。这表明这是一种类似机器人的行为,而不是类似人类的行为。滑动窗口方法从会话的第一个HTML请求开始,并保存每个窗口内最大点击次数的记录,按一个HTML请求滑动窗口,直到到达给定会话的最后一个。每个窗口所有点击次数的最大值就是这个属性/特性的值。
会话持续时间:这是第一个请求和最后一个请求之间经过的秒数。
爬行者诱导的会话往往比人类会话持续时间长得多。人类的浏览行为比网络机器人更有针对性和目标导向。此外,人类在网站中浏览的时间是有一定限制的。
打标
因此,我们开发了一种使用启发式将标签分配给会话的半自动方法。所有会话最初都假定为人类。然后,我们使用以下启发式方法将一些会话标记为爬行器,已知爬虫程序的IP地址:我们使用日志中记录的HTTP请求的IP地址来执行反向DNS查找和转换IP
地址的主机名。用这个mappingweassign
用一组众所周知的主机名向爬虫程序发送IP地址。然后,我们的日志分析器准备一个表,其中包含属于已知爬虫程序的所有IP地址。
训练会话的每个IP地址都与这个已知爬虫程序的IP地址表进行比较。如果IP匹配,我们将会话标记为Web机器人。
会话持续时间:如果是会话的持续时间,即。
第一个请求和最后一个请求之间的时间超过了阈值小时数,那么我们假定这是一个爬虫引起的会话。从我们的实验中,我们发现3小时是一个很好的阈值选择。
HTML对图像的请求比:如前所述,我们之前的研究[15,14]表明,由于HTML文件中嵌入了图像,人类比爬虫有更高的图像请求数量。另一方面,爬虫程序有大量的HTML请求和微不足道的图像请求,因为这些通常在网络机器人下载时被忽略了。这个启发式的目的是通过将每个图像文件超过10个HTML文件的任何会话标记为crawler来获取关于爬虫程序行为的知识。换句话说,如果一个会话中的html与图像的比率大于10,那么这很可能是一个爬虫会话,因此我们将其标记为爬虫会话。
需要注意的是,我们只使用上面的第一个启发式方法来确定会话的标签为爬虫。其他启发式算法用于将会话作为爬虫程序给出一个推荐的标记。然后由人类专家手动检查这些会话,以确认或否认建议的爬虫标记。通过这种半自动的方法,我们的目标是最小化引入在我们的训练集中的噪声。
由于我们正在研究用户代理的点击流的明显行为,因此可以公平地假设,任何总共少于5个请求的会话都太短,无法启用标签。即使通过人工检查,具有如此少量请求的会话也几乎不可能进行分类。因此,我们忽略了标记和测试阶段中太小的会话(即少于5个请求)。
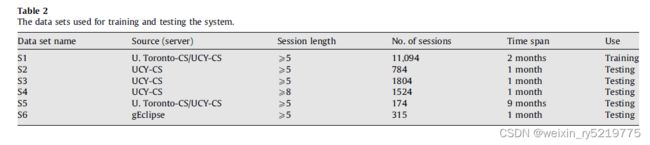
图1显示了一系列页面视图的时间间隔。在图1中,大多数时间间隔从大约20秒收敛到140秒。我们认为在一个正常的会话中,页面浏览的间隔时间分布在一个值的范围内,一个非常大的值的出现可能意味着另一个会话的开始。那么67’^ 和68’之间的时间间隔是2230秒,远远大于平均值,可以认为是一个新会话的开始。
会话的定义

代理服务器的处理?
Other techniques, such as using cookies or combining content/structure information can be used to deal with these kinds of complexity.
而图3(b)中的分布表现为高斯特征。我们认为它显示了一个唯一用户的浏览行为。对于一个网站的常客来说,他访问网页的特点反映了他/她的心理、兴趣、阅读风格、阅读速度等,而与网页的内容无关。然后根据频率分布识别出唯一的用户。
Web robot detection A probabilistic reasoning approach_2009