深度学习实战(十一)——多标签分类(基于Keras)
目的:
训练一个分类器来将物品分到不同的类别中,比如一件衣服:可以安照服饰类别、颜色、质地打上“衬衫”、“蓝色”、“棉”的标签
服饰类别:衬衫、裙子、裤子、鞋类等
颜色:红、蓝、黑等
质地:棉、羊毛、丝、麻等
整个工程的步骤如下:
- 首先讨论多标签分类数据集(以及如何快速构建自己的数据集)。
- 之后简要讨论SmallerVGGNet,我们将实现的Keras神经网络架构,并用于多标签分类。
- 然后我们将实施SmallerVGGNet并使用我们的多标签分类数据集对其进行训练。
- 最后,我们将通过在示例图像上测试我们的网络,并讨论何时适合多标签分类,包括需要注意的一些注意事项。
这里给出的是项目的文件结构
├── classify.py
├── dataset
│ ├── black_jeans [344 entries
│ ├── blue_dress [386 entries]
│ ├── blue_jeans [356 entries]
│ ├── blue_shirt [369 entries]
│ ├── red_dress [380 entries]
│ └── red_shirt [332 entries]
├── examples
│ ├── example_01.jpg
│ ├── example_02.jpg
│ ├── example_03.jpg
│ ├── example_04.jpg
│ ├── example_05.jpg
│ ├── example_06.jpg
│ └── example_07.jpg
├── fashion.model
├── mlb.pickle
├── plot.png
├── pyimagesearch
│ ├── __init__.py
│ └── smallervggnet.py
├── search_bing_api.py
└── train.py
我们将用到的重要文件(基于它们本文出现的大致顺序)包括:
- search_bing_api.py:此脚本使我们能够快速构建深度学习图像数据集。你不需要运行这段脚本因为图片数据集已经囊括在zip文件中。我附上这段脚本仅为保证(代码的)完整性。
- train.py:一旦我们拥有了数据,我们将应用train.py训练我们的分类器。
- fashion.model:我们的train.py脚本将会将我们的Keras模型保存到磁盘中。我们将在之后的classify.py脚本中用到它。
- mlb.pickle:一个由train.py创建的scikit-learn MultiLabelBinarizer pickle文件——该文件以顺序数据结构存储了各类别名称。
- plot.png:训练脚本会生成一个名为plot.png的图片文件。如果你在你自己的数据集上训练,你便需要查看这张图片以获得正确率/风险函数损失及过拟合情况。
- classify.py:为了测试我们的分类器,我写了classify.py。在你将模型部署于其他地方(如一个iphone的深度学习app或是树莓派深度学习项目)之前,你应该始终在本地测试你的分类器。
本项目中的三个文件夹为:
- dataset:该文件夹包含了我们的图片数据集。每个类别拥有它自己的子文件夹。我们这样做以保证(1)我们的数据在结构上工整有序(2)在给定图片路径后能更容易地提取类别标签名称。
- pyimagesearch:这是装有我们的Keras神经网络的模块。由于这是一个模块,它包含了固定格式的__init__.py。另外一个文件smallervggnet.py,它包含组装神经网络本身的代码。
- examples:该文件夹包含了7个样例图片。我们将基于keras,应用classify.py对每一个样例图片执行多标签分类。
一、数据集准备
数据集包含六个类别的2,167个图像,包括:
黑色牛仔裤(344图像)
蓝色连衣裙(386图像)
蓝色牛仔裤(356图像)
蓝色衬衫(369图像)
红色连衣裙(380图像)
红色衬衫(332图像)
6类图像数据可以通过python爬虫在网站上抓取得到。

为了方便起见,可以通过使用Bing图像搜索API(Microsoft’s Bing Image Search API)建立图像数据,具体配置过程见这里(需要在线注册获得api key,使用key进行图像搜索),创建图片搜索文件search_bing_api.py,代码:
# import the necessary packages
from requests import exceptions
import argparse
import requests
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-q", "--query", required=True,
help="search query to search Bing Image API for")
ap.add_argument("-o", "--output", required=True,
help="path to output directory of images")
args = vars(ap.parse_args())
# set your Microsoft Cognitive Services API key along with (1) the
# maximum number of results for a given search and (2) the group size
# for results (maximum of 50 per request)
API_KEY = "YOUR_API_KEY_GOES_HERE"
MAX_RESULTS = 250
GROUP_SIZE = 50
# set the endpoint API URL
URL = "https://api.cognitive.microsoft.com/bing/v7.0/images/search"
# when attempting to download images from the web both the Python
# programming language and the requests library have a number of
# exceptions that can be thrown so let's build a list of them now
# so we can filter on them
EXCEPTIONS = set([IOError, FileNotFoundError,
exceptions.RequestException, exceptions.HTTPError,
exceptions.ConnectionError, exceptions.Timeout])
# store the search term in a convenience variable then set the
# headers and search parameters
term = args["query"]
headers = {"Ocp-Apim-Subscription-Key" : API_KEY}
params = {"q": term, "offset": 0, "count": GROUP_SIZE}
# make the search
print("[INFO] searching Bing API for '{}'".format(term))
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
# grab the results from the search, including the total number of
# estimated results returned by the Bing API
results = search.json()
estNumResults = min(results["totalEstimatedMatches"], MAX_RESULTS)
print("[INFO] {} total results for '{}'".format(estNumResults,
term))
# initialize the total number of images downloaded thus far
total = 0
# loop over the estimated number of results in `GROUP_SIZE` groups
for offset in range(0, estNumResults, GROUP_SIZE):
# update the search parameters using the current offset, then
# make the request to fetch the results
print("[INFO] making request for group {}-{} of {}...".format(
offset, offset + GROUP_SIZE, estNumResults))
params["offset"] = offset
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
results = search.json()
print("[INFO] saving images for group {}-{} of {}...".format(
offset, offset + GROUP_SIZE, estNumResults))
# loop over the results
for v in results["value"]:
# try to download the image
try:
# make a request to download the image
print("[INFO] fetching: {}".format(v["contentUrl"]))
r = requests.get(v["contentUrl"], timeout=30)
# build the path to the output image
ext = v["contentUrl"][v["contentUrl"].rfind("."):]
p = os.path.sep.join([args["output"], "{}{}".format(
str(total).zfill(8), ext)])
# write the image to disk
f = open(p, "wb")
f.write(r.content)
f.close()
# catch any errors that would not unable us to download the
# image
except Exception as e:
# check to see if our exception is in our list of
# exceptions to check for
if type(e) in EXCEPTIONS:
print("[INFO] skipping: {}".format(v["contentUrl"]))
continue
# try to load the image from disk
image = cv2.imread(p)
# if the image is `None` then we could not properly load the
# image from disk (so it should be ignored)
if image is None:
print("[INFO] deleting: {}".format(p))
os.remove(p)
continue
# update the counter
total += 1
新建一个文件夹dataset:mkdir dataset。然后收集各类图片
mkdir dataset/charmander #换成待收集的图片名,其它的不变
python search_bing_api.py --query "charmander" --output dataset/charmander
[INFO] searching Bing API for 'charmander'
[INFO] 250 total results for 'charmander'
[INFO] making request for group 0-50 of 250...
[INFO] saving images for group 0-50 of 250...
[INFO] fetching: http://fc06.deviantart.net/fs70/i/2012/355/8/2/0004_c___charmander_by_gaghiel1987-d5oqbts.png
[INFO] fetching: http://th03.deviantart.net/fs71/PRE/f/2010/067/5/d/Charmander_by_Woodsman819.jpg
[INFO] fetching: http://fc05.deviantart.net/fs70/f/2011/120/8/6/pokemon___charmander_by_lilnutta10-d2vr4ov.jpg
...
[INFO] making request for group 50-100 of 250...
[INFO] saving images for group 50-100 of 250...
...
[INFO] fetching: http://38.media.tumblr.com/f0fdd67a86bc3eee31a5fd16a44c07af/tumblr_nbhf2vTtSH1qc9mvbo1_500.gif
[INFO] deleting: dataset/charmander/00000174.gif
...
有几类图片执行几遍上面的操作,然后使用find方法得到下载的图像数据数目
find . -type d -print0 | while read -d '' -r dir; do
> files=("$dir"/*)
> printf "%5d files in directory %s\n" "${#files[@]}" "$dir"
> done
2 files in directory .
5 files in directory ./dataset
235 files in directory ./dataset/bulbasaur
245 files in directory ./dataset/charmander
245 files in directory ./dataset/mewtwo
238 files in directory ./dataset/pikachu
230 files in directory ./dataset/squirtle
之后打开下载的数据,进行一些手工剔除不相关的数据。数据制作over。
二、定义多标签分类网络架构smallervggnet
多标签分类网络采用smallervggnet,
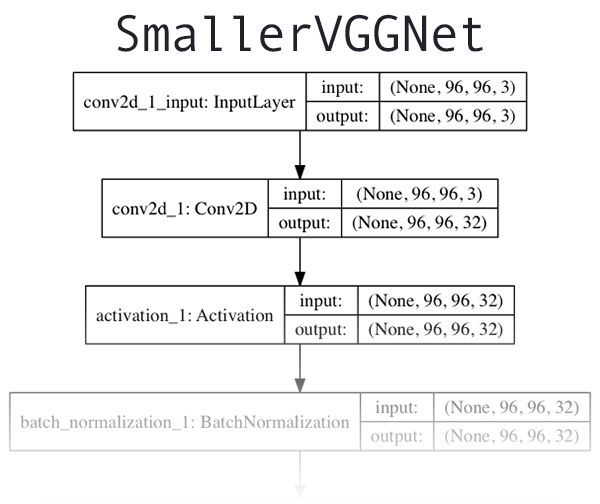
图片2:被我称为“SmallerVGGNet”的类VGGNet神经网络,我们将用它基于Keras训练一个多标签深度学习分类器
其原理见论文传送门。有关架构/代码的长篇大论转移至我之前的一篇文章《Keras and Convolutional Neural Networks (CNNs)》,如果你有任何关于架构的问题或是想要了解更多细节,请参阅参阅该文章。如果你希望设计你自己的模型,可以看:《Deep Learning for Computer Vision with Python》(ps:SCDN上有该资源)
在工程目录下创建python文件,命名为smallervggnet.py
# import the necessary packages
from keras.models import Sequential
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dropout
from keras.layers.core import Dense
from keras import backend as K
#引入了Keras模块并于此开始建立我们的SmallerVGGNet类
class SmallerVGGNet:
@staticmethod
def build(width, height, depth, classes, finalAct="softmax"): #定义构建函数,用于组装卷积神经网络。
#width指定一张输入图片的通道(channels)数量,classes是种类(并不是他们所属的标签)数量(整数)。
#可选参数finalAct(默认值为“softmax”)将会在神经网络底部被应用。将这个值由softmax改为sigmoid将允许我们基于Keras执行多标签分类。
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
# CONV => RELU => POOL
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Dropout(0.25))
# CONV => RELU => POOL
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Dropout(0.25))
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# use a *softmax* activation for single-label classification
# and *sigmoid* activation for multi-label classification
model.add(Dense(classes))
model.add(Activation(finalAct))
# return the constructed network architecture
return model代码说明:
构建第一个CONV ==> RELU ==> POOL模块:
我们的CONV层拥有32个卷积核大小为3×3的滤波器以及RELU(Rectified Linear Unit)激活函数。我们在这之后使用批标准化,最大池化,以及25%的遗忘率(Dropout)。
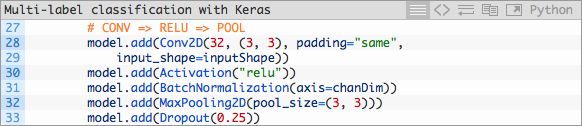
Dropout是一个随机切断当前神经网络层节点与下一神经网络层节点间链接的过程。这个随机断开的过程自然地帮助神经网络降低了过拟合的可能性,得益于没有任何一个节点会被分配以预测某个特定的类别、对象、边缘或是角落。
紧接着我们有两组(CONV ==> RELU)*2 ==> POOL模块:
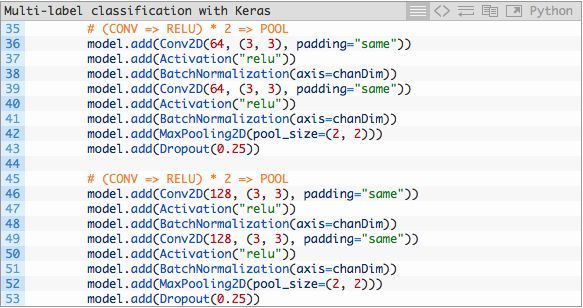
请注意本模块中过滤器、卷积核以及池化大小的变化,这些变化将会共同运作从而逐渐减少空间大小但提升深度(depth)。
这些模块之后是我们唯一的FC ==> RELU层:

全连接层被放置在神经网络的最末端(在第57-64行由Dense声明)。
第65行对于我们的多标签分类非常重要——finalAct指明我们使用的是针对于单标签分类的“softmax”激活函数,还是针对于今天我们提出的多标签分类的sigmoid激活函数。请参考本脚本smallervggnet.py的第14行以及train.py的第95行。
三、实现多标签分类Keras模型
既然我们已经实现了SmallerVGGNet,接下来让我们创建train.py,我们用于训练多标签Keras神经网络的脚本。
我强烈建议你重温一下先前的博文,今天的train.py脚本便是基于该文章。实际上你可能会想要在屏幕上并行查看它们以观测它们之间区别并阅读关于代码的详细解释。今天回顾将简洁明了
打开train.py并插入下述代码:
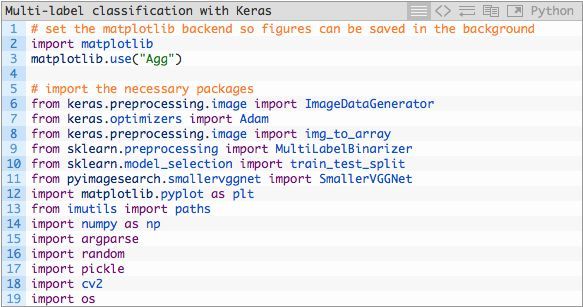
在第2至第19行,我们导入了该脚本所需要的包和模块。第三行指定了一个matplotlib后端,基于此我们可以在后台保存我们所绘制的图片。
我将假定你已经安装了Keras,scikit-learn,matplotlib,imutils以及OpenCV。
如果这是你的深度学习首秀,你有两个选择来确保你拥有正确的库和包:
- 已配置好的环境(你将在5分钟内准备就绪并执行代码,训练今天的这个神经网络的花费将少于一杯星巴克咖啡的价格)。
- 建立你自己的环境(需要时间,耐性以及持久性)。
我更喜欢在云端预先配置好的环境,你能够在云上启动、上传文件、训练+获取数据以及在几分钟之内终止程序。我推荐的两个预先配置好的环境:
- Pre-configured Amazon AWS deep learning AMI with Python
- Microsoft’s data science virtual machine (DSVM) for deep learning
如果你坚持要建立你自己的环境(而且你有时间来调试及问题修复),我建议你遵循下列博文中的一个:
- Configuring Ubuntu for deep learning with Python (CPU only)
- Setting up Ubuntu 16.04 + CUDA + GPU for deep learning with Python (GPU and CPU)
- macOS for deep learning with Python, TensorFlow, and Keras
既然你的环境已经准备就绪,而且你已经导入了相关包,那么让我们解析命令行参数:
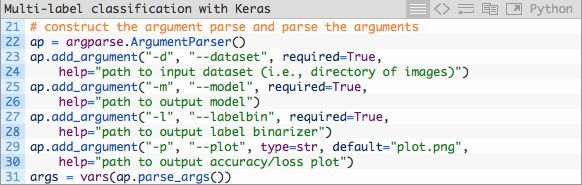
命令行参数之于脚本犹如参数之于函数——如果你不理解这个类比,你需要参阅命令行参数。
我们今天将会处理4个命令行参数:
- --dataset:输入的数据集路径。
- --model:输出的Keras序列模型路径。
- --labelbin:输出的多标签二值化对象路径。
- --plot:输出的训练损失及正确率图像路径。
如果你需要关于这些参数的结束,请务必参阅之前的博文。
让我们进一步讨论一些在我们训练过程中起到至关重要的作用的参数:

在第35-38行的这些参数定义了:
- 我们的神经网络将会训练75轮(epoch),通过反向传播不断提升模型表现从而学习数据背后的模式。
- 我们设置初始学习率为1e-3(Adam优化器的默认值)。
- Batch size是32。如果你拥有GPU,你应该根据你的GPU能力调整这个值,但我发现设置batch size为32能使这个项目执行的非常好。
- 如之前所言,我们的图片大小是96×96并包含3个通道。
之前的博文提供了更多细节。
紧接着,接下来的两个代码模块用于加载及预处理我们的训练数据:
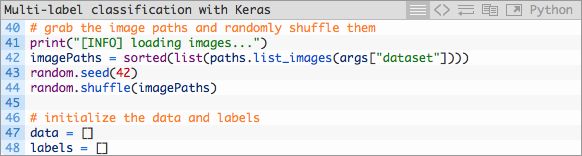
在这里我们获取imagePaths并将它们的顺序随机打乱,随后初始化data和labels数组。
然后我们将循环遍历imagePaths,预处理图像数据并解析多类标签。
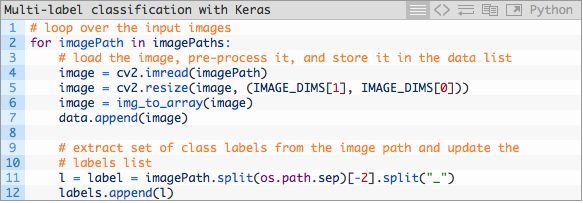
注:该代码的行号出现问题
首先我们将每张图片加载至内存。其次,我们在第54和第55行代码执行预处理(深度学习流水线中的重要一环)。我们将image添加在data的末尾。
第60和第61行针对我们的多标签分类问题将图片路径切分为多个标签。在第60的代码执行之后,一个拥有2个元素的数组被创建,随后在第61行中被添加至labels数据中。如下是一个在终端中经过分解的例子,你能从中了解多标签分词的过程:

如你所见,labels数组是一个“包含数组的数组”——labels中的每个元素都是一个包含两个元素的数组。每个数组对应两个标签这种架构是基于输入图片的文件路径构建的。
继续完成预处理:

我们的data数据由利用Numpy数组存储的图片组成。在每一行代码中,我们将Python数组转换为Numpy数组并将像素值缩放于范围 [0,1] 之中。
我们也将标签转换为Numpy数组。
随后,然我们将标签二值化——下述模块对于本周的多类分类概念十分重要:
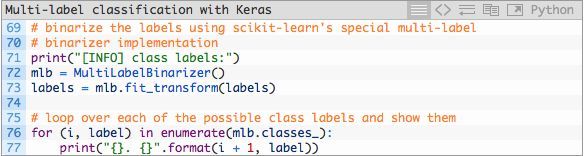
为了能够针对多类分类将标签二值化,我们需要运用scikit-learn库中的MultiLabelBinarizer类。你不能在多类分类问题上用标准的LabelBinarizer类。
第72和第73行代码将人可读的标签转换为包含各类对应编码的向量,该向量根据某类是否在图片中出现来决定对应类的具体值。
这里是一个展现MultiLabelBinarizer如何将(“red”,“dress”)元组转换为一个有6个类别的向量的例子:
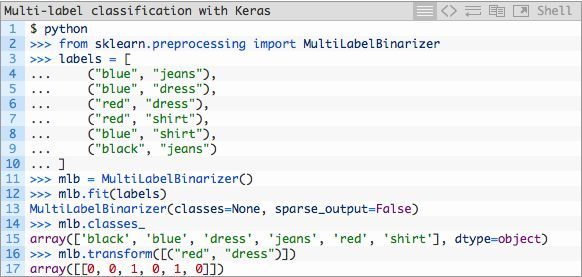
One-hot编码将分类标签由一个整数转换为一个向量。同样的概念可以应用在第16和第17行代码上,除非这是一个two-hot编码。
请注意在Python命令行(为了不与train.py中的代码块混淆)中的第17行,有两个分类标签是“hot”(在数组中用一个“1”表示),表明这各个标签的出现。在本例中,“dress”和“red”在数组中是“hot”(第14至第17行)。其他所有标签的值为“0”。
我们将数据分为训练集和测试集并初始化数据增强器。
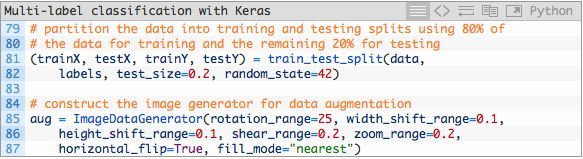
在机器学习实战中,将数据分为训练和测试集是一种很常见的做法——我把80%的图片分配为训练数据,20%为测试数据。这一过程在第81和82行中由scikit-learn进行处理。
我们的数据增强器对象在第85至第87中被初始化。当你的没类数据少于1000张图像时,数据增强是一个最好的实践也或许是一个“必须”的实践。
接下来,让我们建立模型并初始化Adam优化器:

在第92至第95行中,我们构建SmallerVGGNet模型,finalAct=”sigmoid”这个参数指明我们将执行多标签分类。
随后,我们将编译模型并开始训练(取决于你的硬件,这可能会需要一段时间):
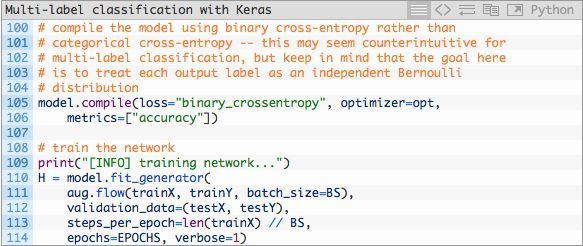
在第105行和第106行中,我们编译模型并使用二元交叉熵而不是类别交叉熵。
对于多标签分类问题,这可能看起来有些违背了直觉;然而,目标是将每个输出标签视作一个独立伯努利分布,而且我们需要独立地惩罚每个输出节点。
随后我们启动运用了数据增强生成器的训练过程(第110-114行)。
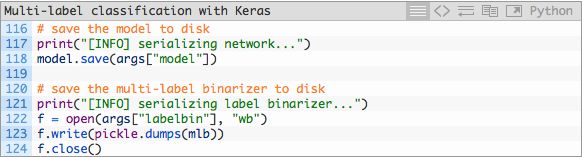
在完成训练之后我们可以将模型和标签二值化器储存至磁盘:
随后,我们绘制正确率及损失:
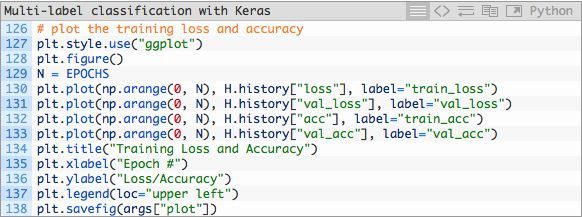
训练和验证的准确率+损失在第127-137行代码中绘画。该图片在第138行中被保存为一个图片文件。
在我看来,训练图像的绘制就跟模型本身一样重要。在我们满意并在博客上与你们分享之前,我通常会执行训练的几个迭代周期并查看图像是否无误。
在迭代过程中我喜欢讲图片存至硬盘上出于几个原因:
- 我在一个无界面的后台服务器上运行代码,也并不想依赖于X-forwarding
- 我不想忘记保存图片(即使我正在使用X-forwarding或是我正使用一个拥有图形化界面的机器)。
回想我们在上面将脚本的第三行改变了matplotlib的后端,就是为了帮助我们将图片储存至硬盘上。
train.py
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from keras.preprocessing.image import img_to_array
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.model_selection import train_test_split
from pyimagesearch.smallervggnet import SmallerVGGNet
import matplotlib.pyplot as plt
from imutils import paths
import numpy as np
import argparse
import random
import pickle
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset (i.e., directory of images)")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
ap.add_argument("-l", "--labelbin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
# initialize the number of epochs to train for, initial learning rate,
# batch size, and image dimensions
EPOCHS = 75
INIT_LR = 1e-3
BS = 32
IMAGE_DIMS = (96, 96, 3)
# grab the image paths and randomly shuffle them
print("[INFO] loading images...")
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
# initialize the data and labels
data = []
labels = []
# loop over the input images
for imagePath in imagePaths:
# load the image, pre-process it, and store it in the data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (IMAGE_DIMS[1], IMAGE_DIMS[0]))
image = img_to_array(image)
data.append(image)
# extract set of class labels from the image path and update the
# labels list
l = label = imagePath.split(os.path.sep)[-2].split("_")
labels.append(l)
四、训练模型
打开终端。在那里,打开项目路径并执行如下命令:
python train.py --dataset dataset --model fashion.model --labelbin mlb.pickle
出现下图
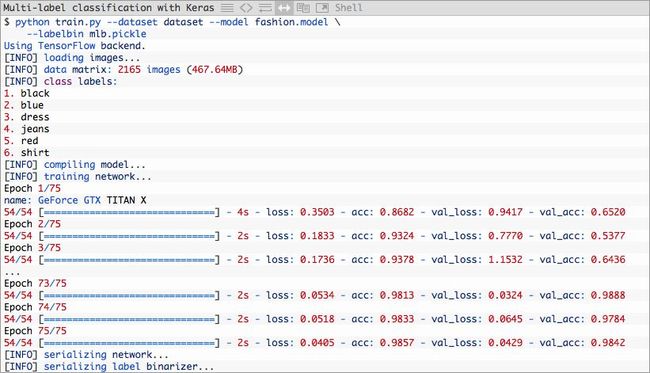
如你所见,我们将模型训练了75个epoch,实现了:
- 98.57% 训练集上的多标签分类正确率
- 98.42% 测试集上的多标签分类正确率
训练图在图3中展示:
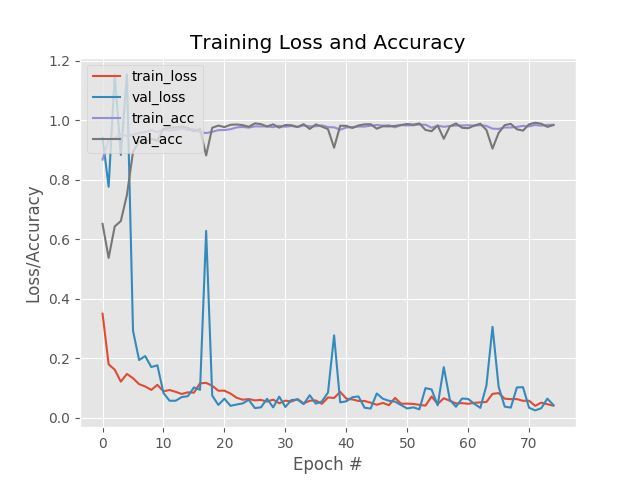
图3:Keras深度学习多标签分类在训练集和测试集中的正确率/损失。
五、使用训练完成的模型预测新的图像
创建名为classify.py的文件并加入如下代码
# import the necessary packages
from keras.preprocessing.image import img_to_array
from keras.models import load_model
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained model model")
ap.add_argument("-l", "--labelbin", required=True,
help="path to label binarizer")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# 加载图片
image = cv2.imread(args["image"])
output = imutils.resize(image, width=400)
# 预处理输入图片(使用与训练数据相同的标准)
image = cv2.resize(image, (96, 96))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
# 加载模型+多标签二值化器并将图片分类。从磁盘将模型和多标签二值化器加载至内存中。
print("[INFO] loading network...")
model = load_model(args["model"])
mlb = pickle.loads(open(args["labelbin"], "rb").read())
# 分类(经过预处理的)图片并通过
#(1)基于相关概率将数组索引按降序排序
#(2)获取前两个类标签的索引,这便是我们的神经网络所作出的最好的两个预测
#方式解析出相关性最大的前两个类的标签索引:
#可以通过修改这段代码以返回更多的类标签。我也建议你对概率设置阈值,并且只返回那些置信程度 > N%的标签。
print("[INFO] classifying image...")
proba = model.predict(image)[0]
idxs = np.argsort(proba)[::-1][:2]
# 对每一个输出图像准备类标签+相关的置信值,该for循环将可能性最大的两个多标签预测及相应的置信值绘制在输出图片上
for (i, j) in enumerate(idxs):
# build the label and draw the label on the image
label = "{}: {:.2f}%".format(mlb.classes_[j], proba[j] * 100)
cv2.putText(output, label, (10, (i * 30) + 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
#将所有的预测打印在终端上。这对于调试过程非常有用
for (label, p) in zip(mlb.classes_, proba):
print("{}: {:.2f}%".format(label, p * 100))
# 在屏幕上显示输出图片
cv2.imshow("Output", output)
cv2.waitKey(0)
用命令行运行测试文件,最终显示出预测的分类结果
python classify.py --model fashion.model --labelbin mlb.pickle --image examples/example_01.jpg
结果:
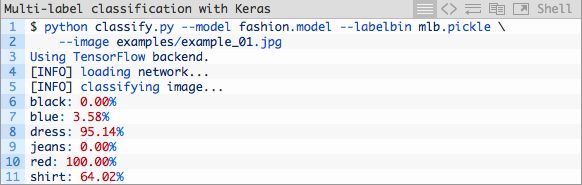

图片4:这张红色裙子的照片被我们的Keras多标签分类深度学习脚本由分类器正确分为“红色”和“裙子”。
总结:
使用Keras执行多标签分类非常简单,包括两个主要步骤:
- 1.使用sigmoid激活替换网络末端的softmax激活
- 2.二值交叉熵作为分类交叉熵损失函数
shortcomings:
网络无法预测没有在训练集中出现过的数据样品,如果出现的次数过少,预测的效果也不会很好,解决办法是增大数据集,这样可能非常不容易,还有一种用的已经很多的方法用在大的数据集上训练得到的权重数据对网络做初始化,提高模型的泛化能力。
参考:
【1】Multi-label classification with Keras(原文)
【2】手把手教你用Keras进行多标签分类(附代码)(原文翻译)
【3】基于keras实现多标签分类(multi-label classification)(完整代码)