集成学习任务七和八、投票法与bagging学习
文章目录
-
-
- 一、投票法
-
- 1.1 投票法概述
- 1.2 投票法分类
- 1.3 使用场景
- 1.4 投票法的案例分析
- 二、bagging的思路
-
- 2.1 bagging概述
- 2.2 bagging的案例分析
-
一、投票法
1.1 投票法概述
Bagging是Bootstrap Aggregating的英文缩写,他bagging不在是一种算法了,Bagging和Boosting都是集成学习中的学习框架,代表着两种不同的思想。
-
boosting,它的特点是各个弱学习器之间有依赖关系。(先后顺序)
-
bagging(装袋),它的特点是各个弱学习器之间没有依赖关系,可以并行拟合。(并行)
下面我们来简单说明一下
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性(算法对数据变化的容忍度有多高)。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
1.2 投票法分类
投票法在回归模型与分类模型上均可使用我们可以分为:
- 回归投票法:预测结果是所有模型预测结果的平均值、中位数啥的。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
分类投票法又可以被划分为硬投票与软投票:
- 硬投票:预测结果是所有投票结果最多出现的类(众数)。
- 软投票:预测结果是所有投票结果中概率加和最大的类(平均概率)。
下面我们使用一个例子说明
硬投票:
对于某个样本:
模型 1 的预测结果是 类别 A
模型 2 的预测结果是 类别 B
模型 3 的预测结果是 类别 B
有2/3的模型预测结果是B,因此硬投票法的预测结果是B
同样的例子说明软投票:
对于某个样本:
模型 1 的预测结果是 类别 A 的概率为 99%
模型 2 的预测结果是 类别 A 的概率为 49%
模型 3 的预测结果是 类别 A 的概率为 49%
最终对于类别A的预测概率的平均是 (99 + 49 + 49) / 3 = 65.67%,因此软投票法的预测结果是A。
从上面我们是可以看出相对于硬投票,soft考虑到了预测概率这一额外的信息,因此可以得出比hard更加准确的预测结果。
在投票法中,我们还需要考虑到不同的基模型可能产生的影响。理论上,基模型可以是任何已被训练好的模型。但在实际应用上,想要投票法产生较好的结果,需要满足两个条件:
- 1、基模型之间的效果不能差别过大。
当某个基模型相对于其他基模型效果过差时,该模型很可能成为噪声。 - 2、基模型之间应该有较小的同质性。
例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型。
1.3 使用场景
1、当投票合集中使用的模型能预测出清晰的类别标签时,适合使用硬投票。
2、当投票集合中使用的模型能预测类别的概率时,适合使用软投票。
软投票同样可以用于那些本身并不预测类成员概率的模型,只要他们可以输出类似于概率的预测分数值(例如支持向量机、k-最近邻和决策树)。
投票法的局限性在于,它对所有模型的处理是一样的,这意味着所有模型对预测的贡献是一样的。如果一些模型在某些情况下很好,而在其他情况下很差,这是使用投票法时需要考虑到的一个问题。
1.4 投票法的案例分析
Sklearn中提供了 VotingRegressor 与 VotingClassifier 两个投票方法。这两种模型的操作方式相同,并采用相同的参数。使用模型需要提供一个模型列表,列表中每个模型采用Tuple的结构表示,第一个元素代表名称,第二个元素代表模型,需要保证每个模型必须拥有唯一的名称。
例如这里,我们定义两个模型:
- 导入需要的库
# 导入需要的库
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import RepeatedStratifiedKFold
from numpy import mean,std
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models)
models = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))]
ensemble = VotingClassifier(estimators=models)
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models, voting='soft')
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2)
# summarize the dataset
return X,y
- 定义五个knn(k-近邻算法)(easy实现)
# get a voting ensemble of models
def get_voting():
# define the base models
models = list()
models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))
# define the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='hard')
return ensemble
# get a list of models to evaluate
def get_models():
models = dict()
models['knn1'] = KNeighborsClassifier(n_neighbors=1)
models['knn3'] = KNeighborsClassifier(n_neighbors=3)
models['knn5'] = KNeighborsClassifier(n_neighbors=5)
models['knn7'] = KNeighborsClassifier(n_neighbors=7)
models['knn9'] = KNeighborsClassifier(n_neighbors=9)
models['hard_voting'] = get_voting()
return models
# evaluate a give model using cross-validation
from sklearn.model_selection import cross_val_score #Added by ljq
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores
from sklearn.neighbors import KNeighborsClassifier
from matplotlib import pyplot
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
>knn1 0.873 (0.030)
>knn3 0.889 (0.038)
>knn5 0.895 (0.031)
>knn7 0.899 (0.035)
>knn9 0.900 (0.033)
>hard_voting 0.902 (0.034)
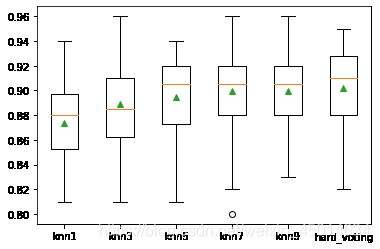
显然投票的效果略大于任何一个基模型
通过箱形图我们可以看到硬投票方法对交叉验证整体预测结果分布带来的提升。
二、bagging的思路
2.1 bagging概述
bagging即装袋法,先说一下bootstrap,bootstrap也称为自助采样法,它是一种有放回的抽样方法,目的为了得到统计量的分布以及置信区间,其算法过程如下:
A)从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
B)每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
C)对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
Bagging同样是一种降低方差的技术,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更加明显。在实际的使用中,加入列采样的Bagging技术对高维小样本往往有神奇的效果。
2.2 bagging的案例分析
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15,
n_redundant=5, random_state=5)
# summarize the dataset
print(X.shape, y.shape)
(1000, 20) (1000,)
# evaluate bagging algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import BaggingClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# define the model
model = BaggingClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
Accuracy: 0.868 (0.033)
最终模型的效果是Accuracy: 0.856 标准差0.037
最后,之前提到的投票法的多个模型的集成降低方差,个人理解就是方差就是数值的差别,我们的值少数服从多数,其中的值也就减小了,而这样数值的差别也就是减小了。