一文速学-Pandas处理缺失值操作各类方法详解
前言
匆忙之间在CSDN上连载博客已有三年之久,现在已临近毕业。回顾大学的四年尽是不甘,意难平。有时反思良久,或许是我对自己的定位还不够明确,还不知道自己想要的是如此模糊,也许接受现实是对理想主义者最大的冲击。
以上是博主突然有感而言,现在回归博客主题。
使用Pandas进行数据预处理时需要了解Pandas的基础数据结构Series和DataFrame。若是还不清楚的可以再去看看我之前的三篇博客详细介绍这两种数据结构的处理方法:
一文速学-数据分析之Pandas数据结构和基本操作代码
DataFrame行列表查询操作详解+代码实战
DataFrame多表合并拼接函数concat、merge参数详解+代码操作展示
以上三篇很容易学会,没有比较难的实战。此篇博客基于Jupyter之上进行演示,本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用,而且能够记录到你的思想之中。当然个人不是数学专业对一些专业性的知识可能不是很了解,希望读者看完能够提出错误或者看法,博主会长期维护博客做及时更新。纯分享,希望大家喜欢。
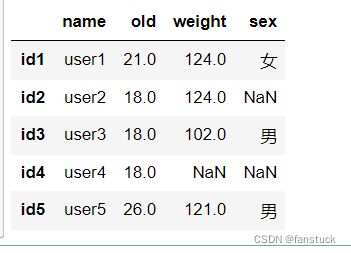
此博客用到的数据集为:
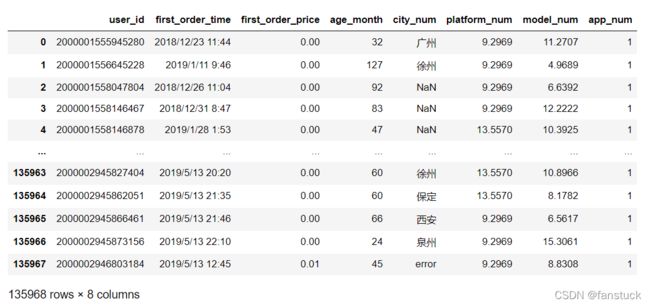
缺失值处理
1.计数
isnull函数可以显示为空的值,使用False和True替换原数据集
df1.isnull()
一般在加上sum()统计各个特征空值数:
df1.isnull().sum()
计数空值的话也可以通过info()函数对比其他列相减得到空值个数:
df1.info() 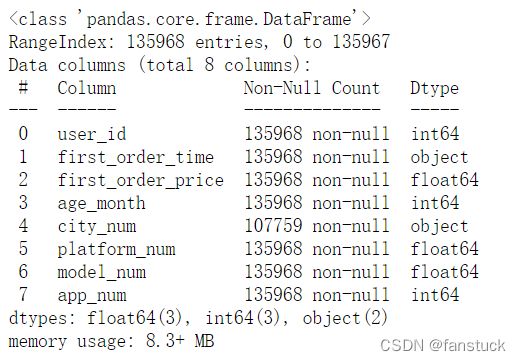
135968-107759=28209就是空值的个数。
2.筛选
检测完毕后可以我们可以筛选出没有空值的行数据:
df1.loc[df1['city_num'].notnull(),:]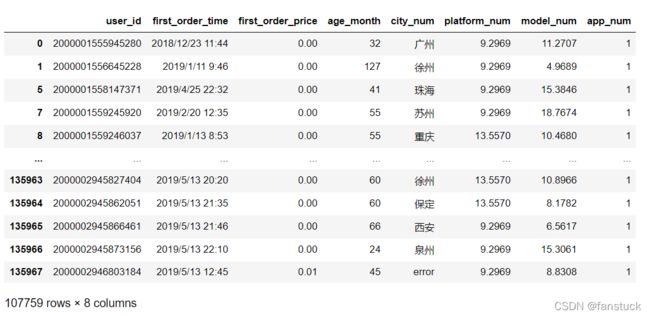
也可以使用dropna()函数对空值进行删除:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)参数说明:
- axis:指定的轴,默认为0也就是参照对每行进行操作,1就为列。
- how:可以为any也可以为all,对整体或者部分进行操作。
- thresh:一行或一列中至少出现了多少个空值才删除。
- subset:在某些列的子集中选择出现了缺失值的列删除,不在子集中的含有缺失值得列或行不会删除(有axis决定是行还是列)
- inplace:是否替换原数据集。
df1.dropna(axis=0,how='any',inplace=False)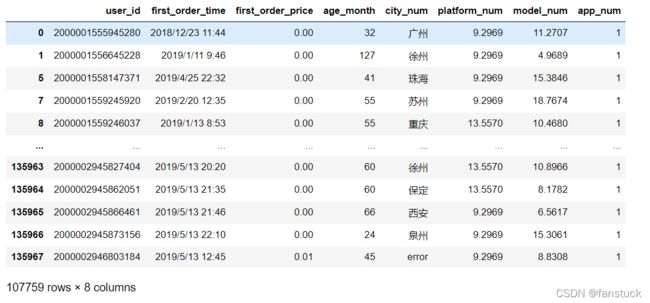
3.填充
关于填充上偏文章有讲述过fillna()函数可以将空值统一替换为想要的数值(也可以设定为均值填充dataFrame.mean(),inplace = True、向上填充method=‘ffill’、向下填充method=‘bfill’、对应值填充df.replace({np.nan:‘aa’}))
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)参数说明:
- value:将空值替换成任意设定的值
- method:method参数的取值 : {‘pad’, ‘ffill’,‘backfill’, ‘bfill’, None}, default None
- ffill:用缺失值前面的一个值代替缺失值,如果axis =1,那么就是横向的前面的值替换后面的缺失值,如果axis=0,那么则是上面的值替换下面的缺失值。backfill/bfill,缺失值后面的一个值代替前面的缺失值。注意这个参数不能与value同时出现。
- 向上填充method=‘ffill’、向下填充method=‘bfill’,
- axis:指定改变的轴,默认为0也就是对每行操作。
- inplace:是否替换原数据集。
- limit参数:限制填充个数。
为方便展示这里另外创建数据集:

例如我想把年龄为空值的数据替换为10:
df2.loc[:,'old'].fillna(value=10,inplace=True) 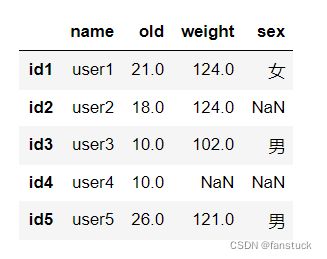
填充为上一个数据:
df2.loc[:,'old'].fillna(method='ffill',inplace=True)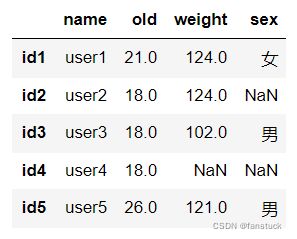
向下填充数据:
df2.loc[:,'old'].fillna(method='bfill',inplace=True)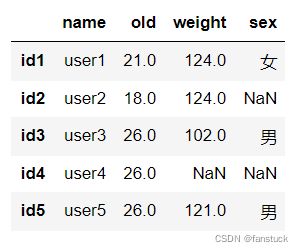
填充为均值:
df2.loc[:,'old'].fillna(value=df2.loc[:,'old'].mean(),inplace=True) 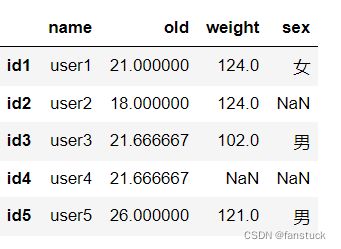
填充为众数:
df2.loc[:,'old'].fillna(value=df2.loc[:,'old'].median(),inplace=True)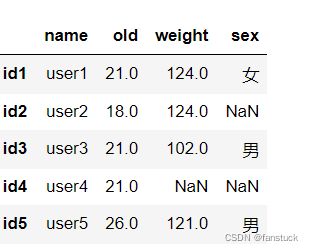
填充为最大值:
df2.loc[:,'old'].fillna(value=df2.loc[:,'old'].max(),inplace=True) 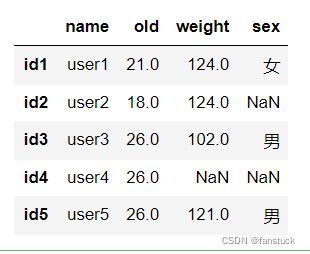
填充为最小值:
df2.loc[:,'old'].fillna(value=df2.loc[:,'old'].min(),inplace=True)