R语言数据分析从入门到高级:(八)数据清洗技巧之数据格式转换(包含宽数据与长数据之间的转换)
R语言数据分析从入门到高级
- 个人主页:JoJo的数据分析历险记
- 个人介绍:小编大四统计在读,目前保研到统计学top3高校继续攻读统计研究生
- 如果文章对你有帮助,欢迎关注、点赞、收藏、订阅专栏
本系列主要介绍R语言在数据分析领域的应用包括:
R语言编程基础、R语言可视化、R语言进行数据操作、R语言建模、R语言机器学习算法实现、R语言统计理论方法实现。本系列会完成下去,请大家多多关注点赞支持,一起学习~
参考资料:
Data Analysis and Prediction Algorithms with R
文章目录
- R语言数据分析从入门到高级
- R语言数据分析从入门到高级:(八)数据清洗技巧之数据格式转换
-
- 8.1 pivot_longer函数
- ️8.2 poivot_wider
- 8.3 seperate函数
- 8.4 unite函数
- ✨相关文章推荐
R语言数据分析从入门到高级:(八)数据清洗技巧之数据格式转换
正如我们之前介绍的,我们希望在R语言中希望数据是tidy形式的(具体大家可以看该专栏的第三篇文章)。在数据分析流程中,第一步是将数据导入,第二步往往就是对数据格式进行转换成tidy数据以便于后续分析。R语言tidyverse可以帮助我们实现这个目的。
首先导入我们相关库和数据,运用了我们在该专栏第四章介绍的数据导入、复制等技巧,不理解的小伙伴可以先看之前的文章,如果报错显示没有相关库,先使用
install.packages(‘tidyverse’)
install.packages(‘dslabs’)
library(tidyverse)
library(dslabs)
path <- system.file('extdata', package='dslabs')
filename <- file.path(path, 'fertility-two-countries-example.csv')
wide_data <- read_csv(filename)
head(wide_data)
| country | 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | 1966 | 1967 | 1968 | ... | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ... | ||||||||||||||||||||
| Germany | 2.41 | 2.44 | 2.47 | 2.49 | 2.49 | 2.48 | 2.44 | 2.37 | 2.28 | ... | 1.36 | 1.36 | 1.37 | 1.38 | 1.39 | 1.40 | 1.41 | 1.42 | 1.43 | 1.44 |
| South Korea | 6.16 | 5.99 | 5.79 | 5.57 | 5.36 | 5.16 | 4.99 | 4.85 | 4.73 | ... | 1.20 | 1.21 | 1.23 | 1.25 | 1.27 | 1.29 | 1.30 | 1.32 | 1.34 | 1.36 |
该数据包含德国和韩国不同年份的生育率,可以看出这个数据不服从tidy数据格式,我们希望将这些不同年份作为一个变量来表示,下面我们来看看具体是怎么操作的
8.1 pivot_longer函数
tidyverse中用的最多的函数之一就是pivot_longer,可以将宽数据转换为tidy格式的数据
与tidyverse其他大多数函数一样,pivot_longer第一个参数也是要转换的数据框,这里我们将
wide_data数据框输入,我们希望将其转换为一行代表一个国家某一年份的一个数据。
而在当前形式中,不同年份的数据位于不同的列中,列名称中有年份。
通过names_to和values_to参数,我们将分别指定给包含当前列名和观察值的列的列名。
如果不指定参数,默认的名字是name和value,在这里我们使用year和fertility。
通过第二个参数col指定我们想要转换的列.
new_tidy_data <- wide_data %>%
pivot_longer(cols = `1960`:`2015`,names_to = "year", values_to = "fertility")
head(new_tidy_data)
| country | year | fertility |
|---|---|---|
| Germany | 1960 | 2.41 |
| Germany | 1961 | 2.44 |
| Germany | 1962 | 2.47 |
| Germany | 1963 | 2.49 |
| Germany | 1964 | 2.49 |
| Germany | 1965 | 2.48 |
我们可以看到,数据已转换为整齐的tidy格式,包含年份和生育率,并且每一年都有两行数据,因为我们有两个国家,因此在这里我们没有将country列进行转换,所有我们也可以使用简化使用下面的代码得到同样的结果
new_tidy_data <- wide_data %>%
pivot_longer(-country, names_to = "year", values_to = "fertility")
head(new_tidy_data)
| country | year | fertility |
|---|---|---|
| Germany | 1960 | 2.41 |
| Germany | 1961 | 2.44 |
| Germany | 1962 | 2.47 |
| Germany | 1963 | 2.49 |
| Germany | 1964 | 2.49 |
| Germany | 1965 | 2.48 |
指的注意的一点是,pivot_longer函数假定列名是字符串的形式,我们来检查一下
class(new_tidy_data$year)
‘character’
因此,如果我们想要进行绘图,首先需要将年份这个变量值转换为数值型变量,可以使用as.interger
new_tidy_data <- wide_data %>%
pivot_longer(-country, names_to = "year", values_to = "fertility") %>%
mutate(year = as.integer(year))
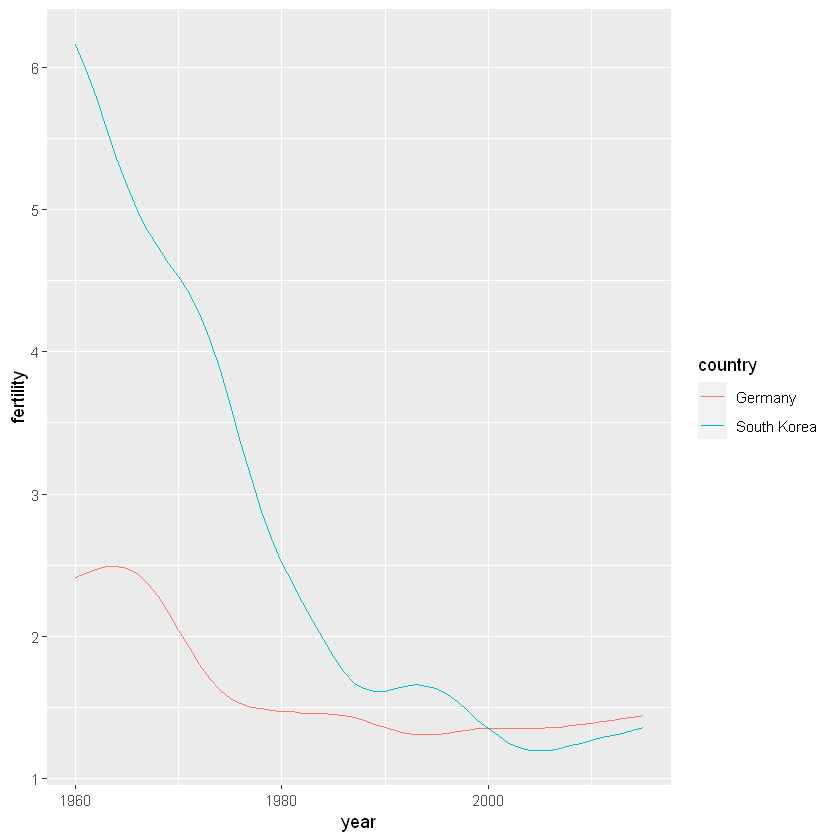
注意我们使用了mutate()函数,这也是我们在第三章所介绍的。现在我们可以使用该数据进行简单的绘图,例如我们要绘制年份和生育率的散点图,并以颜色进行分组
new_tidy_data %>% ggplot(aes(year, fertility, color = country)) +
geom_line()
️8.2 poivot_wider
有时将tidy数据转换为宽数据对于数据清洗非常有用。我们通常将此作为整理数据的中间步骤。pivot_Wider函数基本上与pivot_longer函数相反。第一个参数是关于数据框,参数names_from告诉哪个变量将用作列名。values_from指定使用哪些变量值填充单元格的值。默认参数值为name和value,如下图所示,我们想要展示1960-1967年两个国家的生育率数据
new_wide_data <- new_tidy_data %>%
pivot_wider(names_from = year, values_from = fertility)
select(new_wide_data, country, `1960`:`1967`)
| country | 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | 1966 | 1967 |
|---|---|---|---|---|---|---|---|---|
| Germany | 2.41 | 2.44 | 2.47 | 2.49 | 2.49 | 2.48 | 2.44 | 2.37 |
| South Korea | 6.16 | 5.99 | 5.79 | 5.57 | 5.36 | 5.16 | 4.99 | 4.85 |
用法基本与poivot_longer相似,大家可以进行相互转换练习。
8.3 seperate函数
上面的数据清洗和实际中相比可能相对简单。接下来我们将介绍一些更复杂的情况。该数据集包含两个变量:预期寿命和生育率。如下所示,该数据不是tidy格式
path <- system.file("extdata", package = "dslabs")
filename <- "life-expectancy-and-fertility-two-countries-example.csv"
filename <- file.path(path, filename)
raw_dat <- read_csv(filename)
select(raw_dat, 1:5)
| country | 1960_fertility | 1960_life_expectancy | 1961_fertility | 1961_life_expectancy |
|---|---|---|---|---|
| Germany | 2.41 | 69.26 | 2.44 | 69.85 |
| South Korea | 6.16 | 53.02 | 5.99 | 53.75 |
首先,注意这个数据也是宽数据格式,但是这个数据框包含两个变量的值,生育率和预期寿命。使用列名来表示哪个列代表哪个变量。即便我们强烈不建议在列名中对信息进行编码,但实际上这很常见。
接下来我们运用数据清洗技术来提取这些信息,并以tidy的形式保存数据。
第一步,我们照样可以先试用pivot_longer函数,将数据转换为长格式。但是这里我们的名字不能命名为year,这里我们使用默认的参数
dat <- raw_dat %>% pivot_longer(-country)
head(dat)
| country | name | value |
|---|---|---|
| Germany | 1960_fertility | 2.41 |
| Germany | 1960_life_expectancy | 69.26 |
| Germany | 1961_fertility | 2.44 |
| Germany | 1961_life_expectancy | 69.85 |
| Germany | 1962_fertility | 2.47 |
| Germany | 1962_life_expectancy | 70.01 |
结果并不完全是我们所说的tidy格式,因为每个观测数据都与两行相关,而不是一行。我们希望将生育率和预期寿命这两个变量的值分为两列。实现这一点的第一步是将名称列分为年份和变量类型。请注意,在本例中是使用下划线将年份与变量名隔开。
在一个列名中编码多个变量是一个常见的问题,readr包包含一个将这些列分隔为两个或更多列的函数。除了数据之外,separate函数还有三个参数:要分隔的列的名称、用于新列的名称以及分隔变量的字符。因此,第一步代码如下:
dat %>% separate(name, c("year", "name"), "_") %>% head()
| country | year | name | value |
|---|---|---|---|
| Germany | 1960 | fertility | 2.41 |
| Germany | 1960 | life | 69.26 |
| Germany | 1961 | fertility | 2.44 |
| Germany | 1961 | life | 69.85 |
| Germany | 1962 | fertility | 2.47 |
| Germany | 1962 | life | 70.01 |
由于因为_是separate假定的默认分隔符,所以我们不必在代码中包含它
dat %>% separate(name, c('year','name')) %>% head()
| country | year | name | value |
|---|---|---|---|
| Germany | 1960 | fertility | 2.41 |
| Germany | 1960 | life | 69.26 |
| Germany | 1961 | fertility | 2.44 |
| Germany | 1961 | life | 69.85 |
| Germany | 1962 | fertility | 2.47 |
| Germany | 1962 | life | 70.01 |
该函数确实会分离这些值,但我们遇到了一个新问题。预期寿命变量被截断为寿命。这是因为_用于区分寿命和预期寿命,而不仅仅是年份和变量名称。我们可以添加第三列来解决这一点,并让单独的函数知道在没有第三个值的情况下,用NA填充那一列。
var_names <- c("year", "first_variable", "second_variable")
dat %>% separate(name, var_names, fill = "right")%>%head()
| country | year | first_variable | second_variable | value |
|---|---|---|---|---|
| Germany | 1960 | fertility | NA | 2.41 |
| Germany | 1960 | life | expectancy | 69.26 |
| Germany | 1961 | fertility | NA | 2.44 |
| Germany | 1961 | life | expectancy | 69.85 |
| Germany | 1962 | fertility | NA | 2.47 |
| Germany | 1962 | life | expectancy | 70.01 |
我们还有一种更好的方式是使用extra参数,在有额外间隔时合并最后两个变量,如下所示
dat %>% separate(name, c("year", "name"), extra = "merge")%>%head()
| country | year | name | value |
|---|---|---|---|
| Germany | 1960 | fertility | 2.41 |
| Germany | 1960 | life_expectancy | 69.26 |
| Germany | 1961 | fertility | 2.44 |
| Germany | 1961 | life_expectancy | 69.85 |
| Germany | 1962 | fertility | 2.47 |
| Germany | 1962 | life_expectancy | 70.01 |
接下来我们可以再使用之前介绍的pivot_wider()函数,为每个变量创建一列
dat %>%
separate(name, c("year", "name"), extra = "merge")%>%
pivot_wider(names_from = name, values_from = value)%>%head()
| country | year | fertility | life_expectancy |
|---|---|---|---|
| Germany | 1960 | 2.41 | 69.26 |
| Germany | 1961 | 2.44 | 69.85 |
| Germany | 1962 | 2.47 | 70.01 |
| Germany | 1963 | 2.49 | 70.10 |
| Germany | 1964 | 2.49 | 70.66 |
| Germany | 1965 | 2.48 | 70.65 |
现在数据是tidy格式,每个观测值有一行,包含四个列变量:国家、年份、生育率和预期寿命。
8.4 unite函数
有时,将两列分开并合并为一列是很有用的。为了演示如何使用unite,假设我们不适用extra参数,我们可以使用以下代码进行合并,这些代码可能不是最佳方法,但可以作为一个示例。
依然用刚刚的dat数据
var_names <- c("year", "first_variable_name", "second_variable_name")
dat %>%
separate(name, var_names, fill = "right")%>%head()
| country | year | first_variable_name | second_variable_name | value |
|---|---|---|---|---|
| Germany | 1960 | fertility | NA | 2.41 |
| Germany | 1960 | life | expectancy | 69.26 |
| Germany | 1961 | fertility | NA | 2.44 |
| Germany | 1961 | life | expectancy | 69.85 |
| Germany | 1962 | fertility | NA | 2.47 |
| Germany | 1962 | life | expectancy | 70.01 |
我们可以通过合并第二列和第三列,然后旋转这些列并将fertility_NA重命名为fertility,来获得相同的最终结果:
dat %>%
separate(name, var_names, fill = "right") %>%
unite(name, first_variable_name, second_variable_name) %>%
pivot_wider() %>%head()
rename(fertility = fertility_NA)%>%head()
| country | year | fertility_NA | life_expectancy |
|---|---|---|---|
| Germany | 1960 | 2.41 | 69.26 |
| Germany | 1961 | 2.44 | 69.85 |
| Germany | 1962 | 2.47 | 70.01 |
| Germany | 1963 | 2.49 | 70.10 |
| Germany | 1964 | 2.49 | 70.66 |
| Germany | 1965 | 2.48 | 70.65 |
✨相关文章推荐
R语言数据分析从入门到高级:(三)数据基础处理(mutate、filter、select等)
R语言数据分析从入门到高级:(四)文件读取、导入和复制