机器学习(五):朴素贝叶斯
朴素贝叶斯
- 1. 关于朴素贝叶斯
- 2.朴素贝叶斯
-
- 2.1 贝叶斯决策理论
- 2.2 条件概率
-
- 2.2.1 贝叶斯准则
- 3. 文本分类
-
- 3.1 从文本中构建词向量
- 3.2 计算概率
- 3.3 使用分类器分类
- 3.3 文档词袋模型
- 4. 示例:使用朴素贝叶斯过滤垃圾邮件
- 5. 课外例子
- 6. 总结
1. 关于朴素贝叶斯
朴素贝叶斯算法是有监督的学习,目的是解决分类问题。朴素贝叶斯的优点是简单易懂,学习效率高,在数据较少的情况下仍然有效,可以处理多类别问题
2.朴素贝叶斯
2.1 贝叶斯决策理论
朴素贝叶斯是贝叶斯决策理论的一部分,所以现在让我们来了解一下贝叶斯决策理论。
我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中红色圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中蓝色三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
- 如果p1(x,y)>p2(x,y),那么类别为1
- 如果p1(x,y)

贝叶斯决策理论的核心思想是:选择具有最高概率的决策
2.2 条件概率
![]()
2.2.1 贝叶斯准则
已知P(x | c)求P(c | x)可用如下公式:

3. 文本分类
进行文本分类时,我们需要先从文本中获得特征,那么我们就需要先拆分文本。文本的特征指的是来自文本的词条,一个词条是字符的任意组合。
3.1 从文本中构建词向量
代码:
def loadDataSet():
postingList = [['my','dog','has','flea','problems','help','please'],
['maybe','not','take','him','to','dog','park','stupid'],
['my','dalmation','is','so','cute','I','love','him'],
['stop','posting','stupid','worthless','garbage'],
['mr','licks','ate','my','steak','how','to','stop','him'],
['quit','buying','worthless','dog','food','stupid']
]
classVec = [0,1,0,1,0,1]
return postingList,classVec
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) #取并集
return list(vocabSet)
def setOfWords2Vec(vocabList,inputSet):
returnVec = [0]*len(vocabList) #创建一个所含元素都为0的向量
for word in inputSet: #遍历每个词条
if word in vocabList: #如果存在词汇表中则智1
returnVec[vocabList.index(word)] = 1
else: print("this word:%s is not in my Vocabulary!" % word)
return returnVec
if __name__ == '__main__':
postingList,classVec = loadDataSet()
print("postingList:\n",postingList)
myVocabList = createVocabList(postingList)
print('myVocabList:\n',myVocabList)
trainMat = []
for postingLIst in postingList:
trainMat.append(setOfWords2Vec(myVocabList,postingLIst))
print('trainMat:\n',trainMat)
结果:

![]()
3.2 计算概率
代码:
def trainNBO(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = np.zeros(numWords); p1Num = np.zeros(numWords)
p0Denom = 0.0;p1Denom = 0.0
for i in range(numTrainDocs):
if trainCategory[i] ==1:
p1Num += trainMatrix[i]
p1Denom +=sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom
p0Vect = p0Num/p0Denom
return p0Vect,p1Vect,pAbusive
if __name__ == '__main__':
postingList,classVec = loadDataSet()
myVocabList = createVocabList(postingList)
print('myVocabList:\n',myVocabList)
trainMat = []
for postingLIst in postingList:
trainMat.append(setOfWords2Vec(myVocabList,postingLIst))
# print('trainMat:\n',trainMat)
p0V,p1V,pAb = trainNBO(trainMat,classVec)
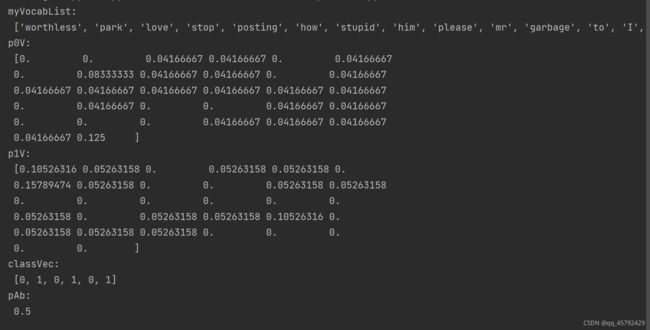
print('p0V:\n',p0V)
print('p1V:\n', p1V)
print('classVec:\n', classVec)
print('pAb:\n', pAb)
结果:
结果如下,p0V存放的是每个单词属于类别0,也就是非侮辱类词汇的概率,p1V存放的是侮辱类词汇的概率,pAb是所有侮辱类的样本占所有样本的概率
3.3 使用分类器分类
代码:
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1 = reduce(lambda x,y:x*y,vec2Classify * p1Vec)*pClass1
p0 = reduce(lambda x,y:x*y,vec2Classify * p0Vec)*(1.0-pClass1)
print('p0:',p0)
print('p1:',p1)
if p1>p0:
return 1
else:
return 0
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat = []
for posinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList,posinDoc))
p0V,p1V,pAb = trainNBO(np.array(trainMat),np.array(listClasses))
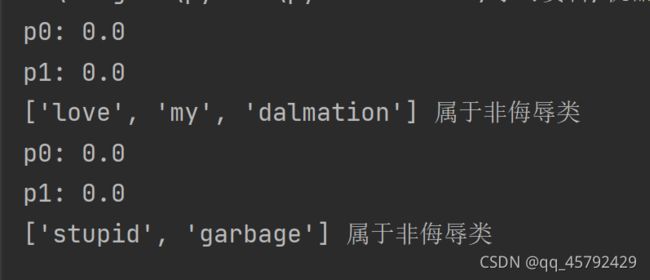
testEntry = ['love','my','dalmation']
thisDoc = np.array(setOfWords2Vec(myVocabList,testEntry))
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'属于侮辱类')
else:
print(testEntry,'属于非侮辱类')
testEntry = ['stupid','garbage']
thisDoc = np.array(setOfWords2Vec(myVocabList,testEntry))
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry, '属于侮辱类')
else:
print(testEntry, '属于非侮辱类')
结果:
3.3 文档词袋模型
目前为止,我们将每个词的出现与否作为一个特征, 这可以被描述为词集模型( set-of- wordsmodel )。如果-一个词在文档中出现不止一次,这可能意味着包含该词是否出现在文档中所不能表达的某种信息,这种方法被称为词袋模型( bag-of-words model )。在词袋中,每个单词可以出现多次,而在词集中,每个词只能出现一次。为适应词袋模型,需要对函数setofWords2Vec()稍加修改,修改后的函数称为bagOfWords2Vec()。
def bagOfWords2VecMN(vocabList,inputSet):
returnVec = [0]*len[vocabList]
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] +=1
return returnVec
4. 示例:使用朴素贝叶斯过滤垃圾邮件
代码:
import numpy as np
import random
import re
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) #取并集
return list(vocabSet)
def setOfWords2Vec(vocabList,inputSet):
returnVec = [0]*len(vocabList) #创建一个所含元素都为0的向量
for word in inputSet: #遍历每个词条
if word in vocabList: #如果存在词汇表中则智1
returnVec[vocabList.index(word)] = 1
else: print("this word:%s is not in my Vocabulary!" % word)
return returnVec
def bagOfWords2VecMN(vocabList,inputSet):
returnVec = [0]*len[vocabList]
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] +=1
return returnVec
def trainNBO(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = np.ones(numWords); p1Num = np.ones(numWords)
p0Denom = 2.0;p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] ==1:
p1Num += trainMatrix[i]
p1Denom +=sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = np.log(p1Num/p1Denom)
p0Vect = np.log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1)
p0 = sum(vec2Classify * p0Vec) + np.log(1.0-pClass1)
if p1>p0:
return 1
else:
return 0
def textParse(bigString):
listOfTokens = re.split(r'\W+',bigString)
return [tok.lower() for tok in listOfTokens if len(tok) >2]
def spamTest():
docList = [];classList = []; fullText = []
for i in range(1,26):
wordList = textParse(open('email/spam/%d.txt' % i, 'r').read()) # 读取每个垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(1) # 标记垃圾邮件,1表示垃圾文件
wordList = textParse(open('./email/ham/%d.txt' % i, 'r').read()) # 读取每个非垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(0) # 标记非垃圾邮件,1表示垃圾文件
vocabList = createVocabList(docList) # 创建词汇表,不重复
trainingSet = list(range(50));
testSet = [] # 创建存储训练集的索引值的列表和测试集的索引值的列表
for i in range(10): # 从50个邮件中,随机挑选出40个作为训练集,10个做测试集
randIndex = int(random.uniform(0, len(trainingSet))) # 随机选取索索引值
testSet.append(trainingSet[randIndex]) # 添加测试集的索引值
del (trainingSet[randIndex]) # 在训练集列表中删除添加到测试集的索引值
trainMat = [];
trainClasses = [] # 创建训练集矩阵和训练集类别标签系向量
for docIndex in trainingSet: # 遍历训练集
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) # 将生成的词集模型添加到训练矩阵中
trainClasses.append(classList[docIndex]) # 将类别添加到训练集类别标签系向量中
p0V, p1V, pSpam = trainNBO(np.array(trainMat), np.array(trainClasses)) # 训练朴素贝叶斯模型
errorCount = 0 # 错误分类计数
for docIndex in testSet: # 遍历测试集
wordVector = setOfWords2Vec(vocabList, docList[docIndex]) # 测试集的词集模型
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: # 如果分类错误
errorCount += 1 # 错误计数加1
print("分类错误的测试集:", docList[docIndex])
print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100))
if __name__ == '__main__':
spamTest()
结果:

![]()
5. 课外例子
以鸢尾花的特征作为数据,共有数据集包含150个数据集,
分为3类setosa(山鸢尾), versicolor(变色鸢尾), virginica(维吉尼亚鸢尾)
每类50个数据,每条数据包含4个属性数据 和 一个类别数据.
代码:
# 鸢尾花的特征作为数据
data = '''5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
4.6,3.4,1.4,0.3,Iris-setosa
5.0,3.4,1.5,0.2,Iris-setosa
4.4,2.9,1.4,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
5.4,3.7,1.5,0.2,Iris-setosa
4.8,3.4,1.6,0.2,Iris-setosa
4.8,3.0,1.4,0.1,Iris-setosa
4.3,3.0,1.1,0.1,Iris-setosa
5.8,4.0,1.2,0.2,Iris-setosa
5.7,4.4,1.5,0.4,Iris-setosa
5.4,3.9,1.3,0.4,Iris-setosa
5.1,3.5,1.4,0.3,Iris-setosa
5.7,3.8,1.7,0.3,Iris-setosa
5.1,3.8,1.5,0.3,Iris-setosa
5.4,3.4,1.7,0.2,Iris-setosa
5.1,3.7,1.5,0.4,Iris-setosa
4.6,3.6,1.0,0.2,Iris-setosa
5.1,3.3,1.7,0.5,Iris-setosa
4.8,3.4,1.9,0.2,Iris-setosa
5.0,3.0,1.6,0.2,Iris-setosa
5.0,3.4,1.6,0.4,Iris-setosa
5.2,3.5,1.5,0.2,Iris-setosa
5.2,3.4,1.4,0.2,Iris-setosa
4.7,3.2,1.6,0.2,Iris-setosa
4.8,3.1,1.6,0.2,Iris-setosa
5.4,3.4,1.5,0.4,Iris-setosa
5.2,4.1,1.5,0.1,Iris-setosa
5.5,4.2,1.4,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
5.0,3.2,1.2,0.2,Iris-setosa
5.5,3.5,1.3,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
4.4,3.0,1.3,0.2,Iris-setosa
5.1,3.4,1.5,0.2,Iris-setosa
5.0,3.5,1.3,0.3,Iris-setosa
4.5,2.3,1.3,0.3,Iris-setosa
4.4,3.2,1.3,0.2,Iris-setosa
5.0,3.5,1.6,0.6,Iris-setosa
5.1,3.8,1.9,0.4,Iris-setosa
4.8,3.0,1.4,0.3,Iris-setosa
5.1,3.8,1.6,0.2,Iris-setosa
4.6,3.2,1.4,0.2,Iris-setosa
5.3,3.7,1.5,0.2,Iris-setosa
5.0,3.3,1.4,0.2,Iris-setosa
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
6.9,3.1,4.9,1.5,Iris-versicolor
5.5,2.3,4.0,1.3,Iris-versicolor
6.5,2.8,4.6,1.5,Iris-versicolor
5.7,2.8,4.5,1.3,Iris-versicolor
6.3,3.3,4.7,1.6,Iris-versicolor
4.9,2.4,3.3,1.0,Iris-versicolor
6.6,2.9,4.6,1.3,Iris-versicolor
5.2,2.7,3.9,1.4,Iris-versicolor
5.0,2.0,3.5,1.0,Iris-versicolor
5.9,3.0,4.2,1.5,Iris-versicolor
6.0,2.2,4.0,1.0,Iris-versicolor
6.1,2.9,4.7,1.4,Iris-versicolor
5.6,2.9,3.6,1.3,Iris-versicolor
6.7,3.1,4.4,1.4,Iris-versicolor
5.6,3.0,4.5,1.5,Iris-versicolor
5.8,2.7,4.1,1.0,Iris-versicolor
6.2,2.2,4.5,1.5,Iris-versicolor
5.6,2.5,3.9,1.1,Iris-versicolor
5.9,3.2,4.8,1.8,Iris-versicolor
6.1,2.8,4.0,1.3,Iris-versicolor
6.3,2.5,4.9,1.5,Iris-versicolor
6.1,2.8,4.7,1.2,Iris-versicolor
6.4,2.9,4.3,1.3,Iris-versicolor
6.6,3.0,4.4,1.4,Iris-versicolor
6.8,2.8,4.8,1.4,Iris-versicolor
6.7,3.0,5.0,1.7,Iris-versicolor
6.0,2.9,4.5,1.5,Iris-versicolor
5.7,2.6,3.5,1.0,Iris-versicolor
5.5,2.4,3.8,1.1,Iris-versicolor
5.5,2.4,3.7,1.0,Iris-versicolor
5.8,2.7,3.9,1.2,Iris-versicolor
6.0,2.7,5.1,1.6,Iris-versicolor
5.4,3.0,4.5,1.5,Iris-versicolor
6.0,3.4,4.5,1.6,Iris-versicolor
6.7,3.1,4.7,1.5,Iris-versicolor
6.3,2.3,4.4,1.3,Iris-versicolor
5.6,3.0,4.1,1.3,Iris-versicolor
5.5,2.5,4.0,1.3,Iris-versicolor
5.5,2.6,4.4,1.2,Iris-versicolor
6.1,3.0,4.6,1.4,Iris-versicolor
5.8,2.6,4.0,1.2,Iris-versicolor
5.0,2.3,3.3,1.0,Iris-versicolor
5.6,2.7,4.2,1.3,Iris-versicolor
5.7,3.0,4.2,1.2,Iris-versicolor
5.7,2.9,4.2,1.3,Iris-versicolor
6.2,2.9,4.3,1.3,Iris-versicolor
5.1,2.5,3.0,1.1,Iris-versicolor
5.7,2.8,4.1,1.3,Iris-versicolor
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
7.1,3.0,5.9,2.1,Iris-virginica
6.3,2.9,5.6,1.8,Iris-virginica
6.5,3.0,5.8,2.2,Iris-virginica
7.6,3.0,6.6,2.1,Iris-virginica
4.9,2.5,4.5,1.7,Iris-virginica
7.3,2.9,6.3,1.8,Iris-virginica
6.7,2.5,5.8,1.8,Iris-virginica
7.2,3.6,6.1,2.5,Iris-virginica
6.5,3.2,5.1,2.0,Iris-virginica
6.4,2.7,5.3,1.9,Iris-virginica
6.8,3.0,5.5,2.1,Iris-virginica
5.7,2.5,5.0,2.0,Iris-virginica
5.8,2.8,5.1,2.4,Iris-virginica
6.4,3.2,5.3,2.3,Iris-virginica
6.5,3.0,5.5,1.8,Iris-virginica
7.7,3.8,6.7,2.2,Iris-virginica
7.7,2.6,6.9,2.3,Iris-virginica
6.0,2.2,5.0,1.5,Iris-virginica
6.9,3.2,5.7,2.3,Iris-virginica
5.6,2.8,4.9,2.0,Iris-virginica
7.7,2.8,6.7,2.0,Iris-virginica
6.3,2.7,4.9,1.8,Iris-virginica
6.7,3.3,5.7,2.1,Iris-virginica
7.2,3.2,6.0,1.8,Iris-virginica
6.2,2.8,4.8,1.8,Iris-virginica
6.1,3.0,4.9,1.8,Iris-virginica
6.4,2.8,5.6,2.1,Iris-virginica
7.2,3.0,5.8,1.6,Iris-virginica
7.4,2.8,6.1,1.9,Iris-virginica
7.9,3.8,6.4,2.0,Iris-virginica
6.4,2.8,5.6,2.2,Iris-virginica
6.3,2.8,5.1,1.5,Iris-virginica
6.1,2.6,5.6,1.4,Iris-virginica
7.7,3.0,6.1,2.3,Iris-virginica
6.3,3.4,5.6,2.4,Iris-virginica
6.4,3.1,5.5,1.8,Iris-virginica
6.0,3.0,4.8,1.8,Iris-virginica
6.9,3.1,5.4,2.1,Iris-virginica
6.7,3.1,5.6,2.4,Iris-virginica
6.9,3.1,5.1,2.3,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
6.8,3.2,5.9,2.3,Iris-virginica
6.7,3.3,5.7,2.5,Iris-virginica
6.7,3.0,5.2,2.3,Iris-virginica
6.3,2.5,5.0,1.9,Iris-virginica
6.5,3.0,5.2,2.0,Iris-virginica
6.2,3.4,5.4,2.3,Iris-virginica
5.9,3.0,5.1,1.8,Iris-virginica'''
import numpy as np
# 数据处理,取得150条的数据,将类别转化为1.0,2.0,3.0数字,因为后面使用NUMPY计算比较快,在类别的类型上和属性一样使用浮点型
data = data.replace(' ', '').replace("Iris-setosa", "1.0").replace("Iris-versicolor", "2.0").replace("Iris-virginica",
"3.0").split('\n')
data = list(filter(lambda x: len(x) > 0, data))
data = [x.split(',') for x in data]
data = np.array(data).astype(np.float16)
# 将数据随机分成训练集与测试集
def splitData(trainPrecent=0.7):
train = []
test = []
for i in data:
(train if np.random.random() < trainPrecent else test).append(i)
return np.array(train), np.array(test)
trainData, testData = splitData()
print("共有%d条数据,分解为%d条训练集与%d条测试集" % (len(data), len(trainData), len(testData)))
clf = set(trainData[:, -1]) # 读取每行最后一个数据,用set得出共有几种分类,本例为1.0,2.0,3.0
trainClfData = {} # 有于存储每个类别的均值与标准差
for x in clf:
clfItems = np.array(list(filter(lambda i: i[-1] == x, trainData)))[:, :-1] # 从训练集中按类别过滤出记录
mean = clfItems.mean(axis=0) # 计算每个属性的平均值
stdev = np.sqrt(np.sum((clfItems - mean) ** 2, axis=0) / float(len(clfItems) - 1)) # 计算每个属性的标准差
trainClfData[x] = np.array([mean, stdev]).T # 对每个类形成固定的数据格式[[属性1均值,属性1标准差],[属性2均值,属性2标准差]]
# print(trainClfData)
result = []
for testItem in testData:
itemData = testItem[0:-1] # 得到训练的属性数据
itemClf = testItem[-1] # 得到训练的分类数据
prediction = {} # 用于存储单条记录集对应的每个类别的概率
for clfItem in trainClfData:
# 测试集中单条记录的每个属性在与训练集中进行比对应用的朴素贝叶斯算法,
probabilities = np.exp(
-1 * (testItem[0:-1] - trainClfData[clfItem][:, 0]) ** 2 / (trainClfData[clfItem][:, 1] ** 2 * 2)) / (
np.sqrt(2 * np.pi) * trainClfData[clfItem][:, 1])
# 将每个属性的概率相乘,等到最终该类别的概率
clfPrediction = 1
for proItem in probabilities:
clfPrediction *= proItem
prediction[clfItem] = clfPrediction
# 取得最大概率的那个类别
maxProbablity = None
for x in prediction:
if maxProbablity == None or prediction[x] > prediction[maxProbablity]:
maxProbablity = x
# 将计算的数据返回,后面有一句print我关闭了,打开就可以看到这些结果
result.append({'数据': itemData.tolist()
, '实际分类': itemClf
, '各类别概率': prediction
, '测试分类(最大概率类别)': maxProbablity
, '是否正确': 1 if itemClf == maxProbablity else 0})
rightCount = 0;
for x in result:
rightCount += x['是否正确']
# print(x) #打印出每条测试集计算的数据
print('共%d条测试数据,测试正确%d条,正确率%2f:' % (len(result), rightCount, rightCount / len(result)))
结果:

6. 总结
朴素贝叶斯的优点:
生成式模型,通过计算概率来进行分类,可以用来处理多分类问题
对小规模的数据表现很好,适合多分类任务,适合增量式训练,算法较简单
朴素贝叶斯缺点:
对输入数据的表达形式很敏感
会带来一些准确率上的损失
需要计算先验概率,分类决策存在错误率
鸣谢:1
2
3