目标检测算法1:FasterRCNN tensorflow-keras源码解读
FasterRCNN tensorflow-keras源码解读
文章目录
- FasterRCNN tensorflow-keras源码解读
- 前言
- 源码下载
- 一、Faster-RCNN整体流程
- 二、代码详解
-
- 1.主干提取网络
- 2.RPN网络结构
- 3.ROI-Pooling层解读
- 4.分类回归网络
- 5.获得网络模型
- 5.真实值的编码
- 6.模型训练过程
- 7.预测过程
- 三、总结
- 四、参考资料
前言
已有很多文章详细介绍faster-rcnn原理,这里不再做相关重复的工作。这篇文章主要通过源码来解读faster-rcnn。
源码下载
https://github.com/yblir/faster-RCNN
一、Faster-RCNN整体流程

faster-rcnn是经典的two-stage网络。其工作流程如下:
① 图片输入主干提取网络后获得特征图feature Map,其shape与图片输入尺寸有关。faster-rcnn网络的输入图片没有固定尺寸,只是做了不失真的resize,例如当输入图片尺寸为600x600时,feature Map尺寸为(None,38,38,1024)。
② feature Map经过3x3卷积后,分别用1x9和4x9通道数的进行1x1卷积。
其中:
9表示9个先验框,
1代表每个先验框是否有物体的置信度,
4代表每个先验框的变化量(每个真实框至少有一个先验框可以通过调整中心位置和宽高获得,那么这个(或这些)先验框应该偏移多少才能获得真实框?就是这个变化量)。
这就是rpn网络。简单地说,变化量+对应的先验框坐标=新框,置信度与这个新框在通道维度拼接一起,就是rpn网络输出的建议框proposal。
③ 使用建议框坐标在feature Map上截取,之后把截取下来的部分resize到14x14大小,每张图片上都有多个建议框,因此最后shape为(batch_size,num_roi,14,14,1024),其中batch_size为一个批次的图片数量,num_roi是每张图片上建议框数量,14为输出特征图尺寸,1024是通道数。这就是roi-pooling层做的事情。
④ roi-pooling层的输出再经过部分卷积后,分别使用全连接网络获得建议框的预测类别和建议框变化量。(变化量指建议框与真实框的差距,与②中的变化量处理手法类似)
小结:
以上就是faster-rcnn网络整个流程,训练和预测过程与mtcnn的级联结构有相似之处,先通过rpn网络初步筛选框,之后再进行精细框回归和类别预测,这也是其two-stage结构的由来。最终的预测框通过对先验框(anchors)的两次调整获得。网络看起来也不难吧! 真正让人头痛的是代码实现过程,涉及比较复杂的矩阵变换,源码陆陆续续读了两周才完全搞明白,现在分享给大家,希望有所帮助,话不多说,我们开始吧!
二、代码详解
1.主干提取网络
主干网络使用RestNet50,但不完整,最后一部分结构是在④分类回归网络中使用。除了resnet,还可以使用其他网络替换,如darknet,mobilenet和新出了Efficientnet网络等。不同的网络结构会带来不一样的预测效果,根据需求选择合适的网络即可,大家不必在这上面纠结太多。
代码如下:
def ResNet50(inputs):
# 假设输入进来的图片是600,600,3
img_input = inputs
# 600,600,3 -> 300,300,64
x = ZeroPadding2D((3, 3))(img_input)
x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1')(x)
x = BatchNormalization(trainable=False, name='bn_conv1')(x)
x = Activation('relu')(x)
# 300,300,64 -> 150,150,64
x = MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
# 150,150,64 -> 150,150,256
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
# 150,150,256 -> 75,75,512
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
# 75,75,512 -> 38,38,1024
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')
# 最终获得一个(None,38,38,1024)的共享特征层,None: batch_size
return x
2.RPN网络结构
RPN网络的构建也很简单,先经过3x3卷积调整通道数,再分别经过1x1卷积获得是否有物体的置信度和每个先验框的变化量。之后都拍平成二维形式。其实这里可以不处理成二维,也可以参与训练与预测,只是对应真实值的编码也要相应改变。
代码如下:
# 创建建议框网络
# 该网络结果会对先验框进行调整获得建议框
def get_rpn(base_layers, num_anchors):
'''
创建rpn网络
Parameters
----------
base_layers:resnet50输出的特征层(None,38,38,1024)
num_anchors:先验框框数量,通常为9,即每个网格分配有9个先验框
Returns
-------
'''
# 利用一个512通道的3x3卷积进行特征整合
x = Conv2D(512, (3, 3), padding='same', activation='relu',
kernel_initializer='normal', name='rpn_conv1')(base_layers)
# 利用一个1x1卷积调整通道数,获得预测结果
# rpn_class只预测该先验框是否包含物体
anchors_class = Conv2D(num_anchors, (1, 1), activation='sigmoid',
kernel_initializer='uniform', name='rpn_out_class')(x)
# 预测每个先验框的变化量,4代表变化量的x,y,w,h
anchors_offset = Conv2D(num_anchors * 4, (1, 1), activation='linear',
kernel_initializer='zero', name='rpn_out_regress')(x)
anchors_class = Reshape((-1, 1), name="classification")(anchors_class)
anchors_offset = Reshape((-1, 4), name="regression")(anchors_offset)
return [anchors_class , anchors_offset]
上面获得仅是初步结果,框数量为38x38x9=12996,太多了,需要根据是否有物体的置信度和非极大值抑制进行筛选,具体步骤如下:
1 先根据rpn预测的框变化量anchors_offset和先验框坐标,计算出建议框坐标
2 对anchors_class 根据置信度值由大到小排序,取前6000个建议框(anchors_class ,anchors_offset和先验框都是一一对应关系)
3 此时6000个建议框和anchors_class 都是从大到小排列,进行非极大值抑制,设定提取300个建议框,这就是rpn网络处理后的最终结果,之后要送入roi-pooling层。
代码如下:
def decode_boxes(self, mbox_loc, anchors):
'''
根据rpn网络输出的偏移量,移动先验框,获得建议框proposal_box
Parameters
----------
mbox_loc:rpn网络输出的先验框偏移量
anchors
Returns
-------
'''
# 获得先验框的宽与高
anchors_w = anchors[:, 2] - anchors[:, 0]
anchors_h = anchors[:, 3] - anchors[:, 1]
# 获得先验框的中心点
anchors_x = (anchors[:, 2] + anchors[:, 0]) / 2
anchors_y = (anchors[:, 3] + anchors[:, 1]) / 2
# 真实框距离先验框中心的xy轴偏移情况
# todo mbox_loc有经过归一化吗?
proposal_center_x = mbox_loc[:, 0] * anchors_w / 4 + anchors_x
proposal_center_y = mbox_loc[:, 1] * anchors_h / 4 + anchors_y
# 建议框的宽与高的求取
proposal_w = np.exp(mbox_loc[:, 2] / 4) * anchors_w
proposal_h = np.exp(mbox_loc[:, 3] / 4) * anchors_h
# 获取建议框的左上角与右下角
proposal_xmin = proposal_center_x - 0.5 * proposal_w
proposal_ymin = proposal_center_y - 0.5 * proposal_h
proposal_xmax = proposal_center_x + 0.5 * proposal_w
proposal_ymax = proposal_center_y + 0.5 * proposal_h
# 建议框的左上角与右下角进行堆叠
# proposal_xmin[:, None]相当于proposal_xmin.reshape(-1,1)
proposal_box = np.concatenate((proposal_xmin[:, None],
proposal_ymin[:, None],
proposal_xmax[:, None],
proposal_ymax[:, None]), axis=-1)
# 防止超出0与1, 因为经过了归一化,坐标在0~1间就能保证在图片内
proposal_box = np.minimum(np.maximum(proposal_box, 0.0), 1.0)
return proposal_box
def detection_out_rpn(self, predictions, anchors):
'''
Parameters
----------
predictions:rpn网络预测结果,包含三组
anchors:归一化后的先验框, 相对于原图
Returns
-------
'''
# 获得种类的置信度
mbox_conf = predictions[0]
# mbox_loc是回归预测结果
mbox_loc = predictions[1]
results = list()
# 训练阶段len(mbox_loc)为batch_size,预测时len(mbox_loc)为1,因为每次处理一张图片
for i in range(len(mbox_loc)):
# 利用rpn的框变化量移动先验框,获得建议框坐标,decode_bbox就是建议框
decode_bbox = self.decode_boxes(mbox_loc[i], anchors)
# 取出先验框内包含物体的概率
c_confs = mbox_conf[i, :, 0]
# 对所有rpn网络预测的先验框是否包含物体的概率,由大到小排序, 获得索引
confs_max_index = np.argsort(c_confs)[::-1]
# 取出前rpn_pre_boxes个包含物体的概率的索引
confs_max_index = confs_max_index[:self.rpn_pre_boxes]
# 根据排序好的索引,取出对应的是否包含物体的概率和对应的建议框坐标
c_confs = c_confs[confs_max_index]
decode_bbox = decode_bbox[confs_max_index, :]
# 根据是否包含物体的概率大小,对建议框进行iou的非极大抑制
idx = tf.image.non_max_suppression(decode_bbox, c_confs,
self.top_k, iou_threshold=self.rpn_nms).numpy()
# 取出在非极大抑制中效果较好的内容
good_boxes = decode_bbox[idx]
confs = c_confs[idx].reshape((-1, 1))
c_pred = np.concatenate((confs, good_boxes), axis=-1)
results.append(c_pred)
# (batch_size,self.top_k,5) top_k此时设为300
return np.array(results)
3.ROI-Pooling层解读
先考虑如下两幅图:
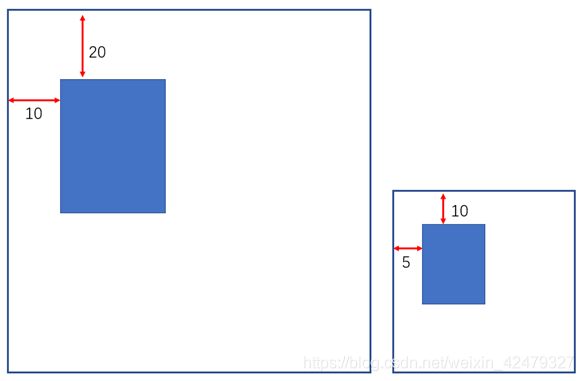
假设坐标大图宽高都为100,其中的长方形坐标为(20,10),归一化后坐标为(0.2,0.1)
此时,若将大图缩小为原来0.5倍,则其中长方形坐标变为(10,5),归一化后坐标还是(0.2,0.1)。
理解上面两幅图关系,我们就很好解释roi-pooling层的工作原理了。
特征图尺寸为38x38,相当于把原图缩小为38x38,放缩后真实框相对位置是不变的。
下面代码中,tf.image.crop_and_resize方法有些烧脑,对其参数做下解释
tf.image.crop_and_resize(image,boxes,box_ind,crop_size),其中:
image是待裁剪的图片,一个batch_size时,是一个列表:[img1,img2,img3,…],列表长度为batch_size。
boxes是要裁剪的位置坐标,数值要归一化,参数格式:[ymin,xmin,ymax,xmax],这也是后面操作中,框坐标要变换x,y位置这样奇怪操作的原因。多个裁剪框时:[box1,box2,box3,…]
box_ind裁剪坐标与图片的对应关系,如果box_ind=[0,1],即使用box1 作用于 img1 , 使用box2 作用于 img2];如果box_ind=[1,0],即使用box1 作用于 img2 , 使用box2 作用于 img1]。下面代码中,box_index最后格式类似[0,0,0,0,…,1,1,1,1,…,2,2,2,…],以0来说,代表第batch_size中第一张图片,0的数量为建议框数量,表示一张图片要截出这么多框。
crop_size表示截出部分会resize到这个尺寸。
代码如下:
class RoiPoolingConv(Layer):
def __init__(self, **kwargs):
super(RoiPoolingConv, self).__init__(**kwargs)
def call(self, inputs, mask=None):
# base_layers:共享特征层, shape=[None,38,38,1024],None表示batch_size
img, rois, pool_size = inputs # 共享特征层,建议框
nb_channels = K.int_shape(img)[3]
# roi_input:[None,None,4],第一个None表示batch_size, 第二个None表示
# 一张图片有多少个建议框,4表示这些建议框的的坐标
batch_size = tf.shape(rois)[0]
num_rois = tf.shape(rois)[1]
box_index = tf.expand_dims(tf.range(0, batch_size), 1)
box_index = tf.tile(box_index, (1, num_rois))
box_index = tf.reshape(box_index, [-1])
rs = tf.image.crop_and_resize(img, tf.reshape(rois, [-1, 4]), box_index, (pool_size, pool_size))
final_output = K.reshape(rs, (batch_size, num_rois, pool_size, pool_size, nb_channels))
return final_output
4.分类回归网络
前面说的resnet最后一部分就用在这里classifier_layers中,结构也很简单,不再单独贴出来。之后再分别经过两个全连接层即可获得该网络结果。
结果虽然简单,但这个网络涉及TimeDistributed这个层包装器,立即使理解难度几何级上升。有多人人开贴解析这个包装器的用法。不过仍然很难懂。这里结合当前环境给出一个简单的解释:
假设输入为(5,38,38,1024):5张图片,每张图片尺寸38x38,每张图片通道数1024
经过Conv2D(64,kernel_size=3,padding=‘same’)后变为(5,38,38,64)
可以理解为5张图片,每张图片尺寸38x38,通道数64
假设输入为(5,10,14,14,1024):5张图片,每张图片有10个建议框,每个建议框尺寸为14x14,每个建议框通道数1024
经过TimeDistributed(Conv2D(64,kernel_size=3,padding=‘same’))后变为(5,10,14,14,64)
可以理解为5张图片,每张图片有10个建议框,每个建议框尺寸为14x14,每个建议框通道数64
使用TimeDistributed,可以把(10,14,14,64)中的10看成新的batch_size,然后执行Conv2D操作,至于原来的5,专业叫法是时间步,这里看成更高维度的存在即可。
最后经过Dense层处理后,out_box_loc 的shape=(batch_size,num_rois,4*(nb_classes-1)),
意思是共有batch_size张图片,每张图片有num_rois个建议框,每个建议框预测每个类别的坐标变化量。
代码如下:
# 将共享特征层和建议框传入classifier网络
# 该网络结果会对建议框进行调整获得预测框
def get_classifier(base_layers, input_rois, nb_classes=21, pooling_regions=14):
'''
Faster-RCNN网络模型
Parameters
----------
base_layers: resnet50输出的特征层(None,38,38,1024)
input_rois:
nb_classes
pooling_regions
Returns
-------
'''
# num_rois, 38, 38, 1024 -> num_rois, 14, 14, 2048
out_roi_pool = RoiPoolingConv()([base_layers, input_rois, pooling_regions])
# out_roi_pool = RoiPoolingConv(pooling_regions)([base_layers, input_rois])
# num_rois, 14, 14, 1024 -> num_rois, 1, 1, 2048
out = classifier_layers(out_roi_pool)
# TimeDistributed: 对batch_size中的每一个单独做处理
# num_rois, 1, 1, 1024 -> num_rois, 2048
out = TimeDistributed(Flatten())(out)
# num_rois, 1, 1, 1024 -> num_rois, nb_classes
# (None,num_rois,nb_classes),None:batch_size,num_rois:每张图片的建议框数量,nb_classes:每个建议框预测的类别
out_class = TimeDistributed(Dense(nb_classes,
activation='softmax',
kernel_initializer='zero'),
name=f'dense_class_{nb_classes}')(out)
# num_rois, 1, 1, 1024 -> num_rois, 4 * (nb_classes-1)
# (None,num_rois,4*(nb_classes-1)), 4*(nb_classes-1):每个建议框预测所有类别的建议框变化量. 这个变化量+建议框=预测框
out_box_loc = TimeDistributed(Dense(4 * (nb_classes - 1),
activation='linear',
kernel_initializer='zero'),
name=f'dense_regress_{nb_classes}')(out)
return [out_class, out_box_loc]
5.获得网络模型
再看一眼流程图:
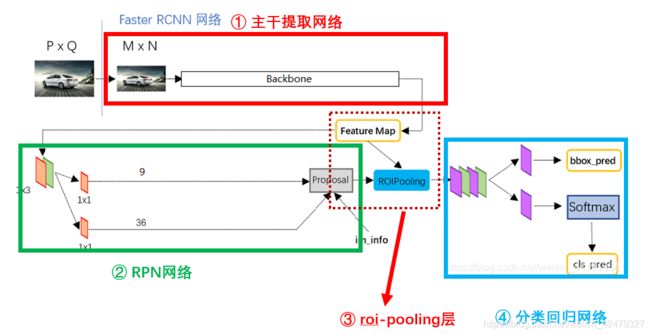
将以上各个模块拼起来就可以获得faste-rcnn的模型了。值得注意的是训练和预测所用的模型不一样。训练时会将所有模块聚在一起构成大网络,计算整体的损失函数,使模型整体最优。预测时不需要更新权重,那么只需构建分类网络即可,加快预测过程。
以上两种情况仅适用权值与网络分离的情况,若连带模型结构一起保存,那就不能按上面的处理。不过可以在保存时再额外保存分类网络,这样也可以达到训练/预测分离的目的。
def get_model(config, num_classes):
'''
创建训练网络模型
Parameters
----------
config
num_classes
Returns
-------
'''
# 输入主干提取的图片
inputs = Input(shape=(None, None, 3))
# roi-pooling层的输入,从rpn层获得的最后建议框,None:一张图片中建议框数量
roi_input = Input(shape=(None, 4))
# 假设输入为600,600,3
# 获得一个38,38,1024的共享特征层base_layers
base_layers = ResNet50(inputs)
# 每个特征点9个先验框,先验框边长数量*先验框宽高比例数
num_anchors = len(config.anchor_box_scales) * len(config.anchor_box_ratios)
# 将共享特征层传入建议框网络
# 该网络结果会对先验框进行调整获得建议框
rpn = get_rpn(base_layers, num_anchors)
# 这是包含在下面moel_all中的子网络,不必单独训练model_rpn,因为下面model_all训练时会同步更新
# model_rpn的权重。model_rpn的作用是每次训练和预测时生成用于截取特征图的建议框。训练时每个batch_size
# 都会更新权重,向好的方向调整,获得的建议框也会越来越精确。额~,我怎么突然想起了GAN网络...
model_rpn = Model(inputs, rpn)
# 将共享特征层和建议框传入classifier网络
# 该网络结果会对建议框进行调整获得预测框
classifier = get_classifier(base_layers, roi_input, num_classes, config.pooling_regions)
# 构建包含rpn和分类的两个网络,一起训练,使得两个网络的损失函数整体最小
model_all = Model([inputs, roi_input], rpn + classifier)
return model_rpn, model_all
def get_predict_model(config, num_classes):
'''
训练时两步一起训练,使得loss全部最小,预测时分开,加快预测速度
Parameters
----------
config
num_classes
Returns
-------
'''
# 输入主干提取的图片
inputs = Input(shape=(None, None, 3))
# roi-pooling层的输入,从rpn层获得的最后建议框,None:一张图片中建议框数量
roi_input = Input(shape=(None, 4))
# 主干网络输出的特征层,预测时作为分类网络的输入
feature_map_input = Input(shape=(None, None, 1024))
# 假设输入为600,600,3, 获得一个38,38,1024的共享特征层base_layers
base_layers = ResNet50(inputs)
# 每个特征点9个先验框
num_anchors = len(config.anchor_box_scales) * len(config.anchor_box_ratios)
# 将共享特征层传入建议框网络
# 该网络结果会对先验框进行调整获得建议框
rpn = get_rpn(base_layers, num_anchors)
model_rpn = Model(inputs, rpn + [base_layers])
# 将共享特征层和建议框传入classifier网络
# 该网络结果会对建议框进行调整获得预测框
classifier = get_classifier(feature_map_input, roi_input, num_classes, config.pooling_regions)
# 此处仅构建分类模型,与训练时的模型不同
model_classifier_only = Model([feature_map_input, roi_input], classifier)
return model_rpn, model_classifier_only
5.真实值的编码
模型输出结果是预测值,训练阶段只有与真实值求损失函数,才能反向更新权重。为此需要把真实值调整成预测值形式(也可以说把模型的预测结果reshape成真实的形状,之后再求损失函数,看从哪个角度理解吧)。
在rpn网络中,输出结果是先验框变化量,我们需要找出什么样的变化量能使先验框经过平移缩放变成真实框,于是有以下变换代码:
def assign_boxes(self, boxes, anchors):
'''
获得真实框对应的变化量,供先验框调整使用
Parameters
----------
boxes:真实框信息,x,y,w,h,c
anchors:由一定规则,为每个网格点生成的先验框
Returns
-------
'''
self.num_anchors = len(anchors)
self.anchors = anchors
# 4:的内容为网络应该有的回归预测结果, 1:先验框是否包含物体,默认为背景
assignment = np.zeros((self.num_anchors, 4 + 1))
# 默认所有先验框都不包含物体
assignment[:, 4] = 0.0
if len(boxes) == 0:
return assignment
# 对每一个真实框都进行iou计算,寻找哪些先验框是需要被忽略的
axis_boxes = np.apply_along_axis(self.encode_ignore_box, 1, boxes[:, :4])
encoded_boxes = np.array([axis_boxes[i, 0] for i in range(len(axis_boxes))])
ingored_boxes_iou = np.array([axis_boxes[i, 1] for i in range(len(axis_boxes))])
# 上面逻辑有些复杂,相当于执行下面的操作
# encoded_boxes, ingored_boxes = list(), list()
# for box in boxes:
# encoded_box, ignored_box = self.encode_ignore_box(box[:4])
# encoded_boxes.append(encoded_box)
# ingored_boxes.append(ignored_box)
#
# encoded_boxes = np.array(encoded_boxes)
# ingored_boxes = np.array(ingored_boxes)
# [num_true_box, num_anchors, 1] 其中1为iou
ingored_boxes_iou = ingored_boxes_iou.reshape(-1, self.num_anchors, 1)
ingored_boxes_iou = ingored_boxes_iou[:, :, 0].max(axis=0)
ignore_iou_mask = ingored_boxes_iou > 0
# 将待忽略先验框的设为是负样本, 坐标设为0
assignment[:, 4][ignore_iou_mask] = -1
# 在reshape后,获得的encoded_boxes的shape为:
# [num_true_box, num_priors, 4+1]=>(3,22500,5)
# 4是编码后的结果,1为iou
encoded_boxes = encoded_boxes.reshape(-1, self.num_anchors, 5)
# 同一个先验框与一张图片中的所有真实框都有iou值,有几个真实框,就是几个iou值,找出最大的那个.
# 有多少先验框就有多少个这样的iou值,这里有22500个
best_iou = encoded_boxes[:, :, -1].max(axis=0)
# 提起是第几个真实框与当前先验框iou最大,(22500,)
best_iou_idx = encoded_boxes[:, :, -1].argmax(axis=0)
# 将最大iou值的索引提取出来
best_iou_mask = best_iou > 0
best_iou_idx = best_iou_idx[best_iou_mask]
# 计算一共有多少先验框满足需求
assign_num = len(best_iou_idx)
# 将编码后的真实框取出
encoded_boxes = encoded_boxes[:, best_iou_mask, :]
# 将编码后的框,每个框对应的最大iou的值取出来,填入assignment中
assignment[:, :4][best_iou_mask] = encoded_boxes[best_iou_idx, np.arange(assign_num), :4]
# 4代表为当前先验框是否包含目标,将与真实框重叠程度满足阈值的先验框认为包含物体
assignment[:, 4][best_iou_mask] = 1
return assignment
分类网络输出的建议框变化量,我们同样需要找出什么样的变化量能使建议框经过平移缩放变成真实框,实现代码如下:
def bbox2loc(pbox, tbox):
'''
计算真实框与建议框的偏移量,这里与rpn网络预测的处理手法一样,都是
求变化量.rpn网格预测的变化量+先验框=建议框.
分类网络预测的偏移量+建议框=网络最终预测框
Parameters
----------
pbox:已提取的正负样本的坐标,[x_min,y_min,x_max,y_max]
tbox:正负样本对应的真实框的坐标,[x_min,y_min,x_max,y_max]
Returns
-------
'''
# 获得建议框宽高与中心
proposal_w = pbox[:, 2] - pbox[:, 0]
proposal_h = pbox[:, 3] - pbox[:, 1]
proposal_center_x = pbox[:, 0] + 0.5 * proposal_w
proposal_center_y = pbox[:, 1] + 0.5 * proposal_h
# 获得真实框宽高与中心
true_w = tbox[:, 2] - tbox[:, 0]
true_h = tbox[:, 3] - tbox[:, 1]
true_center_x = tbox[:, 0] + 0.5 * true_w
true_center_y = tbox[:, 1] + 0.5 * true_h
eps = np.finfo(proposal_h.dtype).eps
# eps=0.0001
proposal_w = np.maximum(proposal_w, eps)
proposal_h = np.maximum(proposal_h, eps)
# 计算真实框与建议框偏移量并归一化
dx = (true_center_x - proposal_center_x) / proposal_w
dy = (true_center_y - proposal_center_y) / proposal_h
dw = np.log(true_w / proposal_w)
dh = np.log(true_h / proposal_h)
# loc.shape=(n,4),n:正负样本总数,值为建议框编号,4:真实框与建议框中心点偏差量和框高比例值
# 并且所有值都已经归一化
loc = np.concatenate([dx[:, None], dy[:, None],
dw[:, None], dh[:, None]], axis=-1)
return loc
6.模型训练过程
获得真实值编码后,就可以开始训练了。
每个bath_size都会先使用rpn层获得预测结果,每轮训练rpn网络都会优化一次,因此理论上每次输出都会更好结果。
之后遍历batch_size中每张图片,取出每张图片正负均衡后的建议框,和建议框调整到真实框应有的变化量,作为标签值传入训练网络。
def model_train(model_rpn, inputs_img, true_boxes, rpn_true_boxes):
'''
模型训练过程,分两步进行:
1. 图片输入rpn预测网络获得每个先验框应有的变化量,和每个先验框是否包含物体置信度
2. rpn预测结果与先验框组合,获得建议框和每个建议框包含物体的置信度(就是上面的置信度,只是提取了最好的一些,之前置信度对应
先验框变化量, 现在对应着处理后的建议框)
3. 建议框与真实框进行iou计算,根据阈值确定正负样本,并根据iou值确定哪个建议框负责预测哪个真实框. 并算出该建议框要想获得真实
框坐标和宽高应该有的偏移量和宽高比
4. 将过滤后的建议框坐标输入分类网络进行最后训练,获得最终预测类别和建议框应有的变化量
Parameters
----------
model_rpn: rpn网络模型
inputs_img:图片
true_boxes:真实框坐标
rpn_true_boxes
Returns
-------
'''
rpn_predict = model_rpn.predict_on_batch(inputs_img)
# (batch_size,600,600,3)
height, width, _ = np.shape(inputs_img[0])
feature_w, feature_h = get_img_output_length(width, height)
anchors = get_anchors([feature_w, feature_h], width, height)
# rpn预测结果与先验框,共同确定建议框,并提取前300个
results = bbox_util.detection_out_rpn(rpn_predict, anchors)
roi_inputs, out_classes, out_regrs = list(), list(), list()
# 遍历一个batch_size中的每张图片
for j in range(len(inputs_img)):
# rpn模型预测的调整后的建议框坐标
# 取出每张图片所有建议框的坐标
proposal_boxes = results[j][:, 1:]
'''
pos_neg_loc:调整正负样本数量后的建议框坐标:x,y,w,h
labels:建议框应该预测的类别值(已one_hot编码)
true_boxes_offset:建议框若要调整到真实框位置,应该有的偏移量和宽高比,x,y,w,h
'''
pos_neg_loc, labels, true_boxes_offset = calc_iou(proposal_boxes,
config,
true_boxes[j],
NUM_CLASSES)
roi_inputs.append(pos_neg_loc)
out_classes.append(labels)
out_regrs.append(true_boxes_offset)
loss_class = model_all.train_on_batch([inputs_img, np.array(roi_inputs)],
[rpn_true_boxes[0], rpn_true_boxes[1],
np.array(out_classes), np.array(out_regrs)])
return loss_class
7.预测过程
预测过程与训练过程类似,步骤如下:
① 预处理后的图传入rpn网络获得每个先验框是否包含物体的置信度和对应的变化量。
② rpn网络获得的变化与先验框组合,获得建议框,并根据置信度与非极大值抑制筛选出300个建议框。
③ 特征层和300个建议框送入分类网络,获得每个建议框的预测类别,和每个类别的建议框变化量。怎么理解这句话呢?
网络输出两组值,假设建议框数量300,类别数量20,则有:
类别:(batch_size,300,20)
坐标偏移量:(batch_size,300,4*20)
每个建议框预测20个类别 每个类别的概率值。
每个建议框预测20个类别 每个类别从建议框调整到真实框的变化量
预测流程的核心代码如下:
# 预测值有3个, rpn类别,框变化量, resnet的输出:公共特征层
rpn_pred = self.rpn_model_pred(photo)
rpn_pred = [x.numpy() for x in rpn_pred]
# 将建议框网络的预测结果进行解码
feat_w, feat_h = self.get_img_output_length(new_w, new_h)
# 获得归一化后的先验框坐标
anchors = get_anchors([feat_w, feat_h], new_w, new_h)
# 获得rpn网络的预测框, 并对rpn预测框根据类别置信度大小进行初步筛选
rpn_results = self.bbox_util.detection_out_rpn(rpn_pred, anchors)
# 在获得建议框和共享特征层后,将二者传入classifier中进行预测
feat_layer = rpn_pred[2]
# 取出rpn网络输出的所有建议框
proposal_box = np.array(rpn_results)[:, :, 1:]
temp_ROIs = np.zeros_like(proposal_box)
# x_min,y_min,x_max,y_max => y_min,x_min,y_max,x_max
temp_ROIs[:, :, [0, 1, 2, 3]] = proposal_box[:, :, [1, 0, 3, 2]]
# classifier_pred = self.model_classifier([feat_layer, temp_ROIs])
classifier_pred = self.model_classifier([feat_layer, temp_ROIs])
classifier_pred = [x.numpy() for x in classifier_pred]
# 利用classifier的预测结果对建议框进行解码,获得预测框
results = self.bbox_util.detection_out_classifier(classifier_pred,
proposal_box, self.config, self.confidence)
其中,③中获得结果需要再次与先验框组合才能获得预测框,再遍历每一个类别,利用非极大值抑制选出最终的预测框,这就是self.bbox_util.detection_out_classifier的作用。
实现代码如下:
def detection_out_classifier(self, predictions, proposal_box, config, confidence):
# 获得种类的置信度
proposal_conf = predictions[0]
# proposal_loc是回归预测结果
proposal_loc = predictions[1]
results = []
# 对每一张图片进行处理,由于在predict.py的时候,我们只输入一张图片,所以for i in range(len(mbox_loc))只进行一次
for i in range(len(proposal_conf)):
proposal_pred = []
proposal_box[i, :, 2] = proposal_box[i, :, 2] - proposal_box[i, :, 0]
proposal_box[i, :, 3] = proposal_box[i, :, 3] - proposal_box[i, :, 1]
# 循环300次
for j in range(proposal_conf[i].shape[0]):
if np.max(proposal_conf[i][j, :-1]) < confidence:
continue
# 最后一个为背景的概率,舍弃不算
# 找到最大的概率对应的索引,就是类别号
label = np.argmax(proposal_conf[i][j, :-1])
score = np.max(proposal_conf[i][j, :-1])
# x,y是左上角点
(x, y, w, h) = proposal_box[i, j, :]
# 取出该类别对应的建议框坐标, 每个类别有4个坐标值,所以每次偏移4
(tx, ty, tw, th) = proposal_loc[i][j, 4 * label: 4 * (label + 1)]
tx /= config.classifier_regr_std[0]
ty /= config.classifier_regr_std[1]
tw /= config.classifier_regr_std[2]
th /= config.classifier_regr_std[3]
# 建议框中心
cx = x + w / 2.
cy = y + h / 2.
# 调整后的建议框中心
cx1 = tx * w + cx
cy1 = ty * h + cy
w1 = math.exp(tw) * w
h1 = math.exp(th) * h
# 调整后的建议框4个坐标点
x1 = cx1 - w1 / 2.
y1 = cy1 - h1 / 2.
x2 = cx1 + w1 / 2
y2 = cy1 + h1 / 2
proposal_pred.append([x1, y1, x2, y2, score, label])
num_classes = np.shape(proposal_conf)[-1]
proposal_pred = np.array(proposal_pred)
good_boxes = []
if len(proposal_pred) != 0:
for c in range(num_classes):
mask = proposal_pred[:, -1] == c
if len(proposal_pred[mask]) > 0:
boxes_to_process = proposal_pred[:, :4][mask]
confs_to_process = proposal_pred[:, 4][mask]
idx = tf.image.non_max_suppression(boxes_to_process, confs_to_process, self.top_k,
iou_threshold=self.classifier_nms).numpy()
# 取出在非极大抑制中效果较好的内容
good_boxes.extend(proposal_pred[mask][idx])
results.append(good_boxes)
return results
三、总结
以上就是对faster-rcnn的解读。我曾想用简短的篇幅写完,但涉及的细节太多,不知不觉写成长篇大论。即使如此,贴出的源码也仅是部分,完整代码在git仓中。
faste-rcnn在2015年发表,对于更新速度极快的目标检测领域来讲,已经算很老的工作了。但其涉及的理念仍是后续很多新方法的基础,理解faster-rcnn可以快速理解其他目标检测算法。
另外,本篇完整中涉及的代码,重构于bubbliiiing同学的代码。这份代码写的很漂亮,我自认写不出更好的代码,既不能超越,那就为之喝彩吧!尽管作者已经很用心地写注释,但代码本身就不好理解,应该还有很多小伙伴看不明白,因此我在原代码基础上重构部分复杂模块,关键部分又增加大量注释和我的理解。希望对想深刻理解faster-rcnn的同学有所帮助,作者还有配套的视频,有兴趣同学一定要取看下,只是视频中代码与其git仓不一样。
还有许多很优秀的学习资料,都列举在下面。目标检测领域待探索的工作还有很多,成长之路漫漫兮,大家共勉之。
四、参考资料
1 https://blog.csdn.net/weixin_44791964/article/details/108513563
2 https://github.com/bubbliiiing/faster-rcnn-tf2
3 https://www.bilibili.com/video/BV1pt411F73V?p=1