从源码角度认识和理解Spring中@Resource注解
从源码角度认识和理解Spring中@Autowired注解 https://blog.csdn.net/qq_43799161/article/details/123904532?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_43799161/article/details/123904532?spm=1001.2014.3001.5501
上篇帖子介绍了@Autowired的使用,然后从源码中角度介绍了@Autowired的一个自动注入的实现,但是在Spring中还有一个@Resource注解可以来实现依赖注入的实现。所以这篇帖子给读者从源码角度认识和理解@Resource注解。
@Resource注解和@Autowired区别
1.首先先从使用层面,来认识一下两者的区别把:


可以很清楚的看到@Resource注解比@Autowired的API多很多,也就是说明@Resource注解的功能会更强大,我们在一些特定的条件,比如一个接口有多个实现类的时候,@Autowired可能需要@Qualifier结合使用。但是在@Resource注解中就可以完美的解决。
2.从包名认识两者区别

可以看到@Resource注解是JDK提供的,而@Autowired注解是Spring提供的,据我所知@Resource注解就是JDK开发人员定义的JNDI的一个实现,何为JNDI,可以理解为在JavaEE中定义的一个规范,就是将Java的对象以名字的形式绑定在容器中。后续可以靠JNDI提供的lookup(@Resource注解中提供了这个方法的实现)来查找容器中的Java对象。这不就可以理解为将对象注入到容器中么~
3.从源码角度:
这里大概提一下,因为后面源码要来认证一下这个结论。
那就是@Resource注解是先根据注解属性的name属性来找,如果找到了再根据属性对匹对,如果是我们需要注入的属性那么就完成了一次注入。但是如果开发者没有实现name属性,那么就会根据需要注入的字段名来找,如果找到了就再去匹对属性完成注入。如果字段名没有找到映射,就会再根据被注入的属性去找,如果根据属性找有多个或0个就抛出异常,如果只有一个就注入成功。
而@Autowired跟@Resource恰恰相反,@Autowired是先根据Type来找,找到了再根据@Qualifier来做筛选,如果没有@Qualifier注解。就会返回一个Type的Map集合再根据Name(字段名)来做映射,如果没映射上就直接抛出异常,当然Map集合就只有一个元素的话就不需要做映射直接完成注入。
@Resource注解使用案例
我们知道@Autowired可以标在方法和字段上(不知道没关系,现在知道了),当然@Resource也不示弱,肯定也是可以的。
案例1
// 定义一个接口
public interface Liha {
}
// 接口的实现1,并且注册到IoC容器中
@Component
public class Liha1 implements Liha{
}
// 接口的实现2,并且注册到IoC容器中
@Component
public class Liha2 implements Liha{
}
// 定义了一个类, 类中对Liha接口中使用@Resource注解做一个注入
@Component
public class AutowirteTest {
// 使用到注解中的name完成了一个根据名称注入
@Resource(name = "liha1")
public Liha liha;
}
// springboot的启动类
@SpringBootApplication
public class Application {
public static void main(String[] args) {
ConfigurableApplicationContext run = SpringApplication.run(Application.class, args);
AutowirteTest autowirteTest = (AutowirteTest) run.getBean("autowirteTest");
System.out.println(autowirteTest.liha);
}
}这里我们使用@Resource注解中的name完成注入,name指定的是liha1,我们知道使用@Component注解将类注册到IoC容器中会根据类名首字母小写,所以也就是liha1,所以这里肯定是可以注入成功的。
案例2
@Component
public class AutowirteTest {
@Resource
public Liha liha1;
}我们把上面代码给做了一个改变,把@Resource注解中name字段给去掉,并且把Liha字段改成liha1,启动容器测试一下也是没任何问题的。
如果我们把liha1给改成liha,那么启动容器可能是会抛出异常的,因为底层根据Liha接口找到了2个实现,实现为liha1和liha2,并没有找到liha。
案例3
前面有提到,@Autowired注解和@Resource注解都是可以在方法上完成注入的。
@Component
public class AutowirteTest {
public Liha liha;
@Resource(name = "liha1")
public void setLiha(Liha liha) {
this.liha = liha;
}
}
其实写在方法和写在字段上,对于注解来是一样的。只不过他是注入方法中的参数字段。说他的玩法
@Resource源码
首先,通过上面的介绍,我们知道@Resource注解他是JDK层面的注解,也是属于的jndi的一个规范,但是我们项目是Spring的项目,所以我们来源码前的推理。
- 对于Spring来说,容器启动的时候,创建bean实例的时候,肯定是通过接口回调机制,将我们标有@Resource的类的字段给完成注入,这个肯定是不用质疑的。
- 如果有看笔者的@Autowired注解的文章的读者可以知道,Spring底层是通过一个写了一个Spring自定义的BeanPostProcessor来进行回调处理,所以我们这里可以推测,对于@Resource来说肯定意识有一个Spring自定义的BeanPostProcessor来进行接口回调。
笔者暂时的推理就这么多,笔者是非常建议大家发散思维来做推理,来做假设,并用源码来证实,这是一个很有效的学习方式~!
我们看到CommonAnnotationBeanPostProcessor类,看他实现的接口,以及他的注释,能很清楚的看到他是对JSR-250规范尤其是javax.annotation的一个处理,而我们的@Resource注解就是这个包旗下的。也就是Spring他对这套规范的注解做了处理,也就是通过BeanPostProcessor的高扩展来对其做的处理。
比如JSR-250中javax.annotation包还有我们常见的PostConstruct annotations and PreDestroy annotations 两个注解,这里不过多的介绍。

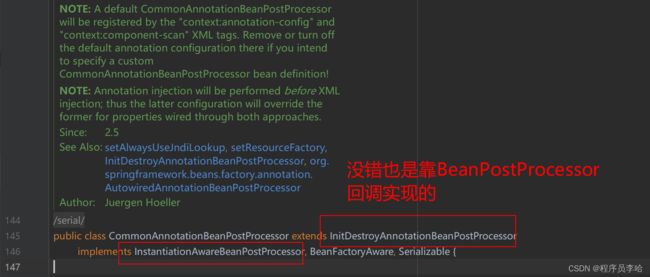
所以我们又可以把重心看到Spring中,此时又要上我们的容器刷新的方法了,因为他就是重点,可以这么说,懂这个方法就可以说懂Spring了。

我们可以说并不关系,他怎么去注册我们的BeanPostProcessor到我们的Spring上下文中,我们更加关注的是我们回调BeanPostProcessor接口来完成的一些事情。所以我们直接看到回调的时机。
创建bean的过程getBean->doGetBean->createBean->doCreateBean这我就直接一笔带过了。
在doCreateBean的创建过程中,大致分为createBeanInstance()反射创建bean实例- > populateBean()给bean中属性赋值->initializeBean()一些高扩展的接口回调。
所以我们能知道注入也就是给字段从Spring容器中获取对象赋值的一个过程,所以我们就能推测出在populateBean()方法中执行。
但是在这之前还有一个操作,看到以下代码。
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}他用来判断当前bean实例,是否需要走MergedBeanDefinitionPostProcessor接口的回调,刚好我们前面介绍的CommonAnnotationBeanPostProcessor类它是实现了此接口的,所以我们看一下具体的回调内容。
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class beanType, String beanName) {
// 调用父类的的方法,也就是去找寻当前bean是否实现了PostConstruct注解和PreDestroy注解
// 如果实现了这两个注解就就会存入到缓存中,等待后面从缓存中取到然后执行
super.postProcessMergedBeanDefinition(beanDefinition, beanType, beanName);
// 这个就是看是否实现了@Resource注解,如果实现了就加入到缓存中,给下文做铺垫
InjectionMetadata metadata = findResourceMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
}回调的执行的大致逻辑如下:
- 查询当前bean是否实现PostConstruct和PreDestroy,如果实现了就加入到缓存,给后面内容做铺垫。因为后续要使用,就可以直接查缓存。
- 查询当前bean中字段或者方法是否使用了@Resource注解,如果使用了就包装成一个InjectedElement,并且一个对象中可能有多个InjectedElement,所以一个对象包装成InjectionMetadata,一个InjectionMetadata中有多个InjectedElement,并且InjectionMetadata还有一些类的信息。并且加入到缓存,给下文做铺垫。
所以我们就可以继续往下走,就是我们的populateBean()方法给bean赋值的操作。我们看到populateBean()方法中的一段代码如下:
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
boolean needsDepCheck = (mbd.getDependencyCheck() != AbstractBeanDefinition.DEPENDENCY_CHECK_NONE);
PropertyDescriptor[] filteredPds = null;
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
PropertyValues pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
pvsToUse = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
pvs = pvsToUse;
}
}
}这里也就是判断我们当前的bean是否需要走InstantiationAwareBeanPostProcessor接口的回调,前面我们的介绍的CommonAnnotationBeanPostProcessor也是实现了这个接口,所以我们就看到CommonAnnotationBeanPostProcessor类中InstantiationAwareBeanPostProcessor类的实现方法之postProcessProperties方法。
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
InjectionMetadata metadata = findResourceMetadata(beanName, bean.getClass(), pvs);
try {
metadata.inject(bean, beanName, pvs);
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Injection of resource dependencies failed", ex);
}
return pvs;
}findResourceMetadata熟悉吗?
没错前面介绍的一个回调中,就是执行的findResourceMetadata方法,给标有@Resource注解的方法和变量给解析包装成InjectedElement,然后包装成InjectionMetadata然后放在缓存中,所以这次执行这个方法就是直接从缓存中获取到。所以我们的重心不就是在inject上面了么,中文意思也就是注入的意思。
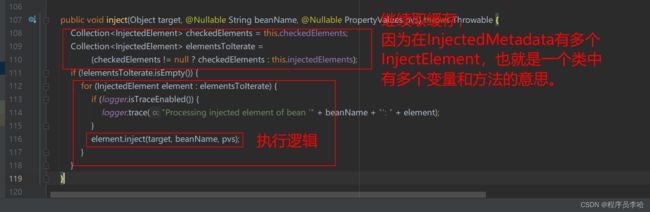
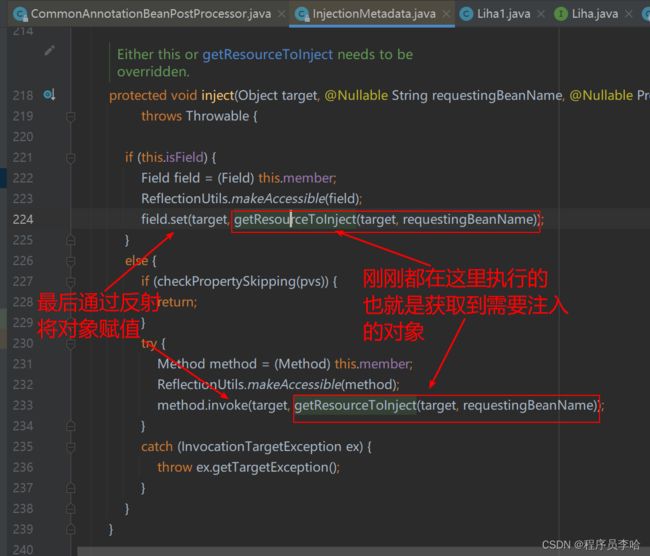
protected void inject(Object target, @Nullable String requestingBeanName, @Nullable PropertyValues pvs)
throws Throwable {
// 这个if也就是来判断,当前这个injectElement是字段还是方法
// 也就是证实了@Resource可以标在方法和字段上面
if (this.isField) {
Field field = (Field) this.member;
ReflectionUtils.makeAccessible(field);
field.set(target, getResourceToInject(target, requestingBeanName));
}
else {
if (checkPropertySkipping(pvs)) {
return;
}
try {
Method method = (Method) this.member;
ReflectionUtils.makeAccessible(method);
method.invoke(target, getResourceToInject(target, requestingBeanName));
}
catch (InvocationTargetException ex) {
throw ex.getTargetException();
}
}
}可以看到这里通过if来判断是方法还是字段,最后通过反射来执行,但是我们可以看到不管是方法还是字段都是走getResourceToInject(target, requestingBeanName)方法获取到属性,所以我们的重点就在这个方法中。

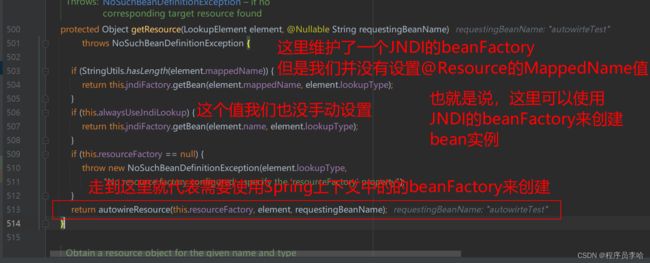
protected Object autowireResource(BeanFactory factory, LookupElement element, @Nullable String requestingBeanName)
throws NoSuchBeanDefinitionException {
Object resource;
Set autowiredBeanNames;
String name = element.name; // 获取到@Resource中name字段的值
// 因为这里是使用Spring上下文的的beanFactory,所以为true
if (factory instanceof AutowireCapableBeanFactory) {
// 转换一下bean工厂
AutowireCapableBeanFactory beanFactory = (AutowireCapableBeanFactory) factory;
// 获取到依赖注入的描述类,也就是封装一些信息罢了
DependencyDescriptor descriptor = element.getDependencyDescriptor();
// 这里重点来了,也就是证明了笔者最前面的结论(跟@Autowired区别的结论)
// 这里会判断是否使用了默认名字,何为默认名字呢? 也就是开发者没使用@Resource的name字段
// 第三个条件就是name是否在bean工厂中存在,name值是当开发者重写了@Resource的name字段的话这里的name就是@Resource的name,如果没写的话就是字段的name
// 第三个条件就是第二个条件为true的时候会执行,当用户没写@Resource的name的时候就会去判断接口名在bean工厂里面是否存在,如果不存在就再根据Type类型来找。
if (this.fallbackToDefaultTypeMatch && element.isDefaultName && !factory.containsBean(name)) {
autowiredBeanNames = new LinkedHashSet<>();
resource = beanFactory.resolveDependency(descriptor, requestingBeanName, autowiredBeanNames, null);
if (resource == null) {
throw new NoSuchBeanDefinitionException(element.getLookupType(), "No resolvable resource object");
}
}
// 所以这个else就是使用了@Resource中name字段。所以使用了name字段就直接去容器中创建或者从容器中取bean缓存
else {
resource = beanFactory.resolveBeanByName(name, descriptor);
autowiredBeanNames = Collections.singleton(name);
}
}
else {
resource = factory.getBean(name, element.lookupType);
autowiredBeanNames = Collections.singleton(name);
}
if (factory instanceof ConfigurableBeanFactory) {
ConfigurableBeanFactory beanFactory = (ConfigurableBeanFactory) factory;
for (String autowiredBeanName : autowiredBeanNames) {
if (requestingBeanName != null && beanFactory.containsBean(autowiredBeanName)) {
beanFactory.registerDependentBean(autowiredBeanName, requestingBeanName);
}
}
}
return resource;
} 这段代码就是证实笔者前面谈到的跟@Autowired注解的区别的第三点的论证。
这段代码并不复杂,大致流程如下:
- 判断是不是Spring上下文的beanFactory
- 如果是的就开始做逻辑if判断了,此时判断开发者是否写了@Resource注解的name字段,或者是写了但是为""为空,就会取到被注入的字段名去bean工厂里面找,如果没找到就会去根据注入的Type类型去找bean工厂找,此时只要根据类型找出来是0个或多个就抛出异常,只有一个就直接通过getBean然后反射注入。如果name不为空,也就是开发者在@Resource注解上写了nanm字段,指定了用哪个bean对象。此时就会直接getBean创建。
没@Resource的name
所以也就是根据@Resource的name来找,没有name就会去根据被注入的字段名去找,如果还没找到就会根据Type来找,Type没找到就抛出异常,如果只找到一个就直接注入,如果找到多个就根据名字来找映射,但是之前就已经判断过名字了,所以找到多个也会抛出异常,所以这里就只能找出一个来。
有@Resource的name
有name就会直接去getBean()创建或者是从容器缓存中获取到。
的确这里判断挺复杂的,笔者的描述能力可能描述的比较差,并且每个读者的理解程度也有差异,所以来张图来理解一下吧,并且我很建议大家这块自行debug一下。
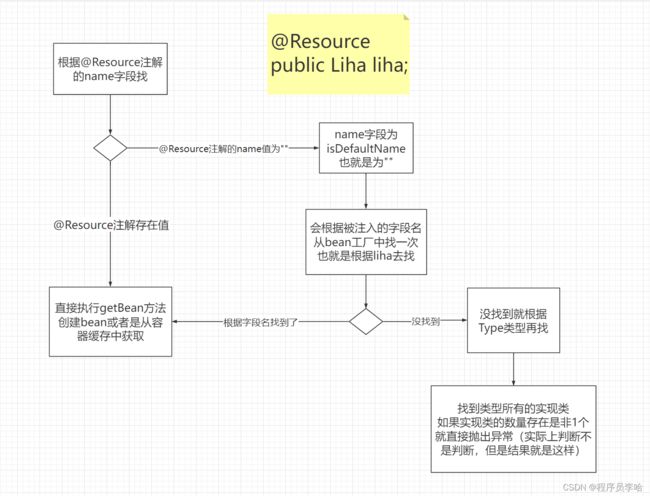
最后如果顺利的通过getBean()获取到实例以后,就回到了执行反射的地方了。
总结:
最后一部分逻辑有一点复杂,用文字来描述清楚,可能比较困难,所以也是特意有画图帮助读者理解。并且我非常建议自行debug。
最后,如果本帖对您有一定的帮助,希望能点赞+关注+收藏,您的支持是给我最大的动力。后续会一直更新各种框架的使用和框架的源码解读~!