【C++初阶:vector类】vector的介绍及使用 | 迭代器失效问题 | vector的深度剖析及模拟实现
文章目录
-
-
- 【写在前面】
- 一、vector的介绍及使用
-
- vector的介绍
- vector的使用
-
- 1、vector的定义
- 2、vector iterator的使用
- 3、vector空间增长问题
- 4、vector增删查改
- 5、vector迭代器失效问题(建议与vector的模拟实现一起分析)
- 6、vector在OJ中的使用
-
- 6.1、只出现一次的数字<难度系数⭐>
- 6.2、杨辉三角<难度系数⭐>
- 6.3、删除排序数组中的重复项<难度系数⭐>
- 6.4、只出现一次的数<难度系数⭐>
- 6.5、只出现一次的数<难度系数⭐>
- 6.6、数组中出现次数超过一半的数字<难度系数⭐>
- 6.7、电话号码字母组合<难度系数⭐>
- 6.8、连续子数组取大和<难度系数⭐>
- 二、vector的深度剖析及模拟实现
-
- std::vector的核心框架接口的模拟实现
- 使用memcpy拷贝问题
- 对bit::vector核心接口的测试
- 动态二维数组理解
-
【写在前面】
相比于 string,vector 的使用更加容易上手的,且它的接口比 string 要少上许多,再加上我们已经学过类似的 string,并且在数据结构篇的顺序表就已经触及过了。vector 在实际中也非常的重要,在实际中我们熟悉常见的接口就可以了。
在 vector 开始我们就可以尝试着去瞅一瞅 STL 的源码了,string 为什么没看的原因,在之前也说过,对于 string 是在 STL 这个规范前被设计出来的。我们的瞅的源码主要参考 P.J 版本和 SGI 版本。
怎么看 ❓
-
P.J
对如下代码打断点后调试,单步执行就可以查阅了

Visual Studio 2017 参考如下目录:
但是对于 P.J 版本的有些地方还涉及了 C++11 的优化,可能会看不懂,所以我们主要参考 SGI 版本。 -
SGI
这里有一本书《STL源码剖析》,它用的是 STL3.0 的版本,有需要的同学可私信电子版本。当然这本上核心的内容我们都会学习。

stl3.0 一览 ❓
-
解包后,找到 vector 并打开

-
找到 stl_vector.h 并打开(核心代码也就 500 多行)
-
怎么阅读
众所周知,看别人的代码是一件很痛苦的事情,如果他的水平高于你,那么你是能成长的,但是看的过程中不要一行一行的去看,这样会导致你只见树木不见森林。这里记住 “二八原则”,一个 1000 行的代码,只有 200 行是最核心的,只要把这 200 行看懂了,那么就都懂了。
-
核心代码简单筛选如下
需要查阅的文件:vector ➡ stl_vector.h ➡ stl_construct.h
vector
#include stl_vector.h
//这里的模板给的是缺省参数,也就意味着不传也行。Alloc是空间配置器,是一个内存池去申请和释放空间,我们直接用new也行,只不过内存池的效率要高一点
template <class T, class Alloc = alloc>
class vector {
public:
typedef T value_type;
typedef value_type* iterator;
protected:
//这里为啥没有看到指针、size、capacity之类的东西? ———— 我们可以先看下iterator是啥(在public里已经指明了)
//所以这里就给了三个T*的指针
iterator start;
iterator finish;
iterator end_of_storage;
public:
//其次还可以去看下它的构造函数,它完成了对3个成员变量的初始化工作
vector() : start(0), finish(0), end_of_storage(0) {}
//其次再看下push_back的实现
//现阶段我们看源码还是有些难度的,等到后期我们会深挖
void push_back(const T& x) {
//说明没满
if (finish != end_of_storage) {
//这里不是直接赋值,而是调用construct,原因这里要对一块已有的空间显示调用构造函数初始化,我们在stl_vector.h里并没有找到有关实现
//其实这里就要结合vector来看了,上面我们不是有一堆头文件嘛,那么它的实现肯定就在stl_vector.h上面的头文件中————stl_construct.h
construct(finish, x);//怎么实现的?
++finish;
}
//满了,增容
else
insert_aux(end(), x);//怎么实现的?
}
}
stl_construct.h
//construct是一个函数模板2
template <class T1, class T2>
inline void construct(T1* p, const T2& value) {
new (p) T1(value);//定位new表达式
}
补充
对于顺序表而言,虽然它改名为 vector 了,但它的实现跟以前的了解的还是大同小异的。

一、vector的介绍及使用
vector的介绍
vector的文档介绍
- vector 是表示可变大小数组序列 容器
- 就像数组一样,vector 也采用的连续存储空间来存储元素。也就是意味着可以采用下标对 vector 的元素进行访问,和数组一样高效。但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理
- 本质讲,vector 使用动态分配数组来存储它的元素。当新元素插入的时候,这个数组需要被重新分配大小为了增加存储空间。其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是一个相对代价高的任务,因为每当一个新的元素加入到容器的时候,vector 并不会每次都重新分配大小
- vector 分配空间策略:vector 会分配一些额外的空间以适应可能的增长,因为存储空间比实际需要的存储空间更大。不同的库采用不同的策略权衡空间的使用和重新分配。但是无论如何,重新分配都应该是对数组增长的间隔大小,以至于在末尾插入一个元素的时候是在常数时间的复杂度完成的
- 因此,vector 占用了更多的存储空间,为了获得管理存储空间的能力,并且以一种有效的方式动态增长
- 与其它动态序列容器相比(deques,lists and forward_lists), vector 在访问元素的时候更加高效,在末尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起 lists 和 forward_lists 统一的迭代器和引用更好
vector的使用
1、vector的定义
| (constructor)构造函数声明 | 接口说明 |
|---|---|
| ⭐vector() | 无参构造 |
| vector(size_type n, const value_type& val = value_type()) | 构造并初始化 n 个 val |
| ⭐vector(const vector& x) | 拷贝构造 |
| vector(InputIterator first, InputIterator last) | 使用迭代器进行初始化构造 |
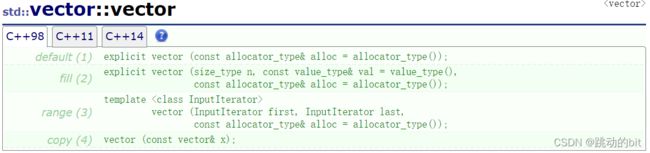
说明
-
default(1)
这里给的是一个缺省值,现在这个阶段我们只要看到 alloc 就可以直接忽略它,它是 STL 六大组件中的空间配置器。 -
fill(2)
value_type 是第一个模板参数,它是一个 \0


-
range(3)
这里的迭代器还是一个函数模板,也就是说这里的迭代器不一定是 vector 的迭代器
#include v3(s1.begin(), s1.end());//err,无法从char转换到char*
//怎么实现的
/*template
vector(InputIterator first, InputIterator last)
{
while(first != last)
{
push_back(*first);
++first;
}
}*/
//拷贝构造
vector<int> v4(v);
}
int main()
{
test_vector1();
return 0;
}
补充
-
List item
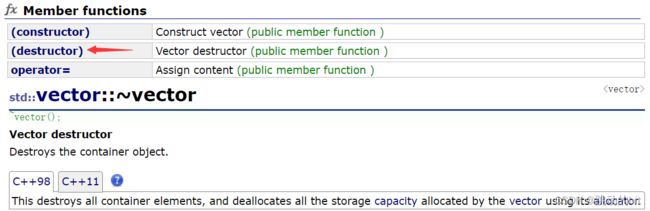
这里我们发现一个问题,我们在用容器时,都不关心析构,因为出了作用域它自动调用,但是你得知道析构函数的价值。 -
List item
vecor 是没有设计写时拷贝的,string 有可能设计了,并且之前也说了在 STL 容器上,写时拷贝也是存在缺陷的,所以并不是特别主流,g++ 下有用过,但好像后面还是舍弃了(这里后面会验证)
2、vector iterator的使用
| 接口 | 说明 |
|---|---|
| ⭐begin+end | 获取第一个位置的 iterator/const_iterator,获取最后一个数据的下一个位置的 iterator/const_iterator |
| rbegin+rend | 获取最后一个数据位置的 reverse_iterator,获取第一个数据的前一个位置的 reverse_iterator |

#include补充

3、vector空间增长问题
| 容量空间 | 接口说明 |
|---|---|
| size | 获取数据个数 |
| capacity | 获取容量大小 |
| empty | 判断是否为空 |
| ⭐resize | 改变 vector 的 size |
| ⭐reserve | 改变 vector 放入 capacity |

#include补充
-
List item
operator[] 和 at 的区别 ❓
它们的功能类似,区别点在于:operator[] 检查越界比较粗暴,如果下标大于等于 size,它会直接断言报错,并中止程序;而 at 报错会抛异常,捕获后,它不会直接中止掉程序。
-
List item
在 string 里也说明过了。这里vector 的 capacity 的代码在 vs 和 g++ 下分别运行会发现:vs 下 capacity 是按 1.5 倍增长的,且这里的初始容量是 0;g++ 是按 2 倍增长的,且这里的初始容量也是 0。这个问题经常会考察,不要固化的认为,顺序表的增容都是 2 倍,具体增长多少是根据具体的需求定义的。vs 是 PJ 版本的 STL,g++ 是 SGI 版本的 STL.
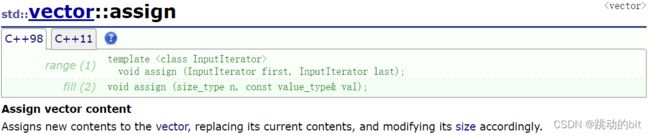
4、vector增删查改
| vector 增删查改 | 接口说明 |
|---|---|
| ⭐push_back | 尾插 |
| ⭐pop_back | 尾删 |
| find | 查找(注意这个是算法模块的实现,不是 vector 的成员接口) |
| insert | 在 position 之前插入 val |
| erase | 删除 position 位置的数据 |
| swap | 交换两个 vector 的数据空间 |
| ⭐operator[] | 像数组一样访问 |

#include gt;
sort(v.begin(), v.end(), gt);*/
sort(v.begin(), v.end(), greater<int>());//同上,更推荐使用匿名对象
//sort不仅可以对容器排序,还可以对数组排序,因为指向数组空间的指针是天然的迭代器
//也就是说从现在开始就可以把C语言的qsort放弃了
int b[] = { 30, 4, 50, 6, 7 };
sort(b, b + 5);
}
void test_vector4()
{
int a[] = { 1, 20, 2, 3, 4, 5 };
vector(int> v(a, a + 6);
//头删
v.erase(v.begin());
//删除2
vector<int>::iterator pos = find(v.begin, v.end(), 2);
if(pos != v.end))
{
v.erase(pos);
}
}
int main()
{
test_vector1();
test_vector2();
test_vector3();
test_vector4();
return 0;
}
说明
-
List item
-
List item

-
List item
operator[] 和 at 的区别 ❓
它们的功能类似,区别点在于:operator[] 检查越界比较粗暴,如果下标大于等于 size,它会直接断言报错;而 at 报错会抛异常,捕获后,它不会直接中止掉程序。
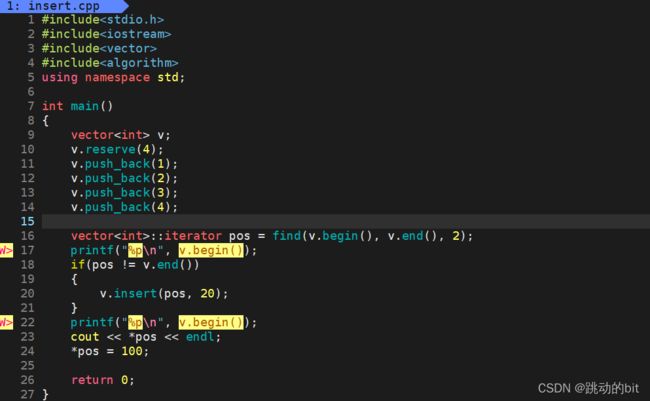
5、vector迭代器失效问题(建议与vector的模拟实现一起分析)
迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对指针进行了封装,比如:vector 的迭代器就是原生态指针 T*。因此迭代器失效,实际就是迭代器底层对应指针所指向的空间被销毁了(迭代器失效问题就类似于野指针问题),而使用一块已经被释放的空间,造成的后果就是程序崩溃(即如果继续使用已经失效的迭代器,程序可能会崩溃)
#include说明
-
List item
VS 下insert 时有两种情况(调试可证)

-
List item
已验,在 Linux g++ 下,test_vector1() 和 test_vector2() 都没有崩溃,这可能是因为不同的环境下,它的增容机制不同(可能一开始就有足够的空间),但要注意是虽然在 g++ 下没有崩溃,但是 pos 依然还是失效了,原因是 pos 的意义被改变了。
随后我们直接在 push_back 前先 reserve 4 个空间,让它达到增容的效果,之后再去访问和修改,它依然没有报错,这就推翻了上面说的增容机制不同。
我们又猜想 g++ 下 vector 的增容会不会是原地增容,而不需要另外开辟空间,但随后也印证了猜想是错误的,因为如果原地增容,*pos 的值就不会是 0 了。
所以这里十有八九 g++ 下并没有把野指针的访问修改操作检查出来(很早之前我们就说明了,关于内存的越界是抽查的形式),已验:把增容前后的 v.begin() 的地址打印出来(注意不是打印 pos,之前打印 pos 的地址两次都是一样,让豌豆误以为 g++ 下是原地扩容的机制,还和上面的 *pos 是 0 的矛盾纠结了好久)
-
List item
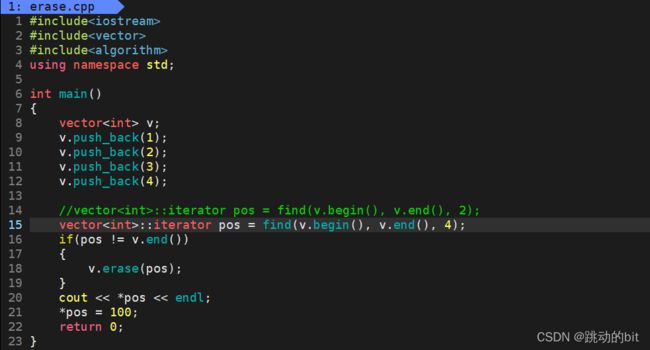
对于 test_vector3() 在 g++ 下没有报错,且打印的值是 3。这里就说明两个环境的检查机制不一样。但是无论这里的编译器是否报错,在 erase(pos) 后,我们都认为 pos 失效了,要注意的是失效后,就不要访问了,原因如下:
因为如果我 erase 的是最后一个数据的话,再去访问,那么程序本身就已经存在问题了。
还有些擦边球的情况,如下代码所示。这段代码无论如何,在 vs 下都一定会报错(上面说过了),但是在 Linux 下就有不同的境遇了。1、出现了段错误
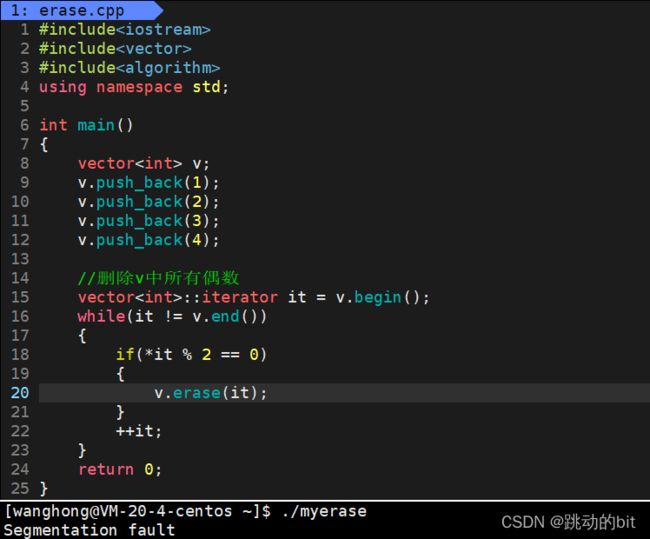
2、再 push_back 5,运行不会报错

为啥 push_back 5 后就不会报错了 ❓
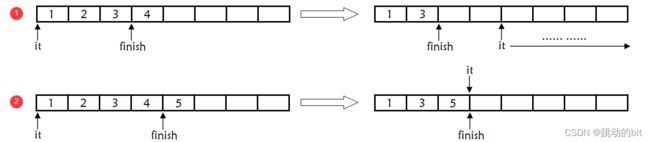
所以这里最后一个是偶数运行就会出现段错误,最后一个是奇数就让你避开了这个错误。所以这段代码的正确规范的写法应该如下

小结:对于失效的迭代器最好的方法就是不要去做任何的访问。1.我们在 insert 时分为两种情况:其一是原空间不够,需要扩容(原地扩、异地扩【VS 和 g++ 下都是异地扩】),之后 pos 还是指向原空间原位置的指针,所以 pos 就失效了,失效了再去访问就有可能会崩溃(VS 下会崩溃,g++ 下不会崩溃【检查内存越界是抽查的形式,不能说没被检查出能,我们就能随便酒驾】);其二是原空间足够,不需要扩容,之后 pos 还是指向原空间原位置,但是 *pos 的值已经被改变了,所以我们也认为它失效了,因为它的意义已经变了。所以说 insert(pos, x) 以后,都认为 pos 失效了,此时就不要再去使用 pos 了,不要说程序没有崩溃,就依然去使用它,否则可能会出现各种不可预测的结果,STL 只是一个理论,它只是告诉我们 insert 后,pos 会失效,但它并没有规定什么时候失效,哪种场景失效。
2.对于 erase,我们在 erase 后也可能会失效,失效的原因有两种:其一,你有没有想过这样一个问题,insert 会扩容,那么 erase 也会缩容(比如有 100 个容量的空间、100 个有效数据,现在删除后,只剩下 30 个有效数据,然后想把容量给缩容至一半【开 50 个容量的空间,把旧空间内容拷贝后释放,pos 就是野指针了】);其二,永远不动这块空间,直接把后面的数据往前覆盖。这两种方式有是有可能的,STL 并没有对它们进行规定,但是不管缩容与否,都认为它们失效了,因为意义已经变了。并且在 VS 下做了非常严格的检查(pos 仅仅是意义改变了,并没有野指针,都不能进行访问),而 g++ 下没有问题。
对于失效,我们也有对应的机制来处理:比如 insert 是有一个返回值的,它返回一个迭代器指向新插入的那个元素,也就是说你想去访问那个指向的新插入的元素就可以 pos 接收 insert 的返回值。同理 erase 也是一样的,它返回被删除数据的下一个数据的位置。

6、vector在OJ中的使用
6.1、只出现一次的数字<难度系数⭐>
题述:给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
⚠ 说明:你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗 ?
示例1:
输入: [2,2,1]
输出: 1
示例2:
输入: [4,1,2,1,2]
输出: 4
平台:Visual studio 2017 && windows
核心思想:使用异或操作符 ^ —— 相同为 0,相异为 1
leetcode原题
class Solution {
public:
int singleNumber(vector<int>& nums) {
int ret = 0;
//1、operator[]
/*for(size_t i = 0; i < nums.size(); ++i)
{
ret ^= nums[i];
}*/
//2、迭代器
/*vector::iterator it = nums.begin();
while(it != nums.end())
{
ret ^= *it;
++it;
}*/
//3、范围for
for(auto e : nums)
{
ret ^= e;
}
return ret;
}
};
6.2、杨辉三角<难度系数⭐>
题述:给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。在「杨辉三角」中,每个数是它左上方和右上方的数的和。
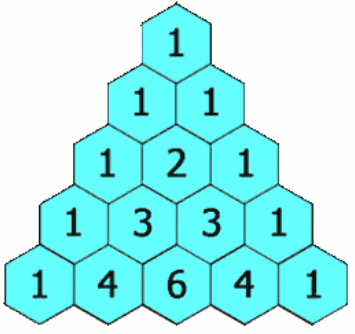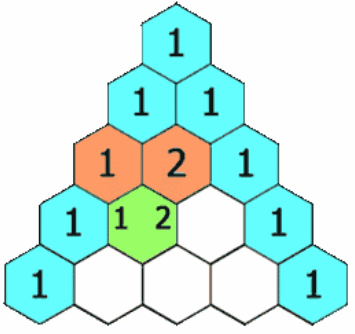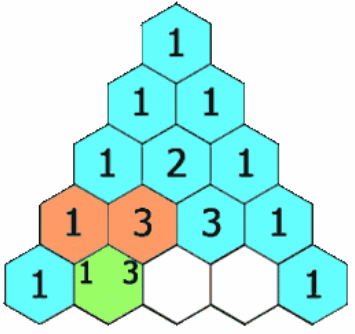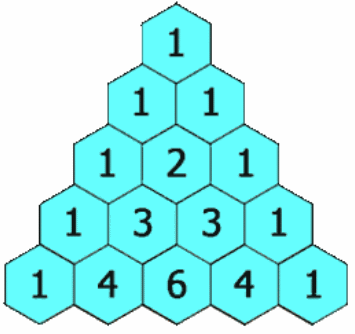
示例1:
输入:numRows = 5
输出:[ [1], [1,1], [1,2,1], [1,3,3,1], [1,4,6,4,1] ]
示例2:
输入:numRows = 1
输出:[ [1] ]
⚠提示:1 <= numRows <= 30
平台:Visual studio 2017 && windows
核心思想:需要先生成一个杨辉三角,每行的第一个和最后一个是 1,其余设置为 0,如果是 0,则需要计算。这里可以发现规律:1 = 1 + (1 - 1),这里以第一个要计算的值为例,且这里的数字代表的下标 —— 第 3 行以 1 为下标位置的值是等于第 2 行以 1 为下标的值加上第 2 行以 1 - 1 为下标的值。
leetcode原题
class Solution {
public:
//vector>就是一个二维数组,这里在vector模拟实现的时候也会细讲
vector<vector<int>> generate(int numRows) {
vector<vector<int>> vv;
vv.resize(numRows);
//生成
for(size_t i = 0; i < vv.size(); ++i)
{
//每行有多少个,并初始化为0
vv[i].resize(i + 1, 0);
//每一行的第一个和最后一个赋值为1
/*vv[i].front() = 1;
vv[i].back() = 1;*/
vv[i][0] = 1;
vv[i][vv[i].size() - 1] = 1;
}
//遍历
for(size_t i = 0; i < vv.size(); ++i)
{
for(size_t j = 0; j < vv[i].size(); ++j)
{
if(vv[i][j] == 0)//需要处理
{
vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];
}
}
}
return vv;
}
};
补充
这道题如果是用 C语言去写的话,就要动态开辟一个二维数组,写起来相对没有 C++ 的舒服。
6.3、删除排序数组中的重复项<难度系数⭐>
leetcode原题
6.4、只出现一次的数<难度系数⭐>
leetcode原题
6.5、只出现一次的数<难度系数⭐>
leetcode原题
6.6、数组中出现次数超过一半的数字<难度系数⭐>
leetcode原题
6.7、电话号码字母组合<难度系数⭐>
leetcode原题
6.8、连续子数组取大和<难度系数⭐>
nowcoder原题
二、vector的深度剖析及模拟实现
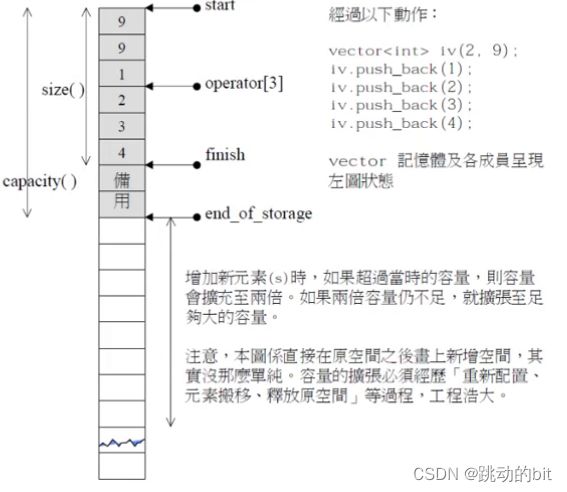
std::vector的核心框架接口的模拟实现
注意我们模拟实现不是把源码中的内容都搬下来,搞一个一模一样的东西,也不是造一个更好的轮子。模拟实现的目的是为了学习源码中的一些细节及核心框架。
vector.h
#pragma once
namespace bit
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
iterator begin()
{
return _start;
}
const_iterator begin() const
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator end() const
{
return _finish;
}
vector()
: _start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{}
//类模板的成员函数还可以再定义模板参数,这样写的好处是first/last可以是list等其它容器的迭代器,只要它解引用后的类型与T匹配
template<class InputIterator>
vector(InputIterator first, InputIterator last)
: _start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
//reserve(?)这个构造函数里传的是一段迭代器区间,只有对象才知道你有多少个容量
while(first != last)
{
push_back(*first);
++first;
}
}
//v2(v1)
//1、传统写法
/*vector(const vector& v)
{
_start = new T[v.capacity()];
memcpy(_start, v._start, sizeof(T) * v.size());
_finish = _start + v.size();
_endofstorage = _start + v.capacity();
}*/
//2、传统写法————复用当前的一些接口,本质还是自己开空间,这里相对于现代写法更推荐第二种传统写法,因为它这里提前把空间开好了,并利用
/*vector(const vector& v)
: _start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
reserve(v.capacity());//一次性开好空间
for(const auto& e : v)//引用的作用是为了防止T是string等
{
push_back(e);
}
}*/
//3、现代写法,sring那我们是取_str来构造一个临时对象再交换,但是这里怎么取所有的数据来构造并交换呢,没有法子
//这里有个法子:vector的构造函数里还提供了一个显示的迭代器(它可以传其它容器或原生指针做迭代器,但是原生指针必须要求指向的空间是连续的)
//所以这里还需要构造一个函数,这里的现代写法对比上面的传统写法并没有讨到便宜()
vector(const vector<T>& v)
: _start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
//现代写法里提前开空间没有意义,因为现代写法的空间是tmp去搞的,tmp没办法自己开,因为它不知道有多少个数据,那有人说用last-first,不敢减,因为比如list是不支持减的,它不是一段连续的空间
vector<T> tmp(v.begin(), v.end());
swap(tmp);
}
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endofstorage, v._endofstorage);
}
//v1 = v4;
//1、传统写法————不推荐(如果你能掌握现代写法,任何容器的深拷贝都推荐现代写法,尤其是赋值操作)
/*vector& operator=(const vector& v)
{
if(this != &v)
{
delete[]_start;
_start = _finish = _endofstorage = nullptr;
reserve(v.capacity());
for(const auto& e : v)
{
push_back(e);
}
}
return *this;
}*/
//2、现代写法,v就是去深拷贝的v4
vector<T>& operator=(vector<T> v)
{
//v是v1想要的,所以v1和v交换
swap(v);
return *this;
}
~vector()
{
delete[] _start;
_start = _finish = _endofstorage = nullptr;
}
size_t size() const
{
return _finish - _start;
}
size_t capacity() const
{
return _endofstorage - _start;
}
T& operator[](size_t i)
{
assert(i < size());
return _start[i];
}
const T& operator[](size_t i) const
{
assert(i < size());
return _start[i];
}
void reserve(size_t n)
{
if(n > capacity())
{
//备份一份
size_t sz = size();
T* tmp = new T[n];
if(_start)
{
//对于string,memcpy会引发更深层次的浅拷贝问题,具体如下说明
//memcpy(tmp, _start, sizeof(T) * size());
for(size_t i = 0; i < size(); ++i)
{
//如果T是string,它会调用string的operator=完成深拷贝
tmp[i] = _start[i];
}
delete[] _start;
}
_start = tmp;
_finish = _start + sz;
//_finish = _start + size();err,size去计算时,_finish还是旧空间的_finish,而_start却是新空间的_start了,所以_finish-_start就是一个负值,再加_start就是0
_endofstorage = _start + n;
}
}
//如果没有给值,就用默认值,如果T是int,那就是int的匿名对象。T是string,那就是stirng的匿名对象。它会调用对应的默认构造函数————int是0,double是0.0,指针就是空指针
//所以一般写一个类型,一定要提供一个不用参数就可以调的函数
void resize(size_t n, const T& val = T())
{
if(n <= size())
{
_finish = _start + n;
}
else
{
if(n > capacity())
{
reserve(n);
}
while(_finish < _start + n)
{
*_finish = val;
++_finish;
}
}
}
void push_back(const T& x)
{
/*if(_finish == _endofstorage)
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
//这里不用像源码中一样使用定位new,因为使用定位new的原因是finish指向的空间没有初始化,所以使用定位new把对象构造上去。但是我们这里的对象是new出来的,所以这里直接赋值即可
*_finish = x;
++_finish;*/
insert(end(), x);
}
void pop_back()
{
/*
//一般情况下--finish就行了,但是特殊情况vector为空时就不好
//所以一般需要assert
assert(!empty());
--_finish;*/
erase(--end());
}
iterator insert(iterator pos, const T& x)
{
//可以=_finish,因为它相当于尾插
assert(pos >= _start && pos <= _finish);
if(_finish == _endofstorage)
{
size_t len = pos - _start;
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
//reserve里会更新那三个成员变量,insert返回新插入的那个元素的地址,所以这里的pos需要先备份一下旧空间里与_start之间的长度,然后再在新空间里重新赋值
reserve(newcapacity);
pos = _start + len;
}
iterator end = _finish - 1;
while(end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x;
++_finish;
return pos;
}
iterator erase(iterator pos)
{
assert(pos >= _start && pos < _finish);
iterator it = pos + 1;
while(it != _finish)
{
*(it - 1) = *it;
++it;
}
--_finish;
return pos;
}
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
};
void print(const vector<int>& v)//const版本的迭代器和operator[]
{
vector<int>::const_iterator it = v.begin();
while(it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
for(size_t i = 0; i < v.size(); ++i)
{
cout << v[i] << " ";
}
cout << endl;
}
void test_vector1()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
vector<int>::iterator it = v.begin();
while(it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
for(size_t i = 0; i < v.size(); ++i)
{
cout << v[i] << " ";
}
cout << endl;
print(v);
}
void test_vector2()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
v.resize(2);
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
v.resize(4);
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
v.resize(10, 5);
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
}
void test_vector3()
{
//放string
vector<string> v;
string s("hello");
v.push_back(s);
v.push_back(string("hello"));
v.push_back("hello");
v.push_back("hello");
v.push_back("hello");
v.push_back("hello");
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
}
void test_vector4()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
vector<int>::iterator pos = find(v.begin(), v.end(), 2);
if(pos != v.end())
{
pos = v.insert(pos, 20);
}
cout << *pos << endl;
*pos = 100;
++pos;
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
}
void test_vector5()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
vector<int>::iterator pos = find(v.begin(), v.end(), 2);
if(pos != v.end())
{
v.erase(pos);
}
//在VS下这段代码是会崩溃的,但是我们很难做到的,但是在Linux下没有崩,所以这块我们就按Linux下实现
cout << *pos << endl;
*pos = 100;
}
void test_vector6()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
//删除v中所有偶数
vector<int>::iterator it = v.begin();
while(it != v.end())
{
if(*it % 2 == 0)
{
it = v.erase(it);
}
else
{
++it;
}
}
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
}
void test_vector7()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
vector<int> v2(v1);
for(auto e : v2)
{
cout << e << " ";
}
cout << endl;
//为什么现代写法里的构造函数的实现还需要再定义模板,而不使用T*或iterator
//因为如果是T*的话就写死了,你是其它容器的迭代器就不行了
string s("abcde");
vector<int> v3(v1.begin(), v1.end());
vector<int> v4(s.begin(), s.end());
//赋值
v1 = v4;
for(auto e : v1)
{
cout << e << " ";
}
cout << endl;
}
}
vector.cpp
//库里的string是一个typedef的类模板,当时在模拟的时候简化了
//这里的vector我们就实现成类模板了,在模板初阶里我们提过函数/类模板不支持把声明写到.h,定义写到.cpp的方式,会报链接错误,所以这里我们就不写vector.cpp了
test.cpp
#include补充
所有的容器我们都不推荐使用传统写法,尤其是后面要学的知识,现在的结构还比较简单,是数组(开好空间,memcpy就都过去了)。后面学到 list、map、树形结构等,就深拷贝时,要把数据拷贝就不是这么简单了。
使用memcpy拷贝问题
假设模拟实现的 vector 中的 reserve 接口中,使用 memcpy 进行的拷贝,以下代码会发生什么问题 ❓
vector<string> v;
string s("hello");
//第一次push,开了4块空间
v.push_back(s);
v.push_back(string("hello"));
v.push_back("hello");
v.push_back("hello");
//再次增容
v.push_back("hello");
v.push_back("hello");
在模拟实现 vector 时,还有一个深层次的浅拷贝问题:如果是 int 是不会出现问题的,问题出在 string 上,详细见下图:
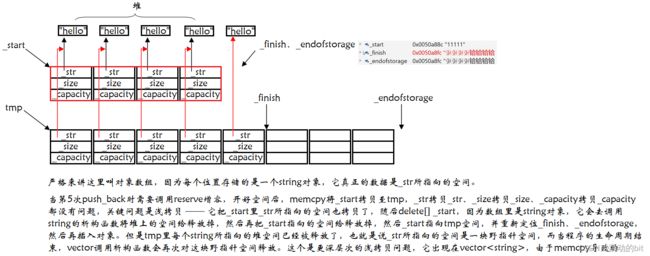 注意我们以前写的拷贝构造的传统写法,包括之前的 string 也面临这种问题。
注意我们以前写的拷贝构造的传统写法,包括之前的 string 也面临这种问题。
对bit::vector核心接口的测试
同上 test.cpp 文件
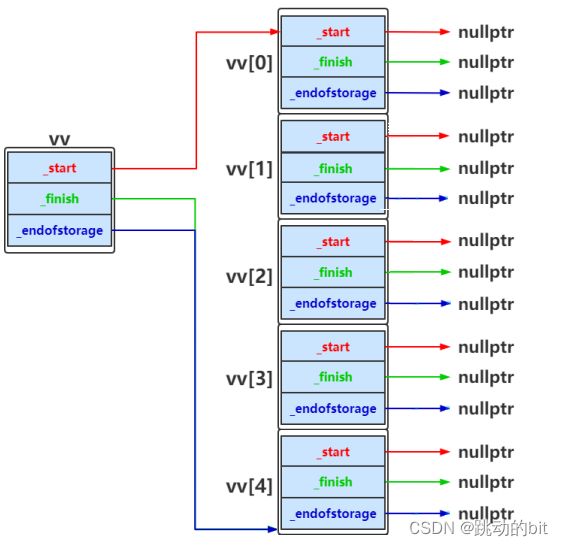
动态二维数组理解
//以杨慧三角的前n行为例:假设n为5
void test5(size_t n)
{
//使用vector定义二维数组vv,vv中的每个元素都是vector中的元素全部设置为1
for (size_t i = 0; i < n; ++i)
vv[i].resize(i + 1, 1);
//给杨慧三角中第一列和对角线的所有元素赋值
for (int i = 2; i < n; ++i)
{
for (int j = 1; j < i; ++j)
{
vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];
}
}
}
说明
bit::vector
vv 中元素填充完成之后,如下图所示:
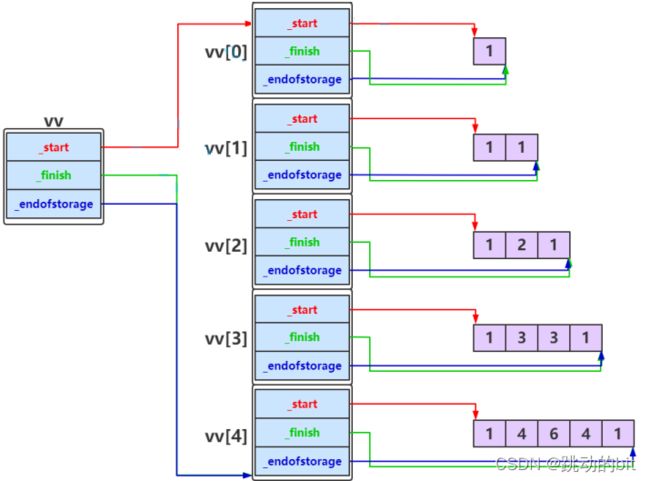
使用标准库中 vector 构建动态二维数组时与上图实际是一致的。