吴恩达深度学习学习笔记——C5W2——自然语言处理与词嵌入——作业1——词向量的操作
这里主要梳理一下作业的主要内容和思路,完整作业文件可参考:
https://github.com/pandenghuang/Andrew-Ng-Deep-Learning-notes/tree/master/assignments/C5W2
作业完整截图,参考本文结尾:作业完整截图。
Operations on word vectors(词向量的操作)
Welcome to your first assignment of this week!
Because word embeddings are very computionally expensive to train, most ML practitioners will load a pre-trained set of embeddings.
After this assignment you will be able to:
- Load pre-trained word vectors, and measure similarity using cosine similarity
- Use word embeddings to solve word analogy problems such as Man is to Woman as King is to __.
- Modify word embeddings to reduce their gender bias
Let's get started! Run the following cell to load the packages you will need.
...
1 - Cosine similarity(余弦相似度)
To measure how similar two words are, we need a way to measure the degree of similarity between two embedding vectors for the two words. Given two vectors and , cosine similarity is defined as follows:
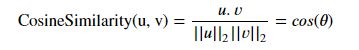
where . is the dot product (or inner product) of two vectors, ||||2 is the norm (or length) of the vector , and is the angle between and . This similarity depends on the angle between and . If and are very similar, their cosine similarity will be close to 1; if they are dissimilar, the cosine similarity will take a smaller value.

Figure 1: The cosine of the angle between two vectors is a measure of how similar they are
...
2 - Word analogy task(寻找同类词)
In the word analogy task, we complete the sentence "a is to b as c is to ____". An example is 'man is to woman as king is to queen' . In detail, we are trying to find a word d, such that the associated word vectors ,,, are related in the following manner: −≈−. We will measure the similarity between − and − using cosine similarity.
...
Congratulations!
You've come to the end of this assignment. Here are the main points you should remember:
- Cosine similarity a good way to compare similarity between pairs of word vectors. (Though L2 distance works too.)
- For NLP applications, using a pre-trained set of word vectors from the internet is often a good way to get started.
Even though you have finished the graded portions, we recommend you take a look too at the rest of this notebook.
Congratulations on finishing the graded portions of this notebook!
...
3 - Debiasing word vectors (OPTIONAL/UNGRADED)(词向量除偏)
In the following exercise, you will examine gender biases that can be reflected in a word embedding, and explore algorithms for reducing the bias. In addition to learning about the topic of debiasing, this exercise will also help hone your intuition about what word vectors are doing. This section involves a bit of linear algebra, though you can probably complete it even without being expert in linear algebra, and we encourage you to give it a shot. This portion of the notebook is optional and is not graded.
Lets first see how the GloVe word embeddings relate to gender. You will first compute a vector =−, where represents the word vector corresponding to the word woman, and corresponds to the word vector corresponding to the word man. The resulting vector roughly encodes the concept of "gender". (You might get a more accurate representation if you compute 1=ℎ−ℎ, 2=−, etc. and average over them. But just using − will give good enough results for now.)
...
3.1 - Neutralize bias for non-gender specific words(非性别特定词的除偏)
The figure below should help you visualize what neutralizing does. If you're using a 50-dimensional word embedding, the 50 dimensional space can be split into two parts: The bias-direction , and the remaining 49 dimensions, which we'll call ⊥. In linear algebra, we say that the 49 dimensional ⊥ is perpendicular (or "othogonal") to , meaning it is at 90 degrees to . The neutralization step takes a vector such as and zeros out the component in the direction of , giving us .
Even though ⊥ is 49 dimensional, given the limitations of what we can draw on a screen, we illustrate it using a 1 dimensional axis below.
...
3.2 - Equalization algorithm for gender-specific words(性别特定词的均衡算法)
Next, lets see how debiasing can also be applied to word pairs such as "actress" and "actor." Equalization is applied to pairs of words that you might want to have differ only through the gender property. As a concrete example, suppose that "actress" is closer to "babysit" than "actor." By applying neutralizing to "babysit" we can reduce the gender-stereotype associated with babysitting. But this still does not guarantee that "actor" and "actress" are equidistant from "babysit." The equalization algorithm takes care of this.
The key idea behind equalization is to make sure that a particular pair of words are equi-distant from the 49-dimensional ⊥. The equalization step also ensures that the two equalized steps are now the same distance from , or from any other work that has been neutralized. In pictures, this is how equalization works:
...
Congratulations
You have come to the end of this notebook, and have seen a lot of the ways that word vectors can be used as well as modified.
Congratulations on finishing this notebook!
References:
- The debiasing algorithm is from Bolukbasi et al., 2016, Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings
- The GloVe word embeddings were due to Jeffrey Pennington, Richard Socher, and Christopher D. Manning. (https://nlp.stanford.edu/projects/glove/)
作业完整截图: