从零到一实现神经网络(六):误差反向传播算法更新网络权重
目录
- 误差反向传播原理
-
- 单个神经元上的误差传播
- 更多层的误差传播
- 误差计算的矩阵表示
- 求函数梯度的新方法
-
- 输出层输出误差 e k e_k ek与权重参数的偏导数表达式推导
- 隐藏层输出误差 e j e_j ej与权重参数的偏导数表达式推导
- 初始权重的优化
- 神经网络中的信号传递
-
- 线代基础:矩阵相乘条件
- 信号正向传播过程图示
-
- 输入层到隐藏层
- 输入层的预处理
- 反向传播过程计算过程图示
- 三层神经网络框架
-
- 代码的最终实现
本博客参考书籍:python神经网络编程
误差反向传播原理
下图中,e=[e1,e2,e3,…]表示输出层各神经元的输出误差
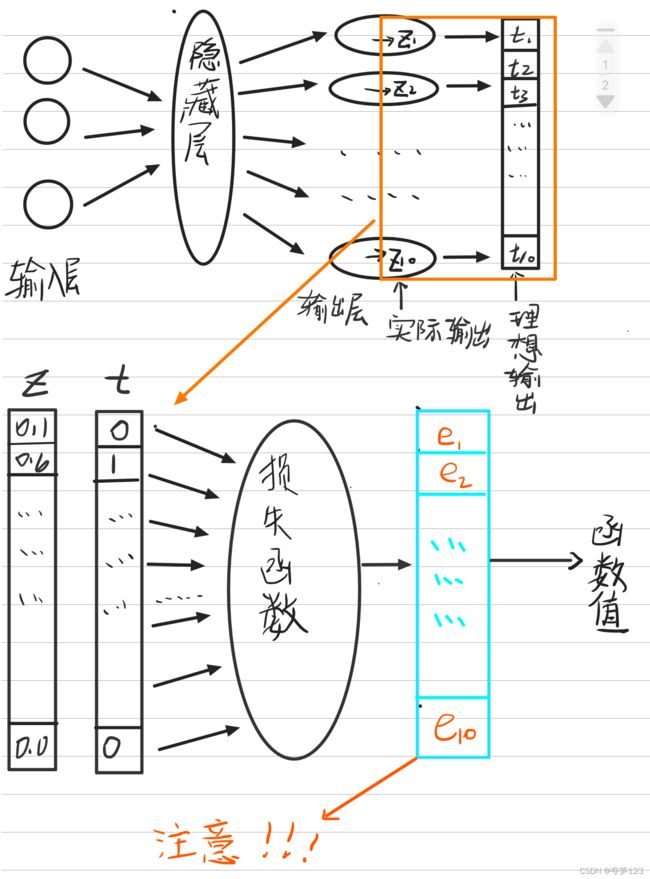
上面的章节我们知道,损失函数的函数值是所有输出神经元的输出值误差另一种表示,它的出现是为了将神经网络的表现量化。又因为输出层某一神经元的输出值是由上一层所有神经元输出值与其对应权重参数乘积的代数和,所以该输出层神经元的误差与上一层所有神经元(对应的权重参数)都有关(也就是说输出和误差是多个节点共同作用的结果),…,这样一层层地向上传播直到输入层,这便是误差能够反向传播进而影响到权重参数的原因
单个神经元上的误差传播
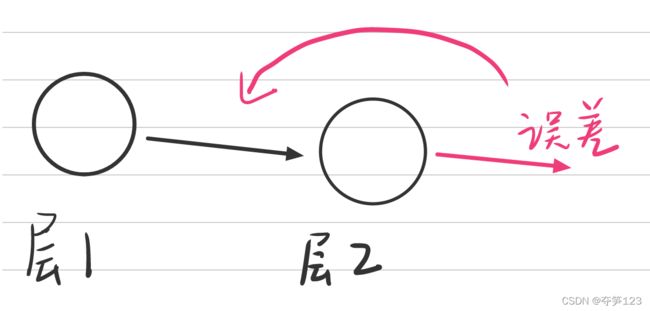
当某一神经元只有一个前馈信号(前一层只有一个神经元与之相链接)时,显而易见,该神经元所造成的误差全部由其前馈信号造成,误差直接向前传递即可
当有两个前馈信号时,误差如何合理分配?
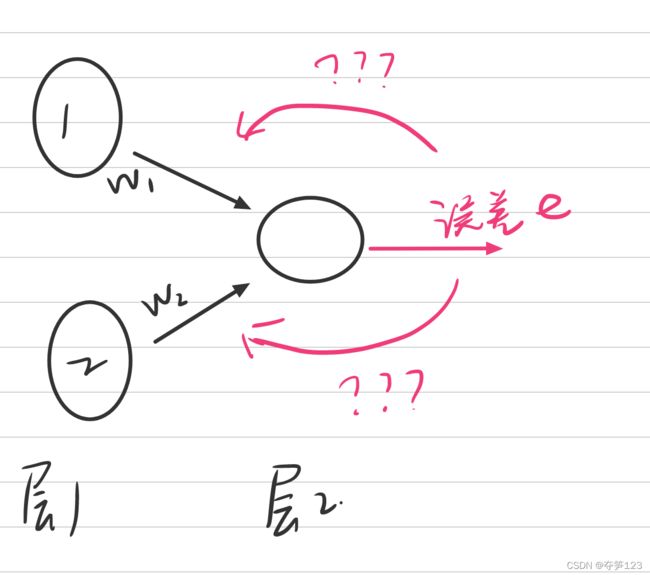
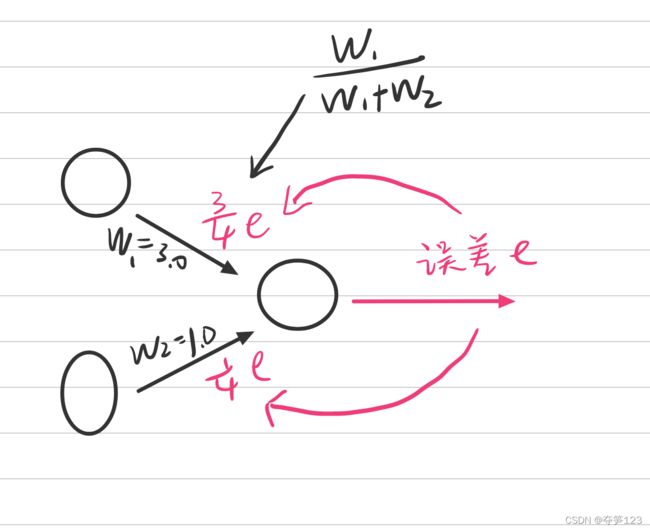
一种思想是我们按照权重分配,我们认为相对较大的权重对误差的贡献比例也较大,相应的它也应该分的更多的误差
更多层的误差传播
我们这里使用一个包含一个隐藏层的3层神经网络作为例子
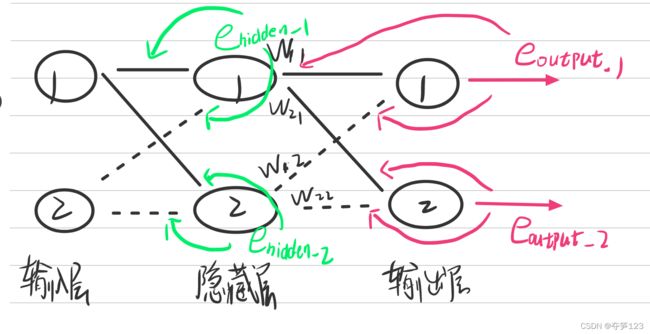
从上面的图片中我们可以看到每个神经元都能够得到下一层神经元传递过来的误差,其中
隐藏层第一个神经元得到的误差
e h i d d e n 1 = w 1 , 1 w 1 , 1 + w 1 , 2 ∗ e o u t p u t 1 + w 2 , 1 w 2 , 1 + w 2 , 2 ∗ e o u t p u t 2 e_{hidden_1}=\frac{w_{1,1}}{w_{1,1}+w_{1,2}}*e_{output_1}+\frac{w_{2,1}}{w_{2,1}+w_{2,2}}*e_{output_2} ehidden1=w1,1+w1,2w1,1∗eoutput1+w2,1+w2,2w2,1∗eoutput2
隐藏层第二个神经元得到的误差
e h i d d e n 2 = w 1 , 2 w 1 , 1 + w 1 , 2 ∗ e o u t p u t 1 + w 2 , 2 w 2 , 1 + w 2 , 2 ∗ e o u t p u t 2 e_{hidden_2}=\frac{w_{1,2}}{w_{1,1}+w_{1,2}}*e_{output_1}+\frac{w_{2,2}}{w_{2,1}+w_{2,2}}*e_{output_2} ehidden2=w1,1+w1,2w1,2∗eoutput1+w2,1+w2,2w2,2∗eoutput2
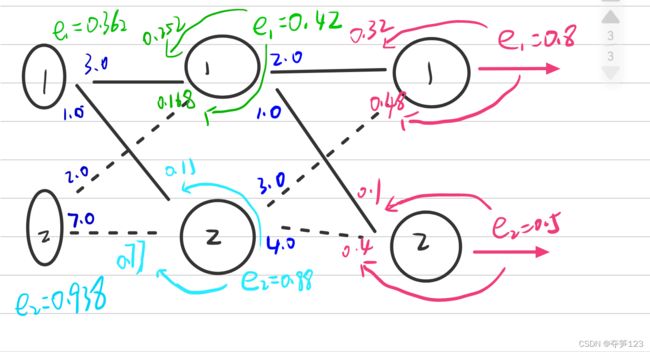
下面我们带入数值计算
误差计算的矩阵表示
上面我们推导出了隐藏层的两个神经元输出误差的数学表达式,当神经元数量增多时,这个式子将会变得十分繁琐,同时为了方便使用Numpy的广播机制,我们在这里使用矩阵表示
输出层的误差矩阵
e o u t p u t = ( e o u t p u t 1 e o u t p u t 2 ) e_{output}=\begin{pmatrix} e_{output_1}\\ e_{output_2} \end{pmatrix} eoutput=(eoutput1eoutput2)
隐藏层的误差矩阵
e h i d d e n = ( w 1 , 1 w 1 , 1 + w 1 , 2 w 2 , 1 w 2 , 1 + w 2 , 2 w 1 , 2 w 1 , 1 + w 1 , 2 w 2 , 2 w 2 , 1 + w 2 , 2 ) ∗ ( e o u t p u t 1 e o u t p u t 2 ) = ( e h i d d e n 1 e h i d d e n 2 ) e_{hidden}=\begin{pmatrix} \frac{w_{1,1}}{w_{1,1}+w_{1,2}}&\frac{w_{2,1}}{w_{2,1}+w_{2,2}}\\ &\\ \frac{w_{1,2}}{w_{1,1}+w_{1,2}}&\frac{w_{2,2}}{w_{2,1}+w_{2,2}} \end{pmatrix}*\begin{pmatrix}e_{output_1}\\ e_{output_2} \end{pmatrix}=\begin{pmatrix} e_{hidden_{1}}\\e_{hidden_{2}}\end{pmatrix} ehidden=⎝⎛w1,1+w1,2w1,1w1,1+w1,2w1,2w2,1+w2,2w2,1w2,1+w2,2w2,2⎠⎞∗(eoutput1eoutput2)=(ehidden1ehidden2)
我们看到,上面这个式子还是太复杂了,如何将其简化?
实际上,权重矩阵的每一个元素都带有一个分母,而这个分母的作用是归一化因子,所以如果我们将分母去除,那么我们得到的将会是
e h i d d e n = ( w 1 , 1 w 2 , 1 w 1 , 2 w 2 , 2 ) ∗ ( e o u t p u t 1 e o u t p u t 2 ) = ( e h i d d e n 1 e h i d d e n 2 ) e_{hidden}=\begin{pmatrix} w_{1,1}&w_{2,1}\\ &\\ w_{1,2}&w_{2,2} \end{pmatrix}*\begin{pmatrix}e_{output_1}\\ e_{output_2} \end{pmatrix}=\begin{pmatrix} e_{hidden_{1}}\\e_{hidden_{2}}\end{pmatrix} ehidden=⎝⎛w1,1w1,2w2,1w2,2⎠⎞∗(eoutput1eoutput2)=(ehidden1ehidden2)
关于这个化简的问题,推导过程笔者正在研究当中,不过在这里笔者还是有一个理解,我们如果将分母去掉,显然,隐藏层获得的误差应该会增大,但是隐藏层误差关于其权重参数的偏导也会成倍增大,梯度也会成倍增大,那么权重参数的更新幅度也会成倍增大,所以从这个角度来看,去掉分母可能并不会影响最终效果
求函数梯度的新方法
在误差反向传播算法中,还是需要求得函数的梯度,不过我们将不再使用数值微分的方法,下面我们从误差函数与权重参数的关系式入手
举一个包含一个隐藏层的3层神经网络作为例子,在该神经网络中中我们使用sigmoid函数作为输出层的映射函数,均方差误差函数作为损失函数
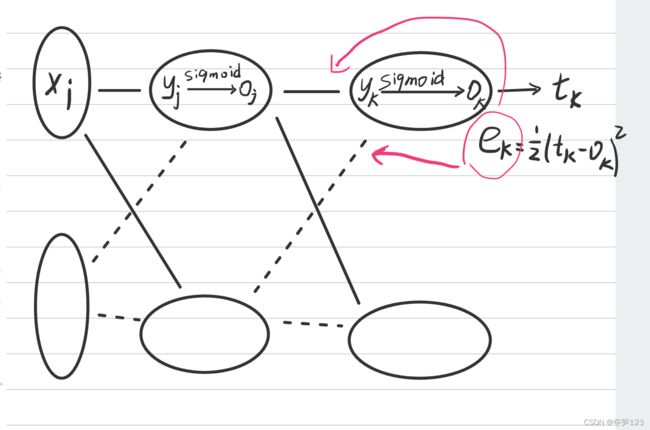
在输出层中使用sigmoid()函数可能有点少见,实际上这是可以的,该函数的输出范围在(0,1)之间,并且呈递增状,能够很多反映输出层拟输出中包含的特征,另外,该函数求导比较容易,在本实例中表现较好
输出层输出误差 e k e_k ek与权重参数的偏导数表达式推导
根据均方差损失函数 E = 1 2 ∑ n ( t n − o n ) 2 E=\frac{1}{2}\sum_{n}(t_{n}-o_{n})^{2} E=21∑n(tn−on)2,我们可以得到输出层某一神经元输出误差 e k = 1 2 ( t k − o k ) 2 e_k=\frac{1}{2}(t_{k}-o_{k})^{2} ek=21(tk−ok)2,由于 t k t_k tk是该神经元的理想输出,为一个常数,所以输出误差 e k e_k ek只与实际输出 o k o_k ok有函数关系
于是,该神经元的输出误差 e k e_{k} ek关于与之相连的权重参数的偏导数如下
∂ e k ∂ w k , j = 1 2 ∂ ∂ w k , j ( t k − o k ) 2 \frac{\partial e_{k}}{\partial w_{k,j}}=\frac{1}{2}\frac{\partial}{\partial w_{k,j}}(t_k-o_k)^{2} ∂wk,j∂ek=21∂wk,j∂(tk−ok)2
根据链式法则
∂ e k ∂ w k , j = ∂ e k ∂ o k ∂ o k ∂ w k \frac{\partial e_{k}}{\partial w_{k,j}}=\frac{\partial e_k}{\partial o_k}\frac{\partial o_k}{\partial w_k} ∂wk,j∂ek=∂ok∂ek∂wk∂ok
其中
∂ e k ∂ o k = − ( t k − o k ) \frac{\partial e_k}{\partial o_k}=-(t_k-o_k) ∂ok∂ek=−(tk−ok)
∂ o k ∂ w k = ∂ ∂ w k , j s i g m o i d ( ∑ j w k , j ∗ o j ) \frac{\partial o_k}{\partial w_k}=\frac{\partial}{\partial w_{k,j}}sigmoid(\sum_{j}w_{k,j}*o_j) ∂wk∂ok=∂wk,j∂sigmoid(j∑wk,j∗oj)
其中
∂ ∂ x s i g m o i d ( x ) = ∂ ∂ x 1 1 + e − x = e − x ( 1 + e − x ) 2 = 1 + ( − 1 ) + e − x ( 1 + e − x ) 2 = 1 1 + e − x ( 1 − 1 1 + e − x ) = s i g m o i d ( x ) ( 1 − s i g m o i d ( x ) ) \begin{aligned} \frac{\partial}{\partial x} sigmoid(x)&=\frac{\partial}{\partial x} \frac{1}{1+e^{-x}} \\ &=\frac{e^{-x}}{(1+e^{-x})^{2}}\\ &=\frac{1+(-1)+e^{-x}}{(1+e^{-x})^{2}}\\&=\frac{1}{1+e^{-x}}(1-\frac{1}{1+e^{-x}})\\&=sigmoid(x)(1-sigmoid(x)) \end{aligned} ∂x∂sigmoid(x)=∂x∂1+e−x1=(1+e−x)2e−x=(1+e−x)21+(−1)+e−x=1+e−x1(1−1+e−x1)=sigmoid(x)(1−sigmoid(x))
所以
令 t = ∑ j w k , j ∗ o j 令t=\sum_{j}w_{k,j}*o_j 令t=j∑wk,j∗oj
则 ∂ o k ∂ w k = ∂ s i g m o i d ( t ) ∂ t ∂ t ∂ w k , j = s i g m o i d ( t ) ( 1 − s i g m o i d ( t ) ∗ ∂ ∂ w k , j ( ∑ j w k , j ∗ o j ) = s i g m o i d ( ∑ j w k , j ∗ o j ) ( 1 − s i g m o i d ( ∑ j w k , j ∗ o j ) ) ∗ o j \begin{aligned} 则 \frac{\partial o_k}{\partial w_k}&=\frac{\partial sigmoid(t)}{\partial t}\frac{\partial t}{\partial w_{k,j}}\\ &=sigmoid(t)(1-sigmoid(t)*\frac{\partial}{\partial w_{k,j}}(\sum_jw_{k,j}*o_j)\\ &=sigmoid(\sum_{j}w_{k,j}*o_j)(1-sigmoid(\sum_{j}w_{k,j}*o_j))*o_j \end{aligned} 则∂wk∂ok=∂t∂sigmoid(t)∂wk,j∂t=sigmoid(t)(1−sigmoid(t)∗∂wk,j∂(j∑wk,j∗oj)=sigmoid(j∑wk,j∗oj)(1−sigmoid(j∑wk,j∗oj))∗oj
则
∂ e k ∂ w k , j = ∂ e k ∂ o k ∂ o k ∂ w k = − ( t k − o k ) ∗ s i g m o i d ( ∑ j w k , j ∗ o j ) ( 1 − s i g m o i d ( ∑ j w k , j ∗ o j ) ) ∗ o j \frac{\partial e_{k}}{\partial w_{k,j}}=\frac{\partial e_k}{\partial o_k}\frac{\partial o_k}{\partial w_k}=-(t_k-o_k)*sigmoid(\sum_{j}w_{k,j}*o_j)(1-sigmoid(\sum_{j}w_{k,j}*o_j))*o_j ∂wk,j∂ek=∂ok∂ek∂wk∂ok=−(tk−ok)∗sigmoid(j∑wk,j∗oj)(1−sigmoid(j∑wk,j∗oj))∗oj
又因为
o k = s i g m o i d ( ∑ j w k , j ∗ o j ) o_k=sigmoid(\sum_{j}w_{k,j}*o_j) ok=sigmoid(j∑wk,j∗oj)
所以
∂ e k ∂ w k , j = − e k ∗ o k ( 1 − o k ) ∗ o j T \frac{\partial e_{k}}{\partial w_{k,j}}=-e_k*o_k(1-o_k)*o_j^{T} ∂wk,j∂ek=−ek∗ok(1−ok)∗ojT
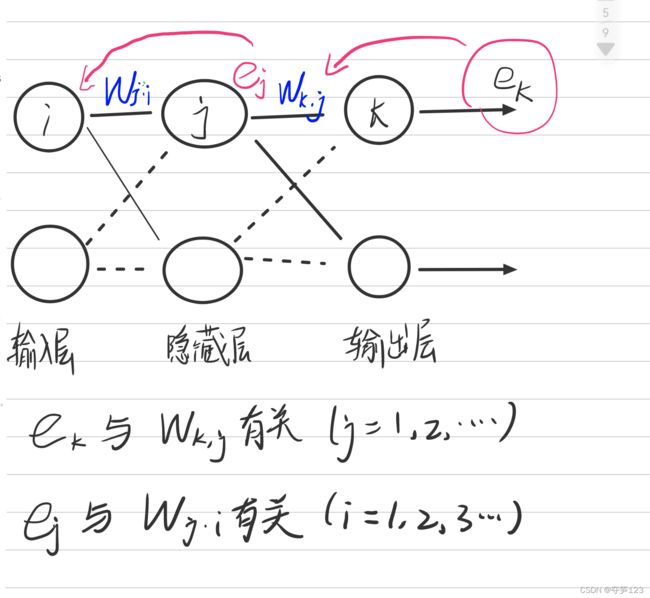
我们得到了输出层输出误差 e k e_{k} ek关于与之相连的权重参数的偏导数的数学表达式,那么
Δ w k , j = η ∂ e k ∂ w k , j \Delta w_{k,j}=\eta\frac{\partial e_k}{\partial w_{k,j}} Δwk,j=η∂wk,j∂ek
隐藏层输出误差 e j e_j ej与权重参数的偏导数表达式推导
同理,我们可以得到隐藏层输出误差 e j e_{j} ej关于与之相连的权重参数的偏导数的数学表达式
∂ e j ∂ w j , i = − e j ∗ o j ( 1 − o j ) ∗ o i T \frac{\partial e_{j}}{\partial w_{j,i}}=-e_j*o_j(1-o_j)*o_i^{T} ∂wj,i∂ej=−ej∗oj(1−oj)∗oiT
Δ w j , i = η ∂ e j ∂ w j , i \Delta w_{j,i}=\eta\frac{\partial e_j}{\partial w_{j,i}} Δwj,i=η∂wj,i∂ej
初始权重的优化
由于在输出层我们使用sigmoid()函数作为映射函数,而sigmoid()函数的缺点就是容易导致网络饱和,我们可以将权重设置为[0,1]之间的均匀分布
self.w_i_h=np.random.rand(self.h_node,self.inode)-0.5 # 输入层与隐藏层之间的权重参数
self.w_h_o=np.random.rand(self.o_node,self.h_node)-0.5
实际上根据相关学者对于初始权重参数的设定的研究表明,对于特定形状的网络,特定的激活函数,初始权重参数是固定的。他们得出的结论大致为:一个节点传入链接数量平方根的倒数范围内随机取样,比如输出层每个神经元有3个传入链接,那么隐藏层与输出层之间的初始权重就应该在 ( − 1 3 , 1 3 ) (-\frac{1}{\sqrt{3}},\frac{1}{\sqrt{3}}) (−31,31)之间
self.w_i_h=np.random.normal(0.0,pow(self.h_node,-0.5),(self.h_node,self.i_node))
self.w_h_o=np.random.normal(0.0,pow(self.o_node,-0.5),(self.h_node,self.i_node))
神经网络中的信号传递
线代基础:矩阵相乘条件
为了方便表示众多权重参数以方便计算,我们引入了矩阵
矩阵相乘的条件:左矩阵的列数等于右矩阵行数,如下图
( a 11 a 12 a 21 a 22 a 31 a 32 ) ∗ ( b 11 b 21 ) = ( a 11 b 11 + a 12 b 21 a 21 b 11 + a 22 b 21 a 31 b 11 + a 32 b 21 ) \begin{pmatrix} a_{11}&a_{12}\\ a_{21}&a_{22}\\ a_{31}&a_{32} \end{pmatrix} *\begin{pmatrix} b_{11}\\ b_{21} \end{pmatrix}=\begin{pmatrix} a_{11}b_{11}+a_{12}b_{21}\\ a_{21}b_{11}+a_{22}b_{21}\\ a_{31}b_{11}+a_{32}b_{21} \end{pmatrix} ⎝⎛a11a21a31a12a22a32⎠⎞∗(b11b21)=⎝⎛a11b11+a12b21a21b11+a22b21a31b11+a32b21⎠⎞
相乘前后,矩阵维度变化 :(行,列)
( 3 , 2 ) ∗ ( 2 , 1 ) = ( 3 , 1 ) (3,2)*(2,1)=(3,1) (3,2)∗(2,1)=(3,1)
结论:相乘后得到的矩阵 行数等于左矩阵,列数等于右矩阵
信号正向传播过程图示
输入层到隐藏层
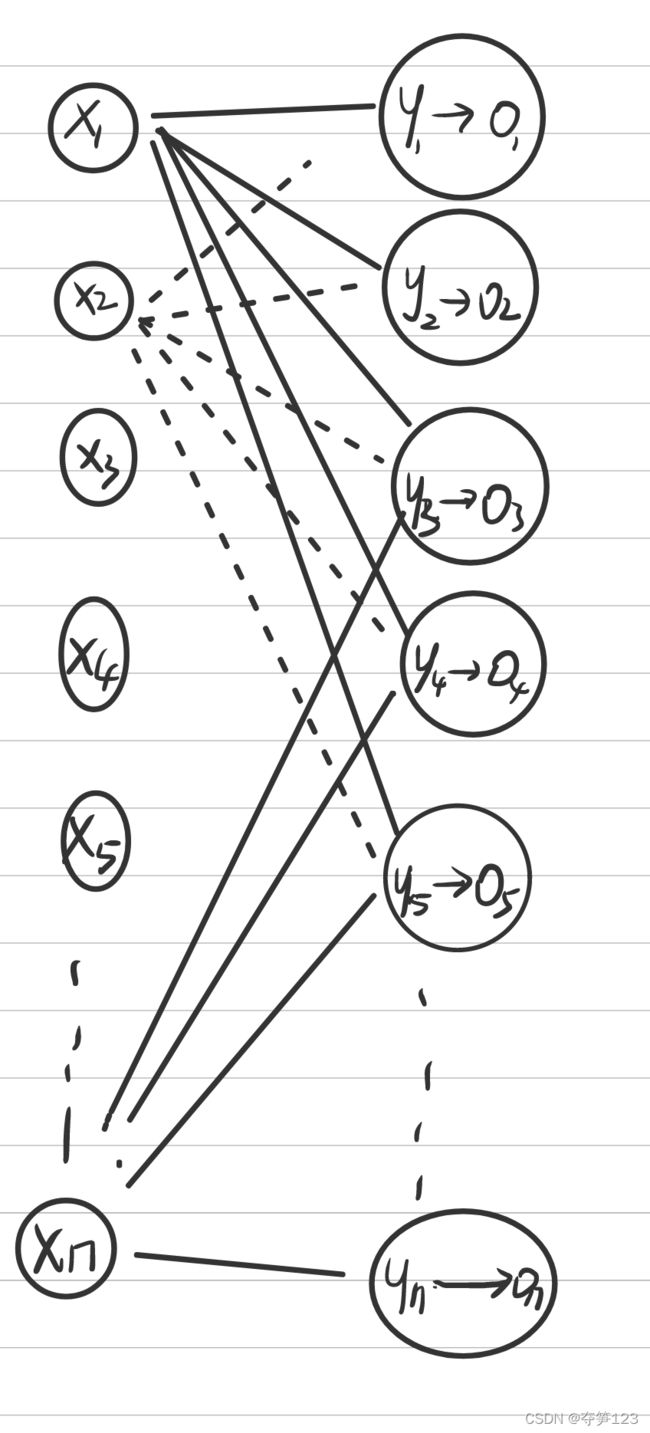
输入层的预处理
如我们看到的那样,输入层的每个神经元都是一个输入数据,我们通常使用列表表示一组输入数据: i n p u t s = [ x 1 , x 2 , x 3 , . . . , x n ] inputs=[x_1,x_2,x_3,...,x_n] inputs=[x1,x2,x3,...,xn],这样的数据不满足矩阵相乘的条件
因此我们将上述数组转化为numpy数组表示
i n p u t s = a r r a y ( [ [ x 1 , x 2 , x 3 , . . . . , x n ] ] ) \begin{aligned} inputs=array([[&x_1,\\ &x_2,\\ &x_3,\\ &....,\\ &x_n]]) \end{aligned} inputs=array([[x1,x2,x3,....,xn]])
矩阵表示为
i n p u t s = ( x 1 x 2 x 3 . . . x n ) inputs=\begin{pmatrix} x_1\\ x_2\\ x_3\\ ...\\ x_n \end{pmatrix} inputs=⎝⎜⎜⎜⎜⎛x1x2x3...xn⎠⎟⎟⎟⎟⎞
| 层/参数 | 矩阵 | 维度 | 符号表示 | 计算过程 |
|---|---|---|---|---|
| 输出层 | 实际输出矩阵 | (onode,1) | o_output | sigmoid(o_input) |
| 拟输出矩阵 | (onode,1) | o_input | np.dot(w_o,h_output) | |
| 权重参数 | (onode,hnode) | w_o | ||
| 隐藏层 | 实际输出矩阵 | (hnode,1) | h_output | sigmoid(h_input) |
| 拟输出矩阵 | (hnode,1) | h_input | np.dot(w_h,inputs) | |
| 权重参数 | (hnode,inode) | w_h | ||
| 输入层 | 输出矩阵 | (inode,1) | inputs |
反向传播过程计算过程图示
| 层/权重 | 维度 | 符号表示 | 计算过程 |
|---|---|---|---|
| 输出层 | (onode,1) | o_error | targets-o_output |
| 权重更新 | (onode,1)*(1,hnode) | w_o+=lr * np.dot((o_error* o_output* (1.0 - o_output)), h_output.T) | |
| 隐藏层 | (hnode,1) | h_error | np.dot(w_o.T,o_error) |
| 权重更新 | (hnode,1)*(1,inode) | w_h+=lr * np.dot((h_error* h_output* (1.0 - h_output)), inputs.T) |
三层神经网络框架
class Threelayer_net:
def __init__(self,i_node,h_node,o_node,learningrate): # 设置网络的一些参数
pass
def predict(self,input_): # 使用网络进行预测
pass
def train(self,input_,target_): # 训练网络,更新参数
pass
代码的最终实现
class Threelayer_net:
def __init__(self, inode, hnode, onode, learningrate):
self.inode = inode
self.hnode = hnode
self.onode = onode
# 权重参数初始化
self.wh = np.random.normal(0.0, pow(self.inode, -0.5), (self.hnode, self.inode))
self.wo = np.random.normal(0.0, pow(self.hnode, -0.5), (self.onode, self.hnode))
# 设置学习率
self.lr = learningrate
def train(self, input_, target_): # 训练网络
inputs = np.array(input_, ndmin=2).T
targets = np.array(target_, ndmin=2).T
# 隐藏层神经元
h_input = np.dot(self.wh, inputs)
h_output = sigmoid(h_input)
# 输出层神经元
o_input = np.dot(self.wo, h_output)
o_output = sigmoid(o_input)
# 计算误差并反向传播
o_error = targets - o_output
h_error = np.dot(self.wo.T, o_error)
# 权重更新,关于这里的权重参数是加减的问题,实际上并没有影响,权重过大会导致输出增大,误差变为负数,这样的结果会反过来使得权重减小
self.wo += self.lr * np.dot((o_error * o_output * (1.0 - o_output)),h_output.T)
self.wh+=self.lr*np.dot((h_error*h_output*(1.0-h_output)),inputs.T)
return o_error
def predict(self,input_): # 预测数据
inputs=np.array(input_,ndmin=2).T
h_input=np.dot(self.wh,inputs)
h_output=sigmoid(h_input)
o_input=np.dot(self.wo,h_output)
o_output=sigmoid(o_input)
return o_output
笔者将模型的训练过程放在了码云,请参考:训练过程源码
另外,本博客参考:《python神经网络编程》作者的github源码