【StyleGAN代码学习】StyleGAN模型架构
完整StyleGAN笔记:http://www.gwylab.com/pdf/Note_StyleGAN.pdf
基于StyleGAN的一个好玩的网站:www.seeprettyface.com
—————————————————————————————————
第二章 StyleGAN代码解读(上)
这一章将对StyleGAN的代码进行非常细致的分析和解读。一方面有助于对StyleGAN的架构和原理有更深的认识,另一方面是觉得AdaIN的思想很有价值,希望把它写代码的技巧学习下来,以后应该在GANs中会有很多能用得上的地方(其它paper里挺多出现了AdaIN的地方)。含有中文注释的代码可以在这里获得。
2.1 StyleGAN代码架构总览

图2.1 StyleGAN官方代码架构
如图2.1所示,StyleGAN代码的封装与解耦做的非常细致,可见作者的代码功底是非常扎实的。简单来说,在dnnlib文件夹下封装了日志提交工具、tensorflow环境配置与网络处理工具以及一些杂项实用类函数,这个文件夹尽量不要去动;在metrics文件夹下定义了许多指标计算方法,包括FID、LS、PPL指标以及一些GANs的通用指标计算方法;而training文件夹是需重点关注的部分,里面包含了数据处理、模型架构、损失函数和训练过程等基于StyleGAN的核心内容,在接下来的笔记中也会重点对这一部分进行细致讲解;最后,在主目录下,有一些全局配置、功能展示和运行接口的代码,其中train.py值得细读一下,它是训练StyleGAN网络的主要切入点。
在接下来的笔记中,将从三个部分解读StyleGAN的代码,分别是:模型架构、损失函数和训练过程。至于其它部分的代码,由于我并不是特别关注,就不再赘述了。
2.2 网络架构代码解读
StyleGAN的网络架构全都写在training/networks_stylegan.py下,主要包括四个组成部分(代码302行-659行):G_style(),G_mapping(),G_synthesis()和D_basic()。
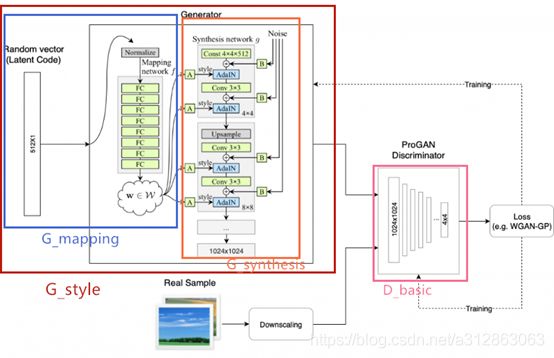
如上图所示,G_style表示整个生成器的网络架构,它由两个子网络组成,分别是映射网络G_mapping和合成网络G_synthesis;然后D_basic表示整个判别器的网络架构,它沿用了ProGAN中的模型设计。
2.2.1 G_style网络
G_style网络位于代码302-379行。在G_style中定义的组件包括:参数验证->设置子网络->设置变量->计算映射网络输出->更新W的移动平均值->执行样式混合正则化->应用截断技巧->计算合成网络输出。其中设置子网络就是调用构建G_mapping和G_synthesis的过程,两个子网络的定义将在下两节介绍。
· G_style输入参数(line303-315)

输入参数包括512维的Z码向量和条件标签(在FFHQ数据集上没有使用标签),和一些可选的参数,包括截断参数、计算移动平均值W时的参数、样式混合参数、网络状态参数和子网络的参数们等。
· 参数验证(line318-330)
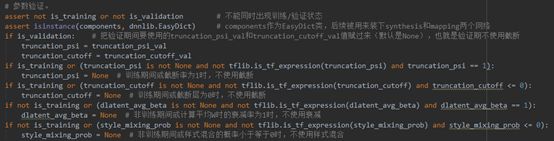
对输入参数进行验证,主要是对网络状态和其对截断率、W平均值衰减率和样式混合概率的关系之间进行验证。
· 设置子网络(line333-338)

直接使用tflib.Network()类(充当参数化网络构建功能的便捷包装,提供多种实用方法并方便地访问输入/输出/权重)创建两个子网络,子网络的内容在后面的函数(func_name = G_synthesis或func_name = G_mapping)中被定义。
· 设置变量(line341-342)
![]()
设置两个变量lod_in和dlatent_avg。前者决定当前处在第几层分辨率,即lod=resolution_log2–res(其中res表示当前层对应的分辨率级别(2-10));后者决定截断操作的基准,即生成人脸的dlatent码的平均值。
· 计算映射网络输出(line345)

得到映射网络的输出,即中间向量W’。
· 更新W的移动平均值(line348-353)

把batch的dlatent平均值朝着总dlatent平均值以dlatent_avg_beta步幅靠近,作为新的人脸dlatent平均值,即dlatent_avg。
· 执行样式混合正则化(line356-366)

样式混合正则化其实很好理解,就是随机创建一个新的潜码,这个潜码以一定概率与原始潜码交换某一部分,对于交换后的混合潜码,其生成的图片也要能够逼真,这就是样式混合正则化的实现。
· 应用截断技巧(line369-374)
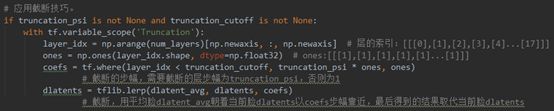
截断是指,用平均脸dlatent_avg朝着当前脸dlatents以coefs步幅靠近,得到的结果就是截断的dlatents。
· 计算合成网络输出(line377-379)

将截断的dlatents传给G_synthesis网络进行合成,得到的结果就是整个生成网络G_style的输出结果。
2.2.2 G_mapping网络

G_mapping网络位于代码384-435行。如上图所示,G_mapping网络实现了从初始生成码到中间向量的映射过程。在G_mapping中定义的组件包括:输入->连接标签->归一化潜码->映射层->广播->输出。其中映射层由8个全连接层组成。
· G_mapping输入参数(line385-398)

输入参数包括512维的Z码向量和条件标签(在FFHQ数据集上没有使用标签),和一些可选的参数,包括初始向量Z参数、中间向量W参数、映射层设置、激活函数设置、学习率设置以及归一化设置等。
· 网络输入(line403-407)

处理好latent的大小和格式后,其值赋给x,即用x标识网络的输入。
· 连接标签(line410-414)

原始StyleGAN是无标签训练集,这部分不会被调用。
· 归一化潜码(line417-418)
![]()
pixel_norm()(line239-242)

逐像素归一化的实现方式为: ,其中ϵ=10^-8。
,其中ϵ=10^-8。
为何要使用pixel_norm呢? Pixel norm,它是local response normalization的变种,具有避免生成器梯度爆炸的作用。Pixel norm沿着channel维度做归一化(axis=1),这样归一化的一个好处在于,feature map的每个位置都具有单位长度。这个归一化策略与作者设计的Generator输出有较大关系,注意到Generator的输出层并没有Tanh或者Sigmoid激活函数。
· 映射层(line421-426)

构建了mapping_layers层映射层,每个映射层有三个组成部分:全连接层dense()、偏置函数apply_bias()和激活函数act()。
1)全连接层dense()(line 154-159)

dense()函数中首先将输出全部展平以计算输出维度,然后调用get_weight()创建全连接层w,最后返回x与w的矩阵相乘的结果,作为dense()层的输出。
get_weight()(line 135-149)
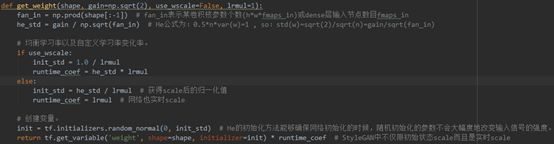
get_weight()函数是用来创建卷积层或完全连接层,且获取权重张量的函数。
值得注意的是,get_weight()采用了He的初始化方法。He的初始化方法能够确保网络初始化的时候,随机初始化的参数不会大幅度地改变输入信号的强度。StyleGAN中不仅限初始状态scale而且也是实时scale。
2)添加偏置apply_bias()(line 213-218)

对给定的激活张量施加偏差。
3)激活函数act()(line 400)
![]()
激活函数采用mapping_nonlinearity的值,StyleGAN中选用’lrelu’,且增益值为√2。
注意这儿的gain是一个增益值,增益值是指的非线性函数稳态时输入幅度与输出幅度的比值,通常被用来乘在激活函数之后使激活函数更加稳定。常见的增益值包括:Sigmoid推荐的增益值是1,Relu推荐的增益值是√2,LeakyRelu推荐的增益值是![]() 。
。
· 广播(line429-431)
![]()
这儿只定义了简单的复制扩充,广播前x的维度是(?,512),广播后x的维度是(?,18,512)。
· 输出(line 434-435)
![]()
广播后的中间向量,就是G_mapping网络的最终输出。
2.2.3 G_synthesis网络

G_synthesis网络位于代码441-560行。如上图所示,G_synthesis网络实现了从广播得到的中间向量到生成图片的合成过程。在G_synthesis中定义的组件包括:预处理->主要输入->噪音输入->★每层层末的调制功能->早期层(4*4)结构->剩余层的block块->★网络增长变换过程->输出。其中,每层层末的调制功能是指的在卷积之后,融入噪音与样式控制的过程(上图的⊕与AdaIN过程);网络增长变换过程是指的在训练时期,合成网络的架构动态增长,以生成更高分辨率图片的过程。上述两个内容是重点值得学习的部分。
· G_synthesis输入参数(line441-462)

输入参数包括512维的中间向量(W)和输出图片的分辨率及通道,和一些可选的参数,包括各层特征图的设置、样式/网络起始值/噪音设置、激活函数设置、数据处理设置以及网络增长架构的设置等。
· 预处理(line464-474)

预处理部分除了进一步细化网络配置以外,还定义了两个函数——nf()返回在第stage层中特征图的数量;blur()对图片进行滤波模糊操作,有利于降噪,其中blur的函数实现方式为blur2d()。
blur2d ()(line 96-106)

在blur2d()里定义了模糊的返回函数为_blur2d(),同时blur2d()的一阶导和二阶导也被定义了出来,都是直接使用_blur2d()函数作为近似。
_blur2d ()(line 22-49)
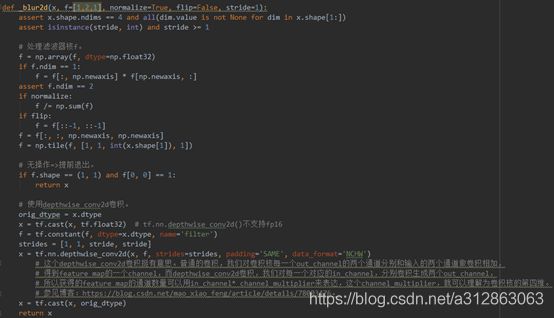
_blur2d ()的实现主要有两个部分,第一个部分是对于卷积核的处理,包括维度的规范和归一化处理;第二个部分是模糊的实现,即用卷积核对x实行depthwise_conv2d卷积。
注意:depthwise_conv2d与普通的卷积有些不同。普通的卷积对卷积核每一个out_channel的两个通道分别和输入的两个通道做卷积相加,得到feature map的一个channel,而depthwise_conv2d卷积对每一个对应的in_channel,分别卷积生成两个out_channel,所以获得的feature map的通道数量可以用in_channel * channel_multiplier来表达,这个channel_multiplier,就可以理解为卷积核的第四维。参见博客:https://blog.csdn.net/mao_xiao_feng/article/details/78003476。
· 主要输入(line 477-479)

主要输入除了dlatents_in之外,还有一个lod_in参数。lod_in是一个指定当前输入分辨率级别的参数,规定lod = resolution_log2 – res。lod_in在递归构建模型架构的部分中被使用。
· 创建噪音(line 482-487)

最初创建噪音时,只是依据对应层的分辨率创建对应的shape,然后随机初始化即为一个噪音。
· ★层末调制(含AdaIN,line490-501)

层末调制,是在每个block的卷积之后对特征的处理,包含6种(可选)内容:应用噪音apply_noise()、应用偏置apply_bias()、应用激活函数act()、逐像素归一化pixel_norm()、实例归一化instance_norm()和样式调制(AdaIN)style_mod()。其中apply_bias()、act()与pixel_norm()在前文中已提及过,下面将不再赘述。
1)apply_noise()(line 270-278)

应用噪音,直接将噪音加在特征x上就行了,注意按channel叠加。
2)instance_norm()(line 247-256)
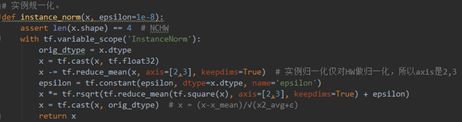
实例归一化是一个在生成模型中应用非常广泛的归一化方式,它的主要特点是仅对特征的HW(高和宽)维度做归一化,对图像的风格影响明显。
3)★style_mod ()(line 261-265)

样式控制(AdaIN)的代码只有3行。第1行是仿射变化A,它通过全连接层将dlatent扩大一倍;第2行将扩大后的dlatent转换为放缩因子y_(s,i)和偏置因子y_(b,i);第3行是将这两个因子对卷积后的x实施自适应实例归一化。
· 早期层结构(line 504-514)

由于StyleGAN的网络结构随训练进行是动态变化的,所以代码中定义了训练最开始时的网络结构,即4*4分辨率的生成网络。StyleGAN的生成起点选用维度为(1,512,4,4)的常量,通过一个卷积层(conv2d)得到了通道数为nf(1)(即512维)的特征图。
· conv2d(line 164-168)

conv2d通过简单的卷积实现,将x的通道数由x.shape[1]变为fmaps,而x的大小不变。
· 剩余层的block块(line 517-527)

StyleGAN将剩余分辨率的网络层封装成了block函数,方便在训练过程中依据输入的res(由lod_in计算出来)实时构建及调整网络的架构。其中每个block都包括了一个上采样层(upscaled_conv2d)和一个卷积层,上采样层后置滤波处理与层末调制,卷积层后置层末调制。另外在训练过程中网络需实时输出图片,StyleGAN中定义了torgb()函数,负责将对应分辨率的特征图转换为RGB图像。
· upscaled_conv2d()(line 174-191)

upscaled_conv2d利用tf.nn.conv2d_transpose反卷积操作实现将特征图放大一倍。其中一个值得注意的操作是,其卷积核被轻微平移了四次并对自身做了叠加,这样或许对于提取特征有帮助,但我查阅不到相关资料证明这一点。
· ★网络增长变换过程(line 530-556)
StyleGAN的生成网络需具备动态变换的能力,代码中定义了三种结构组合方式,分别是:固定结构、线性结构与递归结构。
1)固定结构(line 530-533)

固定结构构建了直达1024*1024分辨率的生成器网络,简单高效但不支持渐进式增长。
2)线性结构(line 536-544)

线性结构构建了upscale2d()的上采样层,能将当前分辨率放大一倍。另外在不同分辨率间变换时,线性结构采用了含大小值裁剪的线性插值,实现了不同分辨率下的平滑过渡。
upscale2d()(line 108-118)
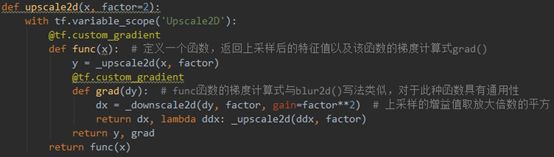
在upscale2d()里定义了上采样的返回函数为_upscale2d(),同时upscale2d()的一阶导和二阶导也被定义了出来,都是直接使用_upscale2d()函数作为近似。
_upscale2d()(line 51-68)

_upscale2d()的实现使用了tf.tile()的骚操作,其实很简单,就是复制扩展了像素值。总而言之,线性结构的实现简单但效率低下。
3)递归结构(line 547-556)
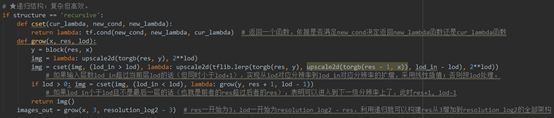
递归结构下定义了递归函数grow(),使得只需要调用一次grow()就能够实现所有分辨率层的构建。它的实现逻辑主要是:比较lod_in和lod的关系——当lod_in超过lod时,在同一层级上实现分辨率的线性扩增;当lod_in小于lod且不是最后一层时,跳转到下一级的分辨率层上。
· 输出(line 558-559)
![]()
网络的最终输出为之前结构中得到的images_out。
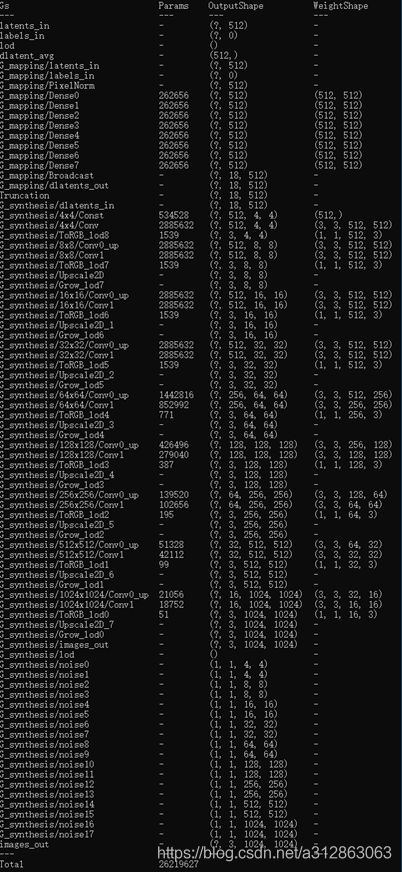
· G_style架构总览
最后,通过一张G_style的完整网络架构图,让我们对各个层的名称、参数量、输入维度和输出维度有更具体的理解。
2.2.4 D_basic网络

D_basic网络位于代码566-661行。如上图所示,D_basic网络实现区分合成图片与真实图片的功能,沿用了ProGAN判别器的架构,基本上是生成器反过来的样子。在D_basic中定义的组件包括:预处理->构建block块->★网络增长变换过程->标签计算->输出。其中,网络增长变换过程是指的在训练时期,随着生成图片的分辨率提升,判别网络的架构动态增长的过程。另外,标签计算是指在训练集使用了含标签数据时,会将标签值与判别分数的乘积作为最终判别网络的输出值。
· D_basic输入参数(line565-582)

输入参数包括图片、标签以及这二者的相关配置,和一些可选的参数,包括各层特征图的设置、激活函数设置、小批量标准偏差层设置、数据处理设置以及网络增长架构的设置等。
· 预处理(line584-596)

预处理主要包括细化网络配置、输入数据的处理以及输出数据的定义,包含内容与G_synthesis中的预处理过程类似。
· 构建block块(line 599-618)

在训练过程中网络需实时处理图片,StyleGAN中定义了fromrgb()函数,负责将对应分辨率的RGB图像转换为特征图。
在block函数中,当分辨率不低于88时,一个block包含一个卷积层和一个下采样层(conv2d_downscale2d);而当分辨率为最开始的44时,一个block包含一个小批量标准偏差层(minibatch_stddev_layer)、一个卷积层和两个全连接层。
conv2d_downscale2d()(line 193-208)

conv2d_downscale2d利用tf.nn.conv2d卷积操作实现将特征图缩小一倍。其中一个值得注意的操作是,其卷积核被轻微平移了四次并对自身做了叠加然后取平均值,这样或许对于提取特征有帮助,但我查阅不到相关资料证明这一点。
minibatch_stddev_layer()(line 283-296)

在4*4分辨率的block中,构建了一个小批量标准偏差层,将特征图标准化处理,这样能让判别网络收敛得更快。
· ★网络增长变换过程(line 621-650)
StyleGAN的判别网络需具备动态变换的能力,代码中定义了三种结构组合方式,分别是:固定结构、线性结构与递归结构。
1)固定结构(line 621-625)

固定结构构建了直达10241024分辨率的判别器网络,简单高效但不支持渐进式增长。
2)线性结构(line 628-638)

线性结构构建了downscale2d()的下采样层,能将当前分辨率缩小一倍。另外在不同分辨率间变换时,线性结构采用了含大小值裁剪的线性插值,实现了不同分辨率下的平滑过渡。
downscale2d()(line 120-130)
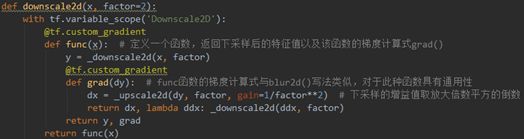
在downscale2d()里定义了下采样的返回函数为_downscale2d(),同时downscale2d()的一阶导和二阶导也被定义了出来,都是直接使用_downscale2d ()函数作为近似。
_downscale2d()(line 70-90)
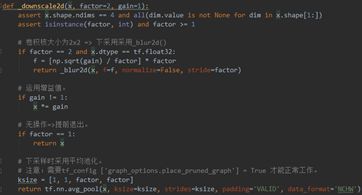
_downscale2d()中,如果卷积核大小为22,则直接返回_blur2d()的结果;否则采用平均池化的方式实现下采样。
3)递归结构(line 641-650)
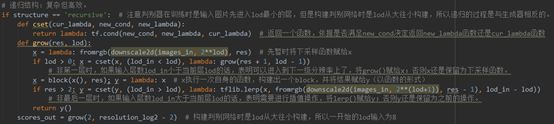
递归结构下定义了递归函数grow(),使得只需要调用一次grow()就能够实现所有分辨率层的构建。它的实现逻辑比较复杂,请参见代码注释;值得注意的是,构建判别网络时是lod从大往小构建,所以递归的过程是与生成器相反的。
· 标签计算(line 653-655)

如果使用了标签的话,将标签值与判别分数的乘积作为最终判别网络的输出值。
· 输出(line 657-659)
![]()
网络的最终输出为scores_out。
· D_basic架构总览
最后,通过一张D_basic的完整网络架构图,让我们对各个层的名称、参数量、输入维度和输出维度有更具体的理解。
