【机器学习】Pandas入门
目录
一、基本概述
二、重要的两个数据结构
三、创建方法
四、参数解析
五、读取文件的方法
六、查看df属性的操作
七、基本操作
八、缺失值处理
一、基本概述
Pandas 库是一个免费、开源的第三方 Python 库,是 Python 数据分析必不可少的工具之一,它为 Python 数据分析提供了高性能,且易于使用的数据结构,即 Series 和 DataFrame。
二、重要的两个数据结构
Series:是一种一维的结构,类似于一维列表和ndarray中的一维数组,但是功能比他们要更为强大,Series由两部分组成:索引index和数值values;
DataFrame:DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔类型)。
三、创建方法
1.创建方法如下:
import pandas as pd
import numpy as np
a = np.array(['a','b','c','d'])
s = pd.Series(a)
print (s)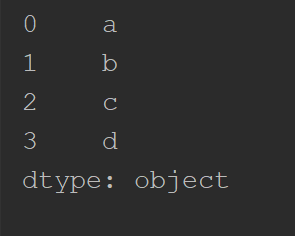
第一列为标签,第二列为数据,一一对应。dtype为数据类型。
2.创建DataFrame方法如下:
import pandas as pd
data = [['li',18],['wang',12],['sun',13]]
df = pd.DataFrame(data,columns=['name','Age'],dtype=float)
print(df)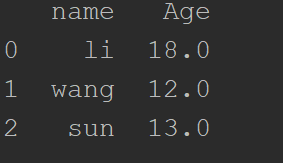
第一列:为index(0,1,2),第一行:列标签columns,左下角:data。
四、参数解析
pandas.DataFrame( data, index, columns, dtype, copy)
| 参数 | 说明 |
| data |
一组数据(ndarray、series, map, lists, dict 等类型)。 |
| index |
索引值,或者可以称为行标签。 |
| columns |
列标签,默认为(0, 1, 2, …, n) 。 |
| dtype | 数据类型。 |
| copy | 拷贝数据,默认为 False。 |
五、读取文件的方法
读取文件这块比较简单,只要掌握read_csv等函数即可,如下图代码所示:
import pandas as pd
if __name__ == '__main__':
#1.加载数据
df = pd.read_csv(r"D:\企业课\data\1.csv")
print(df)
#输出df所有内容数据文件1.csv陆续会上传,方便大家使用!
六、查看df属性的操作
| 属性 | 描述 |
| shape | df的类型 |
| index | 索引值 |
| columns | 列标签 |
| ndim | 查看维度 |
| info() | 查看函数的帮助文档,方便使用 |
import pandas as pd
if __name__ == '__main__':
#1.加载数据
df = pd.read_csv(r"D:\企业课\data\1.csv")
#查看df 属性
print(df.shape)
print("--" * 20)
print(df.index)
print("--" * 20)
print(df.columns)
print("--" * 20)
print(df.ndim)
print("--" * 20)
print(df.info())七、基本操作
| 方法 | 描述 |
| sum() | 求和 |
| mean() | 求平均值 |
| std() | 求标准差 |
| describe() | 数据汇总描述 |
八、缺失值处理
1.检查缺失值,使用isnull()方法进行检查
2.缺失值计算,将缺失值NAN值视为0
3.清理并填充缺失值,使用fillna()函数将非空数据填充NAN值。
4.使用dropna()函数进行删除缺失值
本文将拿第4点进行举例
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f','h'],columns=['one', 'two', 'three'])
df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'])
print(df)
#删除缺失值
print (df.dropna())