3D 目标检测
参考:
-
3D检测入门知识梳理
-
基于单目摄像头的物体检测(YOLO 3D)
1 基本处理方法
目前主要是综合利用单目相机、双目相机、多线激光雷达来进行3D目标检测,从目前成本上讲,激光雷达>双目相机>单目相机,从目前的准确率上讲,激光雷达>双目相机>单目相机。
1.1 激光
CVPR2018年的一篇文章Voxlnet,直接处理激光点云,将点云在空间上划分为均匀的voxel,再把不同的voxel点云提取Voxel Feature Encoding对物体进行分类和位置回归。具体的研读看这里
Voxelnet把激光点云在空间中均匀划分为不同的voxel,再把不同voxel中的点云通过提出的VFE(Voxel Feature Encoding)层转换为一个统一的特征表达,最后使用RPN(Region Proposal Network)对物体进行分类和位置回归,整体流程如图Fig.2所示。

Fig.2 Voxelnet Architecture, figure from reference[2]
如图所示,voxelNet的过程分为3的步骤,分别是:VFE特征提取,3D卷积和RPN预测。本文第一篇使用自学特征做检测,不是采用的手工特征。并且仅仅只用了点云输出。
(1)文章最大的亮点在VFE层,其实结构就是Pointnet,但是却采用了一个voxel中所有数据的整合。最后得到每一个voxel都具有128维度特征的voxel-wise结构。后续就是一个3D卷积和维度融合成二维卷积,再在二维上做RPN操作。
(2)另外一个亮点是在VFE层中计算时先进行升维操作(很多在这篇文章上的后续工作都跟进了这一操作,也就是局部信息和全局坐标结合变成7个维度的特征)。
(3)但是需要提出的问题依旧是两点:第一点,3D卷积的操作实则是一个很鸡肋的东西,在voxel中对每个voxel的特征的提取实则不能做到很好的效果。第二点,anchor-based的方法还是比较耗时间的,而且3D卷积尤其如是。这里的proposals没有任何先验就提来了,而后续的两片文章呢则是在proposal上做了不少文章。
1.2单目相机
YOLO3D将3D检测通过2D的YOLOV2模型来扩展延伸。
以开源的Apollo为例,Apollo中使用的YOLO 3D,在Apollo中通过一个多任务网络来进行车道线和场景中目标物体检测。其中的Encoder模块是Yolo的Darknet,在原始Darknet基础上加入了更深的卷积层同时添加反卷积层,捕捉更丰富的图像上下文信息。高分辨多通道特征图,捕捉图像细节,深层低分辨率多通道特征图,编码更多图像上下文信息。和FPN(Feature Paramid Network)类似的飞线连接,更好的融合了图像的细节和整体信息。Decoder分为两个部分,一部分是语义分割,用于车道线检测,另一部分为物体检测,物体检测部分基于YOLO,同时还会输出物体的方向等3D信息。

Fig.3 Multi-Task YOLO 3D in Apollo, figure from reference[3]
通过神经网络预测3D障碍物的9维参数难度较大,利用地面平行假设,来降低所需要预测的3D参数。1)假设3D障碍物只沿着垂直地面的坐标轴有旋转,而另外两个方向并未出现旋转,也就是只有yaw偏移角,剩下的Pitch和Roll均为0。障碍物中心高度和相机高度相当,所以可以简化认为障碍物的Z=0;2)可以利用成熟的2D障碍物检测算法,准确预测出图像上2D障碍物框(以像素为单位);3)对3D障碍物里的6维描述,可以选择训练神经网络来预测方差较小的参数。

Fig.4 Predictparameters in Apollo YOLO 3D, figure from reference[3]
在Apollo中,实现单目摄像头的3D障碍物检测需要两个部分:
1、训练网络,并预测出大部分参数:
图像上2D障碍物框预测
障碍物物理尺寸
不被障碍物在图像上位置所影响,并且通过图像特征可以很好解释的障碍物yaw偏转角
2、通过图像几何学计算出障碍物中心点相对相机坐标系的偏移量X分量和Y分量
1.3 激光+单目相机
AVOD,AVOD输入RGB图像及BEV(Bird Eye View),利用FPN网络得到二者全分辨率的特征图,再通过Crop和Resize提取两个特征图对应的区域进行融合,挑选出3D proposal来进行3D物体检测,整个流程如图Fig.5所示。

Fig.5 AVOD Architecture, figure from reference[4]
在KITTI 3D object Detection的评测结果如下图Fig.6,目前领先的算法主要集中于使用激光数据、或激光和单目融合的方法,纯视觉做3D目标检测的方法目前在准确度上还不能和上述两种方法相提并论,在相关算法上还有很大的成长空间,在工业界有较大的实用性需求,本次分享主要集中在目前比较新的纯视觉单目3D目标检测。

Fig.6 KITTI 3D object detection competition ranking for car, figure from reference[5]
2 研究问题
2.1 3DBBox
理论上3DBBox会含有9个自由度。分别是:
- 描述形状:{L,W,H}
- 描述位置:{X,W,Z}
- 描述旋转角:{Yaw,pitch,roll}
但是我们存在先验知识:地面是水平的,所以一般就可以少去描述位置的Z的变量和旋转角的pitch和roll,因此变成如下的6个自由度:
- 描述形状:{L,W,H}
- 描述位置:{X,W,0}
- 描述旋转角:{Yaw,0,0}
所以3D检测的位置回归是一个6D的预测回归问题。
2.2 目前存在的数据集
- Jura
- Pascal3D+
- LINEMOD
- KITTI
以KITTI数据集为例,如图Fig.7是KITTI数据集中对于一个3D障碍物的标注:

2.3主要难点
- 遮挡问题:目标相互遮挡或者目标被背景遮挡。
- 截断: 只有物体的一部分
- 小目标
- 旋转角度的学习:物体的朝向不同,但是对应的特征相同
,旋转角的有效学习有较大难度,如图Fig.8所示
Fig.8 Rotation angle confusion, figure from reference[4]
5)缺失深度信息,2D图片相对于激光数据存在信息稠密、成本低的优势,但是也存在缺失深度信息的缺点
2.4 主要方法
目前基于单目相机的3D目标检测的方法主要是复用2D检测中的一系列方法,同时加入多坐标点的回归、旋转角的回归或分类,同时也有采用自编码器的方法来进行姿态学习。
2.4.1
2.4.1 SSD-6D
Making RGB-Based 3D Detection and 6D Pose Estimation Great Again

Fig.9 SSD-6D Architecture, figure from reference[6]
SSD-6D的模型结构如上图Fig.9所示,其关键流程介绍如下:
输入为一帧分辨率为299x299的三通道RGB图片
输入数据先经过Inception V4进行特征提取和计算
分别在分辨率为71x71、35x35、17x17、9x9、5x5、3x3的特征图上进行SSD类似的目标值(4+C+V+R)回归,其中目标值包括4(2D包围框)、C(类别分类得分)、V(可能的视点的得分)和R(平面内旋转)
对回归的结果进行非极大抑制(NMS),最终得到结果
关键点:
Viewpoint classification VS pose regression:
作者认为尽管已有论文直接使用角度回归,但是有实验证明对于旋转角的检测,使用分类的方式比直接使用回归更加可靠,特别是使用离散化的viewpoints比网络直接输出精确数值效果更好
Dealing with symmetry and view ambiguity:
给定一个等距采样的球体,对于对称的目标物体,仅沿着一条弧线采样视图,对于半对称物体,则完全省略另一个半球,如图Fig.10所示

Fig.10 discrete viewpoints, figure from reference[6]
效果:

Tab.1 F1-scores for each sequence of LineMOD, table from reference[6]
2.4.2 3D Bounding Box Estimation Using Deep Learning and Geometry
作者提出一种从单帧图像中进行3D目标检测和姿态估计的方法,该方法首先使用深度神经网络回归出相对稳定的3D目标的特性,再利用估计出来的3D特征和由2D bounding box转换为3D bounding box时的几何约束来产生最终的结果。论文中,作者提出了一个严格的假设,即一个3D bounding box应该严格地被2D bounding box所包围,一个3D bounding box由中心点的(x, y, z)坐标、和三维尺度(w, h, l)和三个旋转角所表示。要估计全局的物体姿态仅仅通过检测到的2D bounding box是不可能的,如下图Fig.11所示,尽管汽车的全局姿态一直没有变,但是在2D bounding box中的姿态一直在变。因此,作者选用回归2D bounding box中的姿态再加上在相机坐标系中汽车角度的变化的综合来进行汽车全局姿态的估计。

Fig.11 Left: Cropped image of car, Right: Image of whole scene, figure from reference[7]
同时,作者还提出了MultiBin的结构来进行姿态的估计,首先离散化旋转角到N个重叠的Bin,对个每一个Bin,CNN网络估计出姿态角度在当前Bin的概率,同时估计出角度值的Cos和Sin值。网络整体结构如下图Fig.12所示,在公共的特征图后网络有三个分支,分别估计3D物体的长宽高、每个Bin的置信度和每个Bin的角度估计。

Fig.12 MultiBin estimation for orientation and dimension estimation, figure from reference[7]
效果:

Tab.2.Comparison of the average orientation estimation, average precision andorientation score for KITTI car, table from reference[7]

Tab.3. Comparisonof the average orientation estimation, average precision and orientation scorefor KITTI cyclist,, table from reference[7]
2.4.3 Implicit 3D Orientation Learning for 6D Object Detection from RGB Images
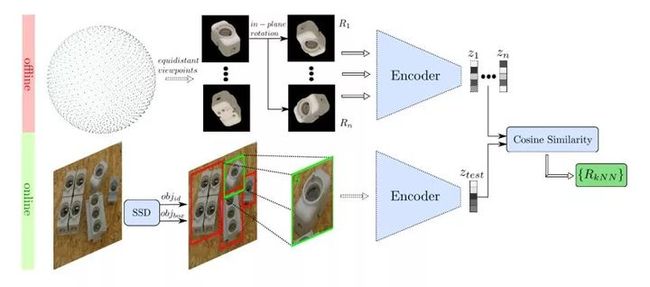
Fig.13 Top:codebook from encodings of discrete object views; Bottom: object detection and3D orientation estimation with codebook, figure from reference[8]
作者主要是提出了一种新型的基于去噪自编码器DA(Denoising Autoencoder)的3D目标朝向估计方法,使用了域随机化(Domain Randomization)在3D模型的模拟视图上进行训练。在进行检测时,首先使用SSD(Single Shot Multibox Detector)来进行2D物体边界框的回归和分类,然后使用预先训练的深度网络3D目标朝向估计算法对物体的朝向进行估计。在模型的训练期间,没有显示地从3D姿态标注数据中学习物体的6D pose,而是通过使用域随机化训练一个AAE(Augmented Autoencoder)从生成的3D模型视图中学习物体6D pose的特征表示。
这种处理方式有以下几个优势:
可以有效处理有歧义的物体姿态,尤其是在物体姿态对称时
有效学习在不同环境背景、遮挡条件下的物体3D姿态表示
AAE不需要真实的姿态标注训练数据

Fig.14 Training process for AAE, figure from reference[8]
效果:
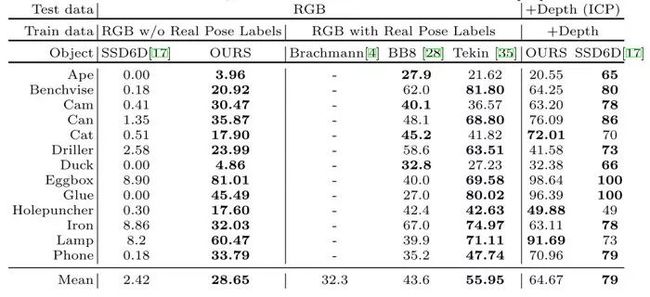
Tab.4 LineMOD object recall with different training and testing data, table from reference[8]
2.4.4 基于YOLO的3D目标检测:YOLO-6D
https://zhuanlan.zhihu.com/p/41790888
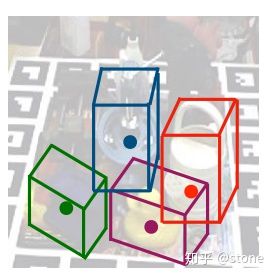
2D图像的目标检测算法我们已经很熟悉了,物体在2D图像上存在一个2D的bounding box,我们的目标就是把它检测出来。而在3D空间中,物体也存在一个3D bounding box,如果将3D bounding box画在2D图像上,那么长这样子:

这个3D bounding box可以表示一个物体的姿态。那什么是物体的姿态?实际上就是物体在3D空间中的空间位置xyz,以及物体绕x轴,y轴和z轴旋转的角度。换言之,只要知道了物体在3D空间中的这六个自由度,就可以唯一确定物体的姿态。
知道物体的姿态是很重要的。对于人来说,如果我们想要抓取一个物体,那么我们必须知道物体在3D空间中的空间位置xyz,但这个还不够,我们还要知道这个物体的旋转状态。知道了这些我们就可以愉快地抓取了。对于机器人而言也是一样,机械手的抓取动作也是需要物体的姿态的。因此研究物体的姿态有很重要的用途。
Real-Time Seamless Single Shot 6D Object Pose Prediction这篇文章提出了一种使用一张2D图片来预测物体6D姿态的方法。但是,并不是直接预测这个6D姿态,而是通过先预测3D bounding box在2D图像上的投影的1个中心点和8个角点,然后再由这9个点通过PNP算法计算得到6D姿态。我们这里不管怎么由PNP算法得到物体的6D姿态,而只关心怎么预测一个物体的3D bounding box在2D图像上的投影,即9个点的预测。
1. 思想
上面已经讲到,我们把预测6D姿态问题转为了预测9个坐标点的问题。而在2D的目标检测中,我们实际上也是需要预测坐标点xy的。那么,我们能不能把目标检测框架拿来用呢? 很显然是可以的。所以这篇文章就提出基于yolo的6D姿态估计框架。
2. 网络架构
整个网络结构图如下:

从上图可以看到,整个网络采用的是yolo v2的框架。网络吃一张2D的图片(a),吐出一个SxSx(9x2+1+C)的3D tensor(e)。我们会将原始输入图片划分成SxS个cell(c),物体的中心点落在哪个cell,哪个cell就负责预测这个物体的9个坐标点(9x2),confidence(1)以及类别(C),这个思路和yolo是一样的。下面分别介绍这些输出的意义。
3. 模型输出的意义
上面已经提到,模型输出的维度是13x13x(19+C),这个19=9x2+1,表示9个点的坐标以及1个confidence值,另外C表示的是类别预测概率,总共C个类别。
3.1 confidence的意义
confidencel表示cell含有物体的概率以及bbox的准确度(confidence=P(object) *IOU)。我们知道,在yolo v2中,confidence的label实际上就是gt bbox和预测的bbox的IOU。但是在6D姿态估计中,如果要算IOU的话,需要在3D空间中算,这样会非常麻烦,因此本文提出了一种新的IOU计算方法,即定义了一个confidence函数:

其中D(x)是预测的2D点坐标值与真实值之间的欧式距离,dth是提前设定的阈值,比如30pixel, alpha是超参,作者设置为2。从上图可以看出,当预测值与真实值越接近时候,D(x)越小,c(x)值越大,表示置信度越大。反之,表示置信度越小。需要注意的是,这里c(x)只是表示一个坐标点的c(x),而一个物体有9个点,因此会计算出所有的c(x)然后求平均。
另外需要注意的是,图上的那个公式是错的,和函数图对应不起来,真正的公式应该是:
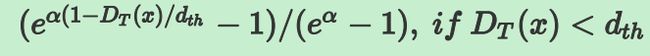
通过以上定义的confidence函数,就可以代替IoU的计算。
3.2 坐标的意义
上面讲到网络需要预测的9个点的坐标,包括8个角点和一个中心点。但是我们并不是直接预测坐标值,和yolo v2一样,我们预测的是相对于cell的偏移。不过中心点和角点还不一样,中心点的偏移一定会落在cell之内(因为中心点落在哪个cell哪个cell就负责预测这个物体),因此通过sigmoid函数将网络的输出压缩到0-1之间,但对于其他8个角点,是有可能落在cell之外的,所以我们没有对8个角点预测添加任何限制。因此坐标偏移可以表示为:
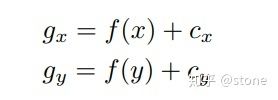
其中cx,cy表示cell的坐标。对于中心点而言,f(.)表示sigmoid函数,对于角点而言,f(.)表示恒等函数。
3.3 类别的意义
类别代表的意义很简单,就是指预测的类别概率,不过这是一个条件概率P(class/object),因为我们在训练的时候,只会在有物体的情况下才计算概率损失,这个和yolo是一样的。
3.4 多目标检测
以上讲的只是对于单目标的情况,如果是多目标的话,某个cell可能会落入多个物体,这个时候就需要使用anchor了,引入anchor之后,网络的输出相应地变为:13x13x(19+C)×anchors,这篇文章使用的anchor数目为5。引入anchor就需要考虑一个问题,如果一个物体落入了某个cell,那么这个cell中的哪个anchor去负责这个物体?这篇文章中的做法和yolo一样,就是去表物体的2D bounding box和anchor的尺寸,最匹配的那个anchor就负责这个物体。
6. 总结
这篇文章实际上将6d姿态问题转为了2D图像中坐标点检测的问题,而2D坐标点的检测问题可以很好地利用目标检测框架来做。当然,这种做法会有一个问题,就是即使你在2D上坐标的检测误差很小,但映射到3D空间中可能会存在较大的误差。当然,这可能是2D图像作为输入的6D姿态估计算法都会面临的问题。不过这篇文章的这个思路还是很值得借鉴的。
上面的几篇文章都是重点在2D图像或者单目结合激光学习6D的姿态,数据来源和我要做的貌似有点出入,我要做的是基于点云的3D检测,因此后续继续挖坑。
2.4.5 基于Mask RCNN的6D姿态估计:deep 6d
https://zhuanlan.zhihu.com/p/45583685
在上篇yolo-6d
stone:基于YOLO的3D目标检测:YOLO-6Dzhuanlan.zhihu.com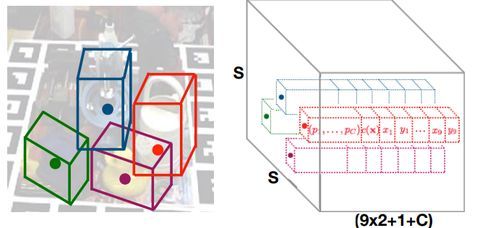
中已经讲了如何通过物体的3D bounding box在2D图像上投影的8个角点和一个中心点来评估物体的6d姿态,这是一种将3d问题转化为2d问题来解决的思路。但deep6d(https://arxiv.org/abs/1802.10367)这篇文章提供了另外一种思路,直接回归6d pose,非常简单暴力。下面详细介绍这种方法。
为什么要基于目标检测框架?
在正式讲deep6d之前,我们先思考一个问题:很多6d姿态估计的方法都是基于2D图像的目标检测框架,为什么要这么做?
我的看法是:目前主流的目标检测方法都是基于多目标检测设计的,而6d姿态估计也涉及多目标,并且也是基于2D图像来进行预测的,只是目标检测预测的目标是xywh,而6d姿态估计预测的是xyzuvw(平移和旋转),因此基于目标检测框架来进行姿态估计也是非常自然的选择。
怎么表示物体的旋转?
这部分是立体视觉的知识。如果对这部分不了解的可以跳过,只要知道,一个物体的旋转可以用一个三维向量来表示就好了。
3D空间中物体的姿态可以用旋转矩阵R和平移向量t来表示。直接回归t没有问题,但是直接回归旋转矩阵R就比较麻烦,因为旋转矩阵需要满足单位正交的条件,网络回归的结果很难满足这种限制,因此需要考虑用其他方式来表示旋转。
表示旋转有几个选择:
- 欧拉角
- 旋转矩阵
- 四元数
- 旋转向量
欧拉角的表示最为简单,也很容易理解,用一个三维向量来表示旋转就好了。但欧拉角有一个问题,同一个角度可以有多种表示,比如1度和361度实际上是同一个角度。除此之外还有万向锁的问题。所以欧拉角不是一个好的选择。
旋转矩阵也是一个选择,但是旋转矩阵的自由度实际上是3,用一个3x3的矩阵来表示旋转显然是多余的。除此之外,旋转矩阵需要满足单位正交的限制,如何在训练目标中加入这个限制条件也是一件难事。所以直接回归旋转矩阵也不是一个好的选择。
四元数就是用一个四维向量来表示旋转,具体什么是四元数这里就不讲了,有兴趣的请查阅其他资料。但是四元数需要满足一个限制,就是这个四维向量必须是一个单位向量。你很难让网络吐出来的结果满足这种限制,因此四元数也不是一个很好的选择。
总之,以上表示方法都有缺点,因此作者就考虑使用一种新的表示方法:旋转向量。旋转向量用一个三维向量的方向来表示旋转轴,用该三维向量的模来表示旋转的角度,所以没有上面的问题。
怎么表示平移?
以上讲解了如何表示旋转,现在还要关心的是如何表示平移xyz。直接预测xy是不容易的,考虑这样一种情况,如果两个物体的z大小一致,但是xy不太一样,这样将3D物体投影到2D图像上之后,从图像上看表面非常相似,大小也相似,只是会在图片中的不同位置。因此很难通过2D图像中的物体来预测xy。因此作者提出通过目标检测得到2D bounding box的中心坐标,由这个中心坐标映射到相机的坐标系就可以得到xy坐标。具体如下:
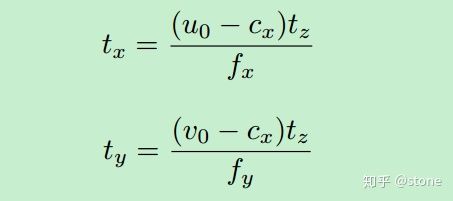
其中 , (u0,v0)是2d边界框的中心点坐标, (cx,cy)是相机内参。注意:上面原图的第2个公式中写错了,应该是cx->cy
模型
知道了如何表示旋转和平移,实际上就知道了模型的训练目标,基于此就可以设计模型了。
模型的架构和mask RCNN是一致的,如下图,只是多了一个pose预测分支。我们先来分别看每个分支。
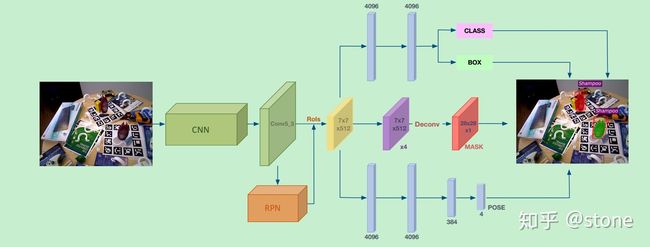
class和box分支:这两个分支是公用一个head的,共用一个head代表分类和回归任务之间的gap比较小,本质上做的事情很像,所以可以共用一个分支。
Mask分支:mask分支和MaskRCNN的网络设计是一样的,唯一不同的是,输出的mask是与类别无关的,只是一个二值mask。而Mask RCNN中,mask的预测是和类别相对应起来的。为什么要这么做?我觉得这是因为mask预测在6d pose预测中是一个很必要的东西,但作者仍然保留下来。既然没什么用,但还保留下来,好吧,那就减少mask预测的复杂度,不管对于哪一类物体,只要预测mask就好了。
Pose分支:pose分支是本文新增的分支。与mask分支不同的是,pose预测是和类别有关的。也就是说每个类别的物体,都会对应一个pose预测。因此pose预测的输出维度是4×num_class。为什么这么做?我觉是因为pose我们的最根本任务就是预测pose,那么我pose预测针对每个类别来做,会更专业化,效果也会更好。这种做法在很多论文里都有这么做。
那么,网络的损失计算就包括了四个方面,总结如下:
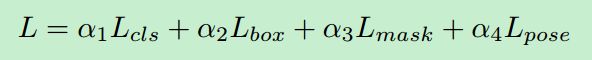
分别包括分类,box回归,mask和pose损失。其中需要特别注意的是pose分支的loss:

这里将rotation和z分开算了,前面的系数表示它们的权重,言下之意就需要分别对待旋转和平移。
实验
具体的实验结果这里不多说了,这里看一下实验的一个可视化结果:

总结
这种通过直接回归6D姿态的方法非常直觉,也很简单,但这类方法想要很好地work的一个重要条件就是,2D图像的变化和6D姿态的变化要能够match,比如说,一个2D图像只有一个轻微的变化,但6D姿态可能变化很大,这种情况是很难让网络学习好的,除非我们有足够的数据进行训练,否则很容易过拟合。直接回归6D姿态应该此前就有人想过,但是可能效果不太好,而这篇文章则验证了直接回归6d姿态也是一个可行的方法,可以说是提供了一种新的思路。
3 Survey of object classification and detection based on 2D/3D data
Brief
这是CVPR-wrokshop上的一篇总结。站在大佬的肩膀上看世界,看看最新的研究进展和发展。文章指出5点3D视觉比2D视觉更加复杂的原因:
- 3D数据的表达多种形式,例如电云和mesh结构,但是2D只有像素格子。
- 计算和内存复杂度都要求更多,更复杂
- 室内,室外的数据分布特征使得一个统一的结构很难运作
- 3D数据,尤其是室外场景,其具有的稀疏性使得检测任务很难做。
- 3D有监督的数据很少,使得学习任务非常困难
3.1 3D data-sets for object detection
- NYU Depth Dataset V2 : has 1449 densely labeled pairs of aligned RGB and depth images from Kinect video sequences for a variety of indoor scenes.
- SUN-RGBD dataset: RGB-D images
- KITTI
3.2 阶段性方法对比
如下图所示的内容,除去19年薪的内容,经典的文章可以如下: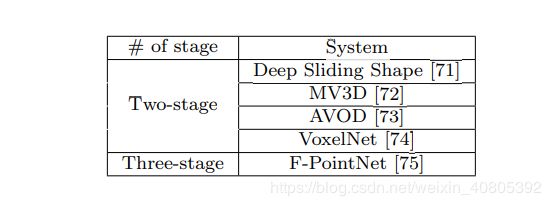
主要可以分为two-stage和three-stage,果然维度提升一维,难度加大的不是一点点。
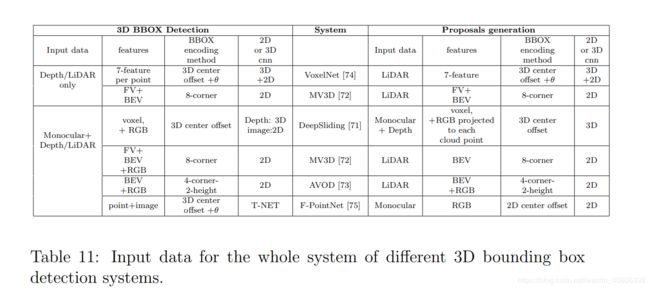
3.2.1 3D bounding box 编码方式
按照输入的数据,把目前3D-detection的文章分类如下;一般来讲,只使用2维数据(单目和立体的数据)的效果并没有结合3维数据的好。

下图表示了目前几种主流(除去19年)的3D检测的方法的Bbox和proposals 生成方法的对比:
Sliding window
Vote3Deep: Fast Object Detection in 3D Point Clouds Using Efficien(IROS2017)

该方法使用三维滑动窗口的方法。首先将点云栅格化,然后使用固定大小的三维窗口,使用CNN判断该窗口的区域是否为车辆。由于栅格化的稀疏性质,该文章使用了稀疏卷积的操作,将卷积核做中心对称,将卷积操作变为投票操作,使得该投票操作只用在不为0的栅格点进行投票即可,减少了大量空卷积的操作。具体投票方式见下图。
具体投票为将中心对称过后的卷积核的中心与非零点对齐,然后相乘,即可得到改点的投票。将多点投票的重叠的区域相加,得到输出。
Two Stage
Multi-View 3D Object Detection Network for Autonomous Driving (CVPR2017)
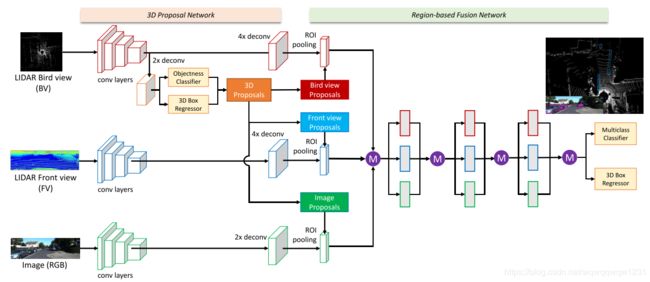
MVNet使用点云和图像作为输入。点云的处理格式分为两种:第一种是构建俯视图(BV),构建方式是将点云栅格化,形成三维栅格,每一个栅格是该栅格内的雷达点最高的高度,每一层栅格作为一个channel,然后再加上反射率(intensity)和密度(density)的信息;第二种是构建前视图(FV),将雷达点云投影到柱坐标系内,也有文章叫做range view,然后栅格化,形成柱坐标系内的二维栅格,构建高度、反射率和密度的channel。
使用俯视图按照RPN的方式回归二维proposal,具有(x, y, w, l)信息,角度只分成0和90度两种,z和h的信息在这一步被设置为常量。然后将三维的proposal进行多个角度的ROI pooling,fusion过程可使用concatenation或summation。最后加上经典的分类头和回归头。
-
文章中强调使用俯视图的好处
“We use the bird’s eye view map as input. In 3D object detection, The bird’s eye view map has several advantages over the front view/image plane. First, objects preserve physical sizes when projected to the bird’s eye view, thus having small size variance, which is not the case in the front view/image plane. Second, objects in the bird’s eye view occupy different space, thus avoiding the occlusion problem. Third, in the road scene, since objects typically lie on the ground plane and have small variance in vertical location, the bird’s eye view location is more cru- cial to obtaining accurate 3D bounding boxes. Therefore, using explicit bird’s eye view map as input makes the 3D location prediction more feasible.” -
本文提出的俯视图的构建过程非常有参考价值,是后续多篇文章所参考的依据。
RT3D: Real-Time 3-D Vehicle Detection in LiDAR Point Cloud for Autonomous Driving
用R-FCN检测车辆。详细解读传送门
Frustum PointNets for 3D Object Detection from RGB-D Data (CVPR2018) F-PointNet

该方法使用图像和激光雷达检测障碍物。
- 处理流程
利用2D Object Detection方法在image上进行车辆检测;
使用2D proposals得到3D椎体proposals,并进行坐标变换,将坐标轴旋转至椎体中心线;
利用PointNet++进行3D Instance Segmentation,并进行坐标变换,将原点平移至instance的型心;
使用T-net进行坐标变换,估计物体的中心;
3D box 回归。
先说下一大体流程:
(1)采用2D优秀的检测方法对深度图的RGB进行检测出物体。
(2)根据检测出来的物体可以确定视锥,文章说的是根据投影关系确定的,所以也不用去考虑什么viewpoint这个无聊的问题。
(3)在视锥内的点进行实例分割,实际上也就是语义分割而已。采用的是一个pointnet的变种结构。这样就算是得到了对应的点。然后在做一次坐标变换,把中心点变换到坐标原点上去。
(4)采用一个T-NET对姿态进行调整,也就是旋转到gt类似的姿态;然后进行的是对size和angel的回归,作者采取了anchor的形式,多个size,多个angel。进行回归。值得注意的一点在于文章的corner-loss的使用。没有细看这个损失。
讲一下文章的贡献点吧:
采用原数据输入。。。文章的意思是没有使用voxel的方式吧。是anchor_free的方法。
坐标转化的使用,很重要,这一点也不算亮点,但是是个trick,后续的PointRCNN也是如此,多次坐标变换得到一个好的结果,我觉得后者就是借鉴了本文的坐标变换,如下图的第三个和第四个所示:
其中包含三次坐标变换如下图:

-
相比于Pointnet,T-net的训练是受监督的。
“However, different from the original STN that has no direct supervision on transformation, we explicitly supervise our translation network to predict center residuals from the mask coordinate origin to real object center.” -
在回归3D box时,该文还提出同时使用Smooth_L1和Corner loss,以提升回归的准确性
"While our 3D bounding box parameterization is compact and complete, learning is not optimized for final 3D box accuracy – center, size and heading have separate loss terms. Imagine cases where center and size are accurately predicted but heading angle is off – the 3D IoU with ground truth box will then be dominated by the angle error. Ideally all three terms (center,size,heading) should be jointly optimized for best 3D box estimation (under IoU metric). To resolve this problem we propose a novel regularization loss, the corner loss:
"
这里提前给一下pointRCNN的变换,下图所示,是不是也是移到中心,然后再正交对齐。

- 贡献点,第三个是采用了一种策略去缩小proposal的范围,这就是那个voxel的存在的问题,满屏的anchor就很蠢。
那么依旧不足如下:
- F-PointNet假设一个frustum中只存在一个instance,这对一些密集区域的segmentation是不利的。
- 受到串行结构的影响,F-PointNet中3d box estimation的结果严重依赖于2d detection,并且RGB信息对整个结构是至关重要的。然而,图像受到光照以及前后遮挡的影响,会导致2d detector出现漏检的情况。
- 有的结构可能只能在3D中才能被看到,一些小的被遮挡住的。
- 阶段性过强,对2D的依赖太大。
Joint 3D Proposal Generation and Object Detection from View Aggregation (IROS2018)

利用Anchor grid作为感兴趣区域进行Crop和Resize到同一大小,然后将两者的特征进行element-wise sum,然后进行3D proposals的第一次回归。然后进行NMS,使用proposals对feature map再次进行Crop和Resize, 然后再次回归,修正proposals,通过NMS得到Object Bounding Boxes。
上图中左边的Fully Connected Layers回归车辆位置的尺寸,右边的Fully Connected Layers回归车辆的朝向角。
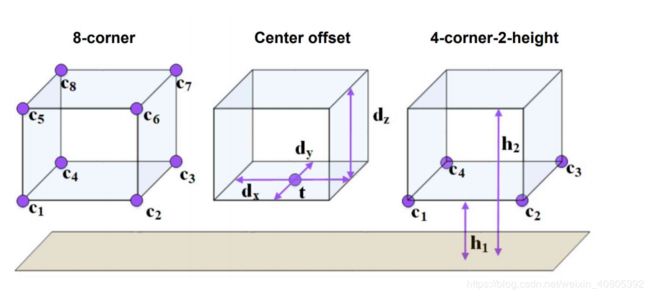
- 本文提出了一种新的3D box 的8个corner的编码方式
“To reduce redundancy and keep these physical constraints, we propose to encode the bounding box with four corners and two height values representing the top and bottom corner offsets from the ground plane, determined from the sensor height.”
PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud (CVPR2019)

该文章提出了使用PointNet++作为主干网络使用two-stage的方法进行目标检测的方法。该方法首先使用PointNet++得到point-wise的feature,并预测point-wise的分类和roi。然后扩大roi,使用上一步得到的feature再使用PointNet++优化3D Box。具体的网络结构可以参考我的另一篇PointRCNN网络可视化,代码详解
- 由于该方法第一次得到RoI的数量与三维点的数量相等,所以该方法理论上可以检测到所有的框。
- 文章中提到了Frustum PointNet的弊端
“F-PointNet [22] generates only 2D box proposals from 2D images, and estimate 3D boxes based on the 3D points cropped from the 2D regions. Its 2D-based proposal generation step might miss many difficult objects that could only be clearly observed from 3D space.” - 解决了大量使用anchor的问题
“our method avoids using a large set of predefined 3D anchor boxes in the 3D space and significantly constrains the search space for 3D proposal generation.” - 使用了Full-bin Loss,使得收敛速度和精度上升
依旧先讲一下过程,两阶段法,很明确的proposals和RCNN两个阶段。
阶段一的过程:
(1)采用pointnet对每个点进行编码得到point-wise特征,随后同时进行两步操作,分割和生成候选框。
(2)分割。采用的方式也就是pointnet,不多说,这里会生成前景mask。
(3)generate proposals。每一个点首先都会生成一个box,但是不会去使用它,而是判断这个点是否在Gt的内部,如果是,那么我们就可以使用这个点的box做proposals;
(4)NMS删选出一些候选的BOX
阶段二:
(1)整合上述的特征,包括有point-wise features,坐标和深度补偿,mask。
(2)进一步对BOX筛选和回归。
优势点:
- 标准的两阶段,Pointnet+RCNN这个名字就是致敬。不过是anchor_free的方法。
- proposals也是相当于经过一定的先验再得到的,会比voxel满屏的anchor好很多。
- bin损失的使用,文章说了这样会比直接使用smoothL1要准确。
- 只采用点云作为输入,完完全全的使用了点云特征,也就是存在Pointnet-wise这个feature。以及各种的feature的大杂烩,但是没有使用局部算数平均值和offest是不是会更好一些。
- 变换坐标这个key-point吧。
不足:
- 每一个点都会开始存在一个proposals,而不是只对前景点。作者当然有考虑到这个问题,只是这样子会比较好计算吧,毕竟一个统一的batch。这倒可以结合voxel的那个采样的思想试一试。
- 大规模的输入,固定到16384个点,点多有点慢。没有采样之类的操作,当然这也是为了得到一个比较高的召回率。
- 一个两阶段法都要去思考的问题,时间比较长。
VoteNet:Deep Hough Voting for 3D Object Detection in Point Clouds
详细解读传送门
Multi-Task Multi-Sensor Fusion for 3D Object Detection
详细解读传送门
GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
详细解读传送门
Stereo R-CNN based 3D Object Detection for Autonomous Driving
详细解读传送门
STD: Sparse-to-Dense 3D Object Detector for Point Cloud
[详细解读传送门(https://blog.csdn.net/wqwqqwqw1231/article/details/100565150)
Part-A^2 Net: 3D Part-Aware and Aggregation Neural Network for Object Detection from Point Cloud
[详细解读传送门(https://blog.csdn.net/wqwqqwqw1231/article/details/100541138)
Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection
本文更偏重于讲一些数据增广的方法和小技巧。
详细解读传送门
BirdNet: a 3D Object Detection Framework from LiDAR Information(2018 ITSC)
本文主要的贡献是解决跨线数激光雷达的训练和检测的鲁棒性问题。
详细解读传送门
StarNet: Targeted Computation for Object Detection in Point Clouds
本文提出了不使用神经网络生成proposal的方法,该方法的另外一个先进性在于inference过程和train过程的使用点云的数量可以不同,使得部署更方便。
详细解读传送门
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
目前KITTI榜首。
详细解读传送门
One Stage
3D Fully Convolutional Network for Vehicle Detection in Point Cloud (IROS2017)
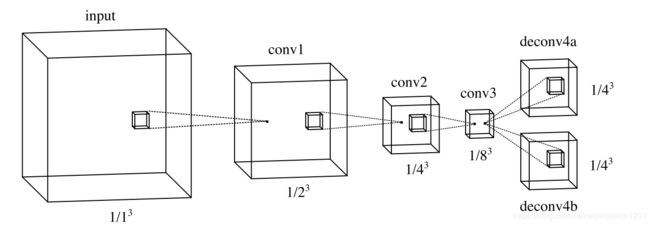
该文章是3D Object Detection的早期之作,使用的方法就是3D卷积,pytorch中有对应的函数torch.nn.Conv3D。方法简单,与YOLOv1思路类似。进行三维卷积和池化,提取高维特征,然后反卷积得到分辨率适中的feature map然使用分类头和回归头预测Bounding Box。
相比后来的方法,该方法显得粗糙一些,但是本论文是将3D Object Detection从传统方法过度到深度学习的文章之一,还是有值得学习之处。
- 提出了使用Bounding Box的Corners作为回归变量,该回归方法在Frustum PointNets又被重新使用,并取得了效果的提升。
- 该文章介绍了比较多的点云栅格化过程中每个栅格的特征构建的方法,可以用来查找手工构建栅格特征的方法。
Complex-YOLO: An Euler-Region-Proposal for Real-time 3D Object Detection on Point Clouds(ECCV2018)
YOLO3D: End-to-end real-time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud(ECCV2018)
两篇文章作者来自同一个机构,姑且认为两篇文章有联系。这两篇文章用的方法也如出一辙,都是使用MVNet俯视图的构建方法,然后利用YOLO在俯视图上做Object Detection,只不过是回归变量多了一个维度和角度,就解决了3D Object Detection的问题。
方法没有什么创新之处,文章中提到了Frustum Pointnet的不足之处。
“This approach has two drawbacks: i). The models accuracy strongly depends on the camera image and its associated CNN. Hence, it is not possible to apply the approach to Lidar data only; ii). The overall pipeline has to run two deep learning approaches consecutive, which ends up in higher inference time with lower effciency.”
说出了Frustum Pointnet在构建proposal的时候依赖CNN这个问题。
PIXOR: Real-time 3D Object Detection from Point Clouds (CVPR2018)

PIXOR思路非常简单,容易理解。计算过程如上图:
类似于MVnet,将点云转为俯视图表示。
使用resnet进行特征提取,然后upsample至原图1/4的大小。
然后加入分类头和回归头。
整个网络框架如下图
我认为这个方法类似于YOLO的思想,One Shot将box分类和回归。Feature Map上采样至俯视图尺寸的1/4,相当于YOLO中的每个格子为4*4个像素。该方法回归的变量均是2维变量:俯视图中的中心点、长宽和方向角。
- 该论文的俯视图的编码是使用栅格的占据编码,不再使用大多数文章使用的高度。
“The value for each cell is encoded as occupancy” - 论文论述了如何解决小目标的问题。小目标在原始图片张占据的像素点少,提取高层特征后,很容易在feature map只对应几个像素点。
“One direct solution is to use fewer pooling layers. However, this will decrease the size of the receptive field of each pixel in the final feature map, which limits the representa- tion capacity. Another solution is to use dilated convolu- tions. However, this would lead to checkerboard artifacts [25] in high-level feature maps. Our solution is simple, we use 16×downsampling factor, but make two modifications. First, we add more layers with small channel number in lower levels to extract more fine-detail information. Sec- ond, we adopt a top-down branch similar to FPN [21] that combines high-resolution feature maps with low-resolution ones so as to up-sample the final feature representation.” - 一个实现细节,在regression头后没有再使用sigmoid函数
HDNET: Exploiting HD Maps for 3D Object Detection (CoRL2018)

该论文是PIXOR的延续之作,使用了PIXOR的网络框架,加入了高精地图的信息,使得检测更准。该论文首先假设高精地图是存在的,那么对于俯视图中,就有道路的的mask和路面的高度。该论文对PIXOR的改进之处体现在将点云转为俯视图过程中,将雷达点的高度z减去对应的高精地图中储存的该点的高度,做此变换之后然后栅格化地图,之后就与PIXOR相同。这样做的目的,论文中提到是减小道路坡度影响,因为PIXOR在进行车辆的Bounding Box的回归时没有考虑高度这个轴,所以这样做直观感觉确实可以提高精度。然后该论文提出了不存在高精度地图的情况,那么就先栅格化点云,然后用U-net在俯视图中做road segmentation和ground estimation(这一步就可以认为是在线地估计高精地图)。
- 该文章除了使用在使用高清地图的地方对PIXOR做了改进,还在输入和回归变量的地方进行了略微改进,论文中称为PIXOR++,可以从结果看出PIXOR++的效果要比PIXOR效果好不少,值得借鉴。
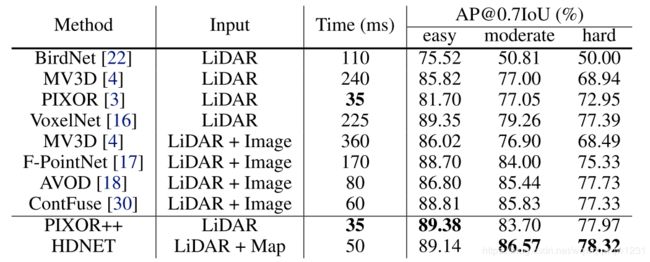
- 为了提高网络在高精地图不存在情况下的鲁棒性,该论文提出了对高清地图做dropout的方法。
“In practice, having a detector that works regardless of map availability is important. Towards this goal, we apply data dropout on the semantic prior, which randomly feeds an empty road mask to the network during training. Our experiments show that data dropout largely improves the model’s robustness to map availability.”
Voxel-FPN: multi-scale voxel feature aggregation in 3D object detection from point clouds
详细解读传送门
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection (CVPR2018) (未完)
LaserNet: An Effcient Probabilistic 3D Object Detector for Autonomous Driving Gregory (Arxiv2019)(未完)

PointPillars
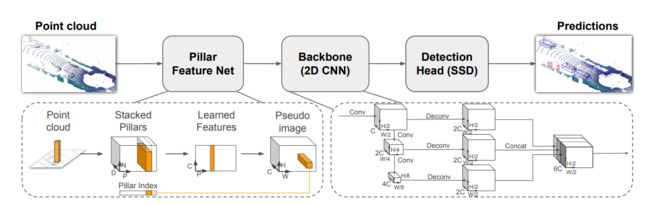
很清晰的三个阶段:
- 特征提取和转化到二维
- 2D CNN骨架网络提取2D特征
- 2D 检测
只说一下第一步:
如何把3D特征转化为2D图片呢?
(1)分柱子。把俯视图分成[Math Processing Error]H \times WH×W个小方格子,再沿着z轴向上拉就成了柱体。
(2)提特征。每个柱体中的点作为一个集合,采用和voxel一样的方式提取特征,最后采用最大池化为[Math Processing Error][T,1,C][T,1,C]
(3)转化为二维。因为[Math Processing Error]T=H\times WT=H×W,所以我们最后可以变化成[Math Processing Error][H,W,C][H,W,C],这是啥,这不就是2D卷积的东西了吗。
优势:
- 又快又好,结构简单优雅。
- 利用了2D成熟的CNN
- anchor-free的方法,借鉴了前人voxelnet的方法,改进了他的3D卷积部分和后续。
- 巧妙的转换到2维度。
不足:
- Z轴的存在的特征缺失。
另一种分类方式:Voxel or Image or Pointcloud?
另一种分类方式,是从网络的输入和网络结构来分。对这种分类的详细的解释,可以参考我的另一篇博客三维激光雷达点云处理分类。
- Voxel:输入为体素格式,典型为VoxelNet,网络使用3D卷积大量使用操作
- Image:输入为图片格式,典型为MVNet,网络使用传统的CNN
- Pointcloud:输入为点云格式,典型为PointNet,网络使用多层感知机,多层感知机的具体实现是2D卷积,但卷积核大小和步长多数为1
这种分类方式由于输入的不同,数据本身就有独自的优势和劣势:
- Voxel:最大问题就是计算慢!体素是三维的,卷积模板也是三维的,那么计算起来就比二维的慢,而且卷积核移动的方向也是三维的,随着空间的大小的增大,体素的数量是以立方的数量增长;而且在自动驾驶场景,体素是稀疏的,存在大量体素中不包含雷达点,特征为0,做很多无用卷积。所以这种方式计算量大而且很多是无效计算。
- Image:结果的好坏与输入的特征的有关,有效地将点云转为图像也是一个可以研究的点。
- PointNet:可用的工具少,目前主流的也就是PointNet系列和Graph convolution系列。
4.1.2 思考与探索
2D CNN的使用方法:
- 类似mv那种,使用对3D的投影得到其2维的图像,再使用2D CNN,这样做无疑是会出现信息损失的,另外呢,先把3D点云分割成若干个体素小块,再把点个数当做二维像素值,再使用2D CNN结构,这又只使用了密度信息,没有局部几何信息。都是不太好的。
- 第二种呢就是先对点的局部提取点特征(这都要归功于pointnet),然后在利用卷积进行处理;这里呢需要说的是voxelnet是第一篇提取局部特征后去做检测的,但是使用了3D voxel检测,后续再把深度信息和通道结合成一个维度,采用二维的RPN。这里最大的鸡肋就是这个3D CNN,后续有一篇sensors上的文章只改了这个3D CNN变成了 稀疏3D卷积的形式;这一篇PointPillars则是在这两篇文章的基础上做的,直接把3DCNN取消了,采用二维CNN接手后面的操作,虽然创新点不算特别亮眼,不过也着实巧妙。
就点云输入的研究热点
- anchor_free的方法,也就是研究如何经过一定的处理再提出proposals,就像是F-pointnet首先经过视锥缩小范围,PointRCNN首先进行一下前景分割,不过实际上每个点也是anchor;
- 把二维成熟的方法向着3维上靠。F-pointnet和voxelnet和pointpillars。PointRCNN的名字就来自二维。
一些重要的trick
- 旋转对其和坐标变换。在pointRCNN和F-pointnet都使用了的。
- 首先进行pointent编码,我觉得这个才是正确的点云使用方式,F-pointnet的后续开展肯定不多,而pointliarrs和voxelNet肯定会有更好的发展。
- 局部结构特征的使用,这里讲的是中心坐标和中心偏移量的使用。
可能有发展的Idea
- 各向异性卷积核的使用。
4.2汇报总结【19年9月9日——19年9月21日】
4.2.1 论文总结
4.2.1.1 GSPN
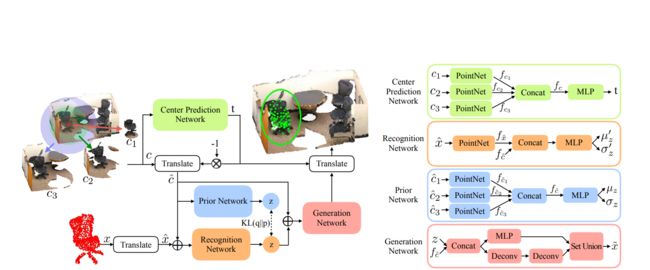
- 怎么生成ins的预测框
(1)预测一个对目标ins的中心
(2)对每一个预测的中心采取一个多尺度特征提取的方式进行特征提取。
(33)对提取到的特征和近似的分布进行采样联合生成一个bbox。
- 运用在检测中会有什么样的问题:
(1) 在训练时,展现的内容是KL-loss不收敛。
(2)研究了生成预测中心的loss,在实例分割中,随机采样的128个点都是有所属实例,因此存在着对应的GT,但是在Kitti数据集中,并不是所有点都有实例。因此网络需要密集采样,但是目前采样点数过多就会导致无法训练。
- 运用到目标检测上的尝试
(1)想要解决的问题:
- 根据提取到的特征结合分布信息(已经被嵌入了gt的分布信息)生成这样大小的size,就不用了根据不同大小设置不同size的anchor了。
- 可以同时做到多分类检测
(2)网络整体结构图可以如下所示:
(3)对代码中5中LOSS的理解,看个人理解的博客。
4.2.1.2 Attention pointnet
上面一篇GSPN的文章重点是在于对实例点的生成ins,但是运用到det的任务时就不能够采样到很多的gt的点,导致需要密集采样才可完成,这一篇文章是采用了GRU的attention,能够从[Math Processing Error]12\times 1212×12的区间中划分感兴趣的区域,这就可以解决上诉的采样的问题,作者把这个叫做attention的机制,是属于大场景下的找到目标的方式,结合 博客理解。
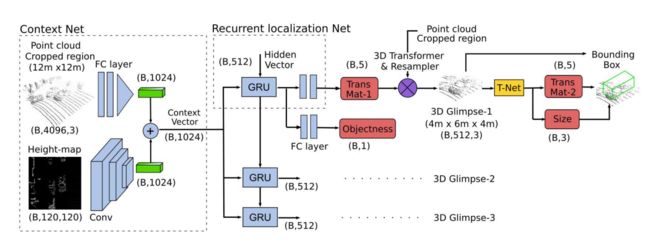
- 可以给我带来什么?
(1)上面的idea正是由于密集采样而导致了生成的问题,但是如果可以先粗略的attention这个所检测的物体上,那么我们就可以在这个小区域上进行采样生成
(2)难点:该文章的代码结合了ROS的rospy,需要进行一定的修改(小事情),不知道实际的效果如何。需要测试。
4.2.1.3 MEGV
这一篇 博客

- 文章主要做什么
(1)文章主要在nusense上做多目标检测,先分size再细每一个类别,目前还没有开源。
(2)算是第一篇做anchor-free的文章。
- 可以给我带来什么
(1)多分类的参考
(2)文章是属于标准的pointpillars那一套做法,划分网格,然后通过voxel提取特征,再转到二维进行RPN和多目标检测。
4.2.1.4 Fast Point R-CNN
也是很新的文章,同样是贾佳亚组的工作(上一篇的PointRCNN),写在博客这里
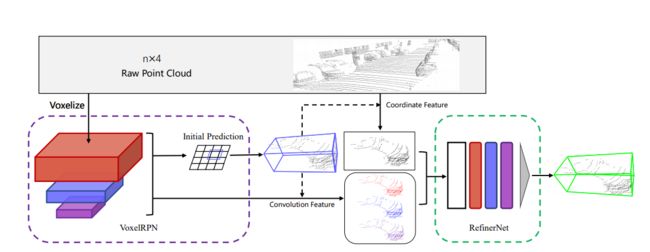
- 主要优点:
(1)在转到二维的时候采用的多尺度联合的方式。
(2)粗回归后又进行了原始点云的细回归。因为voxel会出现roi pooling的精度定位到网格上,因此网格个大小直接导致了回归的精度,作者就此采用了原始点云的输入进行refine。
4.2.2 思路整理
- 3D检测就是要就解决两个问题:定位和分类。
(1)第一个问题,分类,目前做了多目标检测的文章只有19年8月才放上arxiv上的class_blanced的MEGV,采用nuscence检测数据集,具体实现是采用了一个voxelnet的anchor方式,但是最后通过了对二维上的每一个voxel粗分类大致确定其size,然后再细分类得到对应的类别;此外其他我见过只采用lidar数据输入的文章只有单次训练一个类别,能不能通过voxelnet特征提取后,在最后的每一个二维的anchor上根据对应的特征生成一个box而不是回归,做到分类和回归同时做。
(2)第二个问题,回归,怎么定位一个目标在平面的区域呢?目前的3D的方法有一个系列(voxelnet)是通过满屏的anchor来把三维的降到二维,再对没也给二维中每一个voxel回归一个7维的定位信息(实际上就不是定位问题,而是一个回问题,这里并没有失去一个遍历的方式,全场景的anchor只有背景和不是背景,是前景的就在每一个anchor的位置回归7个维度的定位信息),这个系列的文章包括了(voxelnet,Second,pointpillars,包括pointrcnn和fastpointRCNN)后面两种方法实际上是采用了voxel特征提取的方式,但是自己的anchor是基于每一个中心点来提的,而faster_rcnn则更加回到voxelnet的方式,采用的结构更加类似,文章还采用所谓的attention(非常简单);但是19年CVPR上有一篇文章:attention-pointnet,这一篇文章,采用GRU的方式直接对输入的点云块采取注意力的形式得到去想要得到的块,再通过坐标变换得到相应的旋转回归矩阵。还有一些不入流的方法,比如我觉得F-pointnet就算是一个,采用一种先减少候选区域的方法去生成proposals的方法,PointRCNN也有一点这样的想法,先通过场景语义分割得到对应的一些粗略的点。目前按照论文的数量来说,voxelnet系列是绝对占有的一种,其首先提取每一个anchor的三维特征,再通过网络降为成二维的anchor去预测训练的前景的概率和对应的回归的7个量,但是不得不说的一点是这样会存在信息的丢失,如何使得信息较少的丢失是一个问题?这里在fast_point_rcnn的多尺度结合应该会存在这个效果;但是依旧很大的问题,定位太依赖anchor,而不是区域中比较突出的特征去直接attention上,分类由于anchor在三维空间上的变化太大,这个系列都是通过固定size的形式,而不是采用生成的方式。
4.2.3 其他工作
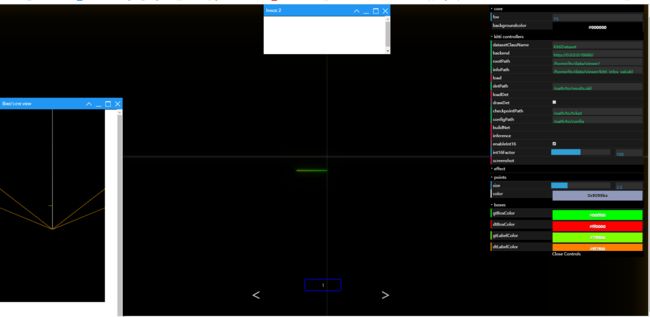
- pointpillars 的kittiviewer:
在web上的界面已经联通了,具体操作:
(1)在服务器端运行gui界面的代码:
cd ./kittiviewer/frontend && python -m http.server
(2)在服务器运行后端加载处理程序:python main.py main(目前还有问题)
(3)在本地上连接并监听对应的端口:ssh -L 16666:127.0.0.1:8000 [email protected],然后在本地对应的浏览器上输入网址:http://127.0.0.1:16666/
参考资料
- LiborNovák. Vehicle Detection andPose Estimation for Autonomous Driving. Master’s thesis, Czech TechnicalUniversity in Prague.
- YinZhou, Oncel Tuzel. VoxelNet: End-to-End Learning for Point Cloud Based 3DObject Detection. In CVPR, 2018.
- https://mp.weixin.qq.com/s/XdH54ImSfgadCoISmVyyVg
- Ku,Jason and Mozifian, Melissa and Lee, Jungwook and Harakeh, Ali and Waslander,Steven. Joint 3D Proposal Generation and Object Detection from ViewAggregation. In IROS, 2018.
- http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
- Wadim Kehl, Fabian Manhardt, Federico Tombari,Slobodan Ilic and Nassir Navab: SSD-6D: Making RGB-Based 3D Detection and 6DPose Estimation Great Again. ICCV 2017.
- ArsalanMousavian, Dragomir Anguelov, John Flynn, Jana Košecká. 3d bounding box estimation using deep learning andgeometry.CVPR 2017.
- MartinSundermeyer、En Yen Puang、Zoltan-Csaba Marton、Maximilian Durner、Rudolph Triebel. Implicit 3DOrientation Learning for 6D Object Detection from RGB Images. In ECCV, 2018.