金融数据获取(二):搭上多进程并行的高速路(上)
摘要:
1:本文将运用多进程对一个简单的美股爬虫程序进行改造;
2:创建进程方式有很多,本文仅使用了multiprocessing模块调用对象的方式创建进程,此外本文讨论了多进程中的效率问题及通信问题并进行了代码展示;
3:开发环境选择了Pycharm,所有程序均基于python3.8;
4:本文依旧是基于干货的分享;
目录
一、概念
1.1 上期回顾
1.2 对多进程的补充
1.2.1 进程的三态:就绪、运行和阻塞
1.2.2 同步和异步、阻塞和非阻塞
1.2.3 多进程的缺点
二、基于多进程对爬虫程序进行改造
2.1 关于多进程效率
2.2 进程间的通信问题
2.2.1 Manager
2.2.2 队列Queue与管道Pipe
三、总结
一、概念
1.1 上期回顾
对理论不感兴趣的读者可以跳过概念直接从第二部分开始看
笔者曾在上一期讨论过多线程、多进程、并发和并行四个概念背后的详细原理和逻辑,并用多线程的方法对一个小型美股爬虫程序进行了改造 (原文链接:https://blog.csdn.net/simon1223z/ article/details/120321212)。作为一个曾在梦里单手开法拉利的分析湿,笔者自然不会满足于多线程那点快感。

通过上期内容我们知道,多进程也是提高程序运行效率的利器,并且由于Python设计之初GIL锁的存在,依靠多核CPU实现的多进程并行理论上可以比多线程并发的方式更快!然鹅,伪多线程的不一定真的一无是处,真多进程的也不一定十全十美。
1.2 对多进程的补充
尽管上期对多进程进行了说明,但主要内容还是放在了线程上,只是简要提到了多进程对内存的占用问题会影响效率;实际上多进程还有其它缺点(笔者无意抨击多线程,实际上多线程还是很香的;只是上期把优点都说没了,本期自然是要做一些补充)
这里笔者再通过一个生动形象的例子详细说明,相信大家小时候都知道家务活问题:烧水5分钟,拖地10分钟,煮饭25分钟,做菜10分钟,如何才能提高效率?我们显然不会等饭煮好再去做其它事情,计算机程序也是一样的道理。下面借这个例子说明多进程的三个状态:就绪、运行和阻塞;还有两组概念:同步和异步、阻塞和非阻塞。
1.2.1 进程的三态:就绪、运行和阻塞
其实这是个很好理解的概念,如果把烧水和煮饭看作是一个程序,在没有按下电源开关前都属于就绪状态,按下电源开关后就处于运行状态。当出现停电时,烧水煮饭不得不停下,那么便可以说程序阻塞了。但值得注意的是,当计算机程序出现阻塞时需要重新回到就绪状态等待电源开关打开方可进入运行状态,而不是从阻塞态直接回到运行状态,如图一所示。
图一:进程的三态
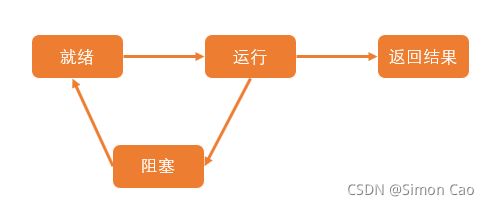
ps.引入三态概念的目的是为了解释阻塞与非阻塞,后文会用到
1.2.2 同步和异步、阻塞和非阻塞
1):同步与异步是程序提交执行的两种方式
同步即是以最笨的办法解决家务活问题:当煮饭时一直等着饭煮好再去做另一件事。程序运行起来即是卡住的感觉。
异步则是在煮饭的同时做其它事情。表现在程序上即是从内存提交程序给CPU后不等待该程序执行完毕,而是去提交其它程序,至于什么时候回返回该程序的结果取决于异步回调机制什么时候被触发(感兴趣的可以去了解一下异步回调机制的条件,文末拓展资料有)。
用代码展示一个同步的原理:
import time
def task_1():
a = 1
b = 2
c = a + b
time.sleep(5)
def task_2(a):
print(a)
if __name__ == '__main__'
task_1()
task_2("我是一个同步提交的任务")主程序包含task_1和task_2两个任务,当主程序运行时task_2必须等待task_1执行完成后才能执行,即是task_1 sleep的5秒时间里什么也没有干,我们平时写的代码行执行,大多都是典型的同步提交方式。
2):阻塞和非阻塞是程序执行的两种状态
阻塞其实已经在进程三态中的阻塞状态;非阻塞态则是就绪和运行状态。
1.2.3 多进程的缺点
了解完上面四个概念后,请思考:以上概念两两组合,哪一种组合的效率是最高的?
| 同步 | 异步 | |
| 非阻塞 | 同步&非阻塞 | 异步&非阻塞 |
| 阻塞 | 同步&阻塞 | 异步&阻塞 |
显然:异步>同步;非阻塞>阻塞, 异步&非阻塞是效率最高的
ps: 我们应该尽量让代码保持在异步&非阻塞状态,然鹅这基本是很难实现的,市面上许多软件甚至都做不到完全在非阻塞状态运行。
既然异步&非阻塞程序效率最高,我们便用家务活的例子结合代码实现来看看如何压缩时间。
先导入必要模块:
import datetime,time
import threading1):同步提交方式做家务
def bio_water():
a = 5
time.sleep(a)
print("水烧开了")
def mop():
a = 10
time.sleep(a)
print("地板擦干净了")
def rice():
a = 25
time.sleep(a)
print("饭煮好了")
def cooking():
a = 10
time.sleep(a)
print("饭做好了")
if __name__ == '__main__':
start = datetime.datetime.now()
bio_water()
mop()
rice()
cooking()
end = datetime.datetime.now()
print("做家务活时间", end - start)运行结果:

以上所有家务活皆是非阻塞的,可以排除一些冗余的创建变量和开辟内存的时间,所有家务做完要50分钟。(ps: 家务活时间太长了,下面都用秒来代表分钟)
2):异步提交方式
由于还没引入多进程,这里笔者就用上期的多线程来模(jia)拟(zhuang)一下异步提交:
## 创建4个线程
t1 = threading.Thread(target = bio_water, name="烧水")
t2 = threading.Thread(target = mop, name="擦地板")
t3 = threading.Thread(target = rice, name="煮饭")
t4 = threading.Thread(target = cooking, name="做饭")
start = datetime.datetime.now()
Pool = [t1,t2,t3,t4]
for t in Pool:
t.start()
for t in Pool:
t.join()
end = datetime.datetime.now()
print("做家务活时间", end - start)运行结果:

以上所有家务活皆是非阻塞的,排除一些冗余的创建变量及开辟内存的时间,所有家务做完要25分钟。
这个25分钟就是煮饭用的25分钟,事实上这25分钟再也无法压缩了,不管是多线程运行;还是多线程异步&非阻塞的运行;还是多进程并行;还是多进程异步&非阻塞的并行运行,甚至可以用两个电饭煲(假设电饭煲都一样,煮饭时间都是25分钟),叫上爸爸妈妈一起煮,都需要25分钟。
笔者认为这是多进程无法克服的最大缺点——与其创建那么多线程浪费时间和占用内存,不如多线程来得简单直接;或者说从任务执行上看就有这样的特点,类似家务活这样的问题从程序设计的角度依旧是无法继续压缩时间的,程序运行的时间能压缩到多少完全取决于用时最长的那个任务。
不过类似于爬虫程序这样的任务,多进程就大有用武之地,接下来笔者会结合多进程对上期写的美股爬虫程序进行改造,看能不能把时间继续压缩,提高效率。
二、基于多进程对爬虫程序进行改造
Python中通过multiprocessing模块来实现多进程,其实创建多进程和多线程的代码实现非常相似,只是换了个名字。
from multiprocessing import Process
可以看到,该模块下的Process对象主要参数设置和多线程都很相似。
class multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)下面就利用multiprocessing.Process来创建一个进程对象并插入到上期所写的爬虫程序中,multiprocessing.Process子类化也可以创建多进程,这里就不作展示了,文末会有相关参考文档:
import requests
import re
import datetime # 仅仅用于测试程序运行时间
start_org = datetime.datetime.now()
stock_list=[]
#pages={"NQ":164,"SP500":26,"DJ":2}
page=[164,26,2]
a = 0
for i in range(len(page)):
markets=i+1
market_list=[]
for i2 in range(int(page[i])):
pages=i2+1
url="https://stock.finance.sina.com.cn/usstock/api/jsonp.php/IO.XSRV2.CallbackList['fTqwo9s8$wLka1yh']/US_CategoryService.getChengfen?page="+str(pages)+"&num=20&sort=&asc=0&market=&id=&type="+ str(markets)
#新浪用来翻页的真实网址是被隐藏在js里的
response = requests.get(url).text
symbol = re.findall('"symbol":"(.*?)","cname"',response,re.S)
market_list.extend(symbol)
print("已经爬取{}".format(symbol))
stock_list.append(market_list)
stock_list
end_org = datetime.datetime.now()
print("执行程序时间",end_org-start_org)
————————————————
版权声明:本文为CSDN博主「Simon Cao」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/simon1223z/article/details/120321212把代码写成函数的形式并加入两个进程:
def craw(*data):
print("jdfjdsngfjidsbnijgfndsgf")
url = data[0]
stock_list = data [1]
for i in url:
lock.acquire()
response = requests.get(i).text
symbol = re.findall('"symbol":"(.*?)","cname"',response,re.S)
stock_list.extend(symbol)
print(threading.current_thread().getName() +"已经爬取{}".format(symbol))
print("爬取完成,共爬取%d条数据"% len(stock_list))
return stock_list
start_org = datetime.datetime.now()
page, url_list=[164,26,2], []
a = 0
for i in range(len(page)):
markets=i+1
for i2 in range(int(page[i])):
pages=i2+1
url="https://stock.finance.sina.com.cn/usstock/api/jsonp.php/IO.XSRV2.CallbackList['fTqwo9s8$wLka1yh']/US_CategoryService.getChengfen?page="+str(pages)+"&num=20&sort=&asc=0&market=&id=&type="+ str(markets)
url_list.append(url)
t1 = multiprocessing.Process(target = craw, args=(url_list[:len(url_list)//2]),name="task1")
t2 = multiprocessing.Process(target = craw, args=(url_list[len(url_list)//2:]),name="task1")
t1.start()
t2.start()
t1.join()
t2.join()
print("总列表",stock_list, len(stock_list),id(stock_list))运行结果妥妥的扑街:
![]()
管道破裂???

这是容易翻车的一个点,创建进程与创建线程最大的一个不同之处在于Windows系统下进程一定要在main中创建。因为进程所达到的效果在于进程之间互不干扰,例如安卓手机上的应用分身功能,实际上分身应用和主应用都是使用的同一套代码。multiprocessing本身便可达到多次复用的效果,而使用main可以实现类似导入模块的方式导入应用分身,而不是multiprocessing一直重复代码本身而陷入死循环。
简单来说只要记住win下创建多进程一定在main下创建就行了。
import datetime, multiprocessing, requests, re
page, url_list = [164, 26, 2], []
a = 0
for i in range(len(page)):
markets = i + 1
for i2 in range(int(page[i])):
pages = i2 + 1
url = "https://stock.finance.sina.com.cn/usstock/api/jsonp.php/IO.XSRV2.CallbackList['fTqwo9s8$wLka1yh']/US_CategoryService.getChengfen?page=" + str(
pages) + "&num=20&sort=&asc=0&market=&id=&type=" + str(markets)
url_list.append(url)
def craw(*data):
url = data[0]
stock_list = data[1]
for i in url:
response = requests.get(i).text
symbol = re.findall('"symbol":"(.*?)","cname"', response, re.S)
stock_list.extend(symbol)
print("已经爬取{}".format(symbol))
print("爬取完成,共爬取%d条数据" % len(stock_list))
return stock_list
if __name__ == '__main__':
stock_list = []
start = datetime.datetime.now()
t1 = multiprocessing.Process(target=craw, args=(url_list[:len(url_list) // 2], stock_list), name="task1")
t2 = multiprocessing.Process(target=craw, args=(url_list[len(url_list) // 2:], stock_list), name="task2")
t1.start()
t2.start()
t1.join()
t2.join()
print("总列表", stock_list, len(stock_list), id(stock_list))
end = datetime.datetime.now()
print("双进程执行时间", end - start)运行得:
![]()
记得上次多线程时间都才41秒而已,不过考虑到网络等情况,双线程几乎可以视为和双进程一样快的存在了。其次有个严重的问题,公司名称并没有正确的存进stock_list中。以上这两个问题一个个来解决,首先是效率问题。
2.1 关于多进程效率
还记得上次多线程笔者一口气创了5个线程,结果比双线程跑下来的速度就快1秒。。这次笔者也用了同样的招数,先创建了4个进程,运行得:
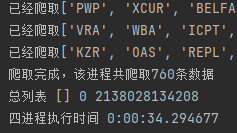
34秒!这个成绩超过5线程的速度了!笔者继续造,一口气开10个试试看!
下面构造进程池,构造十个进程:
if __name__ == '__main__':
devisor, process_pool, stock_list = len(url_list) // 10, [], []
for i in range(0, 10):
t1 = multiprocessing.Process(target=craw, args=(url_list[devisor * i:devisor * (i + 1)], stock_list),
name="task{}".format(i))
process_pool.append(t1)
t1.start()
for i in process_pool:
i.join()
print("总列表", stock_list, len(stock_list), id(stock_list))
end = datetime.datetime.now()
print("十进程执行时间", end - start)运行得:
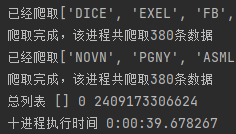
好的,又是上次双线程和五线程的悲剧。。

理论上看,多进程其实与多进程不太一样,很大程度上与电脑性能有关,打开资源管理器和监视器可以看到笔者的电脑仅是4核CPU,且开着很多应用连续烧机整整8天,如果换一台有很多框框的高级电脑,多进程能力应该会强上许多。

为了给不堪重负的电脑造成成吨的伤害,笔者直接将进程数开上100,运行结果让笔者大感意外:

竟然缩短到了20秒,电脑几乎也没有卡顿。
笔者尝试了1-200线程,在电脑性能允许的范围下,进程数与爬取效率间大致呈现正相关关系,但随着进程数的递增将出现边际递减,到某个阶段超出电脑负荷时开始边际为负。由于每个人的电脑,网络情况等都大相径庭,笔者写了一段代码可以从单进程到200进程都统统运行一下,最后导出csv,这段代码运行起来颇费时间,笔者专门写了一篇补充文章讨论进程数量与效率之间的关系,感兴趣的戳:(82条消息) 金融数据获取(二):多进程下的性能压力测试(下)_simon1223z的博客-CSDN博客 https://blog.csdn.net/simon1223z/article/details/120452540?spm=1001.2014.3001.5501
https://blog.csdn.net/simon1223z/article/details/120452540?spm=1001.2014.3001.5501
import datetime, multiprocessing, requests, re, time
import pandas as pd
page, url_list = [164, 26, 2], []
a = 0
for i in range(len(page)):
markets = i + 1
for i2 in range(int(page[i])):
pages = i2 + 1
url = "https://stock.finance.sina.com.cn/usstock/api/jsonp.php/IO.XSRV2.CallbackList['fTqwo9s8$wLka1yh']/US_CategoryService.getChengfen?page=" + str(
pages) + "&num=20&sort=&asc=0&market=&id=&type=" + str(markets)
url_list.append(url)
def craw(*data):
url = data[0]
stock_list = data[1]
for i in url:
response = requests.get(i).text
symbol = re.findall('"symbol":"(.*?)","cname"', response, re.S)
stock_list.extend(symbol)
print("已经爬取{}".format(symbol))
if __name__ == '__main__':
num , timer = [], []
for a in range(1,3):
start = time.time()
devisor, process_pool, stock_list = len(url_list) // a, [], []
for i in range(0, a):
t1 = multiprocessing.Process(target=craw, args=(url_list[devisor * i:devisor * (i + 1)], stock_list),
name="task{}".format(i))
process_pool.append(t1)
t1.start()
for i in process_pool:
i.join()
num.append(a)
#print("总列表", stock_list, len(stock_list), id(stock_list))
end = time.time()
print(a,"进程执行时间", end - start)
t = end - start
timer.append(t)
time = {"number":num, "run_time":timer }
df = pd.DataFrame(time)
df.to_csv("C:/Users/Administrator/Desktop/program_data.csv")2.2 进程间的通信问题
上文提到有个严重的问题,公司名称并没有正确的存进stock_list中,其实这就是多进程间的通信问题导致的。在进程间运行的程序有个特点——相互隔离,互不影响。与线程不同,线程更像是同一条流水线上的工人,它们共享数据,共享内存;而进程更像是两个不同的流水线上的个人,两条流水线间互不影响。
于是当工厂老板向两个流水线下达指令时,它们只会按照自己流水线上的工序进行生产,这个例子用到上面的代码中也是一样的。如图二所示,进程间其实有道”防火墙的存在“(只是笔者具象化的比喻,实际进程中没有这个概念),当老板将Stock_list给到两个进程时,两个进程只会根据它们自己的生产工艺进行生产,且加工出来的Stock_list也互不干扰。这就类似于函数里的变量,笔者创建的进程的确对Stock_list进行了添加,但由于是在进程内添加的,后面print()时依然是空列表,而且这种被隔离起来的变量即使用global全局化也无法解决。
图二:进程间的”防火墙“

目前主流的有三种方式实现进程间的通信:1): 进程对列Queue; 2): 管道Pipe; 3): Managers
Queue和Pipe只是实现了数据交互,并没实现数据共享,Managers则是允许一个进程去更改另一个进程的数据。
2.2.1 Manager
Manager()也是multiprocessing下的对象,其强大之处在于可共享的数据多样,字典、列表,以及Arra数组等均可共享。下面就演示一下列表共享的实现:
import multiprocessing, requests, re, time
page, url_list = [164, 26, 2], []
a = 0
for i in range(len(page)):
markets = i + 1
for i2 in range(int(page[i])):
pages = i2 + 1
url = "https://stock.finance.sina.com.cn/usstock/api/jsonp.php/IO.XSRV2.CallbackList['fTqwo9s8$wLka1yh']/US_CategoryService.getChengfen?page=" + str(
pages) + "&num=20&sort=&asc=0&market=&id=&type=" + str(markets)
url_list.append(url)
def craw(*data):
url = data[0]
sl = data[1] # 进程所共享的列表
stock_list = []
for i in url:
response = requests.get(i).text
symbol = re.findall('"symbol":"(.*?)","cname"', response, re.S)
stock_list.extend(symbol)
print("已经爬取{}".format(symbol))
sl.append(stock_list) # 添加进共享列表
#print("爬取完成,该进程共爬取%d条数据" % len(stock_list))
return stock_list
if __name__ == '__main__':
m = multiprocessing.Manager()
sl = m.list() # 实例化,使用列表方式进行共享
for a in range(4,5):只用了4线程做例子,这里改参数可以控制进程数
start = time.time()
devisor, process_pool, stock_list = len(url_list) // a, [], []
for i in range(0, a):
t1 = multiprocessing.Process(target=craw, args=(url_list[devisor * i:devisor * (i + 1)], sl),
name="task{}".format(i))
process_pool.append(t1)
t1.start()
for i in process_pool:
i.join()
print(总列表,sl) 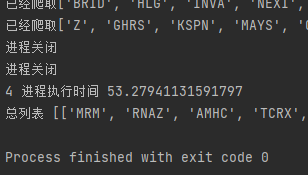
上面最重要的关键在于
m = multiprocessing.Manager()
sl = m.list() 它创建了一个共享列表,后面只需要传给每个线程让它们将加工好的数据添加进共享列表中即可,概括来说即是简单,好用,强大。
2.2.2 队列Queue与管道Pipe
简单理解队列就是充当一个产品仓库的角色,当进程加工出新的数据时都存进这个仓库,最后需要使用数据时到仓库进行提取即可。与Manager不同,队列与管道所能实现的共享有限,且提取加工的数据时需要Queue.get()才能拿到数据。其它操作与Manager大同小异,这里对Queue进行代码展示,Pipe就不做更多展示了。
import multiprocessing, requests, re, time
from multiprocessing import Queue
page, url_list = [164, 26, 2], []
a = 0
for i in range(len(page)):
markets = i + 1
for i2 in range(int(page[i])):
pages = i2 + 1
url = "https://stock.finance.sina.com.cn/usstock/api/jsonp.php/IO.XSRV2.CallbackList['fTqwo9s8$wLka1yh']/US_CategoryService.getChengfen?page=" + str(
pages) + "&num=20&sort=&asc=0&market=&id=&type=" + str(markets)
url_list.append(url)
def craw(*data):
url = data[0]
stock_list = []
sl = data[1]
for i in url:
response = requests.get(i).text
symbol = re.findall('"symbol":"(.*?)","cname"', response, re.S)
stock_list.extend(symbol)
print("已经爬取{}".format(symbol))
q.put(stock_list)
#print("爬取完成,该进程共爬取%d条数据" % len(stock_list))
return stock_list
if __name__ == '__main__':
q = Queue()
num , timer = [], []
for a in range(4,5):
start = time.time()
devisor, process_pool, stock_list = len(url_list) // a, [], []
for i in range(0, a):
t1 = multiprocessing.Process(target=craw, args = (url_list[devisor * i:devisor * (i + 1)], q),
name="task{}".format(i))
process_pool.append(t1)
t1.start()
for i in process_pool:
i.join()
print("总列表", q.get())另外,Queue在多线程中也可以实现通信,只是上期笔者粗暴的用了全局变量,因此没有讨论多线程间的通信问题。
三、总结
从最初单线程的2分钟,到今天100个多进程的20秒,改造效果笔者还是相当满意的。
多线程和多进程是个很大的话题,应用场景也十分广泛,对大多数程序来说,多线程和多进程的确有助于提高效率。对于笔者自己的研究来说,多线程多进程的方式是高效获取更多金融数据的基础,巧妇难为无米之炊,之后我们还需要思考如何对获取的数据进行有效管理。
写到此处不知不觉就天亮了,创作不易,路过的朋友赏光点个赞叭。
您若不弃,我们风雨共济。
拓展资料
(67条消息) Python multiprocessing.Manager介绍和实例(进程间共享数据)_weixin_38170065的博客-CSDN博客https://blog.csdn.net/weixin_38170065/article/details/99895724?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-4.no_search_link&spm=1001.2101.3001.4242多线程就一定能提高处理速度吗? - 简书 (jianshu.com)https://www.jianshu.com/p/616d074214d2(67条消息) 【python】详解multiprocessing多进程-process模块(一)_brucewong0516的博客-CSDN博客https://blog.csdn.net/brucewong0516/article/details/85776194
一篇文章搞定Python多进程(全) - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/64702600
(67条消息) 函数回调机制、异步函数回调机制图例详解_Leeon的博客-CSDN博客_异步回调https://blog.csdn.net/zhangliangzi/article/details/52066560