机器学习中七种常用的类别变量编码方法
关注”AI自研社“公众Hao,回复“编码”即可获得本文完整源码。
机器学习一般仅对数字特征有好,无法直接利用类别特征进行学习,一般我们在将数据输入算法进行训练前需要对类别特征进行编码处理,将其转换成数字特征。本文将为大家精心整理七种常用的类别特征的编码方法。
在具体介绍前,我们还是先创建好用于演示的数据集。
import pandas as pdimport numpy as npdata = {'Temperature':['Hot','Cold','Very Hot','Warm','Hot','Warm','Warm','Hot','Hot','Cold'],'Color':['Red','Yellow','Blue','Blue','Red','Yellow','Red','Yellow','Yellow','Yellow'],'Target':[1,1,1,0,1,0,1,0,1,1]}df = pd.DataFrame(data,columns=['Temperature','Color','Target'])
01
标签编码(Label Encoding)
假设特征取值有n个不同值,即n个类别,那么将按照特征数据的大小将其编码为0-(n-1)之间的整数。
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()df['Temp_label_encoded'] = le.fit_transform(df.Temperature)df

# 获取编码与类别之间的映射关系res = {}for cl in le.classes_:res.update({cl:le.transform([cl])[0]})res{'Cold': 0, 'Hot': 1, 'Very Hot': 2, 'Warm': 3}
02
独热编码(One-Hot Encoding)
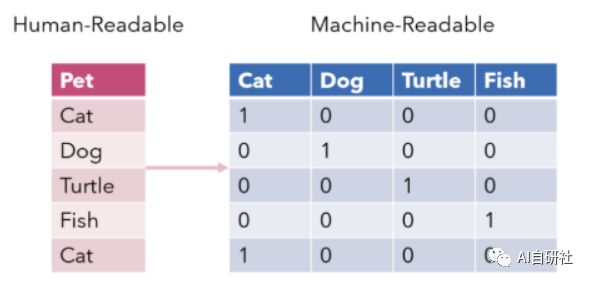
独热编码即One-Hot编码,是一种将分类变量转换为几个二进制列的方法,其中1表示具有该属性特征,0表示不具有该属性特征。
下面的例子中有一个特征Pet,它的取值类别为Cat、Dog、Trutle、Fish、Cat,在采用One-Hot编码后,会生成四个新的特征(新特征数量与类别数量一致),每一列新特征的取值限定在0,1中,并且每一行的四个新特征中,只能有一个取值为1,其他则全为0。如果该特征类别的数量非常多,则此方法会产生很多列,从而大大降低学习速度。
# 下面是一个封装好的通用方法def OneHotForEncoding(target_columns,df):enc = OneHotEncoder(handle_unknown='ignore')enc.fit(df[target_columns].values)matrix = enc.transform(df[target_columns].values).toarray()feature_labels = np.array(enc.categories_).ravel()col_names = []for col in target_columns:for val in df[col].unique():col_names.append("{}_{}".format(col, val))return pd.DataFrame(data = matrix, columns=col_names, dtype=int)# 传入需要编码的特征的列表及原始数据onehot_df = OneHotForEncoding(["Temperature", "Color"],df)onehot_df

03
序号编码(Ordinal Encoding)
对于ordinal 变量,将1到N按顺序赋值给这个N类的定序变量。但是其实是将表征interval变量的方法应用到ordinal变量上。比如天气寒冷为1, 温暖为2, 炎热为3。
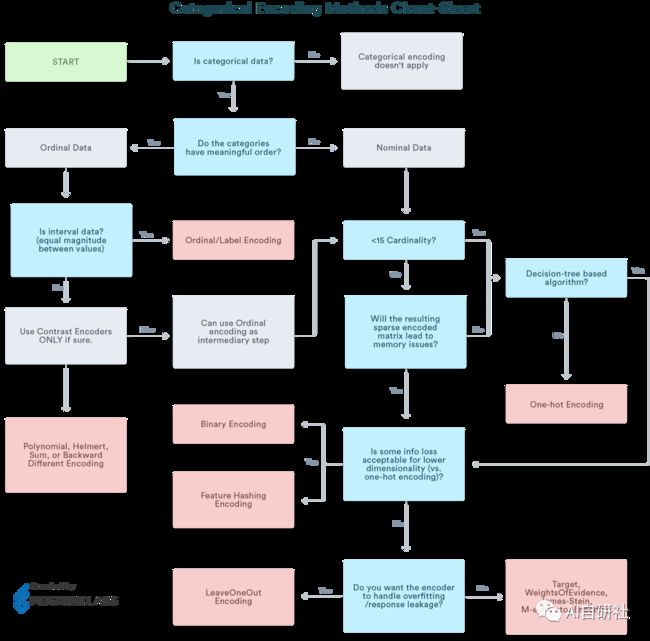
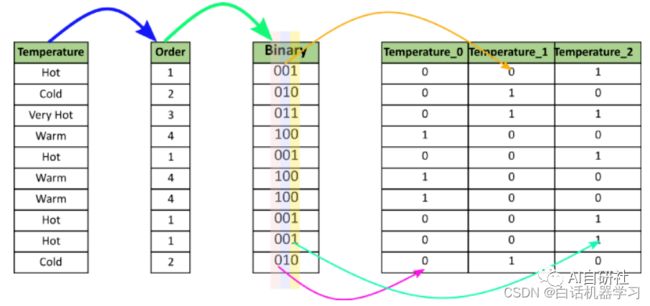
类似于标签编码,但是是按照提前指定好的编号顺序对类别进行编码。如果我们以温度标尺为顺序,则顺序值应从“冷”到“非常热”。顺序编码会将值指定为 ( Cold(1) 04 二进制编码(Binary Encoding) 二进制编码将类别转换为二进制数字。每个二进制数字创建一个特征列。如果存在n个唯一类别,则二进制编码将导致仅有log(base 2)ⁿ 个特征。在此示例中,有四个特征;因此,二进制编码特征的总数将是三个特征。与“独热编码”相比,这将需要较少的特征列(对于100个类别,“独热编码”将具有100个特征,而对于“二进制”编码,我们将仅需要七个特征)。 对于二进制编码,必须遵循以下步骤: 1、将类别转换为从1开始的数字顺序(顺序是在类别出现在数据集中时创建的,并不表示任何序数性质)。 2、将这些整数转换为二进制代码,例如3变为011,4变为100。 3、二进制数的数字形成单独的列。 05 频率编码(Frequency Encoding) 这是一种利用类别的频率作为标签的方法。在频率与目标变量有些相关的情况下,它可以帮助模型根据数据的性质以正比例和反比例理解和分配权重。三个步骤: 1、选择要转换的分类变量 2、按类别变量分组并获得每个类别的计数 3、将其与训练数据集重新结合 06 平均编码(Mean Encoding) 平均编码与标签编码类似,只是这里的标签与目标直接相关。例如,在平均目标编码中,对于特征标签中的每一个类别,都是用目标变量在训练数据上的平均值来决定的。这种编码方法将相似类别之间的关系凸显出来,但联系被限定在类别和目标本身之内。平均目标编码的优点是不影响数据量,有助于加快学习速度。 通常,Mean编码存在过拟合,因此,在大多数场合,使用交叉验证或其他方法进行正则化是必须的。平均数编码的方法如下: 1、选择要转换的分类变量。 2、按类别变量分组,并获得“目标”变量上的汇总和。(“温度”中每个类别的总数为1) 3、按类别变量分组,并获得“目标”变量的总计数。 4、划分第2步/第3步的结果,然后将其与训练集合并。 07 Helmert编码 Helmert编码通常在计量经济学中使用。在Helmert编码(分类特征中的每个值对应于Helmert矩阵中的一行)之后,线性模型中编码后的变量系数可以反映在给定该类别变量某一类别值的情形下因变量的平均值与给定该类别其他类别值的情形下因变量的平均值的差值。在category_encoders包中实现的Helmert编码为反向Helmert编码。 总结: 对于不同的类别特征到底应该使用哪种编码方式,并没有绝对的公式,如下一张图为我们总结了一些实战经验,可以帮助我们判断对于不同情况的类别特征,我们应该如何更加高效的选取编码方法。 AI自研社是一个专注人工智能、机器学习技术的公众平台,目前已发表多篇连载文章,对机器学习领域知识由浅入深进行详细的讲解,其中包含了大量实例及代码参考,对学习交流有很大帮助,欢迎大家关注。Temp_dict = {'Cold':1, 'Warm':2, 'Hot':3, 'Very Hot':4 }df['Temp_Ordinal'] = df.Temperature.map(Temp_dict)df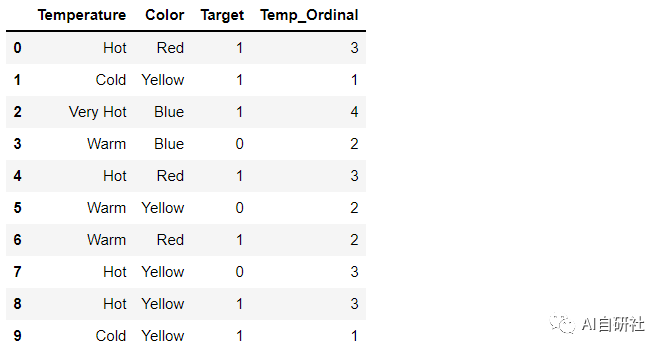
import category_encoders as ceencoder = ce.BinaryEncoder(cols=['Temperature'])dfbin = encoder.fit_transform(df['Temperature'])df = pd.concat([df,dfbin],axis=1)df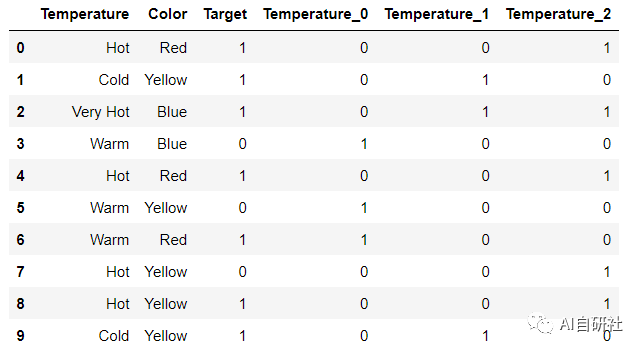
fe = df.groupby('Temperature').size()/len(df)df.loc[:,'Temp_freq_encode'] = df['Temperature'].map(fe)df
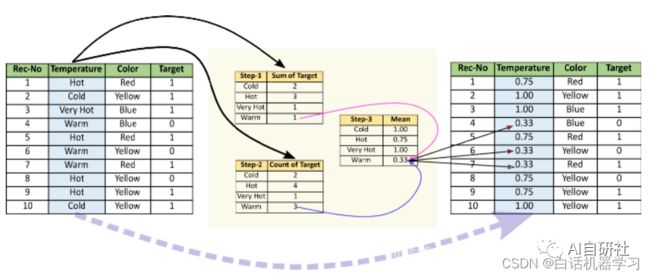
mean_encode = df.groupby('Temperature')['Target'].mean()df.loc[:,'Temperature_mean_enc'] = df['Temperature'].map(mean_encode)df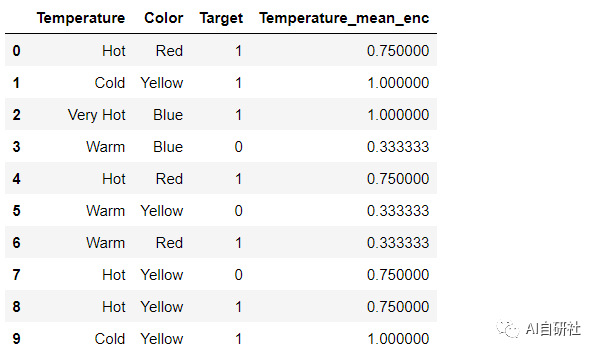
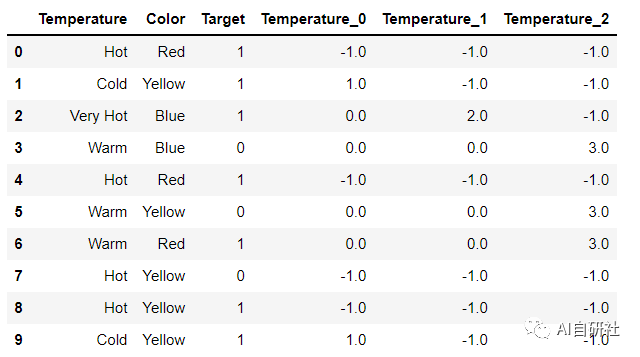
import category_encoders as ceencoder = ce.HelmertEncoder(cols=['Temperature'],drop_invariant = True)dfh = encoder.fit_transform(df['Temperature'])df = pd.concat([df,dfh],axis=1)df