【MySQL】数据表四字真决---增删查改(一)(简单易懂)
我是目录哦~~~
一、第一真决:增!(Create)
1、插入单行数据:
2、插入多行数据:
3、指定列插入数据:
4、日期类型的插入
二、第二真决:查!(Retrieve)
1、全列查询:
2、指定列查询:
3、表达式查询:
4、起别名:
5、去重:
6、排序:
7、条件查询:
7.1、基本查询:
7.2、AND与OR:
7.3、范围查询:
7.4、模糊查询:
7.5、关于NULL的查询:
8、分页查询:
第三真决:改!(Update)
第四真决:删!(Delete)
小小前言:
在我的上一篇博客中我分享了一些关于MySQL的基础知识和一些简单的操作,如果有的朋友有兴趣可以点进去学习一下前面的内容。这篇博客中我会继续和大家分享一下在MySQL中的关于数据表的增删查改操作以及一些自己的看法。
点击这里跳转上一篇博客!!!
增删查改,通常我们也简称为CURD,即C:create、U:update、R:retrieve、D:delete。这是我们学习数据库的一个非常重要的知识点!!!
一、第一真决:增!(Create)
在上一篇博客中,我们学习了如何在一个数据库中新建一个数据表,那么这里的“增”呢,是在新建的数据表中增加一条数据或者说插入一条记录。
1、插入单行数据:
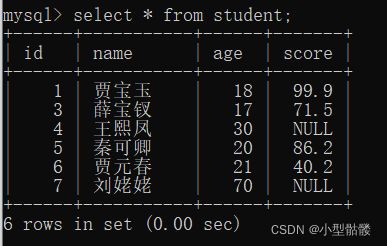
我使用了上篇博客中新建的数据库mynewdb,并且已经新创建了一个数据表student:
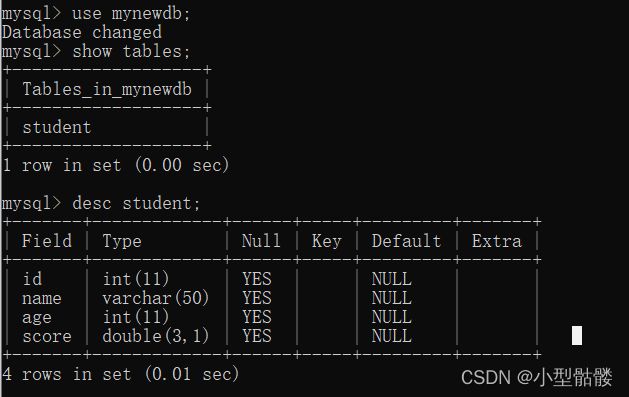
现在我要往这个student数据表里插入一行数据:
insert into 表名 values ( 各列的数据 ) ;
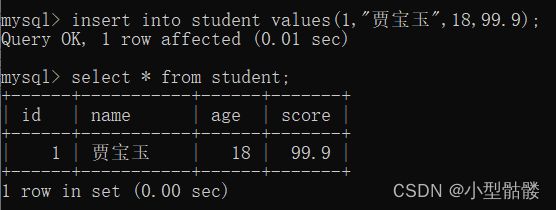
如上图,我在student数据表中插入了一条学生数据,id为1,name为贾宝玉,age为18,score为99.9。
当然,我们也可以再插入一行数据:
或者在插入数据的时候将某一列的数据置为NULL。这里我们将王熙凤的成绩置为null了,所以之后在显示各个列的数据情况的时候,王熙凤的score这一列就会显示为null:
注意1 :我们在插入数据的时候括号里的每一个数据必须和要插入的表中的每一列的数量和顺序都一致才行!!!比如我在下图中插入这一行数据的时候,因为只是没有插入score这一列的数据,MySQL就提示我出现错误了:
注意2:在SQL中字符串可以使用单引号 ' 也可以使用双引号 " 。



2、插入多行数据:
上面的插入操作只是一行SQL语句插入一行数据,我们同样也可以用一行SQL语句插入多行数据:
insert into 表名 values (各列的数据) , (各列的数据) ;
这里我通过一行SQL语句插入了两行数据,同样的,你也可以插入三行四行等等,只不过在括号之间我们需要用英文逗号“ , ”来隔开。

3、指定列插入数据:
上面两个插入操作都是需要我们把所有的列都写在括号里(插入到表中),但是在实际需求中,有时候我们可能并不能每个列都插入数据,这时候呢,就可以使用这个指定列插入,我们想在那个列插入数据,就在哪个列插入数据:
insert into 表名 (需要插入数据的列名) values (插入的数据) ;
这个操作需要我们在表名后面加上一个括号,括号里面填入需要插入数据的列名,然后values后面的括号就可以只写入我们需要插入的数据就可以啦!
比如上面这个栗子:我们的刘姥姥都已经七十大寿啦!这时候你还让她考试吗?所以她肯定是没有考试成绩的,所以我们在插入刘姥姥这个数据的时候就没有成绩(score)这个数据可以插入了。注意:我们在插入某一列或某几列时,是只有这几列是有数据的,那其他未插入数据的列显示为null!

4、日期类型的插入
在SQL中我们往往也会遇到日期类型(datetime)的数据,那这时候该如何插入日期类型的数据呢?
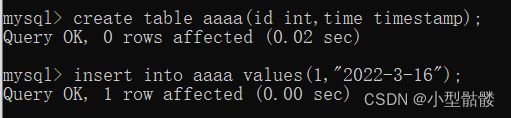
在下图中,我新建了一个数据表aaaa,有id列和time列,此处的日期格式是有很多的,但是我们比较推荐使用YYYY-MM-DD hh-mm-ss 这一种写法。
上图栗子中只是添加了日期,如果没有小时分钟秒数的话,那么显示出来的时候就是00时00分00秒,现在我添加下时间:
注意:时间和日期之间得有个空格存在哦~
我们也可以使用MySQL内置函数now()来插入时间,它表示插入你计算机现在的时间:
那么以上呢,就是常用的插入时间/日期的方法了,这里我先偷偷查看一下aaaa表里我刚刚究竟插入了些什么玩意儿(虽然咱还没讲到查询的方法):
第一行只插入了日期,第二行还插入了我自己设定的时间,第三行使用了函数,代替手动插入了计算机当时显示的时间。



二、第二真决:查!(Retrieve)
通过上面那些新建操作,我们已经获得了一张有数据的数据表了,接下来就可以使用第二真决来驱动第一真决 —— 查看一下刚刚的student表了:
1、全列查询:
select * from 表名;
通过这个sql语句,可以查看到一个数据表中全部的列(字段)和行(记录)的信息。其中,这里的星号“ * ”是一个“通配符”,表示一个表中的所有列。
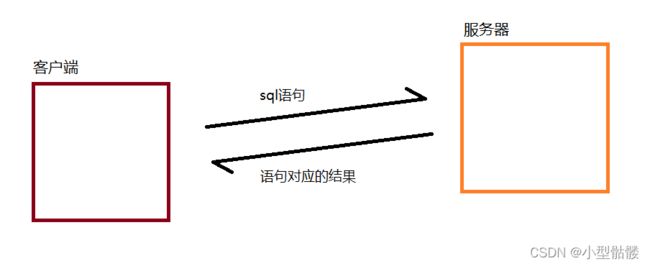
这个全列查找虽然可以把所有的行和列都查找出来,但是它显示的是一个“临时表”!也就是说这个临时表不会对原本的数据表产生任何影响的,我也在上个博客中说过,数据库存储的数据和表都是在硬盘上的,而这个临时表呢则是在内存上的,随着它的输出打印,这些临时存储的数据也就会随风消散了~SQL语句获得响应的原理:
1、当用户们输入sql语句后,客户端就会把这个sql包装成网络信号,发送给服务器。
2、服务器接收到请求后,会操作硬盘,从硬盘读取数据,把这些数据包装成响应,再返回给客户端。
3、客户端接收到这个响应数据后,就会临时的在内存中把这个响应数据结果保存起来,并且在显示器(输出设备)上打印,当它打印完毕,这些临时保存的数据也就被 释放消失了。
2、指定列查询:
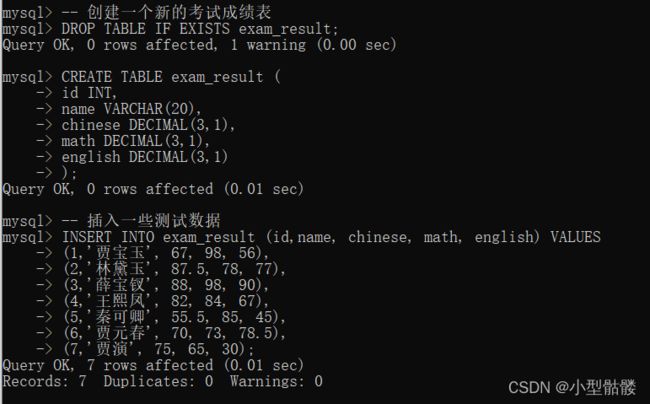
这里我先插入一堆测试用例,方便接下来的几个测试:

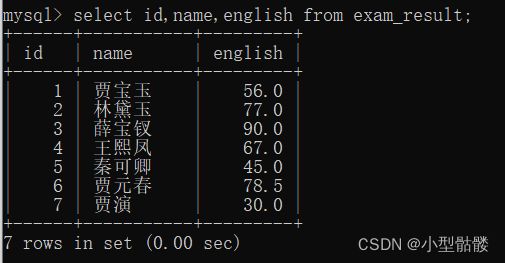
select 列名,列名··· from 表名;
这里我查询了id(学号)、name(姓名)和english(英语成绩)这三列,那显示结果就只会出现这三列,其他列(字段)就不会出现了。你指定哪个列,哪个列就会出现,非常的随心所欲!
列名可以写任意个,但是不能超过原本的表。列名顺序也可以随意调换,比如:只能说是非常自由了~~~
注意:指定列查询的结果也是一个临时表,随着打印完成,临时保存的这些数据也就消失不见了。
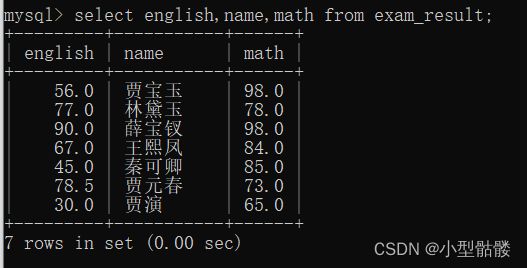
3、表达式查询:
我们在查询的过程中,往往需要一些直接查询显示不出来的数据,比如这次考试数据,因为一些原因,语文老师在批改的过程中把每个人的成绩少算了十分,现在我要查成绩就需要把每个人的语文成绩多加上十分,咱们可以这么做:
在指定列查询的同时,在chinese(语文成绩)后面 + 10。这样就变成了一个表达式了。和原来相比确实每个人语文都多了十分:
上面的表达式只包含了一个字段,也可以包含多个字段一起运算表达式,比如我们查一下每个同学的总分(chinese+math+english):
注意:1、表达式查询出来的结果也是临时表啊!是不会改变原来数据库上的数据的!不要以为我+10了原来数据表数据也会改变,不会的!
2、临时表中结果的数据类型不一定会和原始表数据类型一致,因为临时表数据类型会自动自适应,以保证结果的正确。


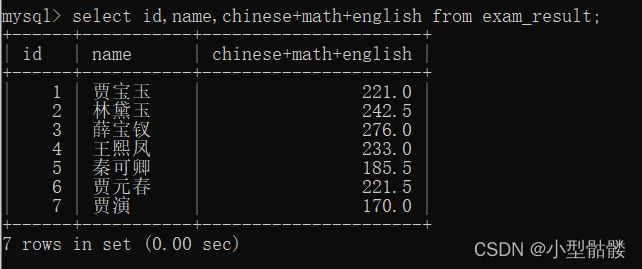
4、起别名:
select 列名 as 别名 from 表名 ;
咱们在查询时每个列或者表达式都是可以起一个“别名”的,啥意思呢?来看:
我在查询的过程中,看英文看烦了,很不顺眼,所以我就把这些改成了汉语拼音,那改成汉语行不行呢?行!只需要把汉字用引号给框起来就可以:
那么,类似这种在原先列名后面加上一个as,再加上别名这种操作就是起别名了,可以令我们更方便的查看查询结果。这个as是可以省略不写的,但是呢不推荐!理由的话自己不写as试试几次就明了了。
除了给列名起别名外,也可以给表达式起别名哦,比如之前查询总分,那一串表达式太长了,很不舒服,我就来给它起个别名,叫total:
这样看起来是不是比刚才舒服?哈哈哈~
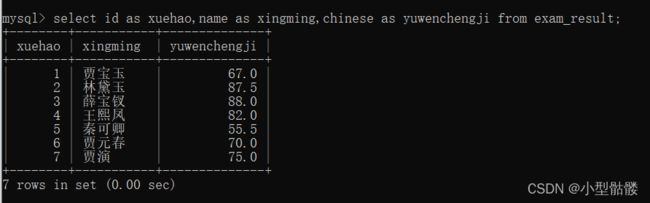


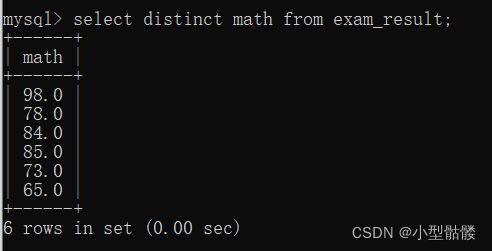
5、去重:
select distinct 列名 from 表名 ;
我们来看一下,原始表里贾宝玉同学和薛宝钗同学数学成绩都考了98分,这固然很棒,但是我想查询的时候不出现重复的成绩,那么该咋办呢?
咱可以这么做:
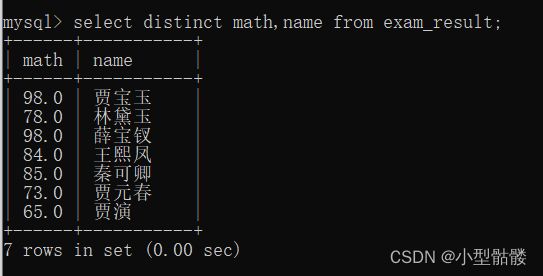
在select后面加上一个distinct就ok啦!但是去重操作必须得在一条列有重复数据的情况下来能生效,如果我在列名多加上一条name列,这样就不行了:
注意:若是针对多个列去重,就必须这些列的值全部相同的时候才视为重复哦~
6、排序:
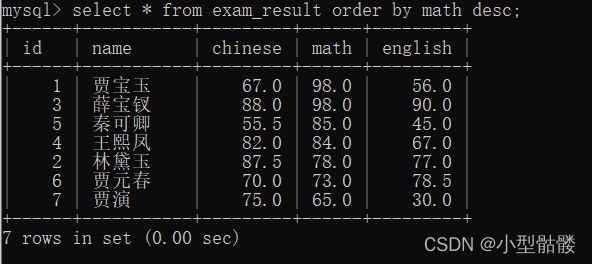
select 列名 from 表名 order by 需要排序的列名 asc/desc;
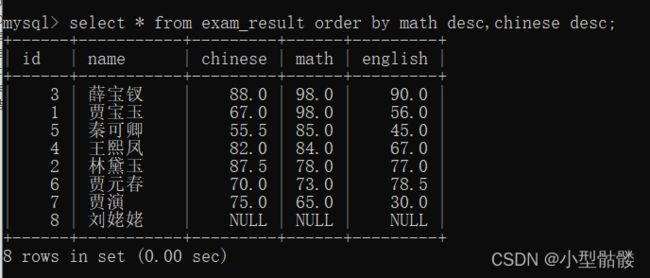
这里我按数学成绩来降序排序,这样数学成绩第一的就会出现在最上面:
有的数据库记录中是带有null值的,那么null会咋排序呢?我把之前刘姥姥的成绩插入进表中,再次对数学成绩进行升序排序:
可以看到,刘姥姥的成绩排在第一位,即在数据表排序的过程中,把null值视为最小值。
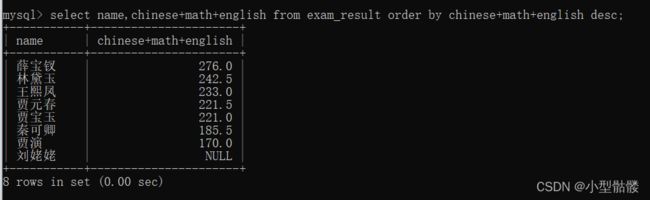
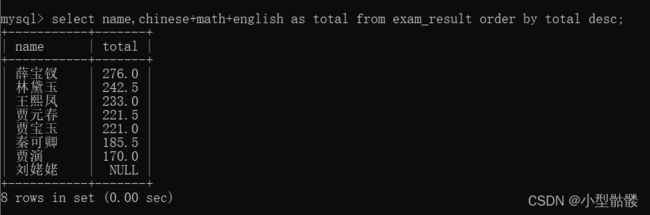
排序也可以以表达式为依据排序,比如这里我用总分来排个序:
排完序后我发现,哎呀,这样总分还要一个个加,多少有点麻烦,能不能先起个别名,然后再排啊?答案当然也是可以的:
如果排序的时候以数学成绩排分不出胜负(说的就是你贾宝玉和薛宝钗)也可以按其他列来排,即通过order by 指定多个列。若第一个列结果相同,按第二个列排序:
注意:1、asc/desc可以不写,asc是按升序排,desc是按降序排,如果不写,默认是升序(asc)。
2、按多个列排序查询是按列的输入顺序来。
3、指定多个列排序时,每个列都需要设定排序规则(asc/desc)。若第一个列按降序排列,第二个列没写(默认升序),那么在第一个列结果相同时,按第二个列的升序排列。

7、条件查询:
在进行条件查询之前,我们需要学习一下SQL中的一些比较运算符:
| 运算符 | 说明 |
| >, >=, <, <= | 大于、大于等于、小于、小于等于 |
| = | 等于。null不安全,例如null = null 结果为null |
| <=> | 等于。null安全,例如null <=> null结果为true |
| != , <> | 不等于 |
| BETWEEN x AND y | 范围匹配。[ x,y ],若x <= value <= y,返回true |
| IN(a1,a2,a3......) | 若是a1,a2,a3等等,中的一个,返回true |
| is null | 判断是否为null,若是则返回true |
| is not null | 判断是否不为null,若是则返回true |
| like | 模糊匹配。"%" 和 "_"都为通配符;%表示任意个任意字符,_表示任意一个字符 |
| and | A and B,A和B都为true,结果才为true |
| or | A or B,A或B任意一个为true,结果为true |
| not | 条件为true,结果为false |
7.1、基本查询:
select 列名 from 表名 where 查询条件 ;
条件查询时,可以单个列比较。例如,查询英语不及格的同学们以及它们的成绩(公开处刑hhh!(恶人脸)):
也可以多个列进行比较。例如,查询语文成绩比英语好的同学:
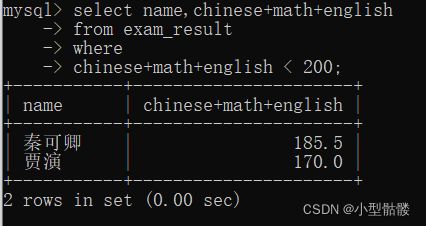
还可以对表达式进行查询。比如说,查询一下总分低于200的同学:
咱们都将到这了,我猜肯定有很多同学会想到能不能用起别名来条件查询?虽然想法是很好的,但是实际上是不行的!!!
所以,where条件语句可以使用表达式,但是不可以使用别名!
7.2、AND与OR:
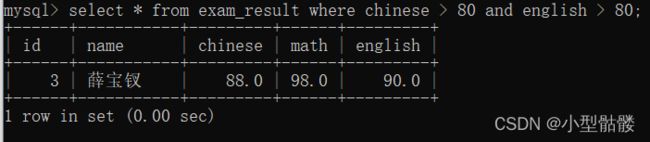
AND与OR可以分别单独使用。例如查询语文成绩大于80,并且英语也大于80的同学:
查询语文成绩大于80,或者英语成绩大于80的同学:
AND和OR呢也可以放在一起使用,但是需要注意的是,AND和OR之间是有优先级的,AND运算时的优先级比OR要高,例如:
上图这里虽然or写在and的前面,但是实际上这句sql意思为:查询语文成绩大于80或者数学和英语成绩都大于70的同学。就是要么你语文成绩80分以上,要么你数学和英语都70分朝上,才可以被我选中。
当然也有办法破解这种优先级顺序,只要加上一个括号就可以!例如:这样就变成了要么你就语文大于80或者数学大于70,要么就英语大于70。先算了or表达式,后算了and表达式!
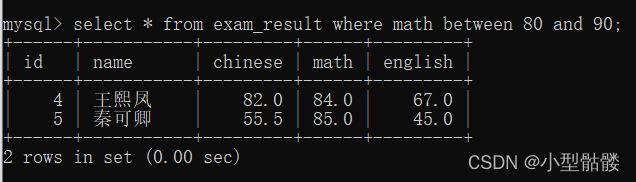
7.3、范围查询:
在查询过程中我们可以查询一定范围内的数据,使用【BETWEEN···AND···】,比如我现在查询数学成绩在80和90之间的同学:
当然了,这个查询使用and也可以实现:
注意:【BETWEEN···AND···】的区间前后都是闭区间,都是可以取到的。
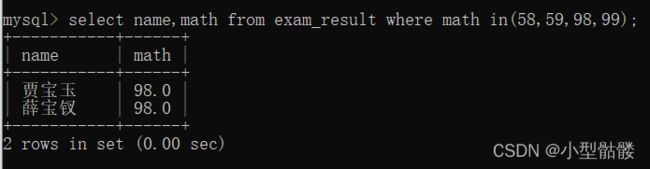
上面的范围查询是查询一个区间内的所有数,我们可以用关键字【IN】来查询更精准的数据,例如我现在要查询数学成绩只等于58、59、98、99的同学:
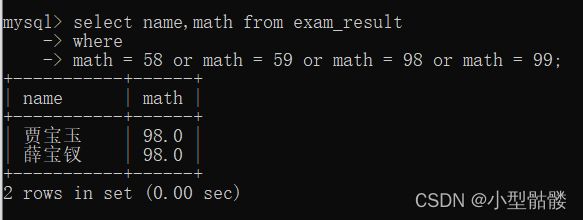
同样的,上面那个可以and实现,咱这个也可以用or来实现:
7.4、模糊查询:
这个模糊查询就需要用到【LIKE】关键字了,并且要用到SQL里的通配符:% 和 _ 。
例如我在这个成绩表里查一下都有谁是姓贾的(以贾字开头):在上图中我使用到了通配符:%。它的意思表示任意个任意字符,就是不论你贾字后面是什么字符不论你有多少,我都能给你查出来。我这里举个栗子,先插入一条记录:
继续查他!
可以看到,依然是可以查出来的,但是因为通配符是在‘贾’字后面,所以若贾字前面还有字符,那是不可能查出来的(明显违背自然常理好吧!)。
上面‘%’这个通配符是很强大的,那接下来我们来看一个不是那么强大,但是也很有用的通配符 —— ‘_’(下划线)它表示任意一个字符。
我来查一下有谁叫贾某吧,就两字儿:也可以把两个下划线 ‘_’ 拼一块,变成任意两个字符(那拼三个不就变成三个咯?):
这样查的话,看起来才是真正的 ‘贾某某’ ~~
7.5、关于NULL的查询:
我们之前看到我在表里插入一些是null的数据,那么能不能查找到null呢?可以!!!就用咱们之前表里看到的【IS NULL】和【IS NOT NULL】:
查询语文成绩是null的同学:
查询语文成绩不是null的同学:











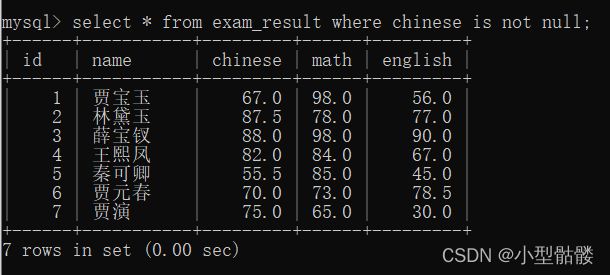
8、分页查询:
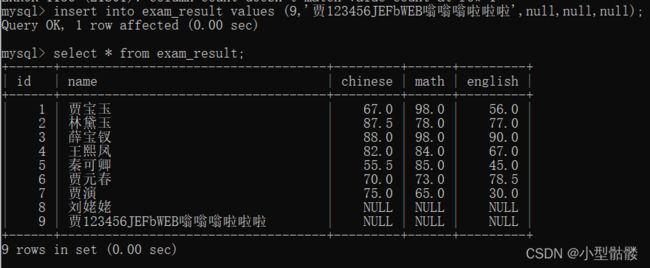
分页查询,顾名思义,就是把查询结果分成一页一页的形式,只不过我们自己可以控制分成几页,每一页显示多少条记录。比如每一页显示20条记录,那么第一页是1-20,第二页就是21-40,第三页就是41-60。分页查询的关键字为【LIMIT...OFFSET...】。我们先来看一下目前为止exam_result这个成绩表里的所有记录: 
呀,忘记删掉9号这个人了···
现在好了,哈哈哈,我先偷偷使用了第四真决:删!不过不必担心,马上我们就会讲到。 可以看到上面那个表里一共有8条记录,那我们就分成三页,每一页三条记录:
第一页:
第二页:
第三页:
这里的limit表示显示多少条记录,offset表示从第几条记录开始。
注意:1、最开始的页数(下标)为0。
2、若结果不足limit,则不受影响,如第三页。
第三真决:改!(Update)
update 表名 set 列名 修改语句 where 条件 ;
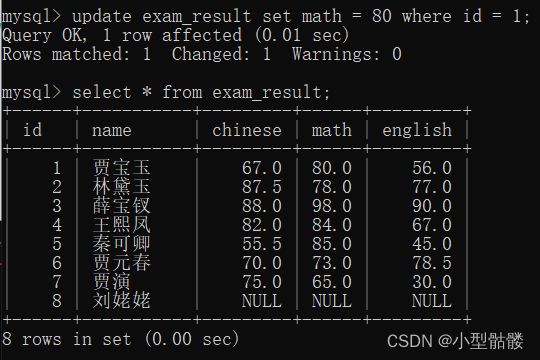
将贾宝玉的数学成绩改为80:
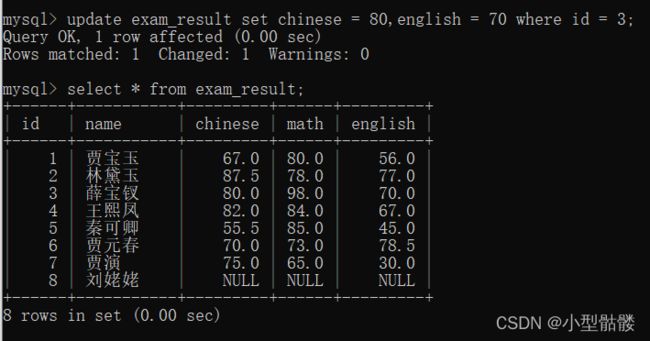
将薛宝钗语文改为60,英语改为70:
将总成绩倒数前三的同学数学成绩加上30:
注意:若修改后的数据超过原本的范围,则会修改失败。update是修改原始表上的数据,一旦修改成功,就会持久生效下去。
第四真决:删!(Delete)
delete from 表名 where 条件 ;
删除贾宝玉同学的所有成绩:
删完之后,再查一下,发现贾宝玉已经完全消失了。
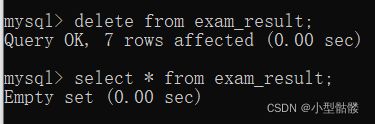
如果后面不加条件的话,就代表删除整个表的数据:
当我们执行完这个操作后,再次查询这个表时,发现提示我们empty(空)了,表名这个表所有数据已经被我们删除了,但是表还在的,已经成为了一个空表了!