序列处理的深度学习框架——从RNN到Transformer
目录
- Chapter9 序列处理的深度学习框架
-
- 9.1 回顾语言模型 (Language Models Revisited)
- 9.2 循环神经网络 (Recurrent Neural Networks)
-
- 9.2.1 RNN的推断 (Inference in RNNs)
- 9.2.2 训练 (Training)
- 9.2.3 循环神经网络与语言模型 (RNNs as Language Models)
- 9.2.3 RNN 的其它应用 (Other Applications of RNNs)
- 9.2.5 序列分类的RNN网络 (RNNs for Sequence Classification)
- 9.2.6 堆叠RNN与双向RNN (Stacked and Bidirectional RNN)
- 9.3 在RNN中管理内容:LSTM 与 GRU (Managing Context in RNNs: LSTMs and GRUs)
-
- 9.3.1 长短时记忆 (Long Shot-Term Memory)
- 9.3.2 门控循环单元 (Gated Recurrent Units)
- 9.3.3 门单元,层与网络 (Gated Units, Layers and Networks)
- 9.4 自注意力网络:Transformers (Self-Attention Networks: Transformers)
-
- 9.4.1 Transformers作为自回归语言模型 (Transformers as Autoregressive Language Models)
- 文本生成和摘要 (Contextual Generation and Summarization)
- 9.4.2 Transformer 模型结构总结 (Summary of Transformer Model Architecture)
- 9.5 语言模型的潜在危害 (Potential Harms from Language Models)
- 9.6 总结
原书:《Speech and Language Processing (3rd)》-- 斯坦福大学
章节:Chapter9 - Deep Learning Architectures for Sequence Processing
出版时间:第三版暂未出版,本章于2020年底在网络上公开
原文链接:https://web.stanford.edu/~jurafsky/slp3/9.pdf
在翻译过程中,译者会选择性省略部分内容;会重述部分内容;也会补充部分原书中未出现的内容。如有疏漏,烦请提出,不胜感激!
本博客是根据原书进行翻译整理得出,如有侵权,请联系删除。如需转载,请私信本人或在文章下方评论。
Chapter9 序列处理的深度学习框架
9.1 回顾语言模型 (Language Models Revisited)
概率语言模型是根据一些列给定的文本去预测下一个单词。我们可以用链式法则将条件概率结合起来,那么一个句子的概率就是:
P ( w 1 : n ) = ∏ i = 1 n P ( w i ∣ w < i ) P\left(w_{1: n}\right)=\prod_{i=1}^{n} P\left(w_{i} \mid w_{
第三章中的N-gram方法和第七章中的有滑窗的前馈神经网络方法都有一个缺陷,即他们均假设下一个词的出现只与前面的N个词有关,在N个词之前的词对最终的输出无影响。本章会放宽这个假设,这会让我们使用更多的文本。
我们通过混乱度(perplexity)来评估模型的质量:
P P θ ( w 1 : n ) = P ( w 1 : n ) 1 n P P_{\theta}\left(w_{1: n}\right)=P\left(w_{1: n}\right)^{\frac{1}{n}} PPθ(w1:n)=P(w1:n)n1
也有另一种根据熵的混乱度的度量方法,其来源于信息论:
P P ( w 1 : n ) = 2 H ( w 1 : n ) = 2 − 1 n ∑ 1 n log 2 m ( w n ) \begin{aligned} P P\left(w_{1: n}\right) &=2^{H\left(w_{1: n}\right)} \\ &=2^{-\frac{1}{n} \sum_{1}^{n} \log _{2} m\left(w_{n}\right)} \end{aligned} PP(w1:n)=2H(w1:n)=2−n1∑1nlog2m(wn)
9.2 循环神经网络 (Recurrent Neural Networks)
简单循环神经网络的结构图如下。其相较于第七章的前馈神经网络最大的变动是它添加了一个新的权值矩阵, U U U,它连接了上一个时间步的隐藏层和下一个时间步的隐藏层。这个权值决定了网络如何利用过去的内容去计算当前输入所决定的输出。同样地,该矩阵也会使用反向传播进行训练。

9.2.1 RNN的推断 (Inference in RNNs)
如上图所示,在时间步 t t t,输入为 x t x_t xt,输出为 y t y_t yt,隐藏层为 h t h_{t} ht,从上一个隐藏层 h t h_{t} ht 到这一个隐藏层 h t h_{t} ht 的权重矩阵为 U ∈ R d h × d h U \in \mathbb{R}^{d_{h} \times d_{h}} U∈Rdh×dh,输入到隐藏层的权重矩阵为 W ∈ R d h × d i n W \in \mathbb{R}^{d_{h} \times d_{i n}} W∈Rdh×din,隐藏层到输出层的权重矩阵为 V ∈ R d out × d h V \in \mathbb{R}^{d_{\text {out }} \times d_{h}} V∈Rdout ×dh,激活函数为 g g g 和 f f f。计算公式如下:
h t = g ( U h t − 1 + W x t ) y t = f ( V h t ) \begin{array}{l} h_{t}=g\left(U h_{t-1}+W x_{t}\right) \\ y_{t}=f\left(V h_{t}\right) \end{array} ht=g(Uht−1+Wxt)yt=f(Vht)
若将输出换为softmax函数,则公式为:
y t = softmax ( V h t ) y_{t}=\operatorname{softmax}\left(V h_{t}\right) yt=softmax(Vht)
9.2.2 训练 (Training)
下图说明了我们在前馈网络中不需要担心的两个问题。首先,为了计算 t t t 时刻输出的损失函数,我们需要 t − 1 t−1 t−1 时刻的隐含层。第二,隐层在时间t的影响在时间t的输出和隐层在时间 t + 1 t + 1 t+1 (因此输出和损失在 t + 1 t + 1 t+1 )。它遵循从这个评估误差积累 h t h_t ht 我们需要知道它的影响当前输出以及后面的输出。
根据这种情况调整反向传播算法,可以使用一种双通道算法来训练RNN中的权值。在第一次过程中,我们进行正向推理,计算 h t h_t ht , y t y_t yt ,累积每一步的损失,保存每一步隐含层的值,供下一个时间步使用。在第二阶段,我们逆向处理序列,随着我们的前进计算所需的梯度,计算并保存误差项,以便在每一步中向后使用隐含层。这种一般的方法通常被称为时间反向传播。
9.2.3 循环神经网络与语言模型 (RNNs as Language Models)
循环语言模型的结构如下:
e t = E T x t h t = g ( U h t − 1 + W e t ) y t = softmax ( V h t ) \begin{array}{l} e_{t}=E^{T} x_{t} \\ h_{t}=g\left(U h_{t-1}+W e_{t}\right) \\ y_{t}=\operatorname{softmax}\left(V h_{t}\right) \end{array} et=ETxtht=g(Uht−1+Wet)yt=softmax(Vht)
其中, E E E 是词嵌入矩阵。
给定了输出 y y y 之后,第 i i i 个词的概率为:
P ( w t + 1 = i ∣ w 1 : t ) = y t i P\left(w_{t+1}=i \mid w_{1: t}\right)=y_{t}^{i} P(wt+1=i∣w1:t)=yti
由此,一系列词语组成的序列的概率为:
P ( w 1 : n ) = ∏ i = 1 n P ( w i ∣ w 1 : i − 1 ) = ∏ i = 1 n y w i i \begin{aligned} P\left(w_{1: n}\right) &=\prod_{i=1}^{n} P\left(w_{i} \mid w_{1: i-1}\right) \\ &=\prod_{i=1}^{n} y_{w_{i}}^{i} \end{aligned} P(w1:n)=i=1∏nP(wi∣w1:i−1)=i=1∏nywii
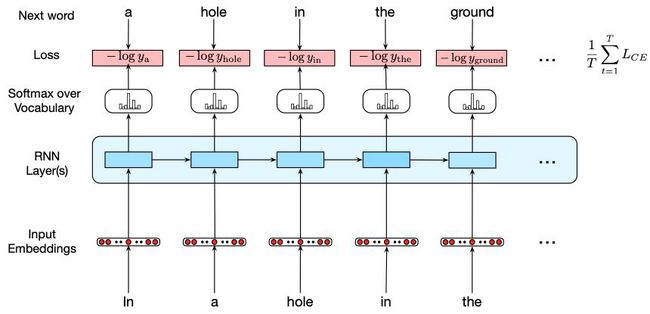
为了训练模型,我们使用文本语料库作为培训材料,并结合名为教师强迫(teacher forcing)的训练方案。使用交叉熵作为损失函数,其任务是最小化预测训练序列中下一个单词的误差。回想一下,交叉熵损失度量的是预测概率分布与正确分布之间的差异,
L C E = − ∑ w ∈ V y w t log y w t ^ L_{C E}=-\sum_{w \in V} y_{w}^{t} \log y_{w}^{\hat{t}} LCE=−w∈V∑ywtlogywt^
在该语言模型下,正确的分布 y y y 来自于知道下一个单词。这表示为对应于词汇表的one-hot向量,其中实际下一个单词的条目为1,其他所有条目为0。因此,语言建模的交叉熵损失是由模型分配给正确的下一个单词的概率决定的。具体来说,在时刻 t t t,CE损失是分配给训练序列中下一个单词的负对数概率,
L C E ( y ^ t , y t ) = − log y ^ w t + 1 t L_{C E}\left(\hat{y}^{t}, y^{t}\right)=-\log \hat{y}_{w_{t+1}}^{t} LCE(y^t,yt)=−logy^wt+1t
E的行表示训练过程中学习到的词汇中每个词嵌入,目的是让意义和功能相似的单词具有相似的词嵌入。由于这些嵌入的长度对应于隐藏层 d h d_h dh 的大小,因此嵌入矩阵形状 E E E 为 ∣ V ∣ × d h |V|× d_h ∣V∣×dh 。
具体结构如下图:
以RNN为基础的生成式语言模型
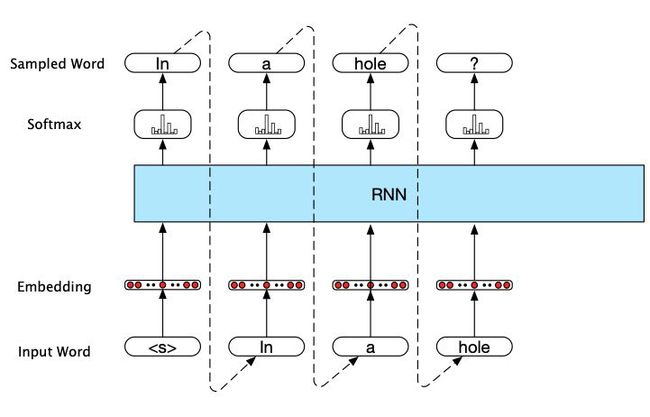
该模型的主要步骤如下:
- 首先,从softmax分布的输出中选取一个单词作为第一个输入,这是使用句子标记开头 < s >
- 使用第一个单词的单词嵌入作为下一个时间步骤的网络输入,然后以同样的方式采样下一个单词。
- 继续生成,直到采样到句子标记 < / s > </s> 或达到固定长度限制为止。
这种技术被称为自回归生成,因为每一步生成的词都是以网络在前一步中选择的词为条件的。该模型的具体结构如下图:
虽然这是一个有趣的练习,但这种架构激发了应用程序的最先进方法,如机器翻译、摘要和问题回答。这些方法的关键是使用适当的上下文来启动生成组件。也就是说,我们可以提供更丰富的适合任务的上下文,而不是简单地使用 < s > <s> 来开始。
9.2.3 RNN 的其它应用 (Other Applications of RNNs)
序列标注 Sequence Labeling
在序列标记中,网络的任务是从一小组固定的标签中选择一个标签分配给序列的每个元素。序列标记的典型例子包括词性标记和命名实体识别,这些已经在第8章进行了详细讨论。在RNN序列标注方法中,输入是词嵌入,输出是由softmax层在给定标签集上生成的标签概率,详见下图:
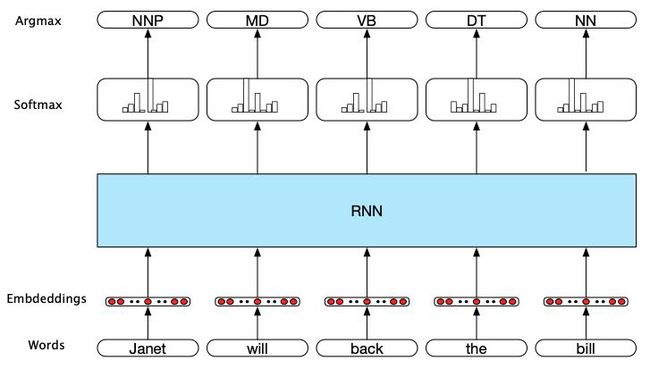
在这个图中,每个时间步的输入都是预先训练的与输入标记对应的词嵌入。RNN块是一个抽象,它表示一个在每个时间步上由输入层、隐含层和输出层组成的展开的简单递归网络,以及组成网络的共享的 U U U、 V V V 和 W W W 权矩阵。网络在每个时间步长的输出表示由softmax层生成的POS标记集上的分布。
为了为给定的输入生成标签序列,我们在输入序列上运行向前推理,并在每一步从softmax中选择最有可能的标签。由于我们使用softmax层在每个时间步上生成输出标记集的概率分布,我们将在训练期间再次使用交叉熵损失。
9.2.5 序列分类的RNN网络 (RNNs for Sequence Classification)
为了在序列分类中应用RNN,待分类的文本每次通过RNN传递一个单词,在每个时间步长生成一个新的隐藏层。将文本最后一个元素 h n h_n hn 的隐含层作为整个序列的压缩表示。在最简单的分类方法中, h n h_n hn 作为后续前馈网络的输入,通过softmax在可能的类别中选择一个类别。具体结构见下图:
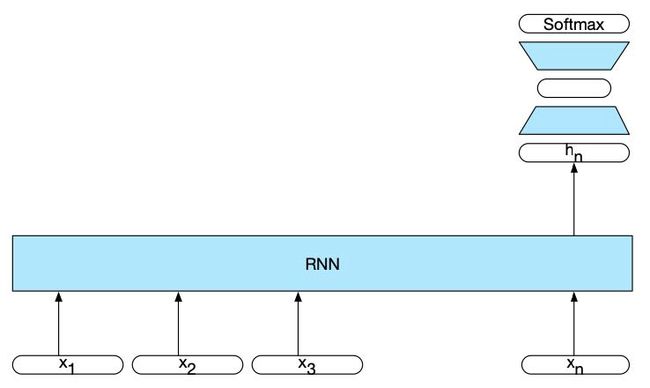
注意,在这种方法中,最后一个元素前面的序列中的单词没有中间输出。因此,没有与这些元素相关的损失项。相反,用于训练网络权重的损失函数完全基于最终的文本分类任务。具体来说,前馈分类器的softmax输出与交叉熵损失一起训练。分类的错误信号通过前馈分类器中的权值一直反向传播到其输入,然后再反向传播到前面9.2.2节中描述的RNN中的三组权值。这种简单递归网络与前馈分类器的组合是我们深度神经网络(deep neural network)的第一个例子。使用来自下游应用程序的损失在整个网络中调整权值的训练方案称为端到端训练(end-to-end training)。
9.2.6 堆叠RNN与双向RNN (Stacked and Bidirectional RNN)
堆叠RNNs
它已经在许多任务中得到了证明,堆叠RNN可以比单层网络的形式更好。这一成功的原因之一是其有能力在不同的抽象层上诱导表示。具体结构见下图:

堆叠的最优数量是根据每个应用和每个训练集而定的。但是,随着堆叠层数的增加,训练成本迅速上升。
双向RNNs
在一个简单的循环网络中,在给定时间 t t t 的隐藏状态代表了网络在序列中那个点之前所知道的所有关于序列的信息。也就是说,时刻 t t t 的隐藏状态是从启动到时刻 t t t 的输入的函数的结果。我们可以把这看作是当前时刻左侧的网络环境。
h t f = R N N forward ( x 1 t ) h_{t}^{f}=R N N_{\text {forward }}\left(x_{1}^{t}\right) htf=RNNforward (x1t)
其中, h t f h_{t}^{f} htf 对应于t时刻的正常隐藏状态,表示网络从序列到该点收集到的所有信息。
在许多应用中,我们可以一次访问整个输入序列。我们可能会问,利用当前输入右侧的上下文是否也有帮助。恢复这些信息的一种方法是用反向的输入序列训练RNN,使用的是我们讨论过的完全相同的网络类型。通过这种方法, t t t 时刻的隐藏状态现在表示关于当前输入右侧序列的信息。
h t b = R N N backward ( x t n ) h_{t}^{b}=R N N_{\text {backward }}\left(x_{t}^{n}\right) htb=RNNbackward (xtn)
将正向网络和反向网络相结合,可以得到一个双向RNN。一个Bi-RNN由两个独立的rnn组成,一个从开始到结束处理输入,另一个从结束到开始处理输入。然后,我们将两个网络的输出组合成一个单独的表示形式,在每个时间点捕捉输入的左上下文和右上下文。
h t = h t f ⊕ h t b h_{t}=h_{t}^{f} \oplus h_{t}^{b} ht=htf⊕htb
连接是组合两个输出的常用方法,但也使用元素的求和、乘法或平均。
下面两个图是双向RNN对于刚才所述的文本生成和句子分类的应用。
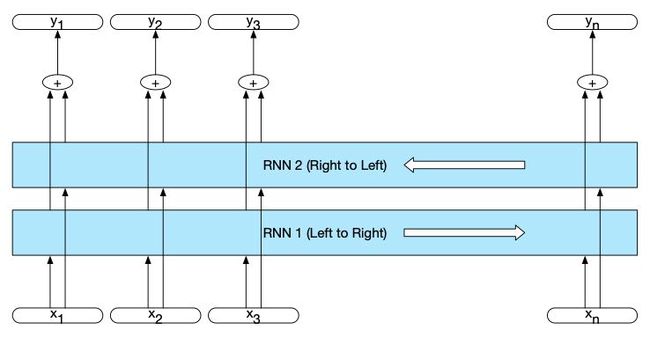
如上是一个双向RNN。分别的模型在前进和后退方向进行训练,每个模型在每个时间点的输出连接起来,以表示该时间点的事件状态。围绕着向前和向后网络的盒子强调了这种架构的模块化本质。
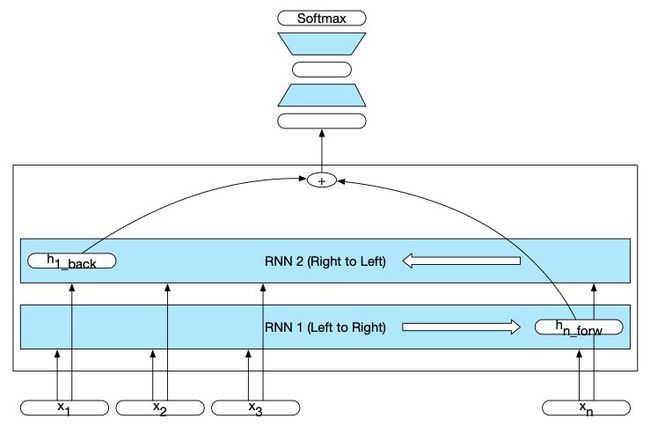
如上是一种用于序列分类的双向RNN。从向前和向后传递的最终隐藏单位被组合起来代表整个序列。这个组合的表示可以作为后续分类器的输入。
9.3 在RNN中管理内容:LSTM 与 GRU (Managing Context in RNNs: LSTMs and GRUs)
在实践中,训练RNN来完成需要网络利用远离当前处理点的信息的任务是相当困难的。
RNN无法有效处理很久之前的重要信息的一个原因是隐藏层(及权重确定隐层中的值)同时被要求执行两个任务:为当前的决策提供有用的信息,更新和携带对未来决策有用的之前的信息。
训练RNN的第二个困难来自需要通过时间反向传播错误信号。回想一下9.2.2节,在 t t t 时刻的隐含层对下一个时间步的损失有贡献,因为它参与了计算。因此,在向后的训练过程中,隐含层要根据序列的长度进行多次乘法运算。这个过程的一个常见结果是这个梯度会趋近于零——这就是所谓的梯度消失(vanishing gradients)问题。
9.3.1 长短时记忆 (Long Shot-Term Memory)
长-短期记忆网络(LSTM networks)将文本管理问题分为两个子问题:从文本中删除不再需要的信息和添加以后决策可能需要的信息。解决这两个问题的关键是学习如何管理文本,而不是将策略硬编码到架构中。LSTM做到这一点,首先添加一个显式文本层架构(通常循环隐藏层),并通过使用专门的神经单元,利用门(gates)控制信息流入和流出包括网络层的单元。这些门是通过使用对输入、前一个隐藏层和前一个文本层进行顺序操作的额外权重来实现的。
LSTM的门具有相同的设计模式:每个都包括一个前馈层,接着是一个sigmoid激活函数,然后是一个元素相乘的被门控制的层。选择sigmoid函数作为激活函数是因为它倾向于输出0或1。将此方法与逐点乘法相结合,其效果类似于二进制掩码(binary mask)。由门控制的层中的值与掩盖层(mask)中的值接近1的值几乎没有变化;较低的值基本上被抹去。
首先是遗忘门(forget gate),其目的是从文本中删除不需要的信息。遗忘门计算一个之前的隐藏层与当前的输入的加权求和,然后传到一个sigmoid函数中。然后将此掩码与文本向量 c c c 相乘,以从上下文中删除不再需要的信息:
f t = σ ( U f h t − 1 + W f x t ) k t = c t − 1 ⊙ f t \begin{array}{l} f_{t}=\sigma\left(U_{f} h_{t-1}+W_{f} x_{t}\right) \\ k_{t}=c_{t-1} \odot f_{t} \end{array} ft=σ(Ufht−1+Wfxt)kt=ct−1⊙ft
下一个任务是计算我们需要从之前的隐藏状态和当前输入中提取的实际信息——这与我们在所有循环网络中使用的基本计算方法相同:
g t = tanh ( U g h t − 1 + W g x t ) g_{t}=\tanh \left(U_{g} h_{t-1}+W_{g} x_{t}\right) gt=tanh(Ught−1+Wgxt)
接下来,为添加门(add gate)生成掩码,以选择要添加到当前文本文的信息:
i t = σ ( U i h t − 1 + W i x t ) j t = g t ⊙ i t \begin{array}{l} i_{t}=\sigma\left(U_{i} h_{t-1}+W_{i} x_{t}\right) \\ j_{t}=g_{t} \odot i_{t} \end{array} it=σ(Uiht−1+Wixt)jt=gt⊙it
接下来,我们将它添加到修改后的文本向量中,以获得新的文本向量:
c t = j t + k t c_{t}=j_{t}+k_{t} ct=jt+kt
我们将使用的最后一个门是输出门,它用于决定当前隐藏状态需要什么信息(而不是为未来的决策需要保留什么信息):
o t = σ ( U o h t − 1 + W o x t ) h t = o t ⊙ tanh ( c t ) \begin{array}{l} o_{t}=\sigma\left(U_{o} h_{t-1}+W_{o} x_{t}\right) \\ h_{t}=o_{t} \odot \tanh \left(c_{t}\right) \end{array} ot=σ(Uoht−1+Woxt)ht=ot⊙tanh(ct)
给定各种门的适当权值,LSTM接受上下文层、前一时间步的隐藏层以及当前输入向量作为输入。然后它生成更新的上下文和隐藏向量作为输出。隐藏层 h t h_t ht 可以作为堆叠RNN中后续层的输入,也可以为网络的最后一层生成输出。
下图是LSTM的结构:

译者注:图中的 s t − 1 s_{t-1} st−1和 s t s_t st 分别表示公式中的 c t − 1 c_{t-1} ct−1和 c t c_t ct,即文本向量。原文仍在编写中,所以图像可能尚未进行修改。后续会持续更新。
9.3.2 门控循环单元 (Gated Recurrent Units)
LSTM为我们的循环网络引入了相当多的附加参数。现在我们有8组权重需要学习(即每个单元中的4个门的 U U U 和 W W W ),而在简单的回归单元中我们只有2个。这些额外的参数增加了训练成本。门控循环单元(GRUs)通过免除使用单独的上下文向量,并通过将门的数量减少到2个(重置门 r r r 和更新门 z z z)来减轻这一负担。
r t = σ ( U r h t − 1 + W r x t ) z t = σ ( U z h t − 1 + W z x t ) \begin{aligned} r_{t} &=\sigma\left(U_{r} h_{t-1}+W_{r} x_{t}\right) \\ z_{t} &=\sigma\left(U_{z} h_{t-1}+W_{z} x_{t}\right) \end{aligned} rtzt=σ(Urht−1+Wrxt)=σ(Uzht−1+Wzxt)
与LSTMs一样,在这些门的设计中使用sigmoid会产生一个类似二进制的掩码,该掩码要么屏蔽值接近于0的信息,要么允许值接近于1的信息不受影响地通过。重置门的目的是决定前一个隐藏状态的哪些方面与当前文本相关,哪些可以忽略。这是通过将 r r r 与前一个隐藏状态的值相乘来实现的。然后,我们使用这个掩码值来计算时间 t t t 时新的隐藏状态的中间表示。
h ~ t = tanh ( U ( r t ⊙ h t − 1 ) + W x t ) \tilde{h}_{t}=\tanh \left(U\left(r_{t} \odot h_{t-1}\right)+W x_{t}\right) h~t=tanh(U(rt⊙ht−1)+Wxt)
更新门z的作用是确定这个新状态的哪些方面将直接用于新的隐藏状态,以及前一个状态的哪些方面需要保留以供将来使用。这是通过使用 z z z 去计算在旧隐藏状态和新隐藏状态之间插值来完成的:
h t = ( 1 − z t ) h t − 1 + z t h ~ t h_{t}=\left(1-z_{t}\right) h_{t-1}+z_{t} \tilde{h}_{t} ht=(1−zt)ht−1+zth~t
9.3.3 门单元,层与网络 (Gated Units, Layers and Networks)

上图展示了四个基本的神经单元结构。
(a) 是最基本的前馈单元,由一组权值和一个激活函数决定其输出,当被安排在一层时,层内各单元之间没有连接。
(b) 表示简单循环网络中的单位。现在有两个输入和一组额外的权重。然而,仍然有一个单独的激活函数和输出。
© LSTM 和 (d) GRU 单元被各自封装了起来。LSTM相较于(b)唯一的额外复杂性是它包括了文本向量的输入和输出。而GRU和(b)有相同的输入输出结构。
9.4 自注意力网络:Transformers (Self-Attention Networks: Transformers)
尽管LSTMs有能力减轻由于RNN的重复的链接而造成的远程信息丢失,但潜在的问题仍然存在。通过一系列重复的连接传递信息会导致相关信息的丢失和训练的困难。此外,循环网络固有的顺序性质抑制了并行计算资源的使用。这些考虑导致了Transformer的发展——一种序列处理的方法,它消除了重复的连接,并返回到类似于第七章前面描述的全连接网络的架构。
Transformer将输入向量序列 ( x 1 , … , x n ) (x_1, …, x_n) (x1,…,xn) 映射到相同长度的输出向量序列 ( y 1 , … , y n ) (y_1, …, y_n) (y1,…,yn)。变压器由一系列的网络层组成,这些网络层由简单的线性层、前馈网络和它们周围的自定义连接组成。除了这些标准组件外,Transformer的关键创新是使用自注意力层(self-attention layers)。我们将从描述自注意力机制如何工作开始,然后回到它如何适应更大的Transformer块。自注意力允许网络直接从任意大的上下文中提取和使用信息,而不需要像在RNNs中那样通过中间反复的连接来传递信息。在这一章中,我们将重点关注自注意力在语言建模(language model)和自回归生成(autoregressive generation)的问题上的应用,这些问题在过去的讨论中使用了文本内容(即我们在LSTM中看到的 c t c_t ct )。我们将在后面的章节中回到自注意力机制和Transformer的更广泛的应用。
下图说明了单个自注意力层(或后向自注意力层)的信息流动。与整个Transformer一样,自注意层将输入序列 ( x 1 , … , x n ) (x_1, …, x_n) (x1,…,xn) 映射到相同长度的输出序列 ( y 1 , … , y n ) (y_1, …, y_n) (y1,…,yn)。当处理输入中的每个项时,模型可以访问所有的输入,包括考虑中的输入,但是不能访问关于当前输入以外的信息。此外,为每个项目执行的计算是独立于所有其他计算的。第一点确保我们可以使用这种方法来创建语言模型,并将其用于自回归生成,第二点意味着我们可以轻松地并行化向前推理(forward inference)和对这些模型进行训练。
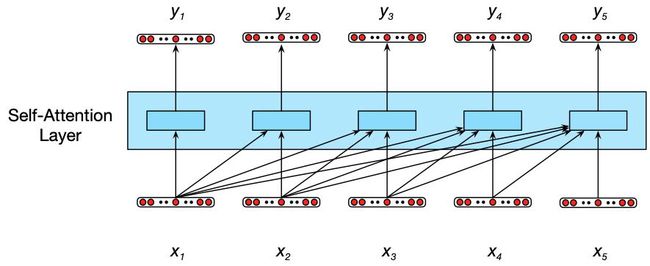
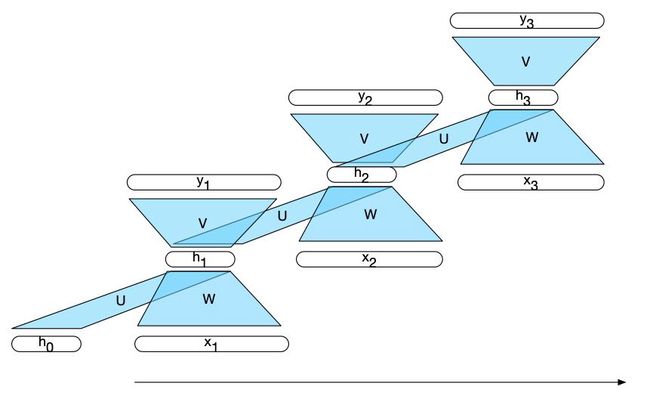
注意力方法的核心是将感兴趣的项与其他项的集合进行比较,从而揭示它们在当前文本中的相关性。在自注意力的情况下,比较集是给定序列中的其他元素的。然后,将这些比较的结果用于计算当前输入的输出。例如,上图中, y 3 y_3 y3 的计算是基于输入 x 3 x_3 x3 与之前的元素 x 1 x_1 x1、 x 2 x_2 x2 以及 x 3 x_3 x3 本身的一组比较。自注意力层中元素之间比较的最简单形式是点积。为了考虑到其他可能的比较,让我们将这些比较的结果称为分数,
score ( x i , x j ) = x i ⋅ x j \operatorname{score}\left(x_{i}, x_{j}\right)=x_{i} \cdot x_{j} score(xi,xj)=xi⋅xj
然后,为了有效地利用这些分数,我们将使用softmax对它们进行标准化,以创建权重向量 α i j α_{ij} αij,该向量表示每个输入与当前关注焦点的输入元素 i i i 的比例相关性,
α i j = softmax ( score ( x i , x j ) ) ∀ j ≤ i = exp ( score ( x i , x j ) ) ∑ k = 1 i exp ( score ( x i , x k ) ) ∀ j ≤ i \begin{aligned} \alpha_{i j} &=\operatorname{softmax}\left(\operatorname{score}\left(x_{i}, x_{j}\right)\right) \forall j \leq i \\ &=\frac{\exp \left(\operatorname{score}\left(x_{i}, x_{j}\right)\right)}{\sum_{k=1}^{i} \exp \left(\operatorname{score}\left(x_{i}, x_{k}\right)\right)} \forall j \leq i \end{aligned} αij=softmax(score(xi,xj))∀j≤i=∑k=1iexp(score(xi,xk))exp(score(xi,xj))∀j≤i
给出了以 α \alpha α 为单位的比例分数,然后我们将目前所看到的输入的总和,按各自的 α \alpha α 值加权,生成一个输出值 y i y_i yi,
y i = ∑ j ≤ i α i j x j y_{i}=\sum_{j \leq i} \alpha_{i j} x_{j} yi=j≤i∑αijxj
不幸的是,这个简单的机制没有提供学习的机会,一切都直接基于原始输入值 x x x。特别是,我们没有机会学习单词如何以不同的方式表示较长的输入。为了允许这种学习,Transformer以一组权重矩阵的形式包含了额外的参数,这些参数在输入的嵌入项上运行。为了激发这些新的参数,考虑每个输入嵌入在注意过程中扮演的不同角色。
- Query:它是当前关注的焦点,其与前面的所有其他输入进行比较。我们将此角色称为查询,query。
- Key:它作为之前的输入,其与当前关注的焦点(即query)相比较。我们将此角色称为键,key。
- Value:它是一个值 value,其用于计算当前关注焦点的输出。
为了捕获输入嵌入在每个步骤中扮演的不同角色,transformer引入了三组权重,我们将其称为 W Q W^{Q} WQ、 W K W^{K} WK 和 W V W^{V} WV。这些权重将用于计算每个输入 x x x 的线性转换,其结果值将用于后续计算中各自的角色,
q i = W Q x i ; k i = W K x i ; v i = W V x i q_{i}=W^{Q} x_{i} ; k_{i}=W^{K} x_{i} ; v_{i}=W^{V} x_{i} qi=WQxi;ki=WKxi;vi=WVxi
给定了输入嵌入的维度 d m d_m dm,这些矩阵的维度分别是 d q × d m d_{q} \times d_{m} dq×dm, d k × d m d_{k} \times d_{m} dk×dm,和 d v × d m d_{v} \times d_{m} dv×dm。在原始的Transformer论文中, d m d_m dm 的维度是1024, d k d_k dk, d q d_q dq 和 d v d_v dv 的维度是64。
给定这些投影矩阵,当前关注焦点 x i x_i xi 和之前文本中的元素 x j x_j xj 之间的分数由其查询向量 q i q_i qi 和前面元素键向量 k j k_j kj 之间的点积组成。让我们更新之前的比较计算来反映这一点:
score ( x i , x j ) = q i ⋅ k j \operatorname{score}\left(x_{i}, x_{j}\right)=q_{i} \cdot k_{j} score(xi,xj)=qi⋅kj
随后产生 α \alpha α 的softmax计算保持不变,但 y i y_i yi 的输出计算现在基于值向量 v v v 的加权和:
y i = ∑ j ≤ i α i j v j y_{i}=\sum_{j \leq i} \alpha_{i j} v_{j} yi=j≤i∑αijvj
下图说明了计算 y 3 y_3 y3 的过程:
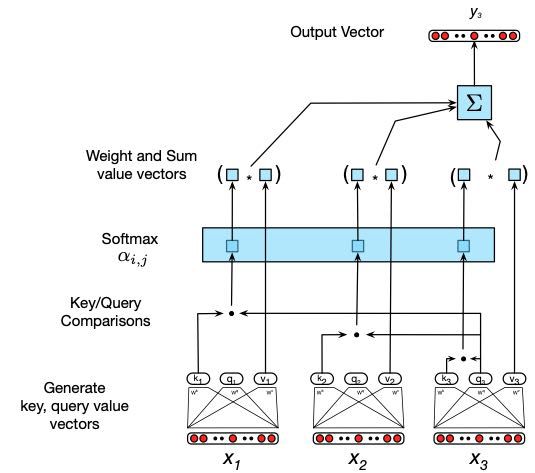
计算 α i j \alpha_{i j} αij 中出现的一个实际考虑来自于使用点积与softmax中的指数相结合进行比较。点积的结果可以是任意大的(正数或负数)值。对如此大的值取幂可能会导致数值问题,并在训练过程中有效地丢失梯度。为了避免这种情况,需要以合适的方式缩放点积。缩放的点积方法将点积的结果除以一个与嵌入尺寸相关的因子,然后将它们通过softmax。一种典型的方法是将点积除以查询的维度和键向量的平方根,从而导致我们再次更新评分函数。
score ( x i , x j ) = q i ⋅ k j d k \operatorname{score}\left(x_{i}, x_{j}\right)=\frac{q_{i} \cdot k_{j}}{\sqrt{d_{k}}} score(xi,xj)=dkqi⋅kj
这种对自注意力过程的描述是从计算特定时间点的单个输出的角度出发的。然而,由于每个输出, y i y_i yi,可以在整个过程中独立地被计算,因此我们可以通过高效的并行矩阵乘法的方式进行并行计算。具体方法是对输入嵌入打包到一个矩阵,然后乘以key,query和value矩阵去得到包含所有key,query 和 value 向量的矩阵:
Q = W Q X ; K = W K X ; V = W V X Q=W^{Q} X ; K=W^{K} X ; V=W^{V} X Q=WQX;K=WKX;V=WVX
给定这些矩阵,我们可以通过在单个矩阵乘法中乘以 K K K 和 Q Q Q 来同时计算所有必需的 query-key 比较。更进一步,我们可以衡量这些分数,取softmax,然后将结果乘以 V V V,从而将整个序列的整个自注意力步骤减少到以下计算中:
SelfAttention ( Q , K , V ) = softmax ( Q K T d k ) V \text { SelfAttention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V SelfAttention (Q,K,V)=softmax(dkQKT)V
不幸的是,上述过程有点“过”了,因为 Q K T QK^T QKT 中的比较计算会为每个query对每个key (包括query后面的key) 产生一个分数。这在语言建模的设置中是不合适的,因为如果您已经知道下一个单词,猜测它是非常简单的。为了解决这个问题,比较矩阵的上三角部分中的元素被置零(设为−∞),从而消除序列中单词的任何知识。
Transformer Blocks
自注意力计算位于所谓的Transformer块的核心,除了自注意力层之外,它还包括额外的前馈层、剩余连接和标准化层。下图显示了一个典型的Transformer块,它由一个关注层和一个全连接的前馈层组成,每个前馈层后面都有剩余连接和层归一化。然后可以像堆叠RNN那样堆叠这些块。

多头注意力 (Multihead Attention)
个句子中的不同单词可以同时以许多不同的方式联系在一起。例如,在一个句子中,动词和它们的受词之间可以存在不同的句法、语义和话语关系。对于单个Transformer组来说,学习捕获其输入之间所有不同类型的并行关系是很困难的。Transformer通过多头自注意层来解决这个问题。这些是一组自注意力层,称为“头”,它们位于模型中相同深度的平行层中,每个层都有自己的一组参数。给定这些不同的参数集,每个头都可以学习在同一抽象级别上存在的输入之间的关系的不同方面。
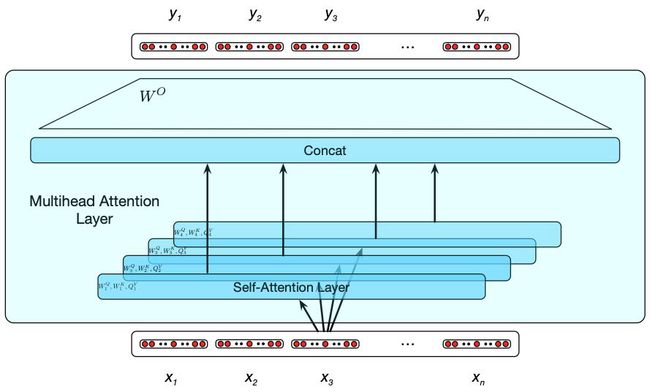
为了实现这个概念,自注意力层中的每个头 i i i 都有自己的一组key、query和value矩阵: W i Q W_i^{Q} WiQ、 W i K W_i^{K} WiK 和 W i V W_i^{V} WiV。它们用于将输入分别投射到每个头的 x i x_i xi 层,而自注意力计算的其余部分保持不变。带有 h h h 个头的多头层的输出由 h h h 个相同长度的向量组成。为了在进一步的处理中利用这些向量,它们被组合起来,然后减少到原始的输入维数 d m d_m dm。这是通过连接每个头的输出,然后使用另一个线性投影来减少到原始的输出维数来完成的。
MultiHeadAttn ( Q , K , V ) = W O ( head 1 ⊕ head 2 … ⊕ head h ) head i = SelfAttention ( W i Q X , W i K X , W i V X ) \begin{aligned} \text { MultiHeadAttn }(Q, K, V) &=W^{O}\left(\text { head }_{1} \oplus \text { head }_{2} \ldots \oplus \text { head }_{h}\right) \\ \text { head }_{i} &=\text { SelfAttention }\left(W_{i}^{Q} X, W_{i}^{K} X, W_{i}^{V} X\right) \end{aligned} MultiHeadAttn (Q,K,V) head i=WO( head 1⊕ head 2…⊕ head h)= SelfAttention (WiQX,WiKX,WiVX)
下图展示了4个自注意力头的情况。该多头层取代了由上图所示的Transformer组中的单个自注意力层,Transformer组的其余部分及其前馈层、剩余连接和归一化层保持不变。
位置编码 Positional Embeddings
译者注:原文使用 position embeddings 的用词,直译为位置嵌入,但是论文《Attention is All You Need》中使用的词为positional encoding。在这里,我们保留英文描述position embeddings,但中文翻译为位置编码。
在RNN网络中,有关输入顺序的信息被融入到模型的性质中。不幸的是,Transformer的情况并非如此;其并不允许使用输入序列元素的相对或绝对位置的信息。这可以从以下事实中看出来:如果你打乱前面提到的注意力计算的输入顺序,你会得到完全相同的答案。为了解决这个问题,Transformer的输入与特定于输入序列中每个位置的位置嵌入相结合。
我们从哪里得到这些位置编码呢?一个简单而有效的方法是随机初始化每一个词所对应的位置嵌入,直到文本末尾。例如,正如我们对单词fish进行了嵌入,我们也将对位置3进行嵌入(如果fish这个单词在第3个位置的话)。与单词嵌入一样,这些位置编码在训练过程中与其他参数一起学习。要生成捕获位置信息的输入嵌入,只需将每个输入的词嵌入添加到对应的位置编码中。这个新的嵌入作为进一步处理的输入。
这种方法的一个潜在问题是,在我们的输入中会有大量的初始位置的训练示例,而在外部长度限制时相应的较少。这些后一种编码可能训练不足,并且在测试期间可能不能很好地推广。位置编码的另一种方法是选择一个静态函数,以捕获位置之间的内在关系的方式将整数输入映射到实值向量。也就是说,它捕捉到这样一个事实,即输入中的位置4与位置5的关系比与位置17的关系更密切。在原Transformer的工作中,使用了不同频率的正弦和余弦函数的组合。
下面是译者添加:
本书原文中未展示出具体的位置编码的公式,下面将补充出来。
位置编码 P E ∈ R L × d \mathbf{PE} \in \mathbb{R}^{L \times d} PE∈RL×d拥有和输入向量相同的维度,因此它课直接加载输入之后。原始的Transformer考虑了正弦位置编码(Sinusoidal positional encoding),其定义如下:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d model ) P E ( pos , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d model ) \begin{aligned} P E_{(p o s, 2 i)} &=\sin \left(\frac{pos}{10000^{2 i / d_{\text {model }}}}\right) \\ \\ P E_{(\text {pos }, 2 i+1)} &=\cos \left(\frac{pos}{10000^{2 i / d_{\text {model }}}}\right) \end{aligned} PE(pos,2i)PE(pos ,2i+1)=sin(100002i/dmodel pos)=cos(100002i/dmodel pos)
其中, p o s = 1 , . . . , L pos = 1, ..., L pos=1,...,L 是单词的位置, i = 1 , . . . , d i = 1, ..., d i=1,...,d 为维度,具体来说就是在一个 d d d维向量中的第 i i i个位置。在实际的代码实现中,我们会对其进行适当的形式变换,这里暂不详述。
译者添加结束。
9.4.1 Transformers作为自回归语言模型 (Transformers as Autoregressive Language Models)
现在我们已经了解了Transformer的所有主要组件,让我们看看如何通过半监督学习将它们部署为语言模型。为此,我们将像使用基于RNN的方法一样继续进行:给定纯文本的训练语料库,我们将训练一个模型,以使用教师强制(teacher forcing)来预测序列中的下一个单词。下图说明了一般的方法。在每一步中,给定所有前面的单词,最终的Transformer层在整个词汇表上产生一个输出分布。在训练过程中,分配给正确单词的概率用于计算序列中每个项目的交叉熵损失。与RNN一样,训练序列的损失是整个序列的平均交叉熵损失。

注意此图与前期基于RNN的版本的关键区别。在RNN中,每一步的输出和损失的计算本质上是串行的,因为在计算隐藏状态时是循环的。使用Transformer,可以并行处理每个训练项目,因为序列中每个元素的输出是分别计算的。一旦训练,我们可以计算得到的模型的混乱度(perplexity),或自回归生成新的文本,就像基于RNN的模型一样。
文本生成和摘要 (Contextual Generation and Summarization)
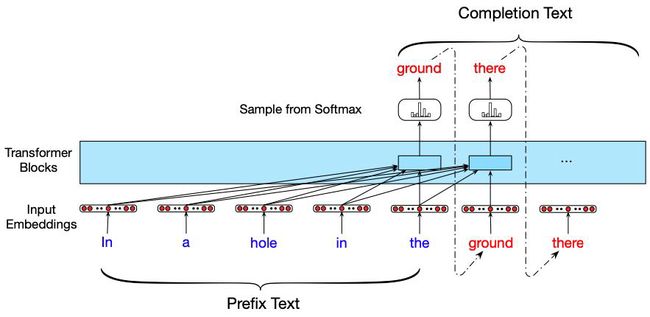
自回归生成的一个简单的变异是使用先前的文本来启动自回归生成过程,它是许多实际应用程序的基础。下图用文本补全任务说明了这一点。在这里,给一个标准语言模型一个文本的前缀,并要求它生成一个可能的实现。请注意,随着生成过程的进行,模型可以直接访问启动文本以及它自己随后生成的所有输出。这种在每个时间步骤中合并整个前期文本和生成输出的能力是这些模型强大的关键。
文本摘要是基于上下文的自回归生成方法的一个实际应用。这里的任务是获取一篇完整的文章,并对其进行有效的总结。为了训练一个基于Transformer的自回归模型来完成这项任务,我们从一个由全文文章及其相应摘要组成的语料库开始。
将Transformer应用于摘要的一个非常有效的方法是在语料库中的每一篇完整的文章后附加一个摘要,并使用一个惟一的标记将二者分开。更确切地说,将训练语料中的每对article-summary对 ( x 1 , … , x m ) (x_1, …, x_m) (x1,…,xm), ( y 1 , … , y n ) (y_1, …, y_n) (y1,…,yn) 转换为单个训练实例 ( x 1 , … , x m , δ , y 1 , … , y n ) (x_1, …, x_m, \delta, y_1, …, y_n) (x1,…,xm,δ,y1,…,yn),总长度为 n + m + 1 n + m + 1 n+m+1。这些训练实例被视为长句子,然后使用教师强迫来训练一个自回归语言模型,就像我们前面所做的那样。
一旦训练,以特殊标记结尾的完整文章作为上下文,以启动生成过程,生成如下图所示的摘要。请注意,与RNN不同的是,模型在整个过程中可以访问原始文章以及新生成的文本。
正如我们将在后面章节中看到的,这种简单方案的变体是成功的文本对文本应用的基础,包括机器翻译、摘要和问题回答。

9.4.2 Transformer 模型结构总结 (Summary of Transformer Model Architecture)
前文已经对Transformer模型及其应用进行了深入浅出的介绍,下面是对整个Transformer模型的总结。
Transformer是一个encoder-decoder模型(虽然本书忽略这样的定义,但仍然值得注意),其以自注意力机制(self-attention)为基础,通过引入参数矩阵 W Q W^{Q} WQ、 W K W^{K} WK 和 W V W^{V} WV,并引入多头自注意力机制来构建模型。其中,在输入过程中,模型还引入了位置编码以弥补其本身不会学习到位置属性的劣势。Transformer由2017年的论文《Attention is All You Need》[1] 提出,原文给出了其Encoder-Decoder架构图,这里我们引用了博客[3]中的图示来解释:
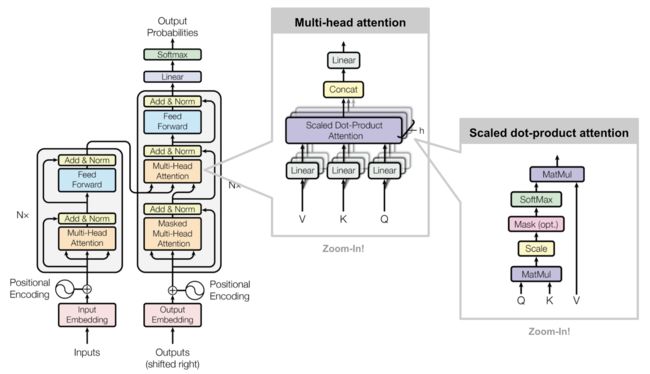
我们看到最右侧是一个自注意力头,其结构正如前文所述一致。中间的部分为多头自注意力的结构。左侧是原文中给出的Encoder Decoder机制结构。首先我们输入一个与位置编码相加的嵌入,然后经过多个“多头自注意力机制+全连接+标准化层+前馈神经网络+前连接+标准化”层,之后,进入解码器。我们注意到,前文在应用中所述的“模型在整个过程中可以访问原始文章以及新生成的文本”,正好体现在这个图中,因为解码器的输入,包括了我们之前的输出以及前文的所有文本(从encoder中来)。
下图是对Transformer的动态图总结,通过如下两个图,我们可以清晰地看到Encoder和Decoder两个过程。同样地,第一个图展示了Decoder部分如何获得并处理之前的文本;第二个图展示了Decoder部分如何获取并处理输出。[2]
图1:
图2:
Transformer在提出之后,出现了许多变体,其中包括Longer Attention Span,Adaptive Attention Span,Localized Attention Span (Image Transformer) 及 Sparse Attention Matrix Factorization (Sparse Transformers) ,Locality-Sensitive Hashing (Reformer),等。它们或多或少地对原始的Transformer进行了改进,如提高注意广度(前三个),其目标是使用于自我注意的语境更长、更有效和更灵活;和减少时间和内存的消耗(后两个)。[3]
译者注:本小节为译者自行添加,参考资料如下:
[1] https://arxiv.org/abs/1706.03762
[2] https://jalammar.github.io/illustrated-transformer/
[3] https://lilianweng.github.io/lil-log/2020/04/07/the-transformer-family.html
9.5 语言模型的潜在危害 (Potential Harms from Language Models)
大型神经语言模型展示了许多在第4章和第6章中讨论的潜在危害。当语言模型用于文本生成时,例如在辅助技术中,如web搜索查询补全或电子邮件的预测键入时,可能会出现问题。
举例来说,有些模型会生成有害语言或者歧视性的语言。语言模型也会生成误导信息,欺诈信息等,从而成为危害社会的活动的工具。同时,隐私泄露也是一个重要问题。
缓解这些危害成为一个在NLP领域中非常重要但尚未解决的一个问题。
9.6 总结
本章介绍了递归神经网络和Transformer的概念,以及如何将它们应用于语言问题。以下是我们总结的要点:
- 在简单的循环神经网络中,序列是作为一个元素自然处理的。
- 神经单元在特定时间点的输出基于当前输入和前一个时间步长的隐层值。
- RNN可以通过对backpropagation算法的直接扩展进行训练,该算法被称为backpropagation through time (BPTT)。
- 基于公共语言的RNNs应用程序包括:
- 概率语言建模,其中模型分配一个概率给一个序列,或一个序列的下一个元素给定前面的单词。
- 使用训练过的语言模型进行自回归生成。
- 序列标号,序列中的每个元素都有一个标号,就像词性标注一样。
- 序列分类,其中整个文本作为符号到一个类别,作为在垃圾邮件检测,情感分析或主题分类。
- 简单的循环网络经常会失败,因为要成功地训练它们,让它们在一段时间内保持有用的梯度是极其困难的。
- 更复杂的门控架构,如LSTMs和GRUs,被设计来克服这些问题,通过显式管理任务,决定在其隐藏和上下文层中记住和忘记什么。
- Transformer结构,通过自注意力机制的设计,从根本上解决了门控框架中仍然保存的远距离信息消失的问题。(本条为译者自行添加)