日常论文分享---持续更新中
日常充电是必须的,每天进步一点点,下面是从日常关注的博主啦公众号啦看过的一些论文,分享分享!!
https://github.com/km1994/nlp_paper_study
一些顶会AAAI、ICLR、CVPR、ACL、ICML、SIGIR、KDD、ECCV、EMNLP、NeurIPS以及IJCAI,都是学习,提高,淘金的宝藏
(1)预训练模型的
《Self-training Improves Pre-training for Natural Language Understanding》
原文:https://arxiv.org/pdf/2010.02194.pdf
更详细的解析:https://zhuanlan.zhihu.com/p/268770394?utm_source=wechat_session&utm_medium=social&s_r=0
以bert为代表的Pretrain预训练大放异彩,self-train自训练就多少有点黯然失色。
两者区别
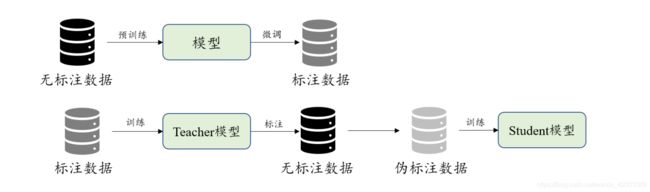
改论文将两则进行了结合,先用一个pre-train模型去在少量标签数据上面进行train得到teacher模型,然后再用其给大量无标注数据进行打标,得到大量伪标注数据,依次训练student模型,依次为最终上线模型。注意看其区别:
和传统自训练的区别是 :在训练teacher阶段是用了一些pretrain 模型(例如论文中用了roberta)热启的,即融合了pretrain思想
和bert代表的预训练模型区别是 :bert利用大量无标签数据在前,即先预训练后用小量标签数据,这里是用大量无标签数据在后,即先用小标签数据训练,然后对大量无标签打标,以此进行有监督训练student
论文提出的总体框架
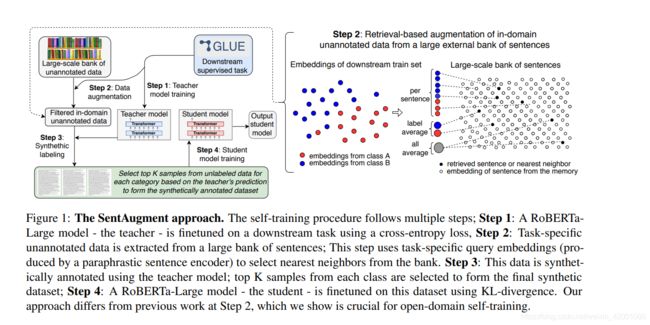
比较吸引一点的还有step2:其不是一股脑的用所有数据,而是抽取和当前领域比较相近的语料,方法就是通过句子编码得到任务编码做余弦相似度。
这里就挑一个实验结果来看看

基线是robera,icp是在step2抽取出来的大量领域内的数据集D上面进行预训练的方法,ST是本文的提出的方法
可以看到icp还不如原来的基线呢,说明没有伪标注数据,单纯的预训练不能很好地实现领域知识迁移,还要借助标注数据。
更多细节看论文吧
《Rethinking the Value of Labels for Improving Class-Imbalanced Learning》
详细解析:https://zhuanlan.zhihu.com/p/259710601?utm_source=wechat_session&utm_medium=social&utm_oi=52706551005184&s_r=0
利用“半监督”或“自监督学习”方式来处理长尾问题(类别不均衡),这里说的半监督和自监督方法并没有什么创新点,都是以前的方法,其主要贡献就是通过实验验证了一个结论:两种方式对处理类别不均衡有效果
半监督:先用监督数据训练一个base模型,然后用其对大量无标签数据打伪标签,用两部分数据重新训练
自监督:先用有标签数据自监督预训练自己的模型(不用标签),在进行有监督训练
两种方式都能提高效果,但是半监督有几个问题:
(1)未标签数据和标签数据要有相关性,否则会降低效果
(2)无标签数据不能过于不平衡
(2)实体关系抽取
《A Frustratingly Easy Approach for Joint Entity and Relation Extraction》
直接目前(2020.11.6)关系抽取sota结果。
论文:https://arxiv.org/pdf/2010.12812.pdf
中文解析:https://mp.weixin.qq.com/s?__biz=MzIwNzc2NTk0NQ==&mid=2247499300&idx=1&sn=060903294baa3f61133d7067a7cf06b0&chksm=970fd6f2a0785fe4fc5cc08d82ec144554e9699f594f57a26afc3b39b169ac48e4679b777139&mpshare=1&scene=1&srcid=1106ugi6Bju7RnRYi9cFCxp5&sharer_sharetime=1604630093212&sharer_shareid=76f523e1337dd36d603ad65850ce4435&key=450159c030237e0279d01c78a3e08ac02fa215d2cadf69c14ec8481c732c0aed0198fa97975c39c1166db5e4940935d1109df2e89f0182bbc60debd37559cc01f88f03b159b29a6c71eb237f233871998b335810ff4ba4a5b0831180398c15be391caba4631ca6c9df374129229d114f48091d6c6fdd909ef83ab5c0070b6719&ascene=1&uin=MjU3MjU4OTIxNw%3D%3D&devicetype=Windows+10+x64&version=6300002f&lang=zh_CN&exportkey=A6ggGOiCwqoP%2BeKLTI2ZXKo%3D&pass_ticket=GW4Ofk9S71XhAQMFSQ3rxG3vHK0FCVkcBjegwgFjF6NDewrdzfACZgZXBf9jXc%2Bc&wx_header=0
主要就是再次显示了pipeline的强大。先实体抽取再关系抽取。
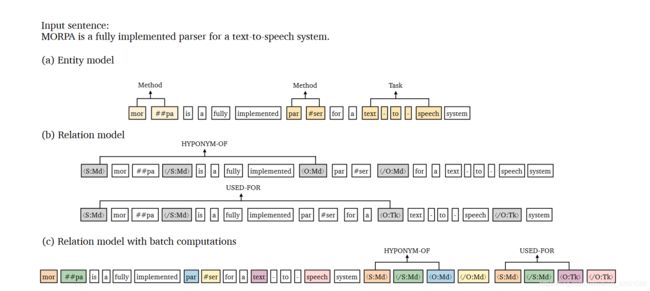
实体抽取:基于的是span思想,预测所有span结果 其参考论文:https://arxiv.org/pdf/1707.07045.pdf,该论文中文解析:https://blog.csdn.net/weixin_44912159/article/details/106276874
关系抽取:这里比较新颖,主要就是在实体左右加上其实体类型标志,预测关系的时候是用实体pair的左面标志(实体开始标志)进行concatenate,然后softmax
,因为其每两两实体对预测关系,所以时间复杂度很大,为此提出了上图中c方案,文本过一次网络就可以啦。
《TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking》
论文:https://arxiv.org/abs/2010.13415
github:https://github.com/131250208/TPlinker-joint-extraction
中文解析:https://mp.weixin.qq.com/s?__biz=MzIwNzc2NTk0NQ==&mid=2247499731&idx=1&sn=9ee1913f53db0754d4b36591644b95d5&chksm=970fd705a0785e13198cd5b5ec58762edebdc33ca3fb16d6ceb8ece6573056ce8ef44a38b130&mpshare=1&scene=1&srcid=1110DxjfKSwscI0W6E2c3dwT&sharer_sharetime=1605006741471&sharer_shareid=76f523e1337dd36d603ad65850ce4435&key=cb189423faa3ef60cbb31e0278c7c54b22f6a44e6772c66d777f9fafe47ddba42f5126a8e8b6e05d3a8520afbb4d276fdac2eaf1683ff43977329fa5c6552f0501856a36bc60a977860f7d4f7e1d02a3cfe7ab9232019a82f930bdfeaeaf72cc66a3ed43f6c0238c88e0253931ce453aefb849fe8b911c4b7781e874d9774584&ascene=1&uin=MjU3MjU4OTIxNw%3D%3D&devicetype=Windows+10+x64&version=6300002f&lang=zh_CN&exportkey=A%2BauI8OI1i8XkylEozMeFxA%3D&pass_ticket=Oyrl9FgSkqwTCOl%2BPHQuZk6im48ndtmA%2FmjN9YiZa07zqqxDciIKX3%2FoBGCi4%2Fj%2B&wx_header=0
实体关系联合抽取,在联合抽取的过程中主要会设计到关系重叠的问题,当然即使pipeline的方式,也会存在实体标注重叠的问题,本篇论文使用矩阵巧妙的进行了标注,而且是联合抽取
(4)CTR模型
阿里CTR三部曲:
《Deep Interest Network for Click-Through Rate Prediction》
《Deep Interest Evolution Network for Click-Through Rate Prediction》
论文:https://arxiv.org/pdf/1809.03672.pdf
github:https://github.com/mouna99/dien/tree/1f314d16aa1700ee02777e6163fb8ca94e3d2810
关于该部分笔者也对其代码进行了部分解读,感兴趣的可以看:
https://blog.csdn.net/weixin_42001089/article/details/109592630

加了两个GRU网络
一个是兴趣提取层(其中加了辅助的losss),一个是兴趣变化层(其中兴趣变化层中融合attention)
《Deep Session Interest Network for Click-Through Rate Prediction》
改组最新成果:
https://zhuanlan.zhihu.com/p/287898562?utm_source=wechat_session&utm_medium=social&s_r=0
下面这篇是京东的CTR模型(2020.11.7 效果好)
《Kalman Filtering Attention for User Behavior Modeling in CTR Prediction》
论文:https://arxiv.org/pdf/2010.00985.pdf
讲解:https://mp.weixin.qq.com/s?__biz=MzUyMDAxMjQ3Ng==&mid=2247494453&idx=1&sn=4262f153ed0c755c1526a8a6944f3e39&chksm=f9f27ce6ce85f5f023dfac5464fb7896f84b25c904d1e9762fc9fbc722b27b10f245167d66df&mpshare=1&scene=1&srcid=1107PkE9SPAL5se8LxRoBT02&sharer_sharetime=1604724518537&sharer_shareid=76f523e1337dd36d603ad65850ce4435&key=60bedb899ff8b38e002e6cf43d6ce5375886d535b031c13ae700c48e67daea2553c5c9937c29affe99c56c81f0250a1e3ead505eee0a6fbf398ba518c0900f402f8fb8f7fb8965c83edf7595574ae94d4d4197df143714eff74e4b2a22e20dabd1060f16888d25dd63077d6e39bf08506bf46580131b90f14a5e5f3fbd3a66cd&ascene=1&uin=MjU3MjU4OTIxNw%3D%3D&devicetype=Windows+10+x64&version=6300002f&lang=zh_CN&exportkey=A5EGT8a2HEiPQ2ZtCR0fjsQ%3D&pass_ticket=NDkx%2Fxf4t1ECN4s8A2i7ruk0jePFjHptfzEB6c30IR9PcLkw%2FuJPyAoy4nCJEU5B&wx_header=0
该模型主要就是用高斯分布对过去行为序列建模,就是对上面图片的user behavior sequence建模求解出兴趣偏好
我猜开始的灵感来源就是要对这部分通过数学的一些分布进行建模,最长想到的就是高斯分布,然后用后验概率可以求解。
那么历史的观察序列可以作为后验概率的观察样本
(5) 图谱推荐
(1)https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247512107&idx=2&sn=ce7ce209d594b0574518e5b62a60998a&chksm=fbd70247cca08b5190e1b06ed87f036fc71c17bdda40fb80cbe69420ac7fe22f4eda2c554398&mpshare=1&scene=1&srcid=1117tkg9ZjNnOzP6FQpafqyo&sharer_sharetime=1605544486501&sharer_shareid=76f523e1337dd36d603ad65850ce4435&key=450159c030237e0225a1d09082ea11198c4c2b5abf9702d27096a2ce5fdfd9040703ea4b1c99d2504423378ce8697c16541a0126b4742be37cd792bfde1d071e6623f3939cb5acdd86badaf0b7686d5bac8140ffc38c85b4cb38b00ee8508a500de84593fae27377c64b6e0448a612213a93685f3741932abff9dae13e6dc190&ascene=1&uin=MjU3MjU4OTIxNw%3D%3D&devicetype=Windows+10+x64&version=6300002f&lang=zh_CN&exportkey=A7xKDIcg%2FqOG8DjQRQ%2Bh%2FvA%3D&pass_ticket=nl86ocOIQkW%2FMkph0lCCXtA3VWdqS2Rvcr4oS4hmoWmyLE9kEiD4pTrRtVgAttk%2B&wx_header=0
(2)https://hub.baai.ac.cn/view/3931
(6)推荐
6.1 网易云
https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247512229&idx=1&sn=fe8430b49e6d5fd73e0f9c5cd9d0aaf6&chksm=fbd702c9cca08bdf665cb5628d380e25073dd18366372ff75243f0d9491760f6030a10aebc01&mpshare=1&scene=1&srcid=11209oh00qS2lbtDThj5p50e&sharer_sharetime=1605923934399&sharer_shareid=76f523e1337dd36d603ad65850ce4435&key=3b5b97cf930d123bd57167311d08507bbad8eecda431b5ead1e170470af82f7757d01490261fe1fe93eff26e71656bfbab58af1ac9605655a526a2d9d2a02f302e1079775ea1b246253f86b6747071194bca479d5aef61bc2333ea6b14edabca491ef6553b9aa67c15fe68d10fe2a55129a133d2bf7cc1383544c56cf92755ab&ascene=1&uin=MjU3MjU4OTIxNw%3D%3D&devicetype=Windows+10+x64&version=6300002f&lang=zh_CN&exportkey=A%2BF%2Fsetg291tQxdWItRP0%2FI%3D&pass_ticket=TK1HfxQpbmeF68wPLP82CpVtrZtbi4J48XaXPejaG2kohz90rsk08YUWfo%2BDt7wz&wx_header=0
6.2阿里文娱深度语义搜索
https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247512107&idx=2&sn=ce7ce209d594b0574518e5b62a60998a&chksm=fbd70247cca08b5190e1b06ed87f036fc71c17bdda40fb80cbe69420ac7fe22f4eda2c554398&mpshare=1&scene=1&srcid=1117tkg9ZjNnOzP6FQpafqyo&sharer_sharetime=1605544486501&sharer_shareid=76f523e1337dd36d603ad65850ce4435&key=450159c030237e026f039a5c78783c284adae71125c9d3b548af02f6f1528db7cb662b99eec174798b45f0e7fb38d72171c9376e9b3e324db00e415fbcadc5372b41eeb37fb221ea92ce31378d9d3e089211ad4a7f8c8026e86bf4aba1ef33133ca257e76d082bbfe94614a8efcc03a761a2680dd69ec1e19c29563aed5a8446&ascene=1&uin=MjU3MjU4OTIxNw%3D%3D&devicetype=Windows+10+x64&version=6300002f&lang=zh_CN&exportkey=A9uYlRRjCn8qkWKxbXsrvhk%3D&pass_ticket=TK1HfxQpbmeF68wPLP82CpVtrZtbi4J48XaXPejaG2kohz90rsk08YUWfo%2BDt7wz&wx_header=0
(6) 多模态模型
https://mp.weixin.qq.com/s?__biz=MzIwNzc2NTk0NQ==&mid=2247500919&idx=1&sn=a36f85d0c987a149345653f5298c19dc&chksm=970feca1a07865b7ab93dfff113867be2df42eac08340e8b0f01fd71e96475d380730ce37990&mpshare=1&scene=1&srcid=1125AqWZHY6OCkYqVodyMKKa&sharer_sharetime=1606272316451&sharer_shareid=76f523e1337dd36d603ad65850ce4435&key=9795b827bf42bc830a17c6991995ef2e2533bf3eb090f126bad6929e8d792a2fcc5674fc64bb9fdf55b7622b0d2acbcce1b2b322c3d0badf88d455ff75955f362406e66e38920b3421ab1c259f272c0db6ba042ee873cf43ed4cd3f1247b90ac53d7fe84e564586eefed7bc1b54bd154c0a09b5143f3b59e3aa4016414cdd800&ascene=1&uin=MjU3MjU4OTIxNw%3D%3D&devicetype=Windows+10+x64&version=6300002f&lang=zh_CN&exportkey=A2%2BIJXfjWx7UJPdOu4BTR9c%3D&pass_ticket=bVNhn%2Bw8SlWAmEHgpWKjDO%2B1tjaspzO08M3hHz7MXahT5zmSXNXyDY1gy%2FD4Ikpr&wx_header=0
(7)开放知识发现阅读清单
https://github.com/thuiar/OKD-Reading-List
(8)元学习的理解
https://mp.weixin.qq.com/s/fN2diN5vFEr8GC-cmmRIwg
https://mp.weixin.qq.com/s/YmzcSi4MIZnmEe6LaFeg1Q
(9)不使用一张图片,训练一个视觉预训练模型
https://mp.weixin.qq.com/s/wjkDwq9gg85ShRmTHG5WXA