图神经网络与属性级文本分类——Syntax-Aware Aspect Level Sentiment Classification with Graph Attention Networks论文解读
1、摘要
属性层次的情感分类任务:在给定上下文句子的情况下,识别某属性表达的情感。
以前的基于神经网络的方法很大程度上忽略了句子的语法结构。
本文提出了一种新的面向属性层次情感分类任务的目标依赖图注意网络(Target-Dependent Graph Attention Network,TD-GAT),这种网络可以利用单词之间的依赖关系(本篇解读都将其简称为依赖图)。使用上述依赖图,可以使上下文中对某一属性的情感特征通过语法结构传播。实验结果表明提出的方法优于Glove嵌入的多个基线方法。除此之外,还展示了使用BERT后,性能进一步大大提高。
2、介绍
属性层次情感分类的目的是:在上下文中,识别属性或其所指向目标对象的情感极性(正面、负面、中性)。与句子级情感分类相比,这是一项更精细的任务。属性层次情感分类可以区分句子中多个属性相异的情感极性,而句子级的情感分类在这些情况下往往是失效的。例如,在一个句子“食物很棒,但服务很糟糕”中,“食物”和“服务”的情感极性分别是积极的和消极的。然而,在这种情况下,由于句子同时拥有积极和消极的表达,很难确定整个句子的整体情绪。
通常,研究人员使用机器学习算法来分类句子中给定属性的情感。早期的研究工作都是手工设计的特征提取方法。后来,各种基于神经网络的方法在这项任务中流行起来,因为他们不需要手动设计特征工程,大多数都是基于LSTM的神经网络,很少使用卷积神经网络。
这些基于神经网络的方法大多将句子视为单词序列,并通过多种方法将属性信息嵌入到句子表示中。这些方法在很大程度上忽略了句子的句法结构,这有助于识别与属性目标直接相关的情感特征。但是当属性词被从情感短语中分离出来时,就很难在单词序列中找到相关的情感词。例如,在一个句子“The food, though served with bad service, is actually great”中,单词“great”在依赖图中比在单纯的单词序列中更接近“food”这个属性。
使用依赖关系也有助于消除单词序列中可能存在的歧义。在一个简单的句子中,“好的食物,糟糕的服务”,“好的”和“坏的”可以互换使用。但是,一个有良好语法知识的读者可以很容易地发现“好的”是“食物”的形容词修饰语,而“坏的”是“服务”的修饰语。
3、提出方法
本文提出了一种新的神经网络框架——目标依赖图注意网络(TD-GAT),它能在属性级情感分类任务中很好地利用句子的语法结构。此方法将句子表示为依赖图,而非单词序列。在依赖图中,属性目标和相关属性词直接相连。作者采用多层图注意网络,将情感特征从重要的语法相邻词传播到属性目标。作者还进一步在TD-GAT中加入了一个LSTM单元,以便在递归邻域扩展过程中明确地捕获跨层次的属性相关信息。
3.1 文本表示
句子 s = [ w 1 , w 2 , ⋯ w i , ⋯ , w n ] s=[w_1,w_2,\cdots w_i,\cdots ,w_n] s=[w1,w2,⋯wi,⋯,wn]长度为 n n n,属性目标为 w i w_i wi
首先需将 w i w_i wi嵌入到维度为 d d d的低维词向量空间 R d R^d Rd中,每个 w i w_i wi对应于 x i ∈ R d x_i\in R^d xi∈Rd
使用论文中的A fast and accurate dependency parser using neural networks一般性依存关系语法分析方法来将句子转换为依赖图。每一个结点都代表了一个词,并且拥有一个词嵌入向量(这个局部相关的词嵌入向量可能来自预训练模型)作为其局部特征向量。一条无向边代表着相连两词在语法上的相关性。下图是句子“delivery was early too”的依赖图,属性目标“delivery”的属性特征(“early”)从距离其2跳的位置传播到距离其1跳的位置,又传给它自己。
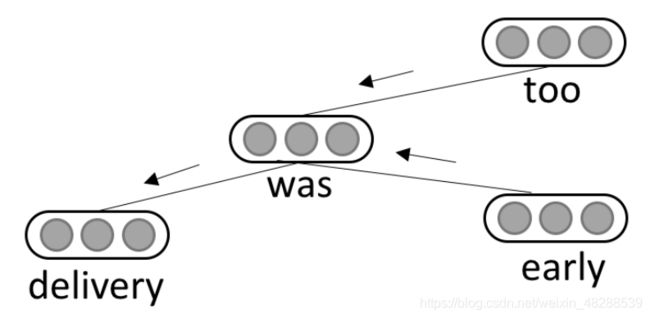
对于具有多个单词的属性目标,首先用特殊符号“__target__”替换整个目标单词序列,然后将整个句子传递到依赖解析器中。因此,依赖图中存在表示目标的元结点,其局部特征向量为组成目标短语的词的嵌入向量的平均值。
3.2 图注意网络
Graph Attention Network(GAT)
图注意网络是GNN的一个变体,也是本文方法的一个关键点。它将某属性的上下文特征传递给属性本身。给定 N N N个结点的依赖图,每个结点都对应一个局部相关的词嵌入向量,每一个GAT层都会通过集成周围邻居结点的隐状态向量来重新计算每个结点的表示向量。对于一个 L L L层的GAT网络, L L L跳的特征会被传递给属性目标结点。对于一个结点 i i i,给定第 l l l层中它的隐状态 h l i h_l^i hli及其邻居结点 n [ i ] n[i] n[i]的隐状态,如何计算第 l + 1 l+1 l+1层它的隐状态呢?使用多头注意力计算。
计算公式如下:
h l + 1 i = ∣ ∣ k = 1 K σ ( ∑ j ∈ n [ i ] α l k i j W l k h l j ) α l k i j = e f ( a l k T [ W l k h l i ∣ ∣ W l k h l j ] ) ∑ u ∈ n [ i ] e f ( a l k T [ W l k h l i ∣ ∣ W l k h l u ] h_{l+1}^i=||_{k=1}^K\sigma (\sum_{j\in n[i]}\alpha_{lk}^{ij}W_{lk}h_l^j)\\ \alpha_{lk}^{ij}=\frac{e^{f(a_{lk}^T[W_{lk}h_l^i||W_{lk}h_l^j])}}{\sum_{u\in n[i]}e^{f(a_{lk}^T[W_{lk}h_l^i||W_{lk}h_l^u]}} hl+1i=∣∣k=1Kσ(j∈n[i]∑αlkijWlkhlj)αlkij=∑u∈n[i]ef(alkT[Wlkhli∣∣Wlkhlu]ef(alkT[Wlkhli∣∣Wlkhlj])
其中,运算 ∣ ∣ || ∣∣表示将向量拼接在一起, α l k i j \alpha_{lk}^{ij} αlkij表示在第 l l l层,从结点 i i i到其邻居结点 j j j在注意头 k k k的注意权重。 W l k ∈ R D K × D W_{lk}\in R^{\frac{D}{K}\times D} Wlk∈RKD×D是一个作用于输入状态的线性变换矩阵, D D D是隐状态向量维度。 σ \sigma σ是sigmoid函数, f ( ⋅ ) f(\cdot) f(⋅)是LeakyReLU非线性函数, a l k ∈ R 2 D K a_{lk}\in R^{\frac{2D}{K}} alk∈RK2D是训练要学习的注意上下文向量。
简单起见,可以将上述这样的特征传递过程写成:
H l + 1 = G A T ( H l , A ; Θ l ) H_{l+1}=GAT(H_l,A;\Theta_l) Hl+1=GAT(Hl,A;Θl)
其中, H l ∈ R N × D H_l\in R^{N\times D} Hl∈RN×D是第 l l l层所有结点隐状态堆积而成的矩阵, A ∈ R N × N A\in R^{N\times N} A∈RN×N是图邻接矩阵, Θ l \Theta_l Θl是GAT第 l l l层的参数集合。
3.3 目标依赖图注意网络
为了更加精确地在这种GAT网络中使用目标地信息,作者进一步使用LSTM来建模属性的目标跨层依赖关系,这将有利于客服噪音的干扰(根据论文Residual or Gate? Towards Deeper Graph Neural Networks for Inductive Graph Representation Learning)。
主要思想是:在第 0 0 0层,属性目标结点的隐状态 h 0 t h_0^t h0t只依赖于它的局部特征,在后面的每一层 l l l中,它的信息由 l l l跳邻居的信息通过LSTM单元加和得到。已知结点 t t t的前一层隐状态 h l − 1 t h_{l-1}^t hl−1t和细胞状态 c l − 1 t c_{l-1}^t cl−1t,便可以首先使用3.2中的多头注意计算得到一个临时的隐状态 h ^ l t \hat{h}_l^t h^lt,然后将之输入LSTM单元中,计算:
i l = σ ( W i ) h ^ l t + U i h l − 1 + b i f l = σ ( W f ) h ^ l t + U f h l − 1 + b f o l = σ ( W o ) h ^ l t + U o h l − 1 + b o c ^ l = t a n h ( W c h ^ l t + U c h l − 1 + b c ) c l = f l ∘ c l − 1 + i l ∘ c ^ l h l = o l ∘ t a n h ( c l ) i_l=\sigma(W_i)\hat{h}_l^t+U_ih_{l-1}+b_i\\ f_l=\sigma(W_f)\hat{h}_l^t+U_fh_{l-1}+b_f\\ o_l=\sigma(W_o)\hat{h}_l^t+U_oh_{l-1}+b_o\\ \hat{c}_l=tanh(W_c\hat{h}_l^t+U_ch_{l-1}+b_c)\\ c_l=f_l\circ c_{l-1}+i_l\circ\hat{c}_l\\ h_l=o_l\circ tanh(c_l) il=σ(Wi)h^lt+Uihl−1+bifl=σ(Wf)h^lt+Ufhl−1+bfol=σ(Wo)h^lt+Uohl−1+boc^l=tanh(Wch^lt+Uchl−1+bc)cl=fl∘cl−1+il∘c^lhl=ol∘tanh(cl)
其中, W , U W,U W,U是参数矩阵, b b b是偏置向量,它们都是训练学习的对象。 ∘ \circ ∘表示向量对应元素相乘。 i , f , o i,f,o i,f,o是输入门、遗忘门、输出门,控制着数据流。总结来说,整个目标依赖图神经网络的前馈过程可写成:
H l + 1 , C l + 1 = L S T M ( G A T ( H l , A ; Θ l ) , ( H l , C l ) ) H 0 , C 0 = L S T M ( X W p + [ b p ] N , ( 0 , 0 ) ) H_{l+1},C_{l+1}=LSTM(GAT(H_l,A;\Theta_l),(H_l,C_l))\\ H_0,C_0=LSTM(XW_p+[b_p]_N,(0,0)) Hl+1,Cl+1=LSTM(GAT(Hl,A;Θl),(Hl,Cl))H0,C0=LSTM(XWp+[bp]N,(0,0))
其中, C l C_l Cl是第 l l l层LSTM堆叠的细胞状态,初始隐状态和细胞状态设置为0。 X X X是堆叠的词嵌入向量,影射矩阵 W p ∈ R d × D W_p\in R^{d\times D} Wp∈Rd×D将其转换为与隐状态维度一致的向量。 [ b p ] N [b_p]_N [bp]N是偏置向量 b p b_p bp堆叠 N N N次的结果,得到 R N × D R^{N\times D} RN×D的矩阵。其实LSTM也可换成GRU。
3.4 分类
通过 L L L层的TD-GAT网络,可以得到属性目标结点的最终向量表示 h L t h_L^t hLt。使用线性变换将隐状态 h L t h_L^t hLt映射到分类空间,即可得到分类结果,使用softmax计算:
P ( y = c ) = e ( W h L t + b ) c ∑ i ∈ C e ( W h L t + b ) i P(y=c)=\frac{e^{(Wh_L^t+b)_c}}{\sum_{i\in C}e^{(Wh_L^t+b)_i}} P(y=c)=∑i∈Ce(WhLt+b)ie(WhLt+b)c
其中的 W , b W,b W,b分别为线性变换的权重矩阵和偏置, C C C是情感分类集。训练使用 L 2 L_2 L2正则化的交叉熵损失进行:
l o s s = − ∑ c ∈ C I ( y = c ) ⋅ l o g ( P ( y = c ) ) + λ ∣ ∣ Θ ∣ ∣ 2 loss=-\sum_{c\in C}I(y=c)\cdot log(P(y=c))+\lambda ||\Theta||^2 loss=−c∈C∑I(y=c)⋅log(P(y=c))+λ∣∣Θ∣∣2
其中 I ( ⋅ ) I(\cdot) I(⋅)是一个指示函数, λ \lambda λ是 L 2 L_2 L2正则化参数, Θ \Theta Θ是模型的所有参数集合。
4、实验
4.1 数据集
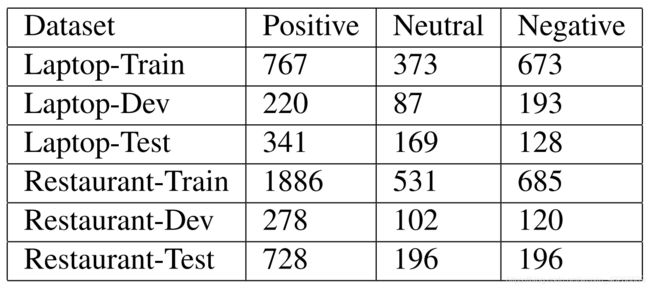
使用SemEval 2014 Task 4中的两个特定域数据集:手提电脑评价集、饭店评价集。每一个数据点都是一个句子和一个属性对象组成的数据对,每一对都被标注了情感极性。作者使用500个训练数据作为验证集,使用训练集和验证集训练模型后,得到如下表结果。
4.2 实验细节
作者使用斯坦福依存关系语法分析神经网络来得到依存关系图。使用两种方法得到初始局部词嵌入向量,一个是300维的GloVe,一个是1024维的BERT。BERT的输入为以下形式的文本对:"[CLS]"+句子+"[SEP]"+属性+"[SEP]“由于BERT和依存关系分析器所用的分词方法不同,当根据依赖图得到词嵌入表示的时候,会将子词的表示进行平均,赋予新表示值。例如,词"overload"的表示就是通过将"over"和”##load"的表示求和平均得到的,这一修正过程是在训练中进行的。整个实验中的向量表示都是300维,BERT的结果会被线性变换到300维。实验用的多头注意包含6个头,batch size是32, L 2 L_2 L2正则化的参数 λ = 1 0 − 4 \lambda=10^{-4} λ=10−4,dropout率为0.7
首先使用Adam优化器进行训练,然后使用随机梯度下降法微调,学习率为 1 0 − 3 10^{-3} 10−3,在Linux上使用Titan XP GPU和Pytorch进行训练
4.3 基线方法比较
1、基于特征的SVM
是一个属性级别的文本分类任务,使用了n元(n-gram)特征、依存关系分析(Parser)特征、词汇(Lexicon)特征
2、TD-LSTM:
一个与作者的方法直接比较的基线方法,它使用两个LSTM网络分别计算属性上文和下文的影响。这两个LSTM网络的最终隐状态连接在一起作为属性的上下文嵌入表示向量,可用来预测情感极性。
3、AT-LSTM
首先使用一个LSTM建模得到中间句子表示,然后将其隐状态向量与属性嵌入表示结合起来,以得到注意向量,最终的句子表示是隐状态的权重均值。
4、MemNet
在词嵌入上多次使用注意力机制,最后一次的输出输入softmax函数得到分类结果
5、IAN
使用两个LSTM网络分别对句子和属性词进行建模。它使用句子的隐藏状态生成属性目标的注意向量,反过来使用属性词的隐状态生成句子的注意向量。基于这两个注意向量,输出一个句子表示和一个属性目标的分类结果
6、PG-CNN
一种基于CNN的模型,属性特征被用作控制句子的特征提取的门限
7、AOA-LSTM
使用一个基于注意-over-注意(AOA)的网络,以联合的方式对属性和句子进行建模,明确地捕获属性和语境之间的交互作用
8、BERT-AVG
使用句子表示的平均值来训练线性分类器
9、BERT-CLS
是一种直接使用“[CLS]”作为分类特征的模型,对BERT模型进行微调,用于成对句子的分类。使用批量大小8和学习率 1 0 − 5 10^{-5} 10−5的Adam优化器为5个epoch进行微调
下图为比较结果
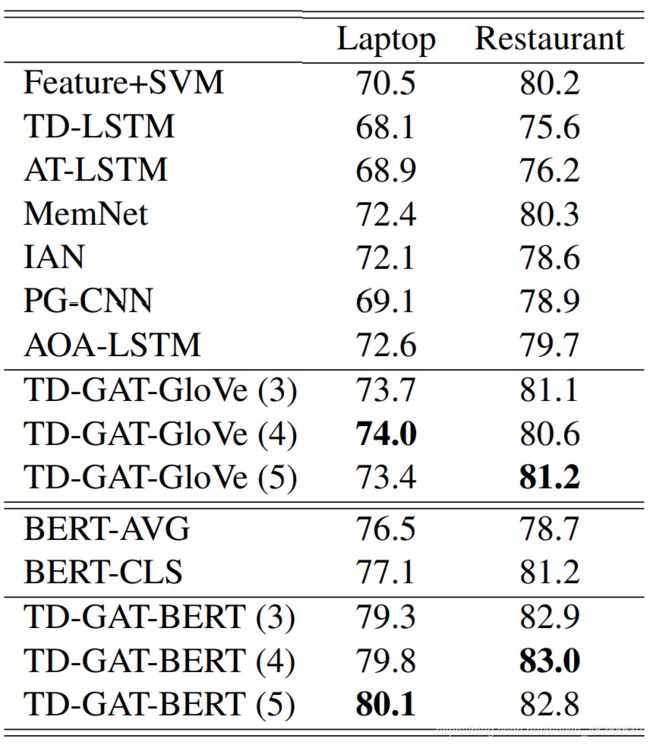
对于GloVe嵌入,作者的方法TD-GAT-GloVe (k)的性能优于所有这些以前的方法,k是模型层数。基于特征的SVM在该任务中取得了较好的表现,说明了特征工程和语法知识的重要性。
作为一个直接的比较对象,TD-LSTM将情感特征从句子的开头和结尾传播到属性目标,而作者的模型将特征从句法依赖词传播到依赖图上的属性目标。与TD-LSTM相比表现出了更好的性能,这直接证明了融合语法信息的必要性。
使用BERT表示进一步提高了模型的性能。BERT-avg使用BERT表示而不进行微调,在这项任务上取得了惊人的优异表现。经过微调,BERT-CLS的性能变得更好。
然而,作者观察到这种微调是相当不稳定的,在某些试验中不能收敛。尽管原始的BERT模型已经提供了强大的预测能力,但作者的模型在BERT-avg和BERT-CLS的基础上不断改进,这表明作者的模型可以更好地利用这些语义表示,在笔记本电脑和餐厅评价数据集上的准确率分别达到80%和83%。
4.4 属性目标所带信息的影响
作者进行了ablation研究,以明确属性目标信息为建模带来的影响。在ablation模型中,去掉了TD-GAT模型中的LSTM单元,这样它就不能显式地利用属性目标信息,将这种烧蚀模型称为GAT。
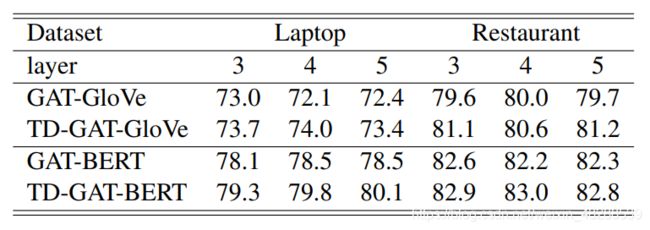
如下表所示,明确地捕获属性目标信息可以持续地提高TD-GAT-Glo Ve的性能。TD-GAT-Glo Ve的准确率平均提高了1.2个百分点。跨层显式地捕获与属性相关的信息对于基于BERT的应用程序也很有用。虽然BERT内部生成了属性目标的嵌入表示,TD-GAT-BERT还是比GAT-BERT更优。平均而言,明确的目标信息对TD-GAT-BERT的最终性能贡献0.95个百分点。
4.5 模型深度
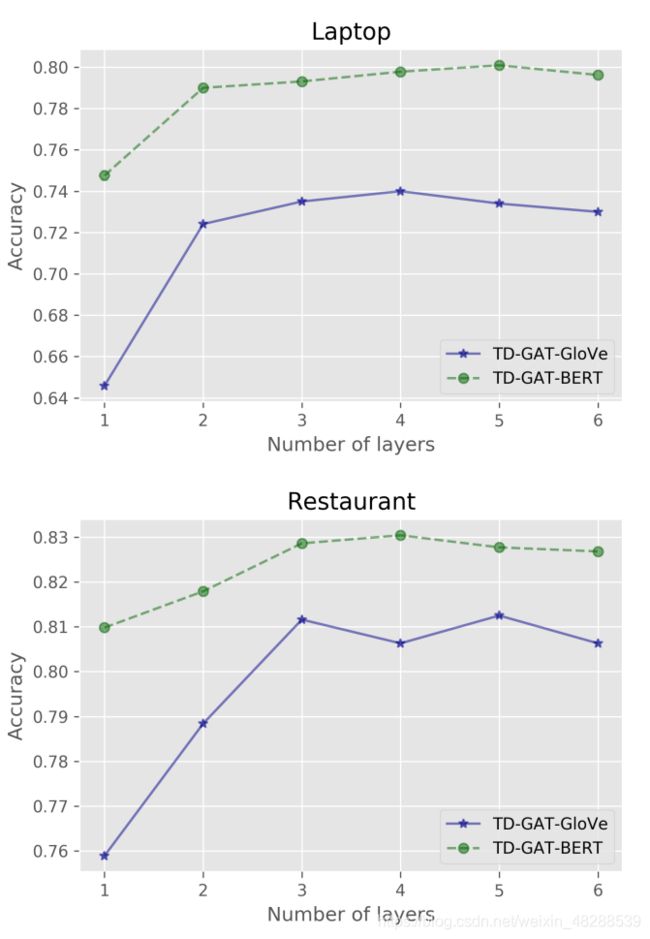
对于提出的TD-GAT-BERT模型,其模型深度从1到6变化。如上图所示,一个单层TD-GAT-GloVe嵌入的模型不能很好地工作,这意味着与目标相关的情感词通常离目标有2跳距离。将模型深度增加到3将大大提高TD-GAT-GloVe模型的性能。
与TD-GAT-GloVe模型不同,TD-GAT-BERT对模型的深度更加鲁棒,即使是单层的TD-GAT-BERT模型也能在两个数据集上获得满意的结果。一个可能的原因是BERT表示已经将上下文词合并到这些语义表示中。因此,单跳的节点可能包含一些全局信息。但增加模型深度仍能提高这种情况下的性能,当模型深度大于3时,模型达到最佳性能。
4.6 模型的大小
作者对TD-GAT模型与各种基准方法以及BERT模型的规模大小进行了比较。对于这些基线方法,我们使用一个开源的PyTorch实现来计算它们的模型大小。

所有模型的尺寸见上表,与这些基于LSTM的方法相比,提出的TD-GAT-GloVe使用相同维度的隐状态,具有更低的模型尺寸。MemNet是模型尺寸排名第一的模型。由于在输入词表示上应用了线性投影层,TD-GAT-BERT的大小增加了 0.3 × 1 0 6 0.3 × 10^6 0.3×106个。当用BERT代替Glo Ve嵌入表示时,餐厅数据集上的三层TD-GAT模型的训练时间仅从 1.12 s / e p o c h 1.12 s/epoch 1.12s/epoch增加到了 1.15 s / e p o c h 1.15 s/epoch 1.15s/epoch
相反,对BERT模型进行微调在每个epoch大约需要226.50秒。与对原始BERT模型进行微调相比,训练TD-GAT-BERT模型需要更少的计算资源和更少的时间。
5、结论
本文提出了一种新的面向属性层次情感分类的目标依赖图注意力神经网络。它利用句子的句法依赖结构,并使用属性目标的句法上下文进行分类。与以往的方法相比,提出的方法使属性词更接近属性目标,并能解决潜在的歧义问题。在实验中,作者在SemEval 2014的笔记本电脑和餐馆评价数据集上演示了提出方法的有效性。使用GloVe嵌入,提出的方法TD-GAT-Glo Ve优于各种基线模型。在切换到BERT表示后,TD-GAT-BERT获得了更好的性能。它是轻量级的,与微调原始BERT模型相比,需要更少的计算资源和更少的训练时间。
据作者所知,本文是第一次尝试直接使用原始依赖图而不转换其结构进行属性级情感分类。在这个方向上可以作出许多潜在的改进。在本研究中,属性的局部特征向量是属性中单词的嵌入向量的均值,这些单词都是同等重要的。今后的工作可考虑使用注意力机制,集中注意在某些重要的词。由于这项工作只使用依赖关系图,忽略了图中的各种类型的关系,作者计划将依赖关系类型合并到现有TD-GAT模型中,并且在将来也会考虑词性标注。同时也想结合这样基于图的模型和基于序列的模型,以避免依赖分析的潜在噪音错误。