电子产品销售数据分析及RFM用户价值分析
目录
项目背景
实战案例
1 读取数据
1.1 字段解析
1.2 数据基础信息查看
1.3 数据存储最小格式
2 数据清洗
2.1 查看缺失值比例
2.2 查看重复值比例
合成新列:buy_count
合成新列:购买总金额(GMV)
2.3 检测异常值
2.3.1 转化id数据格式
2.3.2 检查price,age是否有异常值
2.3.3 其他字段是否有异常值
3 数据探索性分析(EDA)
3.1 总览
3.1.1 总成交金额GMV
3.1.2 月成交金额GMV
月度GMV可视化
3.1.3 客单价
3.2 用户分析
3.2.1 用户区域特征
3.2.2 用户性别特征
3.2.3 用户年龄特征
3.2.4 用户消费特征
4 RFM模型
4.1 M:消费金额
4.2 F:消费频率
4.3 R:最近一次消费
4.4 RFM打分体系
4.5 用户打标
4.6 RFM用户价值模型可视化
案例全代码
参考文章
项目背景
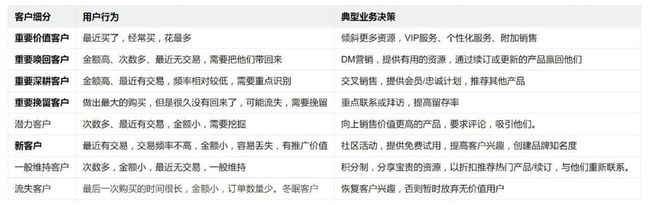
RFM是一种经典的业务分析模型。通过对客户购买行为的3个维度R(最近购买),F(购买频次),M(购买)金额进行打分,进而对客户价值类型进行分类。经典的RFM模型将客户分为8类。不同类型的客户对企业的贡献是截然不同的,针对不同价值的客户企业需要制定不同的营销对策。
- 近度(Recency,最近一次消费到当前的时间间隔)
- 频度(Frequency,最近一段时间内的消费次数)
- 额度(Monetory,最近一段时间内的消费金额总额/均额)
实战案例
电子产品销售数据分析及RFM用户价值分析
内容是分析消费类电子产品(主要指不同品牌手机及配件)在某电商平台的销售数据。
全代码notebook文件及原始数据文件附于文末。
1 读取数据
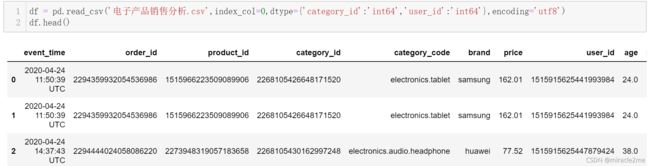
1.1 字段解析
- Unnamed: 行号
- event_time:下单时间
- order_id:订单编号
- product_id:产品标号
- category_id :类别编号
- category_code :类别
- brand :品牌
- price :价格
- user_id :用户编号
- age :年龄
- sex :性别
- local:省份
1.2 数据基础信息查看
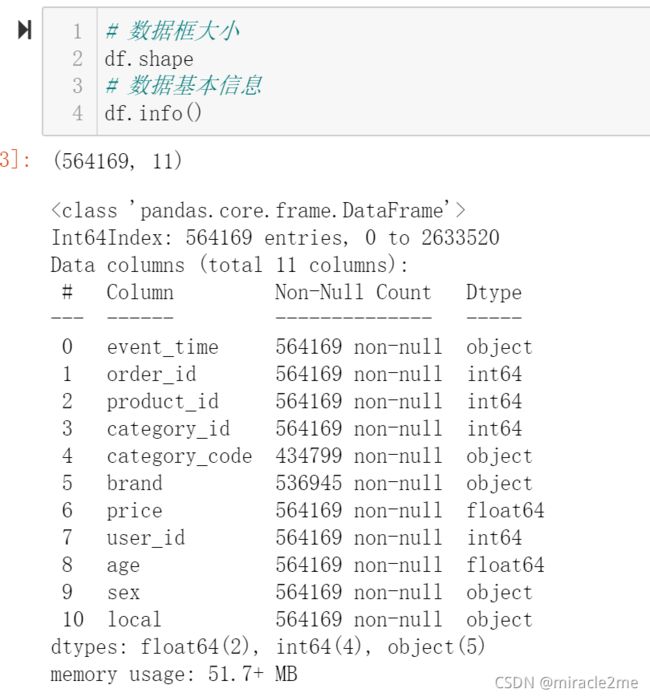
1.3 数据存储最小格式
看上一步最后,数据大小50+MB,读取还是需要5-10秒的,这里介绍一段缩减数据类存储空间的代码。
# reduce memory
def reduce_mem_usage(df, verbose=True):
start_mem = df.memory_usage().sum() / 1024**2
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df本案例执行后代码可缩减12.5%

2 数据清洗
清晰必做的3个工作,处理缺失值、重复值、异常值
2.1 查看缺失值比例
df.isnull().mean()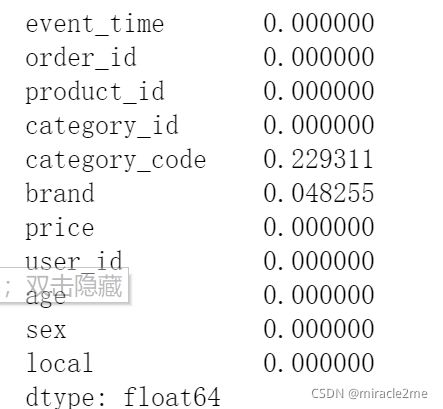
缺失率23%的字段:category_code,保留,固定值填充
# category_code本身为字符型,且缺失率在23% ,不宜直接删除,考虑用字符‘N’表示缺失进行填充
df['category_code'] = df['category_code'].fillna('N')缺失率4%的字段:brand,删除缺失行
# 只保留非缺失行的数据
df = df[df.brand.notnull()]2.2 查看重复值比例
df.duplicated().mean()合成新列:buy_count
# df.duplicated():表示的是所有信息完全相同的两行
# 考虑到实际购买场景,有的订单是同一个订单有好几样商品;
# 则根据订单号合成产品个数'buy_count'
df.shape
tmp = df.groupby(['order_id','product_id']).agg(buy_count=('user_id','count'))
df = pd.merge(df,tmp,on=['order_id','product_id'],how='inner')
df = df.drop_duplicates().reset_index(drop=True)
df.shape合成新列:购买总金额(GMV)
df['Amount'] = df['price'] * df['buy_count']2.3 检测异常值
2.3.1 转化id数据格式
df.order_id = df.order_id.astype('object')
df.product_id = df.product_id.astype('object')
df.category_id = df.category_id.astype('object')
df.user_id = df.user_id.astype('object')
# 注意:这里不把price,age转为float64类型的话,下面计算mean可能显示NaN
df.price = df.price.astype('float64')
df.age = df.age.astype('float64')2.3.2 检查price,age是否有异常值
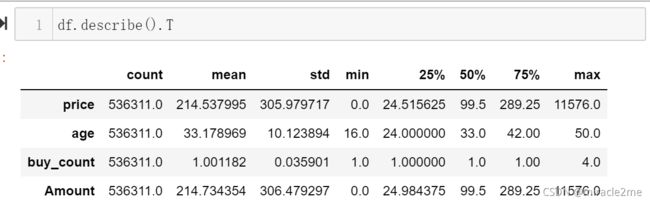
price中有0元购的情况,考虑到实际情况中有做活动抽奖的场景,价格0元也不算异常
2.3.3 其他字段是否有异常值
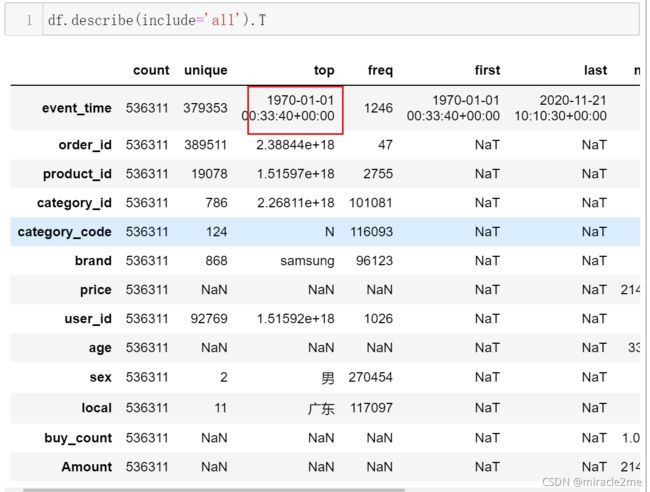
购买时间出现了明显异常,通过时间筛选去掉异常值。再观察数据无异常即可。
df = df[df.event_time>'2000-01-01']
df.describe(include='all').T3 数据探索性分析(EDA)
3.1 总览
3.1.1 总成交金额GMV
round(df.Amount.sum(),2)3.1.2 月成交金额GMV
# 将日期列设为索引
df.set_index('event_time',drop=False,inplace=True)
df.index = pd.to_datetime(df.index)
df.resample('M').agg({'Amount':np.sum})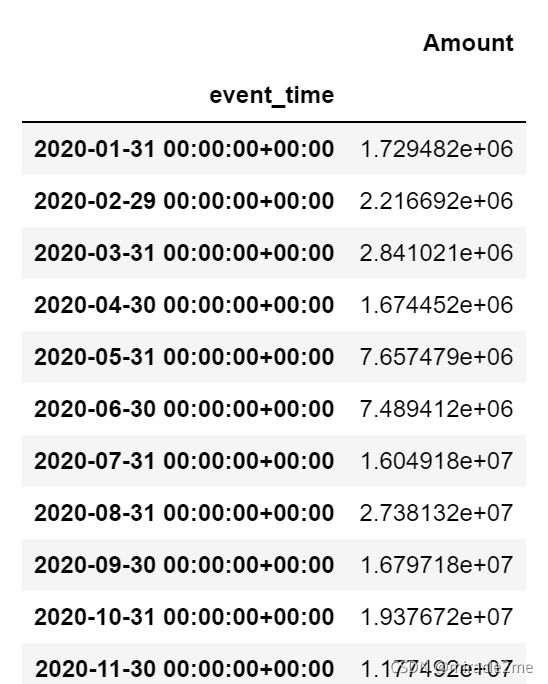
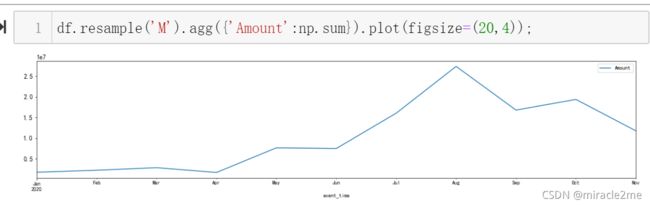
月度GMV可视化
- 8月是销量峰值月份
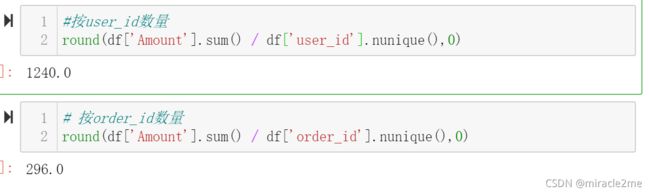
3.1.3 客单价
3.2 用户分析
3.2.1 用户区域特征
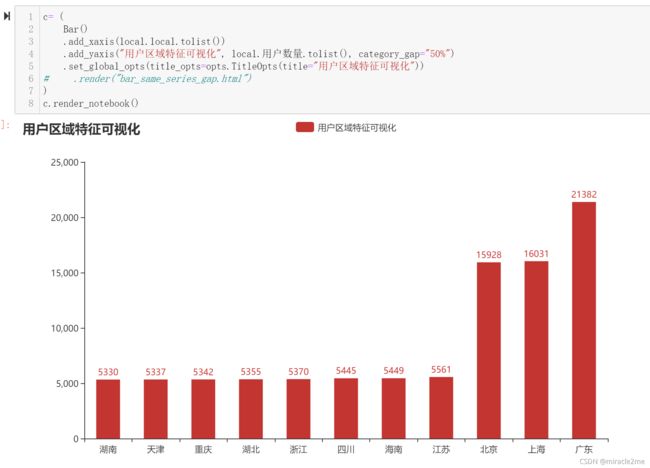
用户数量排前3的地区分别广东,上海,北京
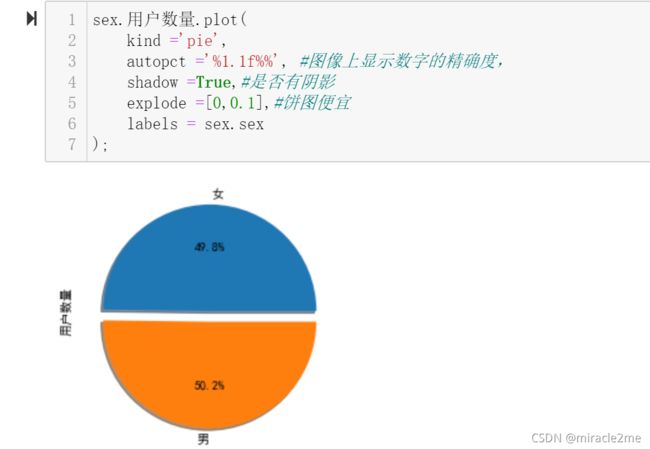
3.2.2 用户性别特征
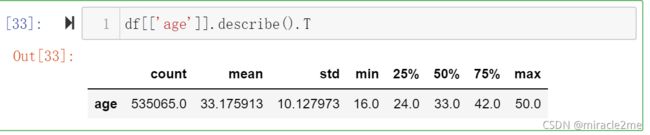
3.2.3 用户年龄特征
- 最小年龄16
- 最大年龄50
对年龄分箱
bins =[0,20,30,40,50]
df_ = df.copy()
df_['age_F']=pd.cut(df.age,bins=bins)
pd.value_counts(df_.age_F)
age_list = pd.value_counts(df_.age_F).index.astype(str).values.tolist()
age = df_.groupby('age_F')['user_id'].nunique().reset_index()
age.rename(columns={'user_id':'用户数量'},inplace=True)
age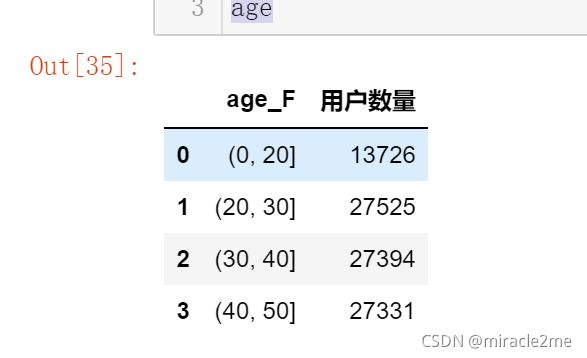
年龄可视化
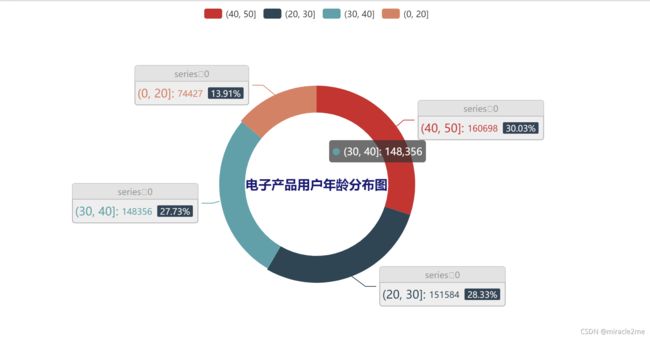
3.2.4 用户消费特征
各年龄段消费金额与下单次数汇总
age_F_data = df_.groupby('age_F').agg(消费金额=('Amount','sum'),下单次数=('order_id','nunique'))
age_F_data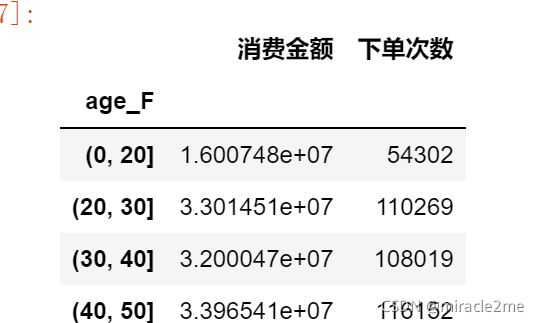
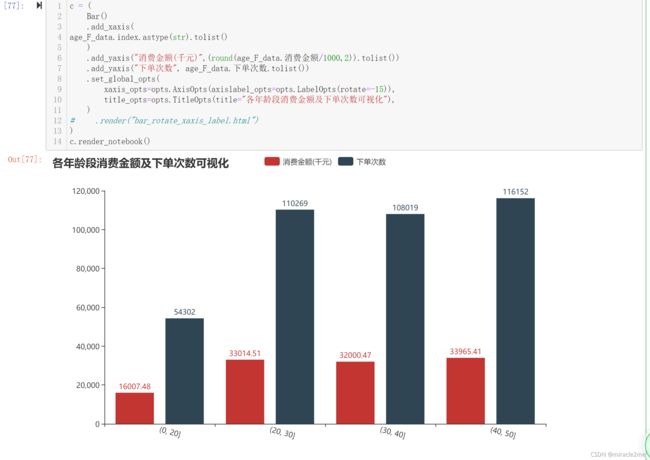
用户消费二八分析
user_28 = df.groupby('user_id').agg(消费金额=('Amount','sum')).sort_values('消费金额',ascending=False).reset_index()
user_28['累计销售额'] = user_28['消费金额'].cumsum()
user_28消费金额累计占比
p = user_28['消费金额'].cumsum()/user_28['消费金额'].sum() # 创建累计占比,Series
key = p[p>0.8].index[0]
# 达到80%销售额的索引值
key贡献80%销售额数据的用户占比

结论:27%的客户贡献了80%的销售额
4 RFM模型
- R(Recency):最近一次消费
- F(Frequency):消费频率
- M(Monetary):消费金额
4.1 M:消费金额
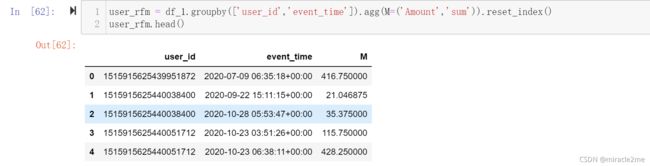
4.2 F:消费频率
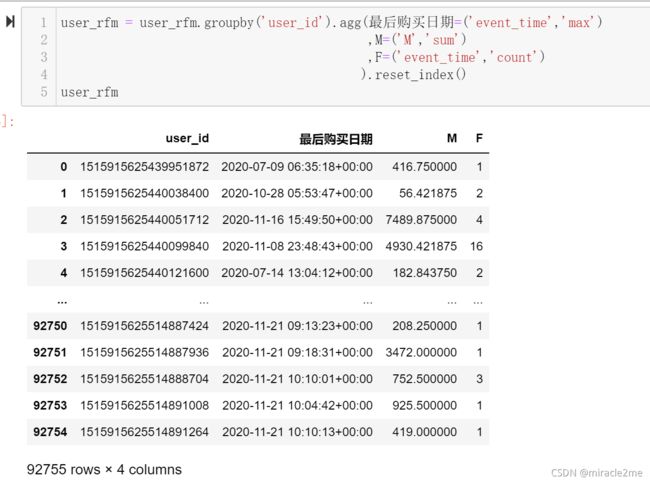
4.3 R:最近一次消费
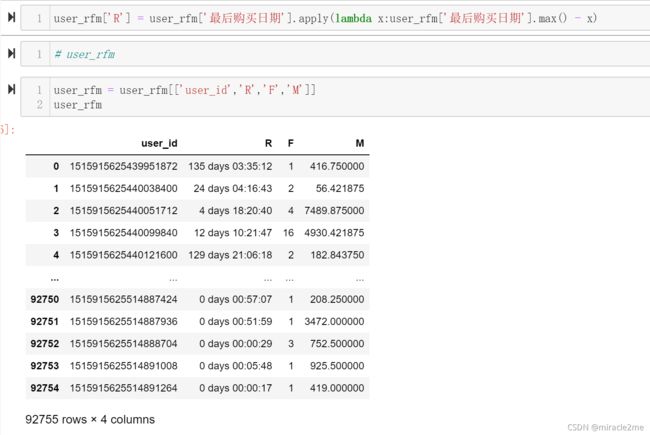
4.4 RFM打分体系
-
R的打分:
- [0-30]:5分
- (30-60]:4分
- (60-90]:3分
- (90-120]:2分
- 120以上:1分
-
F的打分:
- 1次:1分
- 2次:2分
- 3次:3分
- 4次:4分
- 5次及以上:5分
-
M的打分:
- [0-200]:1分
- (200-500]:2分
- (500-1000]:3分
- (1000-2000]:4分
- 2000以上:5分
rfm_score = user_rfm.copy()
# 提取日期数据
rfm_score['R'] = rfm_score.R.dt.days为rfm3项指标进行打分
for i,j in enumerate(rfm_score['R']):
if j <= 30:
rfm_score['R'][i] = 5
elif j <= 60:
rfm_score['R'][i] = 4
elif j <= 90:
rfm_score['R'][i] = 3
elif j <= 120:
rfm_score['R'][i] = 2
else :
rfm_score['R'][i] = 1
for i,j in enumerate(rfm_score['F']):
if j <= 1:
rfm_score['F'][i] = 1
elif j <= 2:
rfm_score['F'][i] = 2
elif j <= 3:
rfm_score['F'][i] = 3
elif j <= 4:
rfm_score['F'][i] = 4
else :
rfm_score['F'][i] = 5
for i,j in enumerate(rfm_score['M']):
if j <= 200:
rfm_score['M'][i] = 1
elif j <= 500:
rfm_score['M'][i] = 2
elif j <= 1000:
rfm_score['M'][i] = 3
elif j <= 2000:
rfm_score['M'][i] = 4
else :
rfm_score['M'][i] = 5 判断各项分数是否在均值之上,均值之上标记为1,均值之下标记为0
# 判断是否在平均值以上
rfm = pd.DataFrame()
rfm['user_id'] = rfm_score['user_id']
rfm['R'] = rfm_score['R'].apply(lambda x: '1' if x >= rfm_score['R'].mean() else '0')
rfm['F'] = rfm_score['F'].apply(lambda x: '1' if x >= rfm_score['F'].mean() else '0')
rfm['M'] = rfm_score['M'].apply(lambda x: '1' if x >= rfm_score['M'].mean() else '0')4.5 用户打标
rfm['result'] = rfm['R'] + rfm['F'] + rfm['M']
# 给标签赋值
for i,j in enumerate(rfm['result']):
if j == '111':
rfm['result'][i] = '重要价值客户'
elif j == '101':
rfm['result'][i] = '重要发展客户'
elif j == '011':
rfm['result'][i] = '重要保持客户'
elif j == '001':
rfm['result'][i] = '重要挽留客户'
elif j == '110':
rfm['result'][i] = '一般价值客户'
elif j == '100':
rfm['result'][i] = '一般发展客户'
elif j == '010':
rfm['result'][i] = '一般保持客户'
elif j == '000':
rfm['result'][i] = '一般挽留客户'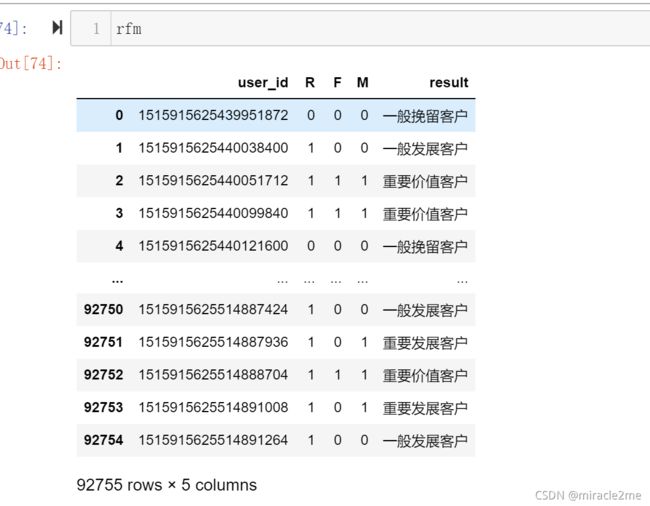
4.6 RFM用户价值模型可视化
c= (
Bar()
.add_xaxis(rfm['result'].value_counts().index.tolist())
.add_yaxis("RFM用户价值模型可视化",rfm['result'].value_counts().values.tolist(), category_gap="30%")
.set_global_opts(title_opts=opts.TitleOpts(title="RFM用户价值模型可视化"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)))
# .render("bar_same_series_gap.html")
)
c.render_notebook()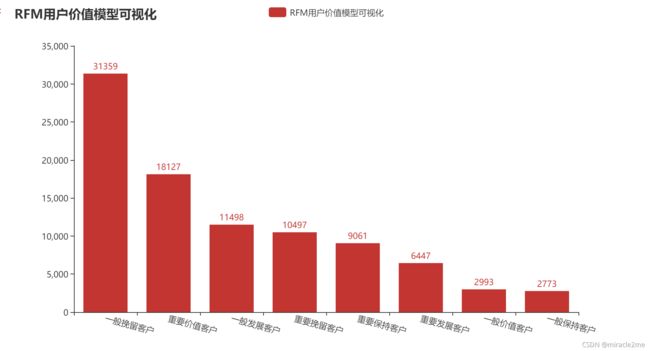
案例全代码
Python实现电子产品销售数据分析及RFM用户价值分析.rar-互联网文档类资源-CSDN下载
参考文章
10分钟,快速搞懂RFM用户分析模型_数据之路-CSDN博客
案例实操|手把手教你搭建,RFM客户价值分析模型 - 知乎