数据分析RFM模型 Python实现
数据分析RMF模型之Python实现
- 一、RFM模型接地气解读
-
- 1.身边的RFM
- 2.业务中的RFM
- 3.RFM分类种类
- 二、Python实现
-
- 1.思路概要
-
- (1)数据
- (2)计算字段
- (3)评分
- (4)分类
- 2.Python方法应用
- 建议
一、RFM模型接地气解读
对于小白来说,沾了“模型”的词汇听起来都会高深莫测,但是所有的高深莫测都要落地、接地气才能被业务真正用上。
RFM模型的作用简单来说就是做用户的分层、分类,到这里听起来还是虚无缥缈。分完类又能干点啥,能为帮助业务做什么呢?
1.身边的RFM
比如我月底没钱了,我要和身边的100个认识的人借钱,那么是否我直接群发一个信息可以了呢?
仔细想想好像不行,正常来说你可能会这么做。
- 关系极好的朋友:沙雕,给我200块。
- 亲爹:爹,我没钱吃饭了,转我500块。
- 普通同学:hello,李哥,能借我100块不,我下周还你,多谢你了。
但是如果你把内容发乱了就真正沙雕了。
对普通同学说:沙雕,借我100块。
对好朋友说:爹,没钱吃饭了,转我500块。
对亲爹说:hello,李哥,能借我100块不,我下周还你,多谢你了。
我相信你好像看出点什么了,给用户好分类才能更好地做接下来的运营动作,帮助业务完成最终的目标,上面例子的目标就是“借钱”。
2.业务中的RFM
现实中的业务可能是什么样子的呢?
假如我的公司WhiteSpace有10000个用户,我这次要做一个销售活动,那么我是直接用CRM给10000个用户直接发推广消息吗?
仔细想想好像也不能,这就和上面的举例是一样的了。
- 2015年注册,只买过一次10元的商品,最近的一次下单日期距今超700天,这些用户占30%。(流失用户)
- 2016年注册,下单超过100次,最近一次下单日期距今10—30天,平均每单200元。
- 2019年注册,下单200次,最近一次下单日期距今10-15天,平均每单50元。
每条短信3分钱,如果都发,就要花300块,好像也不多,哈哈。那300块成本能带来多少收益呢?这次业务的投入产出比ROI又会咋样呢?
如果发优惠券,那么每类用户
- 都发满200减30?
- 都发无门槛10元?
- 都发9折券?
这就是业务真正面对的问题了,那么我们就需要用RFM把用户进行分类了,不同的用户对应不同的运营策略和方法。
3.RFM分类种类

具体分类见此表,通过R、F、M三个纬度将用户分为8类,对这8类用户进行个性化的运营方法和策略。
这里要注意,要结合实际的业务去看对用的用户,要实际业务化。
例如对于今日头条资讯了app,R-最近一次登陆,F-登陆次数,M-在线时常。
二、Python实现
1.思路概要
(1)数据
首先要有数据,数据至少要包括用户ID、下单时间、消费金额,示例如表。
| user_id | order_time | payment |
|---|---|---|
| 999xc | 2018-10-01 | 9999 |
| 666sh | 2018-07-01 | 9999 |
(2)计算字段
首先要求每个用户最近的一次消费时间,也就是最大的order_time,按用户分组,求最大order_time,然后用今天减去最大的Order_time,这样就求出每个用户最后一次消费日期距今的天数。
用户分组,求最大order_time,今天-最大order_time,求的R值。
| user_id | order_time | payment | R_v(距今天数) |
|---|---|---|---|
| 999xc | 2018-10-01 | 9999 | 10 |
| 666sh | 2018-07-01 | 9999 | 15 |
按用户分组,求所有的下单次数F_v,直接分组计数即可
| user_id | order_time | payment | R_v(某时间周期中最近一次消费的距今天数) | F_v(某时间周期中下单次数) |
|---|---|---|---|---|
| 999xc | 2018-10-01 | 9999 | 10 | 20 |
| 666sh | 2018-07-01 | 9999 | 15 | 30 |
按用户分组,对消费金额进行求和M_v
| user_id | order_time | payment | R_v(某时间周期中最近一次消费的距今天数) | F_v(某时间周期中下单次数) | 总消费金额 |
|---|---|---|---|---|---|
| 999xc | 2018-10-01 | 9999 | 10 | 20 | 500 |
| 666sh | 2018-07-01 | 9999 | 15 | 30 | 600 |
(3)评分
有很多中评分的方法,这里只分享平均值纬度评分法。
分别求出所有用户R_v,F_v,M_v的平均值,然后将每位用户的R_v,F_v,M_v平均值进行比较。
高于R_v平均值则为0,反之为1,高于F_v平均值为1,反之为0,高于M_v平均值为1,反之为0。R_v数值5越大,得分越低。
所以我们有得到6列的计算值。
| user_id | order_time | payment | R_v(某时间周期中最近一次消费的距今天数) | F_v(某时间周期中下单次数) | 总消费金额 | R_mean | F_mena | M_mean | R_score | F_score | M_score |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 999xc | 2018-10-01 | 9999 | 10 | 20 | 500 | 5 | 15 | 200 | 1 | 1 | 0 |
| 666sh | 2018-07-01 | 9999 | 15 | 30 | 600 | 5 | 15 | 200 | 1 | 1 | 0 |
(4)分类
根据R_score|F_score|M_score的得分,按照分类种类进行判断分类。
if R_score = 1 and F_score = 1 and M_score = 1:
then ‘重要价值’
elif R_score = 1 and F_socre = 0 and M_score = 1:
then ‘’
按照第一个图分类即可,这样我们就会得到最后一个分类结果。
| user_id | order_time | payment | R_v(某时间周期中最近一次消费的距今天数) | F_v(某时间周期中下单次数) | 总消费金额 | R_mean | F_mena | M_mean | R_score | F_score | M_score | customer_Class |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 999xc | 2018-10-01 | 9999 | 10 | 20 | 500 | 5 | 15 | 200 | 1 | 1 | 0 | 一般价值 |
| 666sh | 2018-07-01 | 9999 | 15 | 30 | 600 | 5 | 15 | 200 | 1 | 1 | 0 | 一般价值 |
整体思路就是这些了,其实写sql会更简单一些,后面在写个SQL实现吧。
2.Python方法应用
数据集可在此下载,大概10W条数据
导入numpy、pandas、matplotlib
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
设置数据集路径
path_order = '/Users/valkyrja/Documents/dataanalysis/数据集/巴西/olist_orders_dataset.csv'
path_payment = '/Users/valkyrja/Documents/dataanalysis/数据集/巴西/olist_order_payments_dataset.csv'
path_customer = '/Users/valkyrja/Documents/dataanalysis/数据集/巴西/olist_customers_dataset.csv'
加载数据集
order = pd.read_csv(path_order)
payment = pd.read_csv(path_payment)
customer = pd.read_csv(path_customer)
预览订单数据集
order.head()

有很多列,我们这里只对order_id,customer_id,order_purchase_timestamp三列保留即可,其他列大家可以自己了解下。
order_t = order[['order_id', 'customer_id', 'order_purchase_timestamp']]
基本的数据清洗,空值、重复值等。
order_t.isnull().sum()
order_t.duplicated('customer_id').sum()


空值和重复值都没有。
对用户数据集进行预览,观察后值保留customer_id、customer_unique_id
customer.head()

保留所需列,观察空值情况
customer_t = customer[['customer_id', 'customer_unique_id']]
customer_t.head()
customer_t.isna().sum()
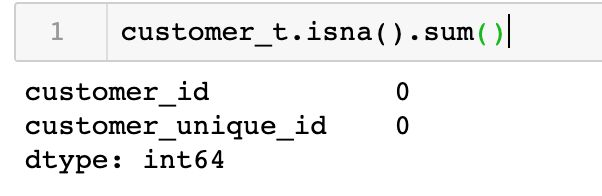
观察付款数据集
payment.head()

保留order_id、payment_value即可
payment_t = payment[['order_id', 'payment_value']]
我们看一下订单的重复情况
payment[payment.duplicated('order_id')]
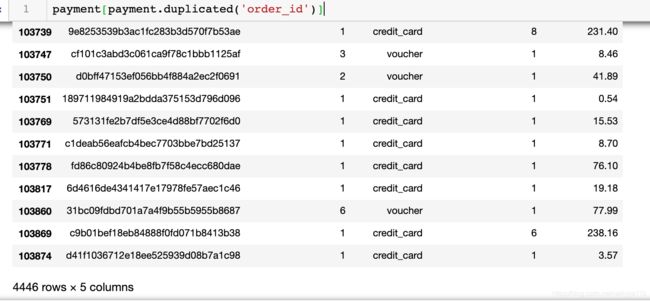
由此看来,order_id是有重复值的,这里一个订单可能又多个方式付款,因此重复。
所以按order_id进行分组,对消费金额进行求和
payment_sum = payment_t.groupby('order_id').agg({'payment_value':'sum'})
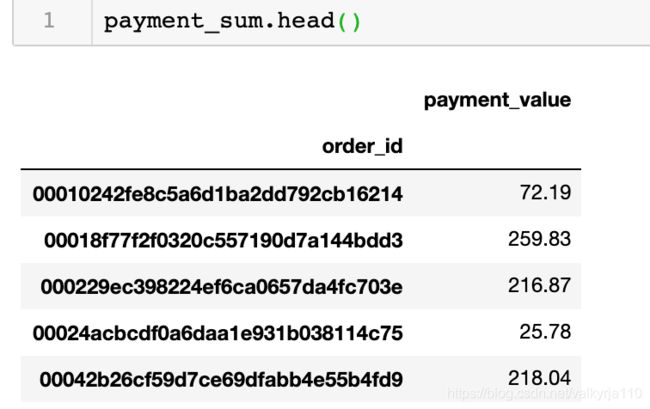
这样每个Order_id就只对应一个总的消费金额了。
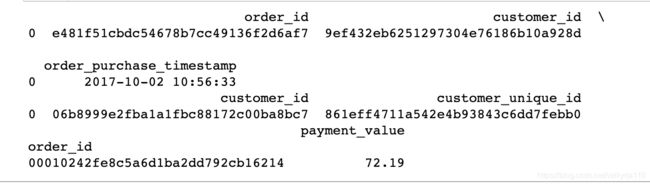
数据集没什么大问题,再预览一下
print(order_t.head(1))
print(customer_t.head(1))
print(payment_sum.head(1))
接下来就是将3各表进行连接了,分别使用order_id,customer_id作为连接键。
cus_order = pd.merge(customer_t, order_t, how = 'left', left_on = 'customer_id', right_on = 'customer_id')
这里先对用户表和订单表进行连接,使用的是merge的方法,形成的用户订单表如下
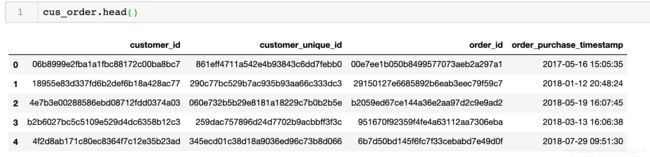
在将用户订单表和消费金额表进行连接,获得用户订单付款表
cus_order_pay = pd.merge(cus_order, payment_sum, how = 'left', on = 'order_id')

3个表进行左连接之后出现了一个缺失值,直接删除即可。
再用isna观察下,没有缺失值了。
cus_order_pay_n = cus_order_pay.dropna()
cus_order_pay_n.isna().sum()
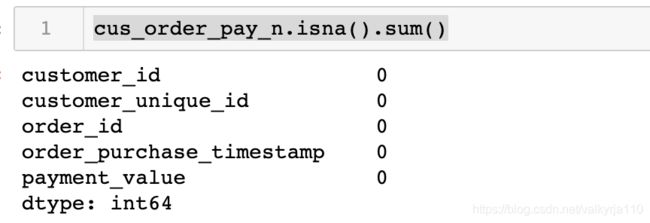
对大表进行统计性分析,发现居然有0元付费情况
cus_order_pay_n.describe()

可能是有优惠,最后付款就是0元,把这些数据拿出来观察下
cus_order_pay_n[cus_order_pay_n['payment_value'] == 0]

只有3行,貌似没什么影响,直接删掉即可。
cus_order_pay_n = cus_order_pay_n.drop(cus_order_pay_n[cus_order_pay_n['payment_value'] == 0].index)
cus_order_pay_n.head()

基本清洗完的大表。
将日期字符串转化为datetime类型方便后面的计算
cus_order_pay_n['order_purchase_timestamp'] = pd.to_datetime(cus_order_pay_n['order_purchase_timestamp'],
format = '%Y-%m-%d %H:%M:%S')
观察下数据类型,应该是没什么问题了。
cus_order_pay_n.info()
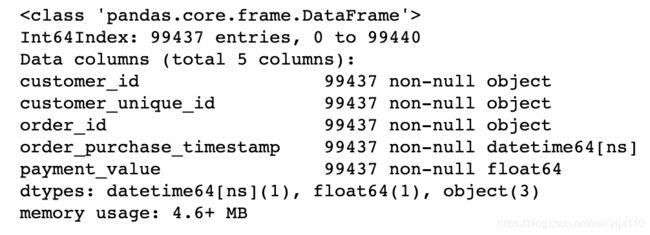
分别观察最大最小下单日期Timestamp(‘2018-10-17 17:30:18’)、Timestamp(‘2016-09-04 21:15:19’)
cus_order_pay_n['order_purchase_timestamp'].max()
cus_order_pay_n['order_purchase_timestamp'].min()
那我们就按照2018-10-20作为分析截止日期
cus_order_pay_n['now'] = pd.to_datetime('2018-10-20 00:00:00')
计算下每个下单日期距离截止日期的天数
cus_order_pay_n['R_value'] = cus_order_pay_n['now'] - cus_order_pay_n['order_purchase_timestamp']
cus_order_pay_n['R_value'].dt.days.head()
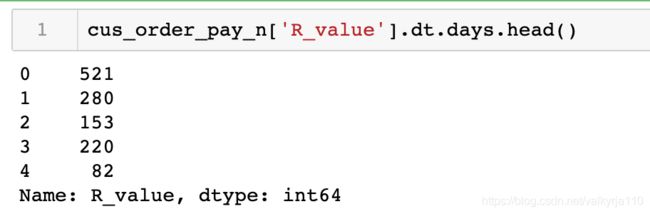
按唯一的用户id进行分组,求最近一次下单的最小时间、订单数量和消费总金额。
modle_value = cus_order_pay_n.groupby('customer_unique_id').agg({'R_value':'min',
'order_id':'count', 'payment_value':'sum'})
modle_value.head()
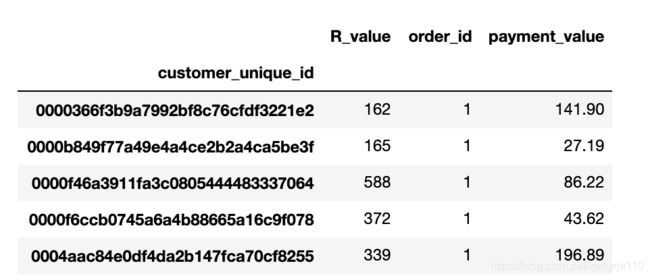
modle_value.describe()

基本的数据出来了,这里做个rename的列重命名
modle_value.rename(columns = {'R_value':'R', 'order_id':'order_num', 'payment_value':'pay_total'}, inplace = True)

对R、F、M进行逻辑判断,是否大于均值
modle_value['R_v'] = modle_value['R'].apply(lambda x: 1 if x < 290 else 0)
modle_value['F_v'] = modle_value['order_num'].apply(lambda x: 1 if x > modle_value['order_num'].mean() else 0)
modle_value['M_v'] = modle_value['pay_total'].apply(lambda x: 1 if x > modle_value['pay_total'].mean() else 0)
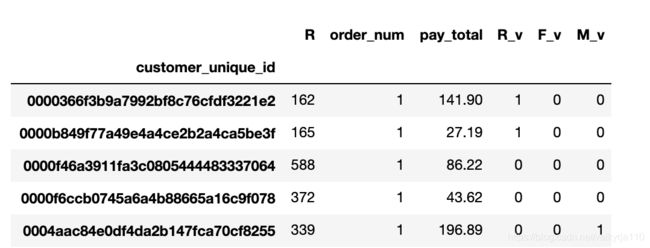
定义个函数,做最后的分类即可
def score(x):
if x['R_v'] == 1 and x['F_v'] == 1 and x['M_v'] == 1:
return '高质量'
elif x['R_v'] == 1 and x['F_v'] == 0 and x['M_v'] == 1:
return '重维持'
elif x['R_v'] == 0 and x['F_v'] == 1 and x['M_v'] == 1:
return '召回'
elif x['R_v'] == 0 and x['F_v'] == 0 and x['M_v'] == 1:
return '挽留'
elif x['R_v'] == 1 and x['F_v'] == 1 and x['M_v'] == 0:
return '挖掘'
elif x['R_v'] == 1 and x['F_v'] == 1 and x['M_v'] == 1:
return '新用户推广'
elif x['R_v'] == 1 and x['F_v'] == 1 and x['M_v'] == 1:
return '价值不高,一般维持'
else:
return '即将流失'
使用apply方法应用函数
modle_value['score'] = modle_value.apply(score, axis = 1)
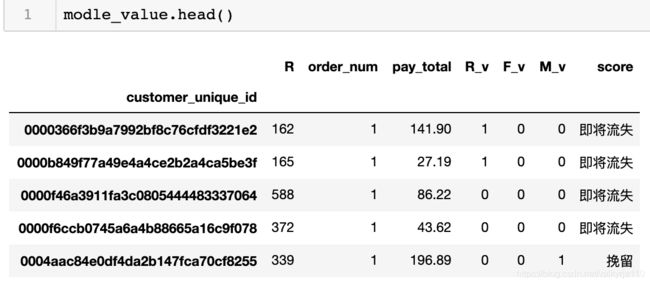
所有用户就分出类别来了,接下来观察下比列。
使用计数方法value_counts,换算成占比
modle_value['score'].value_counts(normalize = True)

即将流失占比70%,高质量占比1%。做一个简单的可视化观察下~
labels = ['loss','important remain','remain','high value','recall','dig']
sizes = [0.704286,0.148721, 0.120290,0.013154, 0.008065, 0.005484]
explode = (0.2,0.2,0.6,0.5,0.3,0.2)
plt.pie(sizes,explode=explode,labels=labels,autopct='%1.1f%%',shadow=False,startangle=150)
plt.show()

这就是最后的用户分类了。
建议
根据运营的需要,将分类结果同步业务方,一起讨论针对不同的用户使用何种方法,以及对应投入的成本等。
一定要去找业务方沟通,别自己直接给判断。