CNN-LSTM预测北京雾霾浓度完整代码
前言:本文主要介绍有关北京市单日雾霾浓度预测问题以及相关代码
1、数据准备
这里主要采用了污染物浓度数据(PM10、SO2、NO2、O3、CO)以及部分气象要素(包括最高温度、最低温度、风速、风向、天气)等数据
数据的获取参见请跳转
(1)污染物浓度相关数据获取
(2)部分气象要素相关数据获取
将获取的数据整合到自己的电脑中,由于数据量不是很大,可以直接存放到Excel中
2、数据清洗
由于数据中存在中文字符,以及一些缺失值(少量),我的做法其实也是比较常规,基本就是均值填充以及LabelEncoding的方式,如果需要这部分的数据,可以评论告诉我!【无偿提供】
数据清洗代码(仅供参考):
import warnings
import pandas as pd
import numpy as np
warnings.filterwarnings('ignore')
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
np.set_printoptions(suppress=True)
# 数据处理
def clean_data(df):
df['WindDir'] = df['WindDir'].map({'无持续风向': 0, '北风': '1', '南风': 2, '东风': 3, '西风': 4,
'西南风': 5, '西北风': 6, '东南风': 7, '东北风': 8})
df['WindDir'] = df['WindDir'].astype(int)
df['Weather'] = df['Weather'].map({'晴': 0, '多云': 1,
'小雨': 2, '雷阵雨': 2, '阵雨': 2, '雷雨': 2,
'中雨': 2, '小到中雨': 2, '大雨': 2, '暴雨': 2, '中到大雨': 2, '雨夹雪': 2,
'小雪': 3, '中雪': 3, '暴雪': 3, '大雪': 3, '小到中雪': 3,
'阴': '4', '霾': 5, '雾': 5})
df['Weather'] = df['Weather'].astype(int)
df['Wind'] = df['Wind'].map({'1': 1, '1-2': 1.5, '2': 2, '2-3': 2.5, '3': 3,
'3-4': 3.5, '4': 4, '4-5': 4.5, '5': 5, '5-6': 5.5, '6': 6, '6-7': 6.5})
df['Wind'] = df['Wind'].fillna(0)
df.drop(['Date'], axis=1, inplace=True)
return df
def data_process(data):
df = np.log(data)
return df
def one_hot(data):
winddir = pd.get_dummies(data.iloc[:, 8], prefix='windDir')
wind = pd.get_dummies(data.iloc[:, 9], prefix='wind')
weather = pd.get_dummies(data.iloc[:, 10], prefix='weather')
X_train = pd.concat((data,
winddir,
wind,
weather
), axis=1)
X_train.drop([
'WindDir',
'Wind',
'Weather'
], axis=1, inplace=True)
return X_train
if __name__ == '__main__':
df = pd.read_excel('Beijing_haze_data.xlsx')
df = clean_data(df)
# print(df)
df.insert(df.shape[1], 'label', df['PM2.5'])
df.drop(['PM2.5'], axis=1, inplace=True)
# print(df)
# 数据规约
columns = []
df.iloc[:, :5] = data_process(df.iloc[:, :5])
df.iloc[:, 10:] = data_process(df.iloc[:, 10:]) # label也对数化
# df.to_excel('data_for_model_beijing.xlsx', index=None)
print(df)
如下图所示
注:label表示PM2.5浓度数据
3、数据建模
本文采用CNN-LSTM模型进行雾霾浓度模型预测,使用该混合模型的效果会好于单个LSTM的模型,具体的模型原理这里不再赘述,可以参考相关的论文,下图是我整个搭建模型的结构图,由于本文属于时序预测,因此使用的是1维卷积。

本文是用前6年的雾霾数据(2015年~2021年),来预测接下来28天的PM2.5浓度的结果,直接给出建模的代码:
import pandas as pd
from sklearn.preprocessing import StandardScaler, MinMaxScaler, OneHotEncoder
from keras import Sequential
from keras.layers import Dense, LSTM, Flatten,Dropout
import matplotlib.pyplot as plt
import numpy as np
import warnings
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers import Flatten
from sklearn.metrics import mean_squared_error
warnings.filterwarnings('ignore')
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
def lstm(X_train,y_train,X_vavid ,y_vavid, X_test,y_test):
# 转化为3D数据(samples,timestep,features)(行数,步长,列数)
X_train = X_train.reshape(X_train.shape[0], 1, X_train.shape[1])
X_vavid = X_vavid.reshape(X_vavid.shape[0], 1, X_vavid.shape[1])
X_test = X_test.reshape(X_test.shape[0], 1, X_test.shape[1])
print(X_train.shape)
print(X_test.shape)
# 设计网络
model = Sequential()
model.add(Conv1D(filters=128, kernel_size=3, padding='same', strides=1,
activation='relu', input_shape=(1, X_train.shape[2]))) # input_shape=(X_train.shape[1], X_train.shape[2])
model.add(MaxPooling1D(pool_size=1))
model.add(LSTM(200, return_sequences=True))
model.add(LSTM(100, return_sequences=True))
model.add(Flatten())
model.add(Dense(100, activation='relu'))
# model.add(Dropout(0.1))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
# 拟合网络
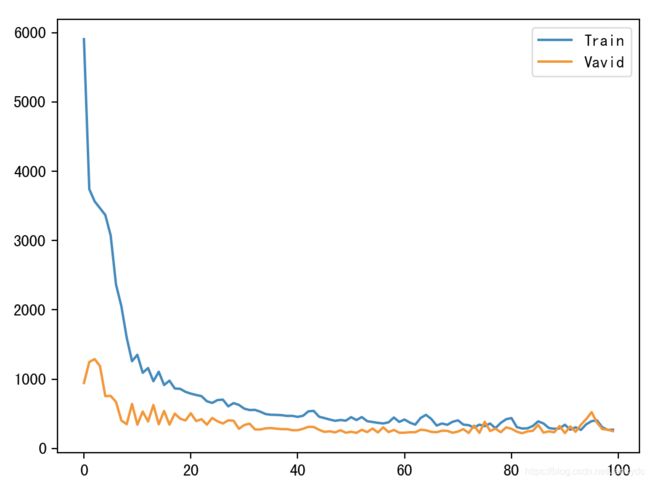
history = model.fit(X_train, y_train, epochs=100, batch_size=20,
validation_data=(X_vavid, y_vavid), verbose=2, shuffle=False)
# 绘制图像
plt.plot(history.history['loss'], label='Train')
plt.plot(history.history['val_loss'], label='Vavid')
plt.legend()
plt.show()
pred = model.predict(X_test, batch_size=20,verbose=2) # batch_size=5,
return pred
if __name__ == '__main__':
df = pd.read_excel('data_for_model_beijing.xlsx')
# print(df)
X_train = df.iloc[4:1523, :-1]
y_train = df.iloc[4:1523, -1]
X_vavid = df.iloc[1523:-28, :-1]
y_vavid = df.iloc[1523:-28, -1]
X_test = df.iloc[-28:, :-1]
y_test = df.iloc[-28:, -1]
X_train = X_train.values
X_vavid = X_vavid.values
X_test = X_test.values
# 测试集
pred = lstm(X_train, y_train,X_vavid, y_vavid,X_test, y_test)
truth = y_test.values
rmse_lstm = np.sqrt(mean_squared_error(pred, truth))
print('RMSE:', rmse_lstm)
max_error = np.mean(abs((pred - truth)))
print('MAE:', max_error)
max_percent_error = np.mean(abs((pred - truth.reshape(-1, 1))) / truth)
print('MAPE', max_percent_error)
r_2 = 1 - mean_squared_error(truth, pred) / np.var(truth)
print('R2', r_2)
IA = 1 - (np.sum(np.power((pred - truth), 2))) / \
(np.sum(np.power((np.abs(np.mean(truth) - pred) + np.abs(np.mean(truth) - truth)), 2)))
print('IA', IA)
result = pd.DataFrame()
result['True'] = y_test
result['Pred'] = pred.flatten()
print('*******预测值********\n', result)
result.to_excel('CNN_LSTM.xlsx', index=None)
print('CNN_LSTM结果文件已输出')
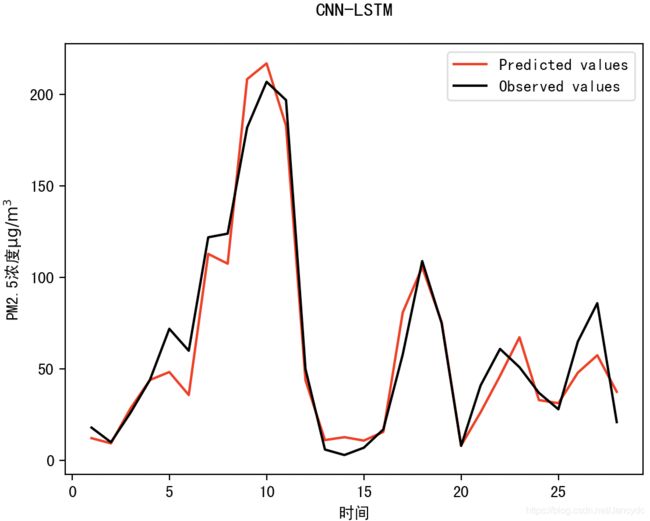
x = range(1, X_test.shape[0]+1)
plt.plot(x, pred, color='r', label='Predicted values')
plt.plot(x, y_test, color='k', label='Observed values')
plt.xlabel('时间')
plt.ylabel('PM2.5浓度$ \mathrm{\mu g/m^3}$')
plt.legend()
plt.title('CNN-LSTM\n')
plt.show()
大家都知到
4、预测结果
训练与验证集误差图
预测结果图:
5、小结
从图上看效果还是可以的,当然还可以将效果做的更好,我这里在参数优化上做的功夫还是比较少的,大家也知道神经网络模型主要就是调参工作,同时影响模型预测结果还是和数据量有关,因为我做的事单日预测,因此数据量上还是有一定的欠缺的,当然CNN-LSTM模型做小时预测也是完全OK的,只要你讲数据整理好,代码只要小小修改一下即可。
以上就是我整理的关于我课题项目的所有内容,如果有其他需求,欢迎评论留言~