视觉SLAM十四讲笔记五(第六讲)
引言
在前面五节中讲述了SLAM的运动方程(位姿由变换矩阵来描述)和观测方程(由相机成像模型给出),但由于噪声的存在,上述的运动方程和观测方程不是精确成立的,我们所得到的数据往往受噪声的影响,因此下文我们需要讨论在有噪声的数据中进行准确的状态估计。
我想在介绍非线性优化的内容,有必要补充一下概率论的知识,给出如下链接,供读者自行学习:
1、第一篇最大似然估计(了解)
2、第二篇,第一篇看完,再看这篇,巩固学习
1、批量状态估计与最大后验估计
我们知道经典SLAM模型由一个运动方程和一个观测方程组成,如下:
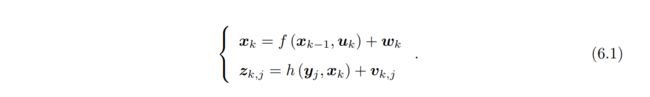
通过上述引言我们可以知道,在没有噪声的干扰下,经典SLAM模型是确立的额,但实际生活中往往会受到噪声的干扰,因此我们就需要在有噪声的数据中进行状态估计。考虑数据受噪声的影响后,会发生什么改变。
一般来说在运动和观测方程中,我们通常假设两个噪声项 wk, vk,j 满足零均值的高斯分布如下:
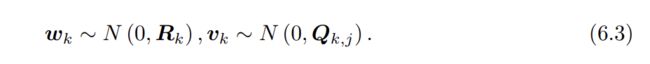
N表示高斯分布,0表示零均值,![]() 为协方差矩阵,在这些噪声的影响下,我们希望通过带噪声的数据z和u推断位姿x和地图y,这构成一个状态估计问题
为协方差矩阵,在这些噪声的影响下,我们希望通过带噪声的数据z和u推断位姿x和地图y,这构成一个状态估计问题
处理状态估计问题的方法分为两种:
1、滤波器(只估计当前状态,又称增量方法)
2、批量方法(把0-k时刻所有的输入和观测数据放在一起估计,以达到更大范围的最优化)(如今SLAM的主流方法)
因此,本书重点介绍以非线性优化为主的优化方法,首先,我们从概率学角度来看一下我们正在讨论什么问题。由于讨论的是批量的方法,考虑1到N的所有时刻,并假设有M个路标点。定义所有时刻的机器人位姿和路标点坐标为:
![]()
同样用不带下标的u表示所有时刻的输入,z表示所有时刻的观测数据。那么对机器人状态的估计,从概率学来看,就是已知输入数据u和观测数据z的条件下,求状态x,y的条件概率分布:
![]()
为了估计状态变量的条件分布,利用贝叶斯法则,有:
![]() 为后验概率
为后验概率
![]() 为似然
为似然
 为先验
为先验
注:直接求取后验分布是困难的,但求一个状态最优估计,使得在该状态下后验概率最大化是可行的:
![]()
贝叶斯法则告诉我们求解最大后验概率等价于最大化似然和先验的乘积。也可以说我们不知大机器人位姿或者路标在什么地方,此时就没有了先验,那么便可以求解最大似然估计(MLE)
![]()
直观地说,似然是指“在现在的位姿下,可能产生怎样的观测数据”。由于我们知道观 测数据,所以最大似然估计,可以理解成:“在什么样的状态下,最可能产生现在观测到的 数据”。这就是最大似然估计的直观意义
2、最小二乘的引出

注:我觉得很多数学基础不扎实的人不了解上述红框里面的内容是怎么来的,有必要给大家推导一下:

推导过程:
设:Y=Ax+B
其中:![]() ,
,![]() ,
,![]() ,A为1
,A为1
因为:![]() ,Y=Ax+B.
,Y=Ax+B.
所以:![]()
它依然是一个高斯分布。为了计算使它最大化的 xk, yj,我们往往使用最小化负对数的方 式,来求一个高斯分布的最大似然。

我们发现,该式等价于最小化噪声项(即误差)的一个二次型,这个二次型被称为马氏距离。
若现在我们考虑批量时刻数据,假设各个时刻的输入和观测是相互独立的,意味着各个输入之间是独立的,各个观测之间是独立的,并且输入和观测之间也是独立的,则可以对联合分布进行因式分解

注:这样我们可以独立处理各个时刻的运动和观测,我们定义数据与估计值之间的误差:
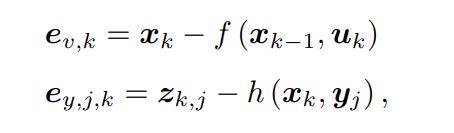
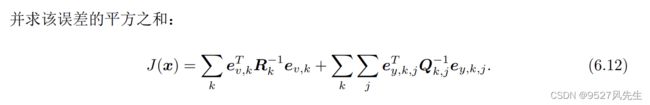

3、非线性最小二乘
3.1、简单最小二乘问题


注:这只针对与具有简单形式的f,对于复杂的目标函数,我们需要知道目标函数的全局性质,但这是不可能的,所以我们转而用迭代的方式求解。

这让求解导函数为零的问题,变成了一个不断寻找梯度并下降的过程。直到某个时刻 增量非常小,无法再使函数下降。此时算法收敛,目标达到了一个极小,我们完成了寻找 极小值的过程。在这个过程中,我们只要找到迭代点的梯度方向即可,而无需寻找全局导 函数为零的情况。
3.2、一阶二阶梯度法(不实用,暂不讲解,想了解的朋友可自行百度)
3.3、高斯牛顿法



缺点:1、增量方程的求解占据主导地位
2、求解增量方程需要H可逆
3、正常H只有半正定性,稳定性较差,无法保证迭代收敛
优点:很多算法都是基于高斯牛顿,依然是非线性优化方面一种简单有效的方法
3.4、列文伯格-马夸尔特方法




4、小结
无论是高斯牛顿还是列文伯格,在做最优化时,都需要提供变量的初始值,一个良好的初始值对最优化问题非常重要
5、库安装
5.1、ceres库安装
sudo apt-get install liblapack-dev libsuitesparse-dev libcxsparse3 libgflags-dev libgoogle-glog-dev libgtest-dev
git clone https://github.com/ceres-solver/ceres-solver
cd ceres-solver
mkdir build
cd build
cmake ..
make
sudo make install5.2、g20库安装
sudo apt-get install qt5-qmake qt5-default libqglviewer-dev-qt5 libsuitesparse-dev libcxsparse3 libcholmod3
git clone https://github.com/RainerKuemmerle/g2o
cd g2o
mkdir build
cd build
cmake ..
make
sudo make install6、Ceres简介
Ceres 库面向通用的最小二乘问题的求解,作为用户,我们需要做的就是定义优化问 题,然后设置一些选项,输入进 Ceres 求解即可。Ceres 求解的最小二乘问题最一般的形式如下(带边界的核函数最小二乘):

7、g2o简介
我们已经介绍了非线性最小二乘的求解方式。它们是由很多个误差项之和组成的。然 而,仅有一组优化变量和许多个误差项,我们并不清楚它们之间的关联。比方说,某一个 优化变量 xj 存在于多少个误差项里呢?我们能保证对它的优化是有意义的吗?进一步,我 们希望能够直观地看到该优化问题长什么样。于是,就说到了图优化。 图优化,是把优化问题表现成图(Graph)的一种方式。这里的图是图论意义上的图。 一个图由若干个顶点(Vertex),以及连接着这些节点的边(Edge)组成。进而,用顶点 表示优化变量,用边表示误差项。于是,对任意一个上述形式的非线性最小二乘问题,我
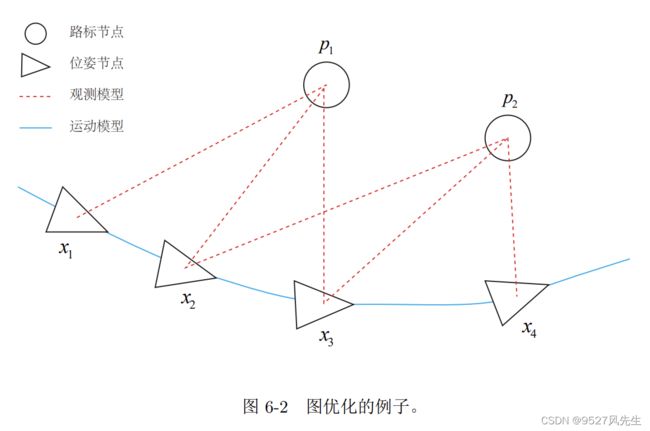
们可以构建与之对应的一个图。 图 6-2 是一个简单的图优化例子。我们用三角形表示相机位姿节点,用圆形表示路标 点,它们构成了图优化的顶点;同时,蓝色线表示相机的运动模型,红色虚线表示观测模 型,它们构成了图优化的边。此时,虽然整个问题的数学形式仍是式(6.12)那样,但现在 我们可以直观地看到问题的结构了。如果我们希望,也可以做去掉孤立顶点或优先优化边 数较多(或按图论的术语,度数较大)的顶点这样的改进。但是最基本的图优化,是用图 模型来表达一个非线性最小二乘的优化问题。而我们可以利用图模型的某些性质,做更好的优化。