我学了这套性能优化方法论,领导年终奖给我发了6个月
目录
概述
预备知识
模拟环境准备
CPU 占满
内存泄露
死锁
线程频繁切换
总结
概述
性能优化一向是后端服务优化的重点,但是线上性能故障问题不是经常出现,或者受限于业务产品,根本就没办法出现性能问题,包括笔者自己遇到的性能问题也不多,所以为了提前储备知识,当出现问题的时候不会手忙脚乱,我们本篇文章来模拟下常见的几个 Java 性能故障,来学习怎么去分析和定位。
大家好,给大家先做个自我介绍,我是码上代码,大家可以叫我码哥,我也是一个普通本科毕业的最普通学生,我相信大部分程序员或者想从事程序员行业的都是普通家庭的孩子,所以我也是靠自己的努力,从毕业入职到一家传统企业,到跳槽未尝败绩,现在在一家某互联网行业巨头公司工作,希望可以通过自己的分享对大家有一些帮助
我为大家准备了16个技术专栏带领大家一起学习
《亿级流量分布式系统实战》
《BAT大厂面试必问系列》
《技术杂谈》
《零基础带你学java教程专栏》
《带你学springCloud专栏》
《带你学SpringCloud源码专栏》
《带你学分布式系统专栏》
《带你学云原生专栏》
《带你学springboot源码》
《带你学netty原理与实战专栏》
《带你学Elasticsearch专栏》
《带你学mysql专栏》
《带你学JVM原理专栏》
《带你学Redis原理专栏》
《带你学java进阶专栏》
《带你学大数据专栏》
预备知识
既然是定位问题,肯定是需要借助工具,我们先了解下需要哪些工具可以帮忙定位问题。
top 命令
top命令使我们最常用的 Linux 命令之一,它可以实时的显示当前正在执行的进程的 CPU 使用率,内存使用率等系统信息。top -Hp pid 可以查看线程的系统资源使用情况。
vmstat 命令
vmstat 是一个指定周期和采集次数的虚拟内存检测工具,可以统计内存,CPU,swap 的使用情况,它还有一个重要的常用功能,用来观察进程的上下文切换。字段说明如下:
-
r: 运行队列中进程数量(当数量大于 CPU 核数表示有阻塞的线程)
-
b: 等待 IO 的进程数量
-
swpd: 使用虚拟内存大小
-
free: 空闲物理内存大小
-
buff: 用作缓冲的内存大小(内存和硬盘的缓冲区)
-
cache: 用作缓存的内存大小(CPU 和内存之间的缓冲区)
-
si: 每秒从交换区写到内存的大小,由磁盘调入内存
-
so: 每秒写入交换区的内存大小,由内存调入磁盘
-
bi: 每秒读取的块数
-
bo: 每秒写入的块数
-
in: 每秒中断数,包括时钟中断。
-
cs: 每秒上下文切换数。
-
us: 用户进程执行时间百分比(user time)
-
sy: 内核系统进程执行时间百分比(system time)
-
wa: IO 等待时间百分比
-
id: 空闲时间百分比
pidstat 命令
pidstat 是 Sysstat 中的一个组件,也是一款功能强大的性能监测工具,top 和 vmstat 两个命令都是监测进程的内存、CPU 以及 I/O 使用情况,而 pidstat 命令可以检测到线程级别的。pidstat命令线程切换字段说明如下:
-
UID :被监控任务的真实用户 ID。
-
TGID :线程组 ID。
-
TID:线程 ID。
-
cswch/s:主动切换上下文次数,这里是因为资源阻塞而切换线程,比如锁等待等情况。
-
nvcswch/s:被动切换上下文次数,这里指 CPU 调度切换了线程。
jstack 命令
jstack 是 JDK 工具命令,它是一种线程堆栈分析工具,最常用的功能就是使用 jstack pid 命令查看线程的堆栈信息,也经常用来排除死锁情况。
jstat 命令
它可以检测 Java 程序运行的实时情况,包括堆内存信息和垃圾回收信息,我们常常用来查看程序垃圾回收情况。常用的命令是jstat -gc pid。信息字段说明如下:
-
S0C:年轻代中 To Survivor 的容量(单位 KB);
-
S1C:年轻代中 From Survivor 的容量(单位 KB);
-
S0U:年轻代中 To Survivor 目前已使用空间(单位 KB);
-
S1U:年轻代中 From Survivor 目前已使用空间(单位 KB);
-
EC:年轻代中 Eden 的容量(单位 KB);
-
EU:年轻代中 Eden 目前已使用空间(单位 KB);
-
OC:老年代的容量(单位 KB);
-
OU:老年代目前已使用空间(单位 KB);
-
MC:元空间的容量(单位 KB);
-
MU:元空间目前已使用空间(单位 KB);
-
YGC:从应用程序启动到采样时年轻代中 gc 次数;
-
YGCT:从应用程序启动到采样时年轻代中 gc 所用时间 (s);
-
FGC:从应用程序启动到采样时 老年代(Full Gc)gc 次数;
-
FGCT:从应用程序启动到采样时 老年代代(Full Gc)gc 所用时间 (s);
-
GCT:从应用程序启动到采样时 gc 用的总时间 (s)。
jmap 命令
jmap 也是 JDK 工具命令,他可以查看堆内存的初始化信息以及堆内存的使用情况,还可以生成 dump 文件来进行详细分析。查看堆内存情况命令jmap -heap pid。
mat 内存工具
MAT(Memory Analyzer Tool)工具是 eclipse 的一个插件(MAT 也可以单独使用),它分析大内存的 dump 文件时,可以非常直观的看到各个对象在堆空间中所占用的内存大小、类实例数量、对象引用关系、利用 OQL 对象查询,以及可以很方便的找出对象 GC Roots 的相关信息。
idea 中也有这么一个插件,就是 JProfiler。
相关阅读:《性能诊断利器 JProfiler 快速入门和最佳实践》
模拟环境准备
基础环境 jdk1.8,采用 SpringBoot 框架来写几个接口来触发模拟场景,首先是模拟 CPU 占满情况
CPU 占满
模拟 CPU 占满还是比较简单,直接写一个死循环计算消耗 CPU 即可。
/**
* 模拟CPU占满
*/
@GetMapping("/cpu/loop")
public void testCPULoop() throws InterruptedException {
System.out.println("请求cpu死循环");
Thread.currentThread().setName("loop-thread-cpu");
int num = 0;
while (true) {
num++;
if (num == Integer.MAX_VALUE) {
System.out.println("reset");
}
num = 0;
}
}Copy to clipboardErrorCopied请求接口地址测试curl localhost:8080/cpu/loop,发现 CPU 立马飙升到 100%

通过执行top -Hp 32805 查看 Java 线程情况

执行 printf '%x' 32826 获取 16 进制的线程 id,用于dump信息查询,结果为 803a。最后我们执行jstack 32805 |grep -A 20 803a来查看下详细的dump信息。

这里dump信息直接定位出了问题方法以及代码行,这就定位出了 CPU 占满的问题。
内存泄露
模拟内存泄漏借助了 ThreadLocal 对象来完成,ThreadLocal 是一个线程私有变量,可以绑定到线程上,在整个线程的生命周期都会存在,但是由于 ThreadLocal 的特殊性,ThreadLocal 是基于 ThreadLocalMap 实现的,ThreadLocalMap 的 Entry 继承 WeakReference,而 Entry 的 Key 是 WeakReference 的封装,换句话说 Key 就是弱引用,弱引用在下次 GC 之后就会被回收,如果 ThreadLocal 在 set 之后不进行后续的操作,因为 GC 会把 Key 清除掉,但是 Value 由于线程还在存活,所以 Value 一直不会被回收,最后就会发生内存泄漏。
/**
* 模拟内存泄漏
*/
@GetMapping(value = "/memory/leak")
public String leak() {
System.out.println("模拟内存泄漏");
ThreadLocal localVariable = new ThreadLocal();
localVariable.set(new Byte[4096 * 1024]);// 为线程添加变量
return "ok";
} Copy to clipboardErrorCopied我们给启动加上堆内存大小限制,同时设置内存溢出的时候输出堆栈快照并输出日志。
java -jar -Xms500m -Xmx500m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/tmp/heaplog.log analysis-demo-0.0.1-SNAPSHOT.jarCopy to clipboardErrorCopied启动成功后我们循环执行 100 次,for i in {1..500}; do curl localhost:8080/memory/leak;done,还没执行完毕,系统已经返回 500 错误了。查看系统日志出现了如下异常:
java.lang.OutOfMemoryError: Java heap spaceCopy to clipboardErrorCopied我们用jstat -gc pid 命令来看看程序的 GC 情况。

很明显,内存溢出了,堆内存经过 45 次 Full Gc 之后都没释放出可用内存,这说明当前堆内存中的对象都是存活的,有 GC Roots 引用,无法回收。那是什么原因导致内存溢出呢?是不是我只要加大内存就行了呢?如果是普通的内存溢出也许扩大内存就行了,但是如果是内存泄漏的话,扩大的内存不一会就会被占满,所以我们还需要确定是不是内存泄漏。我们之前保存了堆 Dump 文件,这个时候借助我们的 MAT 工具来分析下。导入工具选择Leak Suspects Report,工具直接就会给你列出问题报告。
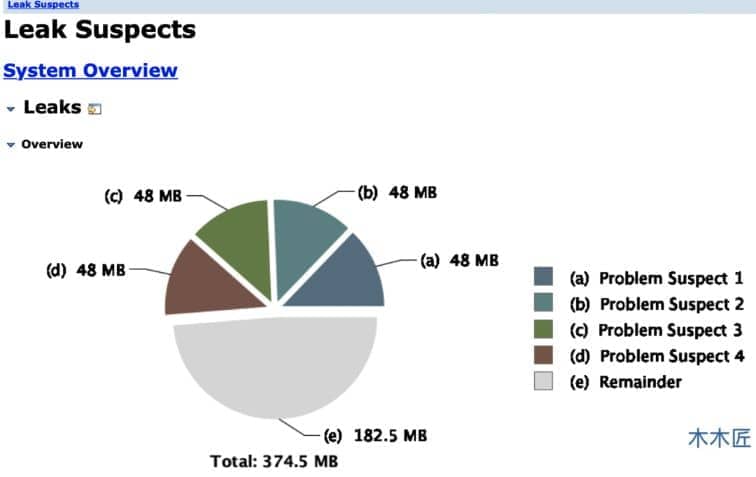
这里已经列出了可疑的 4 个内存泄漏问题,我们点击其中一个查看详情。
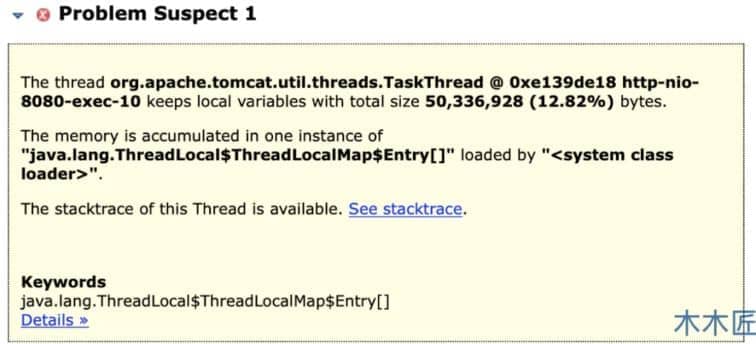
这里已经指出了内存被线程占用了接近 50M 的内存,占用的对象就是 ThreadLocal。如果想详细的通过手动去分析的话,可以点击Histogram,查看最大的对象占用是谁,然后再分析它的引用关系,即可确定是谁导致的内存溢出。
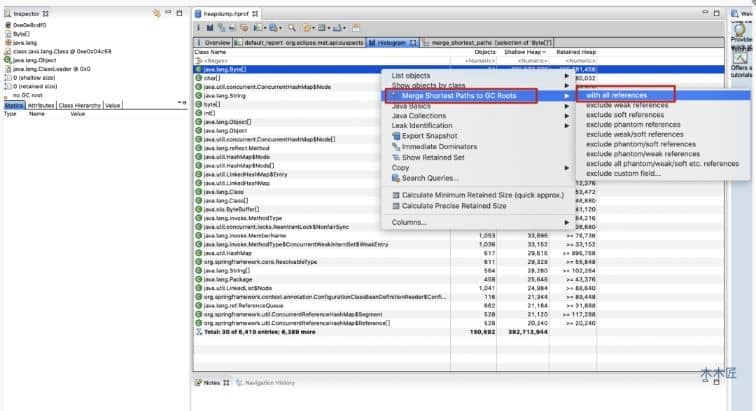
上图发现占用内存最大的对象是一个 Byte 数组,我们看看它到底被那个 GC Root 引用导致没有被回收。按照上图红框操作指引,结果如下图:

我们发现 Byte 数组是被线程对象引用的,图中也标明,Byte 数组对像的 GC Root 是线程,所以它是不会被回收的,展开详细信息查看,我们发现最终的内存占用对象是被 ThreadLocal 对象占据了。这也和 MAT 工具自动帮我们分析的结果一致。
死锁
死锁会导致耗尽线程资源,占用内存,表现就是内存占用升高,CPU 不一定会飙升(看场景决定),如果是直接 new 线程,会导致 JVM 内存被耗尽,报无法创建线程的错误,这也是体现了使用线程池的好处。
ExecutorService service = new ThreadPoolExecutor(4, 10,
0, TimeUnit.SECONDS, new LinkedBlockingQueue(1024),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
/**
* 模拟死锁
*/
@GetMapping("/cpu/test")
public String testCPU() throws InterruptedException {
System.out.println("请求cpu");
Object lock1 = new Object();
Object lock2 = new Object();
service.submit(new DeadLockThread(lock1, lock2), "deadLookThread-" + new Random().nextInt());
service.submit(new DeadLockThread(lock2, lock1), "deadLookThread-" + new Random().nextInt());
return "ok";
}
public class DeadLockThread implements Runnable {
private Object lock1;
private Object lock2;
public DeadLockThread1(Object lock1, Object lock2) {
this.lock1 = lock1;
this.lock2 = lock2;
}
@Override
public void run() {
synchronized (lock2) {
System.out.println(Thread.currentThread().getName()+"get lock2 and wait lock1");
try {
TimeUnit.MILLISECONDS.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock1) {
System.out.println(Thread.currentThread().getName()+"get lock1 and lock2 ");
}
}
}
} Copy to clipboardErrorCopied我们循环请求接口 2000 次,发现不一会系统就出现了日志错误,线程池和队列都满了,由于我选择的当队列满了就拒绝的策略,所以系统直接抛出异常。
java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@2760298 rejected from java.util.concurrent.ThreadPoolExecutor@7ea7cd51[Running, pool size = 10, active threads = 10, queued tasks = 1024, completed tasks = 846]Copy to clipboardErrorCopied通过ps -ef|grep java命令找出 Java 进程 pid,执行jstack pid 即可出现 java 线程堆栈信息,这里发现了 5 个死锁,我们只列出其中一个,很明显线程pool-1-thread-2锁住了0x00000000f8387d88等待0x00000000f8387d98锁,线程pool-1-thread-1锁住了0x00000000f8387d98等待锁0x00000000f8387d88,这就产生了死锁。
Java stack information for the threads listed above:
===================================================
"pool-1-thread-2":
at top.luozhou.analysisdemo.controller.DeadLockThread2.run(DeadLockThread.java:30)
- waiting to lock <0x00000000f8387d98> (a java.lang.Object)
- locked <0x00000000f8387d88> (a java.lang.Object)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
"pool-1-thread-1":
at top.luozhou.analysisdemo.controller.DeadLockThread1.run(DeadLockThread.java:30)
- waiting to lock <0x00000000f8387d88> (a java.lang.Object)
- locked <0x00000000f8387d98> (a java.lang.Object)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Found 5 deadlocks.Copy to clipboardErrorCopied线程频繁切换
上下文切换会导致将大量 CPU 时间浪费在寄存器、内核栈以及虚拟内存的保存和恢复上,导致系统整体性能下降。当你发现系统的性能出现明显的下降时候,需要考虑是否发生了大量的线程上下文切换。
@GetMapping(value = "/thread/swap")
public String theadSwap(int num) {
System.out.println("模拟线程切换");
for (int i = 0; i < num; i++) {
new Thread(new ThreadSwap1(new AtomicInteger(0)),"thread-swap"+i).start();
}
return "ok";
}
public class ThreadSwap1 implements Runnable {
private AtomicInteger integer;
public ThreadSwap1(AtomicInteger integer) {
this.integer = integer;
}
@Override
public void run() {
while (true) {
integer.addAndGet(1);
Thread.yield(); //让出CPU资源
}
}
}Copy to clipboardErrorCopied这里我创建多个线程去执行基础的原子+1 操作,然后让出 CPU 资源,理论上 CPU 就会去调度别的线程,我们请求接口创建 100 个线程看看效果如何,curl localhost:8080/thread/swap?num=100。接口请求成功后,我们执行 vmstat 1 10,表示每 1 秒打印一次,打印 10 次,线程切换采集结果如下:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
101 0 128000 878384 908 468684 0 0 0 0 4071 8110498 14 86 0 0 0
100 0 128000 878384 908 468684 0 0 0 0 4065 8312463 15 85 0 0 0
100 0 128000 878384 908 468684 0 0 0 0 4107 8207718 14 87 0 0 0
100 0 128000 878384 908 468684 0 0 0 0 4083 8410174 14 86 0 0 0
100 0 128000 878384 908 468684 0 0 0 0 4083 8264377 14 86 0 0 0
100 0 128000 878384 908 468688 0 0 0 108 4182 8346826 14 86 0 0 0Copy to clipboardErrorCopied这里我们关注 4 个指标,r,cs,us,sy。
r=100,说明等待的进程数量是 100,线程有阻塞。
cs=800 多万,说明每秒上下文切换了 800 多万次,这个数字相当大了。
us=14,说明用户态占用了 14%的 CPU 时间片去处理逻辑。
sy=86,说明内核态占用了 86%的 CPU,这里明显就是做上下文切换工作了。
我们通过top命令以及top -Hp pid查看进程和线程 CPU 情况,发现 Java 进程 CPU 占满了,但是线程 CPU 使用情况很平均,没有某一个线程把 CPU 吃满的情况。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
87093 root 20 0 4194788 299056 13252 S 399.7 16.1 65:34.67 javaCopy to clipboardErrorCopied PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
87189 root 20 0 4194788 299056 13252 R 4.7 16.1 0:41.11 java
87129 root 20 0 4194788 299056 13252 R 4.3 16.1 0:41.14 java
87130 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.51 java
87133 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.59 java
87134 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.95 javaCopy to clipboardErrorCopied结合上面用户态 CPU 只使用了 14%,内核态 CPU 占用了 86%,可以基本判断是 Java 程序线程上下文切换导致性能问题。
我们使用pidstat命令来看看 Java 进程内部的线程切换数据,执行pidstat -p 87093 -w 1 10,采集数据如下:
11:04:30 PM UID TGID TID cswch/s nvcswch/s Command
11:04:30 PM 0 - 87128 0.00 16.07 |__java
11:04:30 PM 0 - 87129 0.00 15.60 |__java
11:04:30 PM 0 - 87130 0.00 15.54 |__java
11:04:30 PM 0 - 87131 0.00 15.60 |__java
11:04:30 PM 0 - 87132 0.00 15.43 |__java
11:04:30 PM 0 - 87133 0.00 16.02 |__java
11:04:30 PM 0 - 87134 0.00 15.66 |__java
11:04:30 PM 0 - 87135 0.00 15.23 |__java
11:04:30 PM 0 - 87136 0.00 15.33 |__java
11:04:30 PM 0 - 87137 0.00 16.04 |__javaCopy to clipboardErrorCopied根据上面采集的信息,我们知道 Java 的线程每秒切换 15 次左右,正常情况下,应该是个位数或者小数。结合这些信息我们可以断定 Java 线程开启过多,导致频繁上下文切换,从而影响了整体性能。
为什么系统的上下文切换是每秒 800 多万,而 Java 进程中的某一个线程切换才 15 次左右?
系统上下文切换分为三种情况:
1、多任务:在多任务环境中,一个进程被切换出 CPU,运行另外一个进程,这里会发生上下文切换。
2、中断处理:发生中断时,硬件会切换上下文。在 vmstat 命令中是in
3、用户和内核模式切换:当操作系统中需要在用户模式和内核模式之间进行转换时,需要进行上下文切换,比如进行系统函数调用。
Linux 为每个 CPU 维护了一个就绪队列,将活跃进程按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。也就是 vmstat 命令中的r。
那么,进程在什么时候才会被调度到 CPU 上运行呢?
- 进程执行完终止了,它之前使用的 CPU 会释放出来,这时再从就绪队列中拿一个新的进程来运行
- 为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片被轮流分配给各个进程。当某个进程时间片耗尽了就会被系统挂起,切换到其它等待 CPU 的进程运行。
- 进程在系统资源不足时,要等待资源满足后才可以运行,这时进程也会被挂起,并由系统调度其它进程运行。
- 当进程通过睡眠函数 sleep 主动挂起时,也会重新调度。
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
- 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
结合我们之前的内容分析,阻塞的就绪队列是 100 左右,而我们的 CPU 只有 4 核,这部分原因造成的上下文切换就可能会相当高,再加上中断次数是 4000 左右和系统的函数调用等,整个系统的上下文切换到 800 万也不足为奇了。Java 内部的线程切换才 15 次,是因为线程使用Thread.yield()来让出 CPU 资源,但是 CPU 有可能继续调度该线程,这个时候线程之间并没有切换,这也是为什么内部的某个线程切换次数并不是非常大的原因。
总结
本文模拟了常见的性能问题场景,分析了如何定位 CPU100%、内存泄漏、死锁、线程频繁切换问题。分析问题我们需要做好两件事,第一,掌握基本的原理,第二,借助好工具。本文也列举了分析问题的常用工具和命令,希望对你解决问题有所帮助。当然真正的线上环境可能十分复杂,并没有模拟的环境那么简单,但是原理是一样的,问题的表现也是类似的,我们重点抓住原理,活学活用,相信复杂的线上问题也可以顺利解决。
大家一定记得点赞,收藏,关注
防止下次找不到了
你们的支持是我持续创作的动力!!!