基于Matlab的随机森林算法实现(附算法介绍及代码详解)
本算例完整代码领取方式在文末展示~
一、内容提要
在地学领域中,岩性的准确识别对于储层评价来说至关重要。因此,今天笔者想要分享的是随机森林算法在岩性识别中的应用与代码实现。
科普中国·科学百科定义:随机森林(Random forest)指的是利用多棵树对样本进行训练并预测的一种分类器。
通俗地来讲,随机森林算法从属于机器学习,它可以高效地实现以分类为目的的计算过程。下面来看一下随机森林的主要优点[1]:
(1) 可产生 高准确度的分类器;
(2) 处理 大量的输入变量;
(3) 在判断类别时,可以 考虑变量的重要性;
(4) 对 变量类型十分友好,可以处理离散型也可以处理连续型数据,且如果有一部分资料遗失,仍然可以保证计算的准确度;
(5) 训练 速度快。
因此,在本文中笔者将随机森林算法应用在基于测井数据的岩性分类计算上,以此提升复杂地质因素影响下的岩性识别效率与准确度。
以下分为三个部分进行讲解,包括算法简介、实例计算与代码解读。
二、算法简介
2.1 随机森林
随机森林算法的名称-Random Forest清晰地表示出这个过程是通过随机的方式形成了由多个决策树组成的一片森林。当新样本做为数据输入进入到构建完成的森林时,森林中的每一棵决策树就会分别进行判断,来识别这个样本所属的类别;再统计哪一类别被判定的最多,就预测这个样本为此类别。
此处分享一个较为生动的例子来帮助大家理解:某学校进行奖学金评选,如果只有一个老师(单一决策树)来决定奖学金的归属可能产生不公正现象(过拟合现象),但是随机选取多个老师组成评审委员会(随机森林)一起进行筛选(集成),然后进行投票得出最佳选举结果(拟合),就会较为公正。
2.2 决策树
因为随机森林由多个决策树构成,所以理应先掌握决策树(Decision Tree)的相关知识。
科普中国·科学百科定义:决策树是一种基本的分类器,一般是将特征分为两类,呈现树形结构;其具有可读性强、分类速度快的优点。
为了方便大家理解,笔者对周志华老师的著作《机器学习》中有关决策树的解释进行了简化,用于判断一个西瓜的好坏(见图1)。
第一步:看看纹理是否清晰的,模糊就判定为坏瓜。
第二步:看看根蒂是否蜷缩,硬挺则为坏瓜。
第三步:看看色泽是否青绿,是则为好瓜。
第四步:但如果色泽为青黑,则需要进一步查看触感是否硬滑,软粘则为坏瓜。
其中,纹理是根节点,包含所有样本集,根蒂、色泽、触感都属于分支节点,用于判断;好瓜和坏瓜属于叶子节点,用于输出结果。

图1 判断西瓜好坏的决策树(改自周志华《机器学习》)
正如上文解释到,单一决策树所做出的决定很有可能存在谬误,随机森林算法就是通过构建多个决策树来最终获取一个优秀的分类效果。
那如何用决策树构建随机森林?通常来说遵循以下流程:
2.3 随机森林的构建
1. 首先构建子数据集。从原始数据集中通过有放回的抽样方式(每抽取一个样本后再将它放回总体)来进行样本的随机抽取。
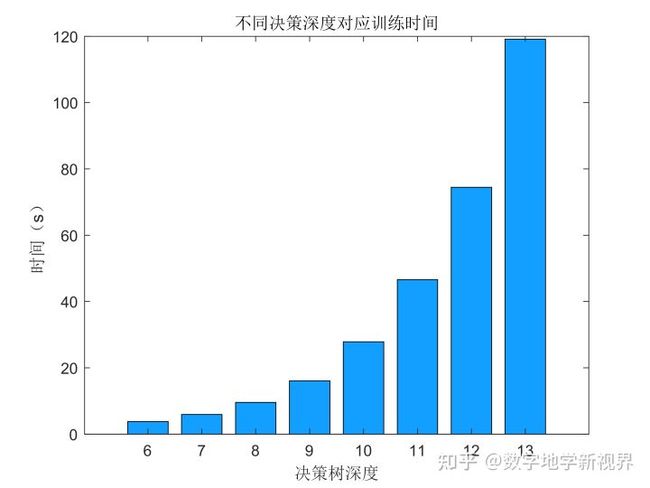
2. 再利用子数据集构建子决策树。假设一个子数据集有X个属性 ,在决策树的每个节点需要分裂时,从这些属性中随机抽选出Y个属性(Y< 3. 按照步骤1-2来构建大量的子决策树,这些子决策树就会构成随机森林。 4. 将这个数据集输入不同的子决策树,然后会得到不同的判断结果,统计哪种判断结果最多,则该结果就是随机森林的最佳分类方案。 实例:基于六条测井曲线,对岩性进行划分。训练集如图所示。 数据:训练集由3300个深度的测井曲线以及对应的岩性分类组成。则每一个深度看作一个样本,测井曲线的数值作为特征、岩性作为分类结果。367个深度的测井曲线以及对应的岩性分类作为测试集,测试建立的模型性能。 目的:基于六条测井曲线数据构建一个随机森林模型,用于岩性类型划分。 图2 基于测井数据的岩性识别结果示意图 代码参照斯坦福大学的Andrej Karpathy建立的开源Random Forest编写,全部的代码都是使用MATLAB的基本语言和函数完成,可以有效帮助大家学习随机森林算法。 随机森林的训练主要由以下三个部分完成: 1) forestTrain函数完成随机森林的训练过程,forestTrian中循环调用treeTrain生成决策树组成“森林”,最后将训练结果保存,用来测试新的数据集。 2) treeTrain函数中的决策树为二叉树、根据输入的参数生成内部节点、叶子节点。每个内部节点都是一个弱分类器函数(weakTrain函数),训练若分类器的同时沿树向下继续对数据进行分类。 3) weakTrain函数是一个弱分类器,在本文中我们使用信息增益(分类效果越好,信息增益越大)作为分类标准。 随机森林训练结果的测试主要由以下三个部分完成: 1) forestTest函数接收训练结果以及测试数据,调用treeTest函数进行每棵决策树的判断。 2) treeTest函数循环调用训练好的弱分类器(weakTest函数),逐个节点进行判断分类。 3) weakTest函数作为弱分类器读取已经训练好的分类依据,对接收的数据进行分类。 第一步 数据导入 加载训练和测试数据。 第二步 使用默认参数运行 使用默认参数运行,决策深度为11,决策树数目为100 输出结果 运行结果为 训练集的学习精度:0.88969 训练集的学习精度:0.83333 第三步 对决策深度进行参数调试 这里以决策深度(决策树节点的分裂次数)为例子进行调参。 使用for循环对6~13的决策深度分别进行计算,并可视化。 随着决策深度的增加,训练集的精度不断上升,测试精度的在11以后无大幅度的提升,这表示深度为11时已经达到准确率的最大值。从运行效率上看,深度为13的运行时间约为深度11的2倍,因此我们计算选择11作为最优深度。在测试集中得到85.79%的准确率。 图3:决策树深度与准确率和时间之间的关系 最后需要加以说明的是MATLAB自带的随机森林计算: MATLAB自带的分类学习器工具箱中的Bagged Tree方法是随机森林的一个特例,由于MATLAB的代码是经过并行运算优化性能的,因此速度很快,只需要2.27秒。运行代码可得如下的结果: 训练数据集交叉检验岩性识别精度:90.1515 % 测试数据集岩性识别精度:88.5246 % [1]李欣海. 随机森林模型在分类与回归分析中的应用[J]. 应用昆虫学报,2013,04:1190-1197. 【注】此文章版权归数字地学新视界账号所有(包括但不限于微信、知乎等平台),如需转载务必联系微信公众号后台管理员。否则将维权到底。 关注公众号并联系数字地学新视界微信后台管理员,可领取完整版带有详尽注释的示例代码! [如何获取管理员联系方式]:菜单栏中的联系我们——>转载须知,扫码添加即可。 知识创作分享不易,希望与大家共同成长进步~ 【多见多闻】| 基于随机森林算法的岩性分类实战详解随机森林算法;决策树;测井数据;岩性识别三、实例简述

四、代码解读
4.1 代码框架
4.2 代码运行
%% 数据导入
load traindata.mat
load testdata.mat % 构造参数
depth = 11;
numTrees = 100;
opts = RFopts(depth,numTrees);
% 训练随机森林模型,m为输出
m= forestTrain(traindata(:,1:6), traindata(:,7), opts);% 计算训练集的学习精度
yhatTrain = forestTest(m, traindata(:,1:6));
disp(['训练集的学习精度:' num2str(sum(yhatTrain==traindata(:,7))./3345)])
% 测试集的学习精度
yhatTest = forestTest(m,testdata(:,1:6));
disp(['训练集的学习精度:' num2str(sum(yhatTest==testdata(:,7))./366)])for depth = startDepth:endDepth
opts = RFopts(depth, 100);
m= forestTrain(traindata(:,1:6), traindata(:,7), opts);
yhatTrain = forestTest(m, traindata(:,1:6));
trainAccuracy(order) = sum(yhatTrain==traindata(:,7))./3300;
yhatTest = forestTest(m,testdata(:,1:6));
testAccuracy(order) = sum(yhatTest==testdata(:,7))./366;
end
4.3 MATLAB自带的随机森林计算
五、参考文献

重点重点重点!!!
![]() http://mp.weixin.qq.com/s?__biz=Mzg5MTcyODU4OQ==&mid=2247483704&idx=1&sn=9c6fd2b67bcd66dbf1f1c3b285ed0e3f&chksm=cfc9a69af8be2f8c071137cfa4f8b640b0c1d8a53cf2ac77bb29379b8f77c693b15fa18b7da1#rd
http://mp.weixin.qq.com/s?__biz=Mzg5MTcyODU4OQ==&mid=2247483704&idx=1&sn=9c6fd2b67bcd66dbf1f1c3b285ed0e3f&chksm=cfc9a69af8be2f8c071137cfa4f8b640b0c1d8a53cf2ac77bb29379b8f77c693b15fa18b7da1#rd