上下文无关文法
牛刀小试
antlr4 的安装
上一章节我们简单介绍了一下 antlr4,这一章节,开始讨论 antlr4 的使用和文法。首先简单介绍一下 antlr4 工具的安装和使用参数,非常简单。
-
安装 java 1.7 及以上版本,配置 java 环境变量
-
下载 antlr4 工具
https://www.antlr.org/download/antlr-4.9.2-complete.jar,可以将 antlr4 工具添加到CLASSPATH环境变量中,比如添加到.bash_profile或者.bashrc文件中export CLASSPATH=".:/usr/local/lib/antlr-4.9-complete.jar:$CLASSPATH" -
创建 antlr4 工具的别名
alias antlr4='java -Xmx500M -cp "/usr/local/lib/antlr-4.9-complete.jar:$CLASSPATH" org.antlr.v4.Tool' alias grun='java -Xmx500M -cp "/usr/local/lib/antlr-4.9-complete.jar:$CLASSPATH" org.antlr.v4.gui.TestRig'
温馨提示:antlr4 本身就是 java 来实现的,面向 java 语言的示例非常多,笔者写作的过程中主要使用的是 c++ 语言,后续的所有示例也几乎都是 c++ 语言来实现的。
上述安装完成之后,输入 antlr4,在 terminal 上会出现如下信息
ANTLR Parser Generator Version 4.7.1
-o ___ specify output directory where all output is generated
-lib ___ specify location of grammars, tokens files
-atn generate rule augmented transition network diagrams
-encoding ___ specify grammar file encoding; e.g., euc-jp
-message-format ___ specify output style for messages in antlr, gnu, vs2005
-long-messages show exception details when available for errors and warnings
-listener generate parse tree listener (default)
-no-listener don't generate parse tree listener
-visitor generate parse tree visitor
-no-visitor don't generate parse tree visitor (default)
-package ___ specify a package/namespace for the generated code
-depend generate file dependencies
-D列出几个常用的比较重要的选项进行说明
- -o 选项指定语法分析器生成的目录
- -lib 目录制定语法,tokens 文件的位置
- -encoding 制定语法文件的编码
- -long-messages 现实详细的错误或者告警信息,通常可以配合与 -Werror 一起使用
- -listener 生成监听器接口,默认选项
- -no-listener 不生成监听器接口
- -visitor 生成访问器接口
- -no-visitor 不生成访问器接口,默认选项
- -package 指定生成代码的命名空间,比如 c++ 代码,这就是指定了语法生成器的命名空间 namespace
一个简单识别表达式的例子
我们使用一个简单的例子来展示一下 antlr4 的使用方法和使用效果,语法 2-1 如下所示
grammar Math;
compileUnit
: expr EOF
;
expr
: '(' expr ')' # parenExpr
| op=(ADD | SUB) expr # unaryExpr
| left=expr op=(MUL | DIV) right=expr # mulDivExpr
| left=expr op=(ADD | SUB) right=expr # addSubExpr
| func=ID '(' expr (',' expr)? ')' # funcExpr
| NUM # numExpr
;
ADD : '+';
SUB : '-';
MUL : '*';
DIV : '/';
ID : [a-zA-Z]+ ;
NUM : [0-9]+ ('.' [0-9]+)? ([eE] [+-]? [0-9]+)? ;
WS : [ \t\r\n] -> channel(HIDDEN) ;
这是一段识别简单表达式——加减乘除表达式——的语法。expr 代表表达式,而表达式本身可以是括号括起来的表达式,也可以是加减乘除表达式,还可以是函数调用,数字同样也是表达式,这里就应用到了递归的思想。下面我们来看一下解析的效果。
我们通过 antlr 工具,生成表达式的语法分析器
java -Xmx500M -cp antlr-4.9.2-complete.jar org.antlr.v4.Tool -Dlanguage=Cpp -listener -visitor -o generated/ Math.g4
笔者选择的目标语言是 c++ 语言,所以 antlr4 生成语法分析器是针对 cpp 的。执行上述操作后,在当前目录的 generated 文件夹下会生成如下文件
MathBaseListener.cpp MathBaseVisitor.cpp Math.interp MathLexer.h MathLexer.tokens MathListener.h MathParser.h MathVisitor.cpp
MathBaseListener.h MathBaseVisitor.h MathLexer.cpp MathLexer.interp MathListener.cpp MathParser.cpp Math.tokens MathVisitor.h
生成了监听器接口,访问器接口,因为没有使用 -package 选项,所以没有指定命名空间。下面我们使用一个简单的 main 方法来调用这些接口,代码 2-1 如下所示
int main(int argc, char *argv[]) {
ANTLRInputStream input(argv[1]);
MathLexer lexer(&input);
CommonTokenStream tokens(&lexer);
// show all the tokens
tokens.fill();
for (auto token : tokens.getTokens()) {
std::cout << token->toString() << std::endl;
}
MathParser parser(&tokens);
auto compile_unit_ctx = parser.compileUnit();
std::cout << "text: " << tokens.getText() << std::endl;
std::cout << ((tree::ParseTree*)(compile_unit_ctx))->toStringTree(&parser) << std::endl;
return 0;
}
main 方法中,将命令行参数的第一个参数作为表达式输入,创建 antlr 输入流对象,通过输入流构造 MathLexer 词法对象,进行词法解析,词法将输入流解析成 token 流,将 token 流传递给语法分析器 MathParser 进行语法解析,语法解析结果就是一棵 Parse tree 的树型结构。语法生成器提供了监听器和访问器两种方式对树形结构进行访问。上面的代码,在语法解析器成功解析的情况下,将 token 标记和 Parse tree 都打印出来了,我们尝试对如下的表达式进行解析
10-3/(8-1*4)
结果输出如下
[@0,0:1='10',<9>,1:0]
[@1,2:2='-',<5>,1:2]
[@2,3:3='3',<9>,1:3]
[@3,4:4='/',<7>,1:4]
[@4,5:5='(',<1>,1:5]
[@5,6:6='8',<9>,1:6]
[@6,7:7='-',<5>,1:7]
[@7,8:8='1',<9>,1:8]
[@8,9:9='*',<6>,1:9]
[@9,10:10='4',<9>,1:10]
[@10,11:11=')',<2>,1:11]
[@11,12:11='',<-1>,1:12]
text: 10-3/(8-1*4)
(compileUnit (expr (expr 10) - (expr (expr 3) / (expr ( (expr (expr 8) - (expr (expr 1) * (expr 4))) )))) )
@0 表示第0个位置(从0开始), 0:1 表明在第0-1个字符之间,内容是 ‘10’,token 的 id 是 9, 1:0 表示的是,位于输入字符串第一行,第0个位置处。那么这个 token 的 id 是哪来的呢,这个可以从上面生成的文件 MathLexer.tokens 文件中查看
T__0=1
T__1=2
T__2=3
ADD=4
SUB=5
MUL=6
DIV=7
ID=8
NUM=9
WS=10
'('=1
')'=2
','=3
'+'=4
'-'=5
'*'=6
'/'=7
id 是 9 说明这个 token 是数字 NUM,而
(compileUnit (expr (expr 10) - (expr (expr 3) / (expr ( (expr (expr 8) - (expr (expr 1) * (expr 4))) )))) )
就是语法解析的完整的树形结构,把这棵树整理一下,如图 2-1 所示
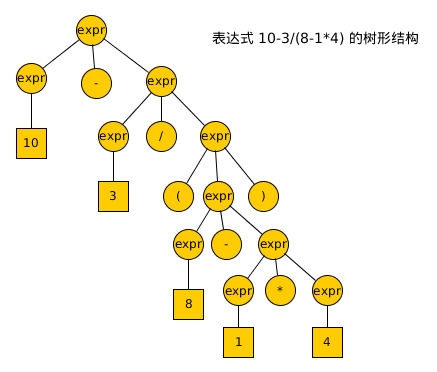
antlr4 就是按照自顶向下的解析方式进行解析,我们可以按照语法 2-1 的描述,将表达式 10-3/(8-1*4) 从左向右展开一下
expr:10-3/(8-1*4)
step1: expr - expr
step2: NUM - expr
step3: NUM - expr / expr
step4: NUM - NUM / expr
step5: NUM - NUM / ( expr )
step6: NUM - NUM / ( expr - expr )
step7: NUM - NUM / ( NUM - expr )
step8: NUM - NUM / ( NUM - expr * expr )
step9: NUM - NUM / ( NUM - NUM * expr )
step10:NUM - NUM / ( NUM - NUM * NUM )
自顶向下的解析方式,就是将语法的左边规则,按照右边的方式进行展开,上面所展示的展开的过程,就相当于图 2-1 所示的树形结构的深度优先遍历。按照这种思维方式,自底向上的解析方式,就是按照语法规则,从右往左进行归约。
这就是 antlr4 语法生成器根据语法生成对应的解析器后,使用该语法解析器进行语法解析的一个过程。这个语法虽然很简单,但是基本能够解析所有加减乘除四则整数运算的表达式。相信大家也能体会到使用 antlr4 工具带来的开发效率的提升,无需关注过多的语法解析方面的实现细节,让我们能够把更多的精力去聚焦在我们需要考虑的业务逻辑方面。
下一小节,我们将重点讲解一下上面描述的这种上下文无关文法。
上下文无关文法
语言是由字符串组成的集合,每一个字符串是由有限字母表中的符号组成的有限序列。对于语法分析而言,字符串是源程序,符号是词法单词,而字母表是词法分析器返回的单词类型集合。
上下文无关文法(context-free grammar),记为 CFG,表示的是一组规则,它描述了语句是如何形成的。对于语言L,其 CFG 定义了表示 L 中的有效语句的符号串的集合。从上下文无关文法 G 中导出的语句集称为 G 定义的语言,记作 L(G)。上下文无关文法定义的语言的集合称之为上下文无关语言的集合。而语句,就是从语法规则导出的一个符号串。
因此,“文法”是用来产生语言(字符串)而不是用来识别语言的。
用文法来定义句子结构,也就是描述单词与单词之间的关系,而上下文无关文法,所定义的所有句子结构之间是没有关系的。比如
expr
: ID '+' ID
;
不需要关心 ID 具体是什么,只需要保证这个 token 是 ID 类型的单词即可。
定义
上下文无关文法是由一组有限的语法规则集合组成,比如下面这则语法规则
A → α A \to \alpha A→α
其中,A 表示非终结符,而位于右边的 α 表示一串终结符或者非终结符,通常,我们把上述这个称之为产生式。与自动机不同,语法是用于产生串而不是识别串的。
上下文无关文法是由一组四元组
G = ( V , Σ , P , S ) G = (V, \Sigma, P, S) G=(V,Σ,P,S)
组成,其中
- V 表示语法符号的有限集合,即 vocabulary
- Σ 表示所有的终结符的集合,是 V 的子集,即
Σ ⊆ V - S 表示起始符号,一般用 S0 表示,
S ∈ (V − Σ) - P 表示所有的语法规则集合,及产生式的集合,
P ⊆ (V − Σ) × V ∗
N = V − Σ 表示的所有的非终结符的集合,所以 P ⊆ N × V ∗。产生式
A → ϵ A \to \epsilon A→ϵ
称之为 ε 规则(epsilon rule, or null rule)。
上下文无关文法还有另一种定义,及
G = ( V N , V T , P , S ) G = (V_N, V_T, P, S) G=(VN,VT,P,S)
其中,
- VN 表示所有的非终结符 non-terminal symbols,与上面定义中的 Σ 对应,即 VN = Σ
- VT 表示所有的终结符 terminal symbols,与 N 对应,所以上面的 V = VT ∪ VN
在这个定义中,
V T ⋂ V N = ∅ V_T \bigcap V_N = \emptyset VT⋂VN=∅
即不存在一个符号,既是终结符又是非终结符
例如这样一个文法
G = ( { E , a , b } , { a , b } , P , E ) (例 2-1) G = (\{E, a, b\}, \{a, b\}, P, E) \tag {例 2-1} G=({E,a,b},{a,b},P,E)(例 2-1)
其中,P 由下面这组规则组成
E → a E b E → a b E \to a E b \\ E \to ab E→aEbE→ab
上面这两个产生式,可以产生出
L ( G ) = { a n b n ∣ n > = 1 } L(G) = \{a^nb^n | n >=1\} L(G)={anbn∣n>=1}
的语言 L(G)
产生式
关于上下文无关文法,最简单的解释就是重写规则。文法的产生式就是重写规则。我们可以将 CFG 看成是从开始符号 S 开始,不断的利用产生式的规则,利用右边对左边进行展开重写的过程。
比如例 2-1 的文法规则,我们将 E 进行重写,过程如下
E -> aEb
E -> aaEbb
E -> aaaEbbb
E -> aaa...E...bbb
E -> aaa...ab...bbb
aabb 是由这个文法产生的一个串,而 aaabbb 也是由这个文法产生的一个串。我们以 aaabbb 这个串为例,以最左推导的方法看下文法是如何推导的
E -> aEb
E -> aaEbb // 将中间的 E 替换成 aEb
E -> aaabbb // 将中间的 E 替换成 ab
完成推导
最左推导就是不断的从左边开始推导的过程,同理,还有最右推导。
描述方式
在上面的定义中,P 就是产生式集合,那么如何来描述这样规则集合呢,通常我们使用巴克斯诺尔范式来描述。
巴克斯诺尔范式(Backus Naur Form),简称 BNF,是以美国人巴科斯(Backus)和丹麦人诺尔(Naur)的名字命名的一种形式化的语法表示方法,用来描述语法的一种形式体系,是一种典型的元语言。BNF 的一般形式为
::=
non-terminal 表示的是非终结符,:: 表示推导符号,相当于上一小节中向右的箭头,而 replacement 由一个符号序列,或用指示选择的竖杠 '|' 分隔的多个符号序列构成,每个符号序列整体都是左端的符号的一种可能的替代。从未在左端出现的符号叫做终结符。比如例 2-1 中的两个产生式,用 BNF 范式描述为
E :: a E b;
E :: a b;
在 一个简单识别表达式的例子 这一小节中,表达式的文法,就是采用的 BNF 范式来描述的,这也是 antlr4 中所支持的标准写法。
antlr4 文法
在 antlr4 中,我们使用的文法规则,都是通过巴科斯诺尔范式来描述的。通常,在书写文法规则时,将文法分成两个文件,一个是词法描述文件,一个是语法描述文件,我们以 语法 2-1 为例,来改写一下,将其中的词法描述和语法描述分开,分别在不同的文件中进行描述。词法文件名为 ExprLexer.g4,语法文件名为 ExprParser.g4。在 antlr4 中,语法文件的后缀都是 g4。
词法
lexer grammar ExprLexer;
ADD : '+';
SUB : '-';
MUL : '*';
DIV : '/';
ID : [a-zA-Z]+ ;
NUM : [0-9]+ ('.' [0-9]+)? ([eE] [+-]? [0-9]+)? ;
WS : [ \t\r\n] -> channel(HIDDEN) ;
在上面的词法文件中,最开始一行为词法名称定义,表明这是一个词法描述文件,词法名称为 ExprLexer,该名称必须与词法文件名相同,否则 antlr4 在生成语法分析器时会提示错误。
ADD/SUB/MUL/DIV 是词法中定义的 token 标记,内容就是 : 后实际表示的串。在生成语法分析器时,每一个 token 都会被赋予一个整型值,作为 token 的唯一 id。在 token 的定义中,还支持正则表达式的方式,ID 和 NUM 这两个 token 就是使用的正则表达式来描述的。
词法中的 token 标记名称,必须以大写字母开头,一般认为,token 名称都是全大写的书写方式。
最后一个 token,表示的是空白符号,比如空格,制表符 tab,回车和换行,channel 为 HIDDEN 表示在语法解析阶段,语法分析器会将该 token 进行忽略。
在词法规则定义中,一个词法规则,可以分成若干个词法子规则,通过 | 进行连接,形式如下
TOKEN_NAME: TOKEN1 | TOKEN2 | TOKEN3 ... ;
同时,这些子规则也不一定必须是 TOKEN,可以是 fragment 定义的规则,比如我们定义数字和浮点数
INTEGER : DIGIT+ ;
FLOAT_NUM: DIGIT* '.'? DIGIT+;
fragment DIGIT: [0-9];
由 fragment 定义的规则 DIGIT 表示 0-9 之间的任意一个数字,而 INTEGER 和 FLOAT_NUMBER 这两个 TOKEN 就是通过 DIGIT 组成的。
语法
语法描述文件内容如下
parser grammar ExprParser;
options {
tokenVocab=ExprLexer;
}
compileUnit
: expr EOF
;
expr
: '(' expr ')' # parenExpr
| op=(ADD | SUB) expr # unaryExpr
| left=expr op=(MUL | DIV) right=expr # mulDivExpr
| left=expr op=(ADD | SUB) right=expr # addSubExpr
| func=ID '(' expr (',' expr)? ')' # funcExpr
| NUM # numExpr
;
同理,第一行定义了语法名称,该名称必须与语法文件名保持一致。在 options 选项定义中,指明了引用的词法为 ExprLexer,这个词法在 ExprLexer.g4 中进行了定义。
在 expr 表达式的语法规则描述中,冒号表示的是产生式中的推导符号,左边部分表示的语法规则名称,必须以小写字母开头,右边表示的替换规则。'(' 表示的是终结符左括号,可以在语法中直接这样写,但是这种写法不推荐,应该在词法中定义左括号的 token 为
LEFT_PAREN : '(' ;
然后在语法规则定义中,使用 token 而不是直接使用 '(' 。expr 表达式的描述中,存在多个语法分支,不同语法分支使用 | 进行分隔。如果想要对不同分支进行不同的处理方式,就像上面所展示的那样的,通过
# branch_name
的方式添加标签,这样,antlr4 生成语法分析器时,会将每一个 branch_name 分开单独进行处理。这种方式使得代码处理更加有条理性。
如果不添加标签,antlr4 为 expr 生成的类中,就只有 ExprContext 这一个类,里面包含所有的成员和操作方法
class ExprContext : public antlr4::ParserRuleContext {
public:
ExprContext(antlr4::ParserRuleContext *parent, size_t invokingState);
ExprContext() : antlr4::ParserRuleContext() { }
void copyFrom(ExprContext *context);
using antlr4::ParserRuleContext::copyFrom;
...
};
但是加上标签之后,会分别为每一个标签生成一个对应的类,然后继承自 ExprContext,比如
class UnaryExprContext : public ExprContext {
public:
UnaryExprContext(ExprContext *ctx);
antlr4::Token *op = nullptr;
ExprContext *expr();
antlr4::tree::TerminalNode *ADD();
antlr4::tree::TerminalNode *SUB();
virtual void enterRule(antlr4::tree::ParseTreeListener *listener) override;
virtual void exitRule(antlr4::tree::ParseTreeListener *listener) override;
virtual antlrcpp::Any accept(antlr4::tree::ParseTreeVisitor *visitor) override;
};
这样就可以对每一个标签指定的规则分开单独进行处理
在语法定义中,比如
left=expr op=(MUL | DIV) right=expr # mulDivExpr
当一个非终结符出现多次时,比如 expr ,如果需要进行区分,可以在需要区分的非终结符前面加上一个标签如 left 和 right,这样,通过标签就能直接访问到这个非终结符所表示的串。但是需要注意的是,标签定义只能存在于单个终结符或者非终结符中,或者由这些终结符或者非终结符通过 | 组成的子规则中,比如上面的 op 标签,就是合法的,如果是
op=(MUL | DIV | MUL EQUAL)
这样的定义就是非法的,因为子规则的第三个分支中的终结符多于 1 个,同样的规则适用于非终结符。
语法定义中常见符号的含义
?- 表示该终结符或者非终结符可选,可以存在,也可以不存在*- 表示该终结符或者非终结符存在 0 个或者多个+- 表示该终结符或者非终结符存在 1 个或者多个- 括号括起来的规则,表示一组子规则,比如上述的
op=(MUL | DIV) []- 表示任意一个中括号内的字符//- 表示行注释/* ... */- 表示块注释
语法文件的编写,就类似代码一样,对于相同的部分,是可以做到复用的。比如有两个 XXParser.g4 的语法文件,如果表达式部分的语法是相同的,那可以将表达式单独成一个 Expr.g4 文件,在其余需要用到的地方,直接引用即可,通过 import 来达到引用的效果
import Expr.g4;
看懂文档中的文法描述
在很多数据库或者编程语言的文档资料说明中,会通过图或者文字的方式来对语法进行描述,要学会能够看懂这些文法所表示的含义,并且能够转化成我们需要的 BNF 形式的上下文无关文法。如图 2-2 所示

这是一个 oracle 查询语法描述的 common table expression 部分,描述的是 with 子查询的语法。首先必须是 WITH 关键字,然后是一个通过逗号分隔的列表,这个列表中的每一个元素,是一个查询名称 query_name,然后是一个可选的选项,该选项是一个小括号括起来的,逗号分隔的多个别名 c_alias,紧接着是 AS 关键字,然后是小括号括起来的子查询。接着后面是两个可选的选项,分别是 search_clause 和 cycle_clause。
我们试着用 BNF 的形式来描述上述语法
subquery_factoring_clause
: WITH cte (COMMA cte)*
;
cte
: query_name (LEFT_PAREN c_alias (COMMA c_alias)* RIGHT_PAREN)? AS LEFT_PAREN subquery RIGHT_PAREN search_clause? cycle_clause?
;
词法部分的描述为
WITH : 'WITH' ;
LEFT_PAREN : '(' ;
RIGHT_PAREN : ')' ;
COMMA : ',' ;
这样,就把上图中的语法,转化成了 BNF 形式的上下文无关文法。
该语法的文字形式的描述为
WITH
query_name ([c_alias [, c_alias]...]) AS (subquery) [search__clause] [cycle_clause]
[, query_name ([c_alias [, c_alias]...]) AS (subquery) [search_clause] [cycle_clause]]...
文字描述中,小括号括起来的若干个规则,表示一个子规则。而中括号就表示可选的含义。
上图中的语法描述中,出现了列表,关键字,可选项等多种情况,一个规则可以包含所有这些形式的子规则,每一个子规则对应的语法如 表 2-1 所示
| 语法 | 说明 |
|---|---|
 |
rule: (x | y | z) …; |
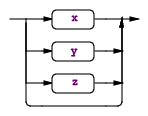 |
x,y,z 分别是三种子规则,最下面一条直通没有任何规则的线条,表示是可选的,语法对应为 rule : (x | y | z)? …; |
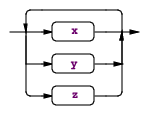 |
最上面往回指向的箭头,表明子规则存在一个或者多个,如果往回的线条上面有一个 ,,说明多个子规则通过逗号分隔。rule : (x | y | z)+ ... ; |
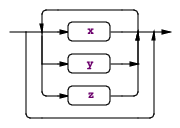 |
同上,但是最下面一条箭头,表示可选rule : (x | y | z)* ... ; |
注意:
*,+,?这三个符号作为语法规则的后缀是可以组合使用的,比如rule+?,说明 rule 这个规则存在一个或者多个,而?的出现,恰恰又说明rule+这个规则是可选的,这个时候,通过rule*就可以直接表示这个规则。同理,对于rule*?这种表示方法来说,本身*就存在 0 个或者多个的意思,?的表示就显得有点多余。这些表示,在上表图形的表示方法中,就能一目了然的看出来。所以大家在写语法的时候,还是需要多加思考,就像重构代码一样,对语法多进行优化。借助工具检测语法也是一个很好的选择,常见的 antlr4 语法 IDE 就是 antlrwork
参考资料
- 编译器设计第二版,3.2.2节
- 现代编译原理 3.1节
- http://cs.union.edu/~striegnk/courses/nlp-with-prolog/html/node37.html
- https://www.cis.upenn.edu/~jean/gbooks/tcbookpdf2.pdf
- 巴科斯范式
- https://github.com/antlr/antlr4/blob/master/doc/