2021:AdaVQA: Overcoming Language Priors with Adapted Margin Cosine Loss∗自适应的边缘余弦损失解决语言先验
摘要
现有的VQA模型都有严重的语言先验问题,然而,尽管现有VQA方法都将VQA视为一个分类任务,但是目前还没有研究从答案特征空间学习的角度解决此问题。因此,我们设计一个自适应的边缘余弦损失以正确区分每个问题类型下的频繁和稀疏答案特征空间,因此,语言模态中的有限制的模式在很大程度上减少了,我们的方法引入的语言先验也将更少。我们将该损失函数应用到基线模型中,并在两个VQA-CP基准上评估有效性,实验结果表明我们的自适应的边缘余弦损失可以极大提高基线模型,平均获得15%的绝对增益,从答案特征空间学习角度有效的验证了解决语言先验的潜力。
一、介绍
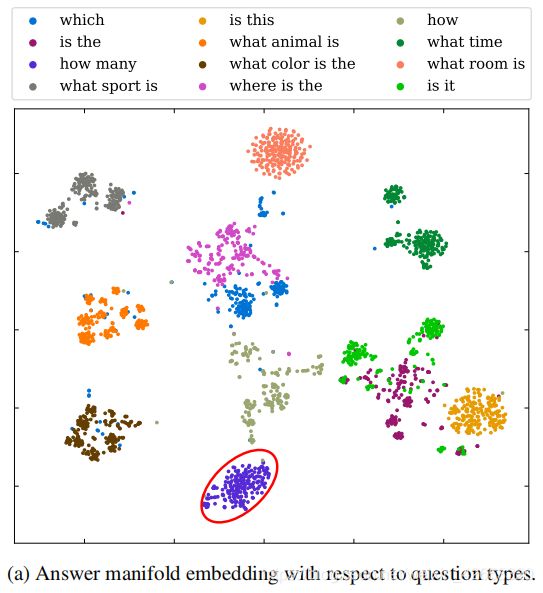
战胜语言先验问题的很多努力可以被大致分为两类:1)平衡有偏见的数据集;2)纠正VQA模型。我们认为,从有偏见的数据集中学习到的特征空间无法明确的区分答案,并且是减轻语言先验影响的关键。我们在图1b中可视化了问题类型how many的答案的2维嵌入特征,可以看到在这两种特征空间中,基线的不同答案实际上是相互交织在一起的,在这一现象的基础上,我们进一步假设:如果我们通过操纵答案所学习到的特征空间正确地分离答案,这对克服语言先验有益?
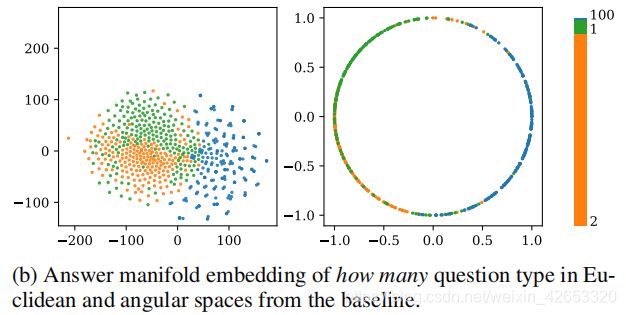
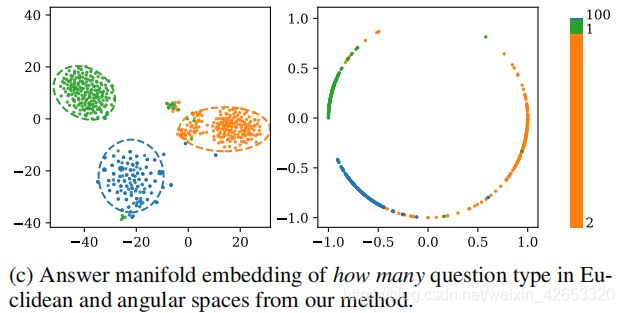
这项工作的主要目标是在相应的问题类型下为角度空间中的不同答案引入一个自适应的边缘,它可以有效分离答案嵌入。为此,我们首先通过L2标准化答案特征x和权重向量Wi,将softmax损失函数重述为一个余弦损失,决策边界可以通过x和Wi间角度的余弦函数计算,之后采用一个适应的边缘mi来分离答案特征,其中mi是基于相应问题类型下答案ai的训练集统计量来计算。理想情况下,对于每个给定的问题及相应的问题类型,频繁的答案在较小边缘的角度空间中更宽,而稀疏的答案在较大边缘的角度空间中跨度更紧密(图1c)。
二、相关工作
三、方法
3.1 问题定义
对于一个关于图像的问题,目标函数为:
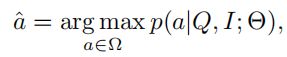
每个实例中都可以有多个正确答案。负log似然损失函数被表示为:
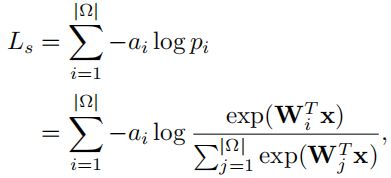
其中,W和x分别表示与答案预测直接相邻的权重矩阵和特征向量;ai∈[0,1]表示相应的答案标签。我们删除了偏置向量,因为我们发现它对模型性能贡献很小。
3.2 方法的直觉
具体地说,我们根据训练集的统计数据,提出一个可适应的边缘来分离角度空间中的答案嵌入。欧几里得空间比角度空间更复杂。基于此,我们首先利用权向量Wi和特征向量x的L2标准化来确保后验概率(由Wi和x间的角度确定)(答案特征空间从欧几里得空间转换为角度空间)。因此,可以获得修改后的归一化Softmax损失(NLS):
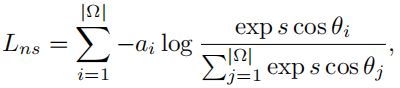
s是更稳定计算的尺度因子,为实现一个更具区别性的分类边界,LMLC向NSL引入了一个固定的余弦边界:
![]()
m是固定的余弦边缘。
然而,应用一个固定余弦边缘不能得到令人满意的结果,主要原因是,每种问题类型的答案分布都是高度有偏见的,导致无法学习角空间中具有固定边缘的充分表示。下面将介绍一个更复杂的适应的边缘余弦损失来克服这个问题。
3.3 AdaVQA
基于以上观察,我们认为一个适应的余弦边缘更有利于克服VQA中的语言先验。一个新的损失函数被详细定义为:

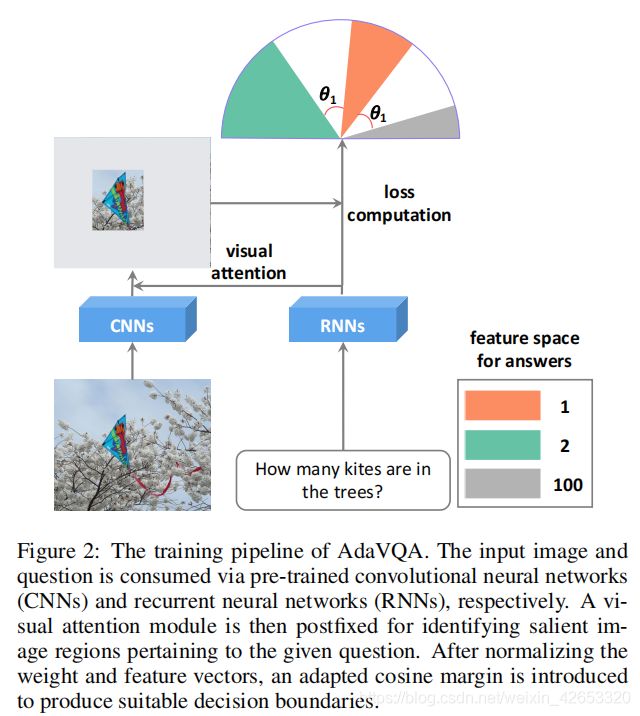
mi是基于给定问题类型的答案i的适应边缘,nki表示训练集中问题类型qtk下的答案i数,=1e−6是一个避免计算溢出的超参数。这背后的直觉是,对于当前给定的问题及其相应的问题类型,频繁的答案在角空间中跨度更广(较小的边距),而稀疏的答案跨度更紧密(更大的边距)。以图1c为例,答案2比训练集中其他答案更频繁,从而导致我们期望的更大的特征空间。图2中提供了AdaVQA的一般训练管道,其中基于提出的损失函数学习三个答案(1,2,100)的特征空间。
然而,人们可能会担心,这种边缘限制可能会损害类型间的歧视,因此,我们获得了关于其问题类型的答案嵌入,并在图1a中可视化。可以观察到与问题类型相关的决策边界,一个可能的原因是,每个答案的余弦边缘是根据给定问题类型下的训练集统计量计算出来的,而这个问题类型之外的其他答案不受影响。这种经验设置固有地增强了模型在不同问题类型之间的辨别能力。
(1)熵的阈值:并不是相应问题类型中的所有问题都会导致语言先验的问题,我们建议在每个问题类型上使用一个熵阈值,正则化应考虑问题类型熵大于阈值的问题。每种问题类型的熵被定义为:
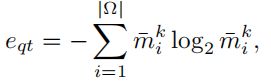
其中¯mki实际上是训练集中问题类型qtk下答案i的发生概率。
(2)偏导数:进一步利用损失函数提供权向量Wi和特征向量x的偏导数。
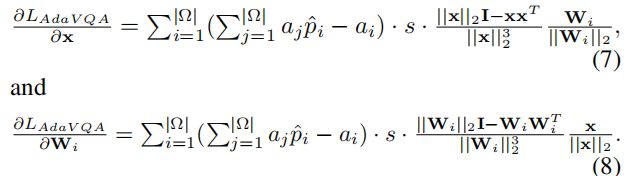
(3) s的边界下限:太小的尺度因子s导致收敛不足,因为它限制了特征空间跨度。鉴于这一点,应该规定s的下界。如果不失去一般性,让Pi表示答案类i的期望最小值。因此,我们有,

3.4 与不同损失函数的比较
我们考虑二元类场景来直观地说明来自不同损失函数的决策边界。如图3,决策边界可以为普通SoftMax的负值,将其扩大为等于NSL损失的零。LMLC定义了不同类的固定边界,这在我们的例子中不适用于克服语言先验问题。关于我们的AdaVQA,更稀疏的答案(绿色的)包含较小的特征空间,而更频繁的答案(橙色的)包含更大的特征空间。

四、实验
4.1 实验设置
(1)数据集:VQA-CP v2和VQA-CP v1
(2)评估指标:
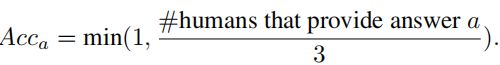
(3)实现细节:将我们的AdaVQA应用于三个基线:Strong-BL,Counter和UpDn,这些方法采用了普遍的视觉注意力。与VQA中克服语言先验问题的大多数方法不同,对于所有三个基线,我们只是用AdaVQA替换了原始损失,并且没有改变任何其他设置,如嵌入大小、学习率、优化器和批处理大小。
4.2 实验结果
(1)总体结果
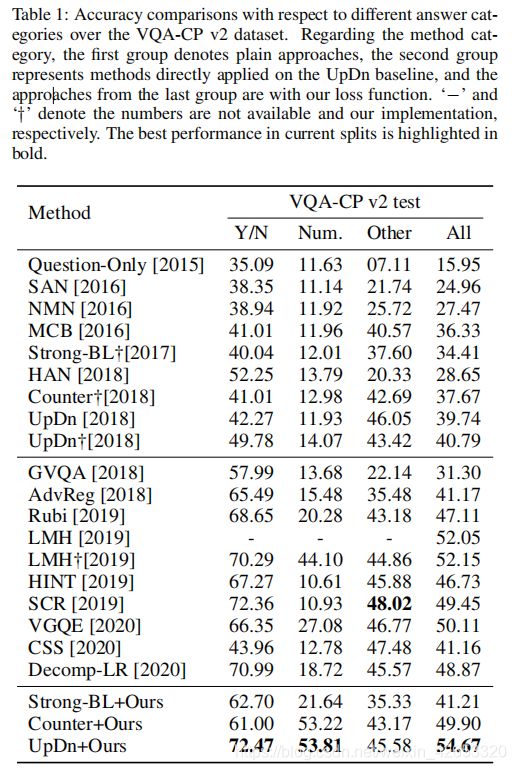
我们的方法只有在other上没有取得最好的结果,可能原因是other类的问题大多以What开头,因此答案比其他类别更多元化,因此引入的语言先验较少,因为答案的偏见较少。对于三种基线,Strong-BL,Counter和UpDn,当应用我们的损失函数,性能显著提升(约15%)。与其它主干模型也是UpDn的方法相比,我们的方法(UpDn+Ours)以很大优势超过它们,尤其是三种新的方法VGQE,CSS和Decomp-LR。

(2)消融研究
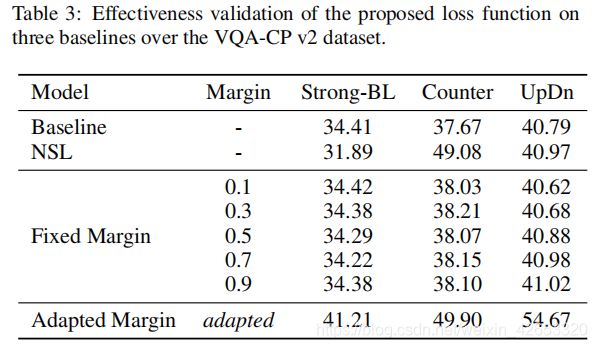
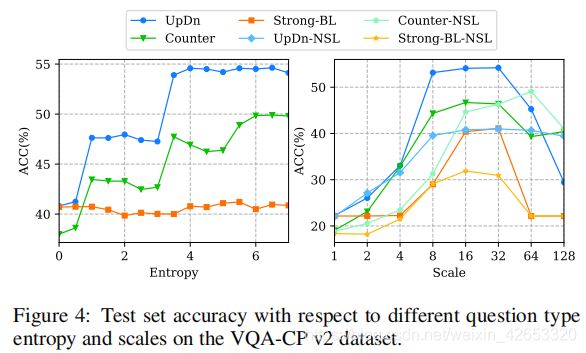
表3中,当在权重向量和特征向量上使用L2标准化时,即NSL,在不同方法上的结果不一致,如在使用NSL的Counter上超过基线11.41%,然而在NSL的Strong-BL上导致性能略有下降。
然后,我们利用固定边缘产生有效的特征区分,边缘从0.1到0.9,步长为0.2,然而,结果并不理想,验证一个固定的边缘不适合克服语言先验问题。相反,当使用一个适应的边缘时,模型可以大幅优化固定边缘的模型,进一步证明了AdaVQA的优越性。
图4中调查了问题类型熵和尺度的影响,我们发现,应考虑一个适当的熵,因为太大的熵不会带来更多的收益,甚至会导致性能下降。太小的尺度对于学习特征空间是不充分的,而太大也会导致不满意的结果。
(3)实例研究

第一个例子中,我们的AdaVQA纠正了基线产生的错误答案,产生了一个更合理的注意力图。第二个例子中,基线模型回答了答案集中最常见的答案,并且人们对猫的区域关注太多了,这也是导致错误答案的另一个原因,因为猫的毛是白色和黑色。相反,我们的AdaVQA可以引导模型更多的关注目标对象-行李,从而得出正确答案。
五、结论
我们从答案特征空间学习的角度解决VQA的语言先验问题,我们设计一个适应的边缘余弦损失,通过适当地表征答案特征空间来区分答案。具体来说,对于给定的问题,关于相应问题类型的频繁和稀疏答案分别被学习在角度空间上跨越更宽和更紧密的范围。在两个基准上进行的广泛实验验证了在三个基线上所提出的损失函数的有效性。
然而,这项工作并没有提出一个在VQA中追求SOTA结果的先进模型,相反,我们期望,随着这种适应的边缘余弦损失,特征研究可以更关注视觉推理的能力,而不受语言先验的影响。