手撕六大经典排序算法(Java代码实现)
文章目录
- 前言
- 关于排序
- 一、直接插入排序(Insertion Sort)
- 二、希尔排序(Shell Sort)
- 三、冒泡排序(Bubble Sort)
- 四、快速排序(Quick Sort)
- 五、简单选择排序(Selection Sort)
- 六、堆排序(Heap Sort)
前言
最近在鼓捣 Java基础 的时候想到,为何不用 Java 来实现一下之前学习 C语言版数据结构 中的排序算法呢?因此我又拿起了垫电脑的 《数据结构》 和在网上看了几篇比较好的文章,便开始了练习之旅,并在这里总结和分享重学排序算法的体会
在本文中具体的步骤都会用代码实现,代码中比较隐晦的代码段都用了注释进行解释,因此代码部分可能会比较长,还请见谅。
若文中哪里存在问题,欢迎大家伙们评论留言指点指点(~ 罒㉨罒 ~)
关于排序
1.、排序的定义
将一序列的数据按照需求将其排列成具有特定的顺序,这一操作便称为排序
2、排序涉及术语
- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
- 不稳定:如果a原本在b前面,而a=b,排序之后a有可能会出现在b的后面;
- 内排序:所有排序操作都在内存中完成;
- 外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
- 时间复杂度:描述算法运行时间的函数,用大O符号表述;
- 空间复杂度:描述算法所需要的内存空间大小。
3、排序分类
排序分为内部排序和外部排序,在本文中主要对内部排序中的前六种详细总结

4、排序性能分析
平均性能表现最好的是快排,但是实际生产中,最好的算法一定是结合数据集本身的特点(大小,长度,是否已经基本有序等等)来选择的,不要拘泥于算法本身,并没有一种算法是完美无缺的,不能因为一种算法而否定了其他算法

5、排序算法的选择
- 若n较小(如n≤50),可采用直接插入或简单选择排序。
- 若文件初始状态基本有序(指正序),则应选用直接插入、冒泡或随机的快速排序为宜;
- 若n较大,则应采用时间复杂度为O(nlgn)的排序方法:快速排序、堆排序或归并排序。
一、直接插入排序(Insertion Sort)
1、直接插入排序定义
直接插入排序的算法描述是插入排序中一种稳定的简单直观的排序算法。
核心思想为:先将当前数值抽取出来,如果比前面一个数值小 (大),则前方数值后挪,最后将抽取出来的数值插入到空缺的位置
最佳情况:T(n) = O(n) 最坏情况:T(n) = O(n2) 平均情况:T(n) = O(n2)
2、动图演示
3、代码实现
/**
* 插入排序
* 从-2开始是因为零号单元格是哨兵
* 一号单元格为第一个数值,没有前方数值
* @param array
* @return
*/
public static int[] insertionSort(int[] array) {
for (int i = 2; i < array.length-1; i++) {
int minIndex = i; //标识当前下标
array[0] = array[minIndex]; //标识当前数值
while(array[0] < array[minIndex-1] && minIndex > 0) { //用标识的数值逐一和前方的数值进行比较
array[minIndex] = array[minIndex-1];
minIndex--;
}
array[minIndex] = array[0];
}
return array;
}
4、运行结果
二、希尔排序(Shell Sort)
1、希尔排序的定义
希尔排序是插入排序中的一种不稳定的排序算法,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破O(n2)的第一批算法之一。它与插入排序的不同之处在于,它会优先比较距离较远的元素。
核心思想为:先选定一个小于N的整数 gap 作为第一增量,然后将所有距离为 gap 的元素分在同一组,并对每一组的元素进行直接插入排序。然后再取一个比第一增量小的整数作为第二增量,重复上述操作直到增量等于1的时候就相当于整个序列被分到一组,进行一次直接插入排序,排序完成。
最佳情况:T(n) = O(nlog2 n) 最坏情况:T(n) = O(nlog2 n) 平均情况:T(n) =O(nlog2n)
2、图片演示
由于狗子本人着实没找到让我眼前一亮的动图,就自己动手搞了一张静态的图片,莫见怪(╚(⊙ω⊙)╝)
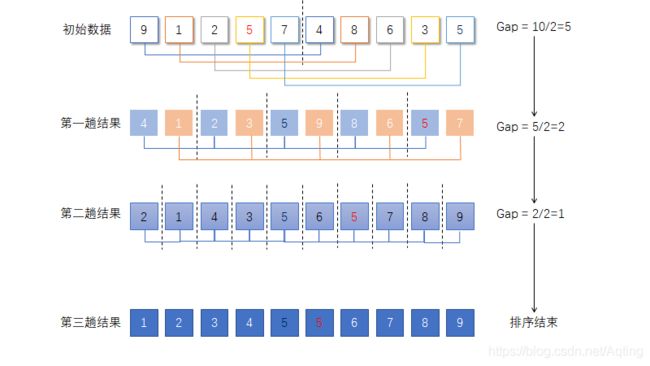
3、代码实现
/**
* 希尔排序
* @param array
* @return
*/
public static int[] shellSort(int[] array) {
for (int gap = (array.length-1)/2; gap > 0; gap /= 2) { //外层控制增量gap
/*
* 细节在于小于array.length-gap而不是小于gap
* 这是为了控制最后一次比较是和最后一个数值比较
* (当i等于范围内最大值时,后面还有gap个数值)
*/
for (int i = 1; i < array.length-gap; i++) {
int minIndex = i; //默认当前指到的数值的前一个是最小的
array[0] = array[minIndex + gap]; //存放当前指到的数值用作寻找比其大的数
/*
* 由于零号单元是哨兵岗,因此minIndex最小值只能是1
* 即最小值只能是每个组中的最前面那个
* 用当前指到的数值和前面的数值进行比较
* 判断是否前面的为小值,当前指到的数为大值
*/
while(minIndex > 0 && array[0] < array[minIndex]) {
array[minIndex + gap] = array[minIndex];
minIndex -= gap;
}
array[minIndex + gap] = array[0]; //由于最后减多了一个gap,因此要加上一个gap
}
}
return array;
}
4、运行结果
三、冒泡排序(Bubble Sort)
1、冒泡排序的定义
冒泡排序是交换排序中一种稳定的简单排序算法。通过每一趟的排序下来,相对最大的数会如同气泡一样浮起来,因此这一排序很形象的被称为冒泡排序。
核心思想为:运用两层循环,外层循环控制排序的趟次,内层循环通过对前后两个数大小进行比较,逐一将最大(小)值挪至最后(前)从而完成排序。在算法中可以加入一个 flag ,用于判断数列初始是否处于有序或基本有序,从而达到优化的效果
最佳情况:T(n) = O(n) 最差情况:T(n) = O(n2) 平均情况:T(n) = O(n2)
2、动图演示
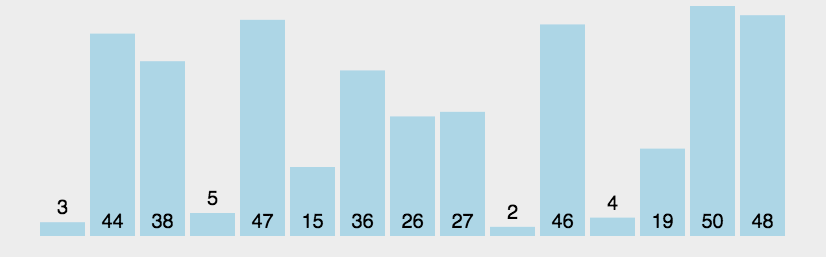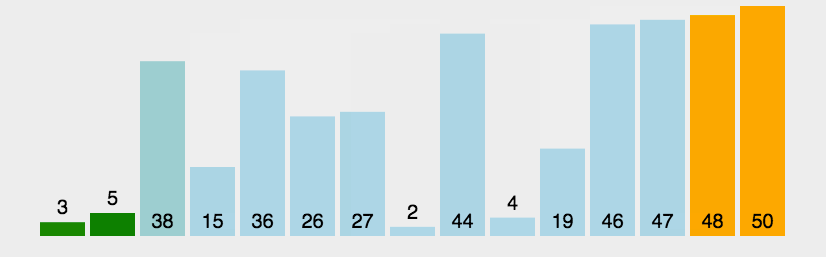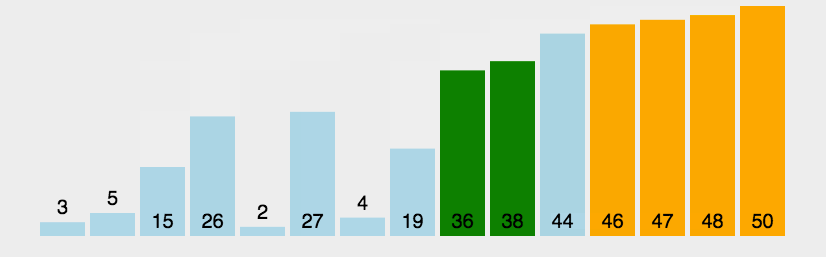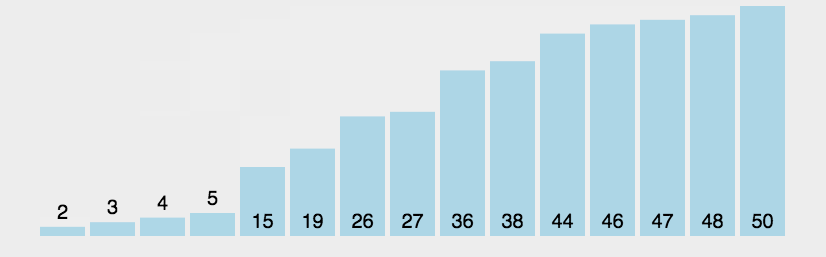
3、代码实现
/**
* 冒泡排序
* 前后两个数值进行比较
* 将最大(小)值逐一挪到后面完成排序
* @param array
* @return
*/
public static int[] bubbleSort(int[] array) {
//从一开始是因为零号单元为哨兵
for (int i = 1; i < array.length-1; i++) {
boolean flag = true; //用于标识是否后方的数值是有序的
for (int j = 1; j < array.length-i; j++) {
if(array[j] > array[j+1]) { //大于号时为升序排序,反则降序
array[0] = array[j];
array[j] = array[j+1];
array[j+1] = array[0];
flag = false; //若交换了则说明后方的数值存在无序
}
}
if (flag) { //若后方数值是有序的话直接退出循环
break;
}
}
return array;
}
4、运行结果
四、快速排序(Quick Sort)
1、快速排序的定义
快速排序是交换排序中一种不稳定的排序算法,它是冒泡排序经过改进之后更高效的版本,常常也被称为“快排”。
核心思想:快排的形式有很多种,有递归的也有非递归的,在这里用了递归算法下的挖坑法(结合我自己常用的方法和网上一些好的文章进行了一定的修改)
- 选出一个数据(一般是最左边或是最右边的)存放在
key变量中,在该数据位置形成一个坑。 - 定义一个
L和一个R,L 从左向右走,R 从右向左走。需要注意的是若在最左边挖坑,则需要 R 先走;若在最右边挖坑,则需要 L 先走。 - 在走的过程中,若 R 遇到小于 key 的数,则将该数抛入坑位,并在此处形成一个坑位,这时L再向后走;若遇到大于key的数,则将其抛入坑位,又形成一个坑位。如此循环下去,直到最终L和R相遇,这时将 key 抛入坑位即可。
- 经过一次单趟排序,最终使得 key 左边的数据全部都小于 key,key 右边的数据全部都大于 key。
- 将 key 的左序列和右序列再次进行这种单趟排序,如此反复操作下去,直到左右序列只有一个数据,或是左右序列不存在时,便停止操作。
最佳情况:T(n) = O(nlogn) 最差情况:T(n) = O(n2) 平均情况:T(n) = O(nlogn)
2、动图演示
3、代码实现
/**
* 快排
* @param array
* @param Left
* @param Right
* @return
*/
public static int[] quickSort(int[] array, int Left, int Right) {
if(Left < Right) { //避免序列中只有一个数据,加一减一都是因为分割位置中的数据是为序列中的中位数,不需要再进行比较了
int partition = partition(array, Left, Right); //确定左右序列的分割位置
quickSort(array, Left, partition-1); //对左序列进行排序
quickSort(array,partition+1, Right); //对右序列进行排序
}
return array;
}
/**
* 寻找 partition 值
* @param array
* @param Left
* @param Right
* @return
*/
public static int partition(int[] array, int Left, int Right) {
int keyIndex = Left; //标识坑位所在下标
array[0] = array[keyIndex]; //存放最左值,充当 key 的作用
while(Left < Right) {
while(Left < Right && array[Right] > array[0]) { //遍历寻找小值
Right--;
}
array[keyIndex] = array[Right]; //将比 key(array[0])小的数放在坑位上
keyIndex = Right; //更新坑位下标
while(Left < Right && array[Left] < array[0]) { //遍历寻找大值
Left++;
}
array[keyIndex] = array[Left]; //将比 key(array[0])大的数放在坑位上
keyIndex = Left; //更新坑位下标
}
array[keyIndex] = array[0]; //将抽取出去的 key(array[0]) 存放在坑位中
return keyIndex; //返回坑位下标
}
4、运行结果
五、简单选择排序(Selection Sort)
1、简单选择排序的定义
简单选择排序是选择排序中一种简单直观的排序算法,通过控制代码中的细节可以控制该算法是否为稳定的排序算法。值得注意的是它的时间复杂度是最稳定的,都是O(n²),因此在使用简单选择排序的时候,数据规模越小越好。
核心思想:定义一个最小值下标 minIndex 用于记录每一次遍历过程中相对最小值的下标。通过两层循环,外层循环控制当前指向的数据,内层循环则进行遍历寻找最小值更新 minIndex,从而完成排序
最佳情况:T(n) = O(n2) 最差情况:T(n) = O(n2) 平均情况:T(n) = O(n2)
2、动图演示

3、代码实现
/**
* 选择排序
* 逐一选择最小(大)的数值,然后进行交换
* @param array
* @return
*/
public static int[] selectionSort(int[] array) {
//从一开始是因为零号单元格为哨兵
for (int i = 1; i < array.length-1; i++) {
int minIndex = i;
for (int j = i+1; j < array.length; j++) {
if(array[j] < array[minIndex]) {
minIndex = j; //最小值下标更新
}
}
if(minIndex != i) { //当最小值下标变化时才进行交换
array[0] = array[minIndex];
array[minIndex] = array[i];
array[i] = array[0];
}
}
return array;
}
4、运行结果
六、堆排序(Heap Sort)
0、堆的定义
若 n 个元素的序列{a1, a2, … , an} 满足

则分别称该序列{a1, a2, …, an} 为 小根堆 和 大根堆。
了解过完全二叉树的大家伙们应该可以看出,堆的实质是满足如下性质的完全二叉树:二叉树中任一非叶子结点均小于(大于)它的孩子结点
1、堆排序的定义
堆排序是选择排序中利用堆进行排序的不稳定的一种排序算法。若在输出堆顶的最小值(最大值)后,使得剩余 n-1 个元素的序列又建成一个堆,则得到 n 个元素的次小值(次大值)。通过反复进行上述操作,便能得到一个有序序列,这个过程称之为堆排序
实质上,堆排序就是利用完全二叉树中等个父结点与孩子结点之间的内在关系进行排序的。其存储形式是顺序存储,逻辑结构则是二叉树。
核心思想:在堆排序中主要有三个核心步骤,分别为堆的建立、调整和排序。
- 堆的建立:由堆的定义和二叉树的特征可知:单结点的二叉树是堆,在完全二叉树中所有的叶子结点(序号i > n/2)也是堆。因此我们只需要依次将以序号为n/2、n/2 - 1、…、 1 的接电为根的子树均调整为堆即可。
- 堆的调整:堆的调整可谓是重中之重,因为堆的建立也是建立在堆的调整之上的。以小根堆为例,大根堆类似:
- 输出堆顶元素之后,以堆中最后一个元素替代堆顶元素
- 将根接电值与左、右子树的根节点值进行比较,并与其中的最小值进行交换
- 重复上述操作,直到遇到叶子结点,将得到新的堆,我们也将从堆顶至叶子的调整过程称为 “筛选”
- 堆的排序:每次调整好一个堆之后,将堆顶的值与堆中最后一个元素交换从而固定最小值(最大值),固定好之后的元素将不会参与到后续的排序中。由于每次堆顶元素都放在参与排序的元素的最后,因此当我们建的是大根堆时,输出为升序;建的是小根堆时,输出为降序
最佳情况:T(n) = O(nlogn) 最差情况:T(n) = O(nlogn) 平均情况:T(n) = O(nlogn)
补充知识:当我们知道完全二叉树的某个叶子结点序号时,其双亲结点的序号为n/2
2、图片演示
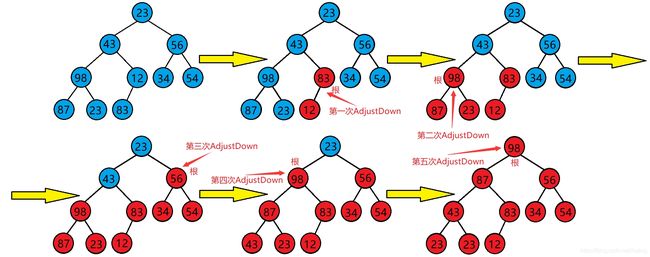
3、代码实现
/**
* 堆排序
* @param array
* @return
*/
public static int[] heapSort(int[] array) {
/*
* 由于数组零号单元格为哨兵岗
* 因此当数组长度为2时代表数组中数据只有一个,没有排序的必要
*/
if(array.length == 2) {
return array;
}
/*
* 从第一个非叶子树开始创建堆
* 直到根结点(零号单元格为哨兵岗,因此根结点的下标为1)
*/
for (int i = (array.length-1)/2; i > 0; i--) {
heapAdjust(array, i, array.length);
}
/*
* 将调整好的堆进行排序
* 堆顶和堆中最后一个元素进行交换固定后再对剩余元素进行调整
* 重复操作直到根结点
*/
for (int i = array.length-1; i > 1; i--) {
array[0] = array[i];
array[i] = array[1];
array[1] = array[0];
heapAdjust(array, 1, i);
}
return array;
}
/**
* 堆的调整
* @param array
* @param rootIndex
* @param length
*/
public static void heapAdjust(int[] array, int rootIndex, int length) {
int minChild = 2*rootIndex; //用于记录最小孩子的下标,此处默认最小是左孩子,若默认为右孩子则需要+1
if(minChild >= length) { //递归结束条件,如果左孩子不存在则返回
return;
}
/*
* 若右孩子存在并且右孩子的值小于左孩子
* 则最小孩子的下标更新
* 同时将后方的比较和下方的比较变成大于号便成了大根堆,输出为升序
*/
if(minChild+1 < length && array[minChild+1] < array[minChild]) {
minChild++;
}
/*
* 若孩子的值比根结点的值要小
* 则两数值进行交换
* 同时更新将 rootIndex 更新为进行交换的孩子的下标
* 充当该子树的根结点的下标传参给下一个 heapAdjust 进行调整、
* 同时将此处的比较和上方的比较变成大于号便成了大根堆,输出为升序
*/
if(array[minChild] < array[rootIndex]) {
array[0] = array[minChild];
array[minChild] = array[rootIndex];
array[rootIndex] = array[0];
rootIndex = minChild; //更新
heapAdjust(array, rootIndex, length); //传参进行下一趟调整
}
}
4、运行结果