商汤实习面试准备(已上岸)
简介
个人从牛客网,知乎等网站收集了一些近一年内商汤实习计算机视觉算法工程师(见习研究员)的面经,总结如下。
面经及回答
-
关于BN层。可学习参数,BN层的作用,在训练阶段和预测阶段的有什么不同,了解GN吗。
-
NMS是怎么做的简述:对于box列表B及其对应的置信度S,采用以下计算方式,选择具有最大socre的检测框M,将其从B集合中移除并加入到最终的检测结果D中,通常将B中剩余的检测框与M计算IoU,将IoU值大于阈值Nt的框从B中移除,重复这个过程,直到B为空。
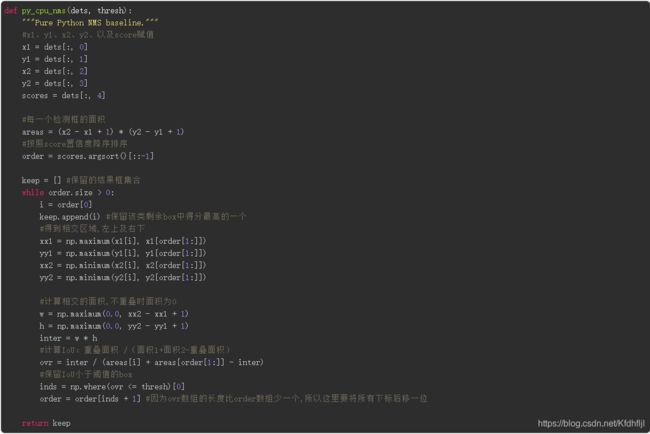
-
编程: 对一个灰度图进行均值滤波(卷积)操作,可以使用numpy,要求输入输出的图片和输入的图片的shape保持一致。
滤波的目的:消除噪声,提取特征
均值滤波:平滑,模糊
中值滤波:消除椒盐噪声
高斯滤波:消除高斯噪声
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
kenel=np.array([
[1,0,1],
[0,1,0],
[1,0,1]
])
# img=Image.open('C:/Users/Kaiser/Desktop/wlop1.jpg')
# plt.imshow(img)
# plt.show()
# img=np.array(img)
img=np.array([
[1,1,1,0,0],
[0,1,1,1,0],
[0,0,1,1,1],
[0,0,1,1,0],
[0,1,1,0,0]
])
def conv(data,kenel):
h,w=data.shape
k=kenel.shape[0]
conv_height=h-k+1
conv_weight=w-k+1
conv=np.zeros((conv_height,conv_weight),dtype=np.float64)
for i in range(conv_height):
for j in range(conv_weight):
conv[i][j]=vaildpixel(np.sum(data[i:i+k,j:j+k]*kenel)/kenel.size)
return conv
img_new=conv(img,kenel)
print(img_new)
#plt.imshow(img_new)
#plt.show()
-
PCA分解是怎么做的。
-
C++之new/delete/malloc/free详解
存储方式相同。malloc和new动态申请的内存都位于堆中。申请的内存都不能自动被操作系统收回,都需要配套的free和delete来释放。
malloc和free返回void类型指针,new和delete直接带具体类型的指针。
malloc和free属于C语言中的函数,需要库的支持,而new/delete是C++中的运算符,况且可以重载,所以new/delete的执行效率高些。C++中为了兼用C语法,所以保留malloc和free的使用,但建议尽量使用new和delete。
在C++中, new是类型安全的,而malloc不是。
不能用malloc和free来完成类对象的动态创建和删除。
使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算,而malloc则需要显式地指出所需内存的尺寸。
(1)栈内存分配运算内置于处理器的指令集中,一般使用寄存器来存取,效率很高,但是分配的内存容量有限。 一般局部变量和函数参数的暂时存放位置。
(2) 堆内存,亦称动态内存。如malloc和new申请的内存空间。动态内存的生存期由程序员自己决定,使用非常灵活。
(3)全局代码区:从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
(4)常量区:文字常量分配在文字常量区,程序结束后由系统释放。
(5)代码区:存放整个程序的代码,因为存储是数据和代码分开存储的。 -
cpp中vector的底层实现原理,如何进行内存分配。
STL 众多容器中,vector 是最常用的容器之一,其底层所采用的数据结构非常简单,就只是一段连续的线性内存空间。
通过分析 vector 容器的源代码不难发现,它就是使用 3 个迭代器(可以理解成指针)来表示的:
//_Alloc 表示内存分配器,此参数几乎不需要我们关心
template>
class vector{
…
protected:
pointer _Myfirst;
pointer _Mylast;
pointer _Myend;
};
其中,_Myfirst 指向的是 vector 容器对象的起始字节位置;_Mylast 指向当前最后一个元素的末尾字节;_myend 指向整个 vector 容器所占用内存空间的末尾字节。
vector扩大容量的本质
另外需要指明的是,当 vector 的大小和容量相等(size==capacity)也就是满载时,如果再向其添加元素,那么 vector 就需要扩容。vector 容器扩容的过程需要经历以下 3 步:
完全弃用现有的内存空间,重新申请更大的内存空间;
将旧内存空间中的数据,按原有顺序移动到新的内存空间中;
最后将旧的内存空间释放。 -
编程: 写一个链表的快速排序,自定义结点。
class NodeList:
def __init__(self,val):
self.val=val
self.next=None
def sort_nodeList_quicksort(head):
'''sort a nodelist by quicksort method
Args:
head: the head node of the nodelist
return:
the head node of the sorted nodelist
'''
if not head:
return None
newhead = NodeList(-1)
newhead.next=head
return quicksort_fornodelist(newhead,None).next
def quicksort_fornodelist(head,end):
'''用于链表快速排序的递归函数
参数:
head:排序列表头节点
end:排序列表尾节点
返回值:
排序完成链表头节点
'''
if head == end or head.next == end or head.next.next == end:
return head
temp_node_head = NodeList(-1)
temp_node=temp_node_head
current_node = head.next
partition_node = head.next
#小于轴值节点的节点接在temp_node后
while current_node.next != end:
next_node=current_node.next
if next_node.val < partition_node.val:
current_node.next = next_node.next
temp_node.next = next_node
temp_node = temp_node.next
else:
current_node = current_node.next
#print_nodelist(partition_node)
#print_nodelist(temp_node_head)
#合并temp链表和原链表
temp_node.next = head.next
head.next = temp_node_head.next
quicksort_fornodelist(head,partition_node)
quicksort_fornodelist(partition_node,end)
return head
def build_nodelist(num_list):
'''创建一个链表,值为num_list中元素值
参数:
num_list:新链表中的元素值列表
返回:
新建链表的头节点
'''
if not num_list:
return None
head = NodeList(num_list[0])
current_node = head
for i in range(1,len(num_list)):
temp_node = NodeList(num_list[i])
current_node.next = temp_node
current_node=current_node.next
return head
def print_nodelist(head):
'''从头到尾打印链表
参数:
head:链表的头节点
返回:
无返回值,直接调用print函数输出
'''
res = []
current_node = head
while current_node:
res.append(current_node.val)
current_node = current_node.next
print(res)
return
num_list = [5,4,3,2,1]
head = build_nodelist(num_list)
print_nodelist(head)
print_nodelist(sort_nodeList_quicksort(head))
-
简单介绍下你知道的 one stage目标检测算法
focal loss
-
5.max pooling 反向传播
max pooling也要满足梯度之和不变的原则 ,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0
。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是max id ,这个变量就是记录最大值所在位置的,因为在反向传播中要用到 -
6.懂马尔科夫吗?
-
简单介绍下SIFT
-
手撕代码:
-
1.单链表的翻转
def reverse_nodelist(head):
'''翻转输入链表
参数:
要翻转链表的头节点
返回:
翻转完成链表的头节点
'''
if not head:
return None
pre_node = None
current_node = head
while current_node:
next_node=current_node.next
current_node.next=pre_node
pre_node=current_node
current_node=next_node
return pre_node
- 之字形打印二叉树
class TreeNode:
def __init__(self,val):
self.val=val
self.left=None
self.right=None
def print_binarytree_zhizixing(root):
'''之字形打印二叉树
参数:
树的根节点
返回值:
按之字形顺序排列的节点值数组
'''
if not root:
return None
is_odd = False
queue = [root]
result_ary = []
while queue:
layer_output = []
next_queue = []
if is_odd:
for i in range(len(queue)):
layer_output.append(queue[i].val)
else:
for i in range(len(queue)-1,-1,-1):
layer_output.append(queue[i].val)
for node in queue:
if node.left:
next_queue.append(node.left)
if node.right:
next_queue.append(node.right)
is_odd= not is_odd
queue = next_queue
result_ary.append(layer_output)
return result_ary
def build_binarytree(num_list,treenode_index):
'''按照num_list中的值建立新的二叉树
输入:
num_list:按照层序遍历的次序,存放二叉树节点的值,空节点使用None代替
treenode_index:建立树节点所对应的值在数组中的索引
返回值:
root,新建树的根节点
'''
if not num_list:
return None
if treenode_index >= len(num_list):
return
if not num_list[treenode_index]:
return
else:
root=TreeNode(num_list[treenode_index])
root.left = build_binarytree(num_list,2 * treenode_index + 1)
root.right = build_binarytree(num_list,2 * treenode_index + 2)
return root
num_list=list(range(1,16))
root=build_binarytree(num_list,0)
print(print_binarytree_zhizixing(root))
-
C++面向对象介绍下
面向对象的三大特性:
1、封装
隐藏对象的属性和实现细节,仅对外提供公共访问方式,将变化隔离,便于使用,提高复用性和安全性。
2、继承
提高代码复用性;继承是多态的前提。
3、多态
父类或接口定义的引用变量可以指向子类或具体实现类的实例对象。提高了程序的拓展性。 -
介绍知识蒸馏是怎么做的
知识蒸馏(KD)是想将复杂模型(teacher)中的dark knowledge迁移到简单模型(student)中去,一般来说,teacher具有强大的能力和表现,而student则更为紧凑。通过知识蒸馏,希望student能尽可能逼近亦或是超过teacher,从而用更少的复杂度来获得类似的预测效果。Hinton在Distilling the Knowledge in a Neural Network中首次提出了知识蒸馏的概念,通过引入teacher的软目标(soft targets)以诱导学生网络的训练。
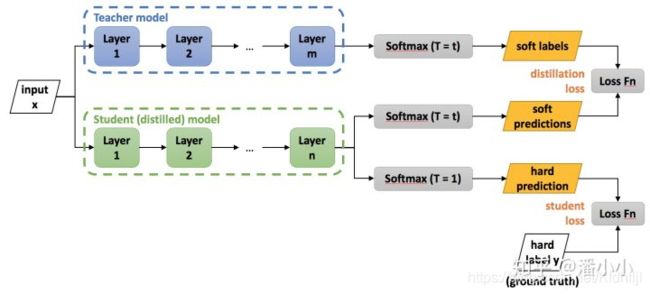
-
MobileNet 介绍
-
普通卷积、DW PW卷积计算量推导
-
MobileNet V2中的Residual结构最先是哪个网络提出来的
-
MxN的方格中有多少个正方形、多少个矩形、有多少种不同面积矩形
//x=min(m,n)-1
//长方形里面数正方形的个数计算公式:m*n+(m-1)*(n-1)+.....+(m-x)*(n-x)
// m*n表示长度为1的正方形的个数,(m-1)*(n-1)表示长度为2的正方形的个数。。。。。。
//长方形里面数长方形的个数计算公式(包含正方形):(1+2+3+...+m)*(1+2+3+...+n)=n*m(n+1)*(m+1)/4
【商汤2面】
- 目标检测在工程中应用有没有遇到一些问题?检测类别冲突怎么办?
- 现有两个特征向量,怎么分析他们的相似度?
闵可夫斯基距离
欧几里得距离
曼哈顿距离
切比雪夫距离
马氏距离
余弦相似度
皮尔逊相关系数
汉明距离
杰卡德相似系数
编辑距离
DTW 距离
KL 散度
编程:
15. 判断二叉树是否包含另一二叉树
class Solution {
public boolean isSubtree(TreeNode s, TreeNode t) {
if (t == null) return true; // t 为 null 一定都是 true
if (s == null) return false; // 这里 t 一定不为 null, 只要 s 为 null,肯定是 false
return isSubtree(s.left, t) || isSubtree(s.right, t) || isSameTree(s,t);
}
/**
* 判断两棵树是否相同
*/
public boolean isSameTree(TreeNode s, TreeNode t){
if (s == null && t == null) return true;
if (s == null || t == null) return false;
if (s.val != t.val) return false;
return isSameTree(s.left, t.left) && isSameTree(s.right, t.right);
}
}
- 有序数组合并
分割的发展可能性
无监督学习在分割的应用
-
如何解决样本不均衡问题
收集更多的数据
改变模型评估方法
数据集重采样
合成样本
尝试不同的算法
使用罚分模型
场景分析:异常检测是罕见事件的检测,这可能是由于偶然事件或由系统调用序列指示的程序的恶意活动而指示的机器故障。与正常操作相比,这些事件很少见。这种思维转变将次要类别视为异常类,这可能有助于考虑分离和分类样本的新方法。
变化检测类似于异常检测,除了寻找异常之外,它正在寻找变化或差异。这可能是使用模式或银行交易所观察到的用户行为的变化。 -
coding:斐波那契数列的O(logn)解法
def fibona(n):
'''计算 f(n)的值 f(n)=f(n-1)+f(n-2)
输入:
n:数列索引,从0开始
返回:
f(n)的值
'''
if n == 0:
return 0
if n == 1:
return 1
f1_f0 = [[1,0]]
matrix_xishu = [
[1,1],
[1,0]
]
fn_fn_1 = matrix_mutilply(f1_f0,matrix_mi(matrix_xishu,n-1)) #[[f_n,f_n_1]]
return fn_fn_1[0][0]
def matrix_mi(matrix,mi):
'''求矩阵的幂
输入:
matrix:底数矩阵
mi:幂次
返回:
res:matrix的mi次结果
'''
if mi == 1:
return matrix
residual = mi%2
oushu_mi = mi - residual
matrix_dishu = matrix
while oushu_mi>1:
matrix_dishu = matrix_mutilply(matrix_dishu,matrix_dishu)
oushu_mi = oushu_mi/2
return matrix_dishu if residual == 0 else matrix_mutilply(matrix_dishu,matrix)
def matrix_mutilply(matrix_a,matrix_b):
'''矩阵乘积运算
输入:
matrix_a:n*m矩阵
matrix_b: m*k矩阵
返回:
res:n*k矩阵
'''
n,m,k = len(matrix_a),len(matrix_b),len(matrix_b[0])
res=[[0] * k for i in range(n)]
for i in range(n):
for j in range(m):
for z in range(k):
res[i][z]+=matrix_a[i][j]*matrix_b[j][z]
return res
print(fibona(100))
如何解决车道线分割有车阻拦视线导致分割结果断裂的问题
coding: 寻找数组中唯一/唯二只出现一次的数
class Solution:
def singleNumber(self, nums: List[int]) -> List[int]:
# xor 为特殊两个数的异或
xor = 0
for num in nums:
xor = xor ^ num
# bit 为xor 第一个为1的位
bit = 1
while xor & bit == 0:
bit <<= 1
# 通过和bit异或的结果,把数分为两组,两个数肯定在不同组,两个组异或出的结果就是两个数
a = 0
b = 0
for num in nums:
if num & bit == 0:
a ^= num
else:
b ^= num
return [b,a]
给了一个一维数组,给了一个行数和列数,要求我转换成二维数组
算法:
3. numpy写个batch norm 层。
4. 给出feature map和卷积核尺寸,求参数量。
一道算法题:迷宫的最短路径
二叉树中序遍历的非递归实现。
sigmoid和softmax的区别
detnet原理
- 一道算法题:输入一个文件,等概率输出某一行,只能顺序遍历
顺序遍历,当前遍历的元素为第L个元素,变量e表示之前选取了的某一个元素,此时生成一个随机数r,如果r%L == 0(当然0也可以是0~L-1中的任何一个,概率都是一样的), 我们将e的值替换为当前值,否则扫描下一个元素直到文件结束。 - smooth L1 loss为什么更有效
![]()
L2损失函数的导数是动态变化的,所以x增加也会使损失增加,尤其在训练早起标签和预测的差异大,会导致梯度较大,训练不稳定。
L1损失函数的导数为常数,在模型训练后期标签和预测的差异较小时,梯度值任然较大导致损失函数在稳定值附近波动难以进一步收敛。
Smooth L1损失函数在x较大时,梯度为常数解决了L2损失中梯度较大破坏训练参数的问题,当x较小时,梯度会动态减小解决了L1损失中难以收敛的问题。
所以在目标检测的Bounding box回归上早期会考虑Smooth L1 Loss:
相比于L1 Loss,可以收敛得更快。
相比于L2 Loss,对离群点、异常值不敏感,梯度变化相对更小,训练时不容易跑飞。
- SGD、Adam之类优化的原理
对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且最好采用默认值
SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果
sgd:负梯度
momentum:乘上上次梯度
adagrad:利用梯度的平方和上一次学习率系数对学习率进行约束
adadelta:梯度的平方和上一次学习率系数对学习率的比例为v和(1-v)
adam:利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,(梯度/根号梯度的平方)
BN、IN、LN、GN原理,BN为什么有效
Python有哪些常用的库报一遍
说一下使用Pytorch对cifar10数据集分类的整个代码流程,构建模型的过程是怎么样的
github的常用操作:上传、合并、分支之类的
linux的常用操作:查看文件大小、删除文件、查看文件行数、假如文件中有很多文件,每个文件中又有很多文件,如何删除全部文件
图像基础知识,如基础网络以及变体。
-
深度学习中提取词向量算法列举、原理、作用以及大致一个发展历程。
-
项目用到的网络介绍。
-
对tensorflow的了解,越多越好。
-
Tf训练执行过程,forword代码过程。
-
Pytorch
-
梯度优化过程原理
-
反向传播
-
梯度优化方式原理介绍
-
损失函数介绍包括公式
-
项目中用的损失函数。
-
西瓜书随机森林。
-
图像处理网络,比如CNN,残差网络结构原理。
-
图像检测。
-
Python知识点:List和tuple区别
-
Return 多个值还是一个值。
-
Import搜索过程
Python搜索模块的路径:搜索路径
1)、程序的主目录
2)、PTYHONPATH目录(如果已经进行了设置)
3)、标准连接库目录(一般在/usr/local/lib/python2.X/)
4)、任何的.pth文件的内容(如果存在的话).新功能,允许用户把有效果的目录添加到模块搜索路径中去
.pth后缀的文本文件中一行一行的地列出目录。
这四个组建组合起来就变成了sys.path了,
-
修饰器功能
-
Yield
-
手写了很简单的代码,斐波那契数列及优化。
-
Svm相关知识
top k问题
bfs
WGAN 有没有分析GAN的问题
代码nms,含类别的,猫和狗两类是分开做nms吗?
代码 psnr
c++ 构造函数和析构函数是干嘛的,如果 在main函数外创建对象,先执行构造函数还是先执行main函数
类内如果没有使用delete,为什么会出现内存泄漏
指针在内存中的存储形式是什么
c++ 存一个二维数组,都会存什么信息 除了元素外 会存列指针
python list和tuple的区别 为什么一个可变一个不可变
写过cuda吗
Faster rcnn中roi pooling是怎么做的
参数量 计算量 dwconv的参数量
为什么dw可以work
用过mask rcnn做检测吗
focal loss的理解
作者:Neymarkim
链接:https://www.nowcoder.com/discuss/192689?type=post&order=time&pos=&page=2&channel=1009&source_id=search_post
来源:牛客网
常用的目标检测算法,one stage two stage的区别
3.比赛中如何解决样本不平衡,以及用了什么训练技巧,为什么能起作用,其原理是什么(回答的不是很好)
- 4.数据增广方法
水平/垂直翻转,旋转,缩放,裁剪,剪切,平移,对比度,色彩抖动,噪声
5.现在有些什么降低模型复杂的的方法,我说了两点,使用一些降低计算量的结构比如mobile net shuffle net,然后模型剪枝(这个就把自己坑了)
7. mobile net shuffle net具体结构,如何降低计算量,给了我一个DW卷积具体实例让我算降低了多少计算量
8.模型剪枝的方法,具体细节(没回答上)
9.SE介绍
问了Matlab / Python / tensorflow的一些操作
谈一谈深度学习的优化的具体措施(问的非常详细,如:常见的损失函数优化算法,二阶导在优化过程中的引入,参数压缩的算法,深度学习分布式部署)
- 详细介绍了batchNorm
首先介绍下实习的工作
介绍faster rcnn这个流程,faster rcnn有哪些缺点
ssd介绍,有哪些优点缺点
nms softnms softernms
任意四边形计算iou
mibilenet v1 v2介绍
resnet inception结构对比
se_resnet和non-local是否了解
开放题:
细粒度分类用inception好还是resnet好
类别不平衡用inception好还是resnet好
pca从特征值分解角度如何解释(这里应该要看下pca推导,可惜不会)
python里如何实现类似c++里引用(在函数里改变基础类型,这里回答可以用list传入,进行修改)
算法题
链表倒数第k个节点
多个数组,都是有序的,想求topk
多路归并
最大连续子串的区间
为什么ssd比faster rcnn慢,介绍r-fcn,介绍ohem
- 算法题:旋转数组,找最小值,能否用递归做
def minnum_of_reverse_array(reverse_array):
'''得到升序数组旋转后的数组中的最小值
参数:
reverse_array:升序数组旋转后的数组 如[3,4,5,1,2]
返回:
数组中的最小值
'''
if not reverse_array:
return None
left = 0
right = len(reverse_array) - 1
while left<right:
mid = left + (right-left) // 2
if reverse_array[mid] > reverse_array[right]:
left = mid + 1
elif reverse_array[mid] < reverse_array[right]:
right = mid
elif reverse_array[mid] == reverse_array[right]:
right = right - 1
return reverse_array[right]
def minnum_of_reverse_array_digui(reverse_array):
'''旋转数组的最小值,使用递归方法
参数:
reverse_array:旋转的有序数组
返回:
数组中的最小值
'''
if not reverse_array:
return float("inf")
left = 0
right = len(reverse_array) - 1
mid = left + (right - left) // 2
minnum_of_array = float("inf")
if reverse_array[mid] < reverse_array[right]:
minnum_of_array = minnum_of_reverse_array_digui(reverse_array[:mid])
elif reverse_array[mid] > reverse_array[right]:
minnum_of_array = minnum_of_reverse_array_digui(reverse_array[mid + 1:])
elif reverse_array[mid] == reverse_array[right]:
minnum_of_array = minnum_of_reverse_array_digui(reverse_array[:right-1])
return min(reverse_array[mid],minnum_of_array)
reverse_array = [2,4,5,1,2,2]
print(minnum_of_reverse_array_digui(reverse_array))
如何解决multiscale问题
算法题:
sqrt(), log()如何求
求数组中出现次数超过一半的数字
四面(45分钟)
介绍实习项目,问目标检测的回归loss是什么,为什么这么用
介绍论文相关
softmax+celoss工程上如何防止上下溢出
SGD 使用mini batch优化和使用所有优化样本优化哪个更好,为什么
特别注意:
- 论文(细节)
- 实习(细节)
后续
- 总结到这,冲冲冲
- 笔者经过了两面技术面+hr面,已拿到实习offer。
其实准备的基本上都没有问,但准备充分,比较有信心,主要是问项目,做的方向比较契合,就通过了,算法题都是剑指offer上的题目,做出来比较简单,但是要求想最优解,有点难度。 - 实习三月,收获很大,也很辛苦,林达华大佬手下的一个部门。